Command Palette
Search for a command to run...
Capacité Catalytique Augmentée De 3,5 Fois ! L'équipe De l'Académie Chinoise Des Sciences a Développé Une Méthode De Conception De Novo De l'enzyme P450 Basée Sur Le Modèle De Diffusion P450Diffusion

Les enzymes du cytochrome P450 sont omniprésentes dans presque tous les organismes et jouent un rôle important dans divers processus métaboliques de la croissance et du développement de la vie. En tant que biocatalyseur le plus polyvalent de la nature, les enzymes P450 peuvent non seulement catalyser plus de 951 réactions redox signalées, mais également oxyder sélectivement les liaisons carbone-hydrogène inertes dans des conditions douces.Il est connu comme le « catalyseur universel » dans les applications industrielles.
De nos jours, l’évolution dirigée a été largement utilisée pour concevoir de nouvelles enzymes P450 avec de meilleures performances. Cependant, les méthodes traditionnelles nécessitent généralement plusieurs cycles de mutagenèse aléatoire et de criblage à haut débit, ce qui rend difficile l’exploration détaillée de l’espace protéique potentiel, soit en effectuant des expériences réelles, soit par des calculs de simulation informatique.
Bien que l’apprentissage profond ait permis des progrès remarquables dans la prédiction de la structure des protéines, la conception fonctionnelle idéale reste un énorme défi. Lors de la conception des fonctions des protéines, il est difficile de collecter suffisamment de données fonctionnelles de haute qualité et de former un modèle complexe pour créer des séquences avec les fonctions souhaitées.En combinant des techniques basées sur la connaissance avec de puissants modèles d'apprentissage profond pour élargir l'espace de séquence de protéines naturelles,Il pourrait s’agir d’une méthode appropriée pour concevoir de nouvelles enzymes P450.
Récemment, Jiang Huifeng, Cheng Jian et d'autres chercheurs de l'Institut de biotechnologie industrielle de Tianjin, Académie chinoise des sciences, ont analysé les principes de conception des poches de l'enzyme P450 flavonoïde 6-hydroxylase (F6H).Développé une méthode de conception de novo d'enzyme P450 basée sur le modèle de diffusion et les principes de conception de poche, P450Diffusion.La recherche connexe a été publiée dans Research sous le titre « Cytochrome P450 Enzyme Design by Constraining the Catalytic Pocket in a Diffusion Model ».
Basée sur la diffusion P450, cette étude a généré une nouvelle enzyme avec une meilleure activité et une stabilité plus élevée que l'enzyme P450 naturelle. Par rapport à la flavonoïde 6-hydroxylase naturelle, la capacité catalytique de la nouvelle enzyme a été augmentée de 1,3 à 3,5 fois.
Points saillants de la recherche :
* Cette étude a analysé le mécanisme d'origine de nouvelles fonctions dans l'évolution des enzymes P450 et a proposé le « principe de fixation en trois points » de la liaison du substrat de l'enzyme P450
* La capacité catalytique de la nouvelle enzyme générée par la diffusion P450 est augmentée de 1,3 à 3,5 fois
* Cette étude fournit de nouvelles idées pour la conception de nouvelles enzymes P450 fonctionnelles dans le cadre du modèle de diffusion d'apprentissage profond. À l’avenir, cette méthode devrait jouer un rôle dans des domaines tels que la bio-ingénierie et la catalyse industrielle, et favoriser le développement et l’application de nouvelles enzymes.

Adresse du document :
https://spj.science.org/doi/10.34133/research.0413
Le projet open source « awesome-ai4s » rassemble plus de 100 interprétations d'articles AI4S et fournit des ensembles de données et des outils massifs :
https://github.com/hyperai/awesome-ai4s
Ensemble de données : collecter et encoder l'ensemble de données
Pour construire P450Diffusion, les chercheurs ont examiné et analysé toutes les enzymes P450 potentielles à partir de bases de données d'enzymes P450 publiées et de bases de données publiques, ont filtré les séquences d'une longueur supérieure à 560 et ont obtenu 226 509 séquences comme ensembles de données d'entraînement.
Par la suite, les chercheurs ont codé l'ensemble de données d'entraînement, chaque acide aminé de la séquence protéique étant codé comme un vecteur à 8 dimensions, et chaque lot de séquences protéiques étant codé comme un vecteur 64×1×560×8 - où 64 est la taille du lot, égale au nombre d'échantillons dans les données d'entraînement ; 1 représente la taille du canal ; 560 représente la longueur maximale de la séquence protéique ; et 8 représente le vecteur codant VHSE8 pour chaque acide aminé dans la séquence protéique.
Si la séquence protéique était plus courte que 560 chiffres, les chercheurs ajoutaient des espaces jusqu’à atteindre une longueur de 560 chiffres. Dans ce cas, il attribue un vecteur de 8 zéros comme code pour l'écart.
Architecture du modèle : P450 Diffusion, une méthode de conception de novo pour les enzymes P450
Les chercheurs ont pris comme exemple une flavonoïde 6-hydroxylase (CYP706X1) d’Erigeron breviscapus. Cette enzyme appartient à la sous-famille CYP706X et convertit l'apigénine en bréviscapine dans la voie de biosynthèse de la bréviscapine.
d'abord,Grâce à la reconstruction de séquences ancestrales, à des expériences de mutation inverse, à une accumulation progressive vers l'avant et à une analyse cristallographique, les chercheurs ont identifié les résidus fondateurs qui composent la poche catalytique, responsables de l'innovation de la fonction du gène de l'enzyme P450 ;Deuxièmement,Grâce à une analyse structurelle approfondie, les chercheurs ont élucidé les principes de conception de la poche catalytique fonctionnellement innovante ;enfin,Il combine le principe de conception de poche catalytique avec le modèle de probabilité de diffusion de débruitage qui fonctionne bien dans la génération d'images, et conçoit un modèle artificiel de génération d'enzyme P450 P450Diffusion.
Première étape : identifier les résidus fondateurs qui constituent la poche catalytique et sont responsables de l’innovation de la fonction du gène de l’enzyme P450.
Parmi les enzymes P450 de la famille CYP706 identifiées, seules les enzymes P450 de la sous-famille CYP706X sont capables de catalyser les substrats flavonoïdes, ce qui suggère que la fonction de l'enzyme P450 flavone 6-hydroxylase (F6H) peut avoir été innovée de novo dans l'ancêtre de la sous-famille CYP706X.
Pour élucider le mécanisme moléculaire de la formation de la poche catalytique avec fonction F6H, les chercheurs ont proposé d'analyser les changements de composition des résidus entre les poches catalytiques de l'ancXY non fonctionnel (l'ancêtre commun des sous-familles CYP706X et CYP706Y) et l'ancX fonctionnel (l'ancêtre commun de la sous-famille CYP706X). À moins de 8 Å du centre actif, 16 des 48 résidus diffèrent.
Comme le montre la figure A ci-dessous, les résidus d’ancX et d’ancXY sont colorés respectivement en cyan et en magenta ; et lorsque tous ces 16 résidus sont remplacés par les résidus correspondants dans ancX, le mutant (appelé ancXY-16) acquiert la fonction F6H, comme le montre la figure B ci-dessous.
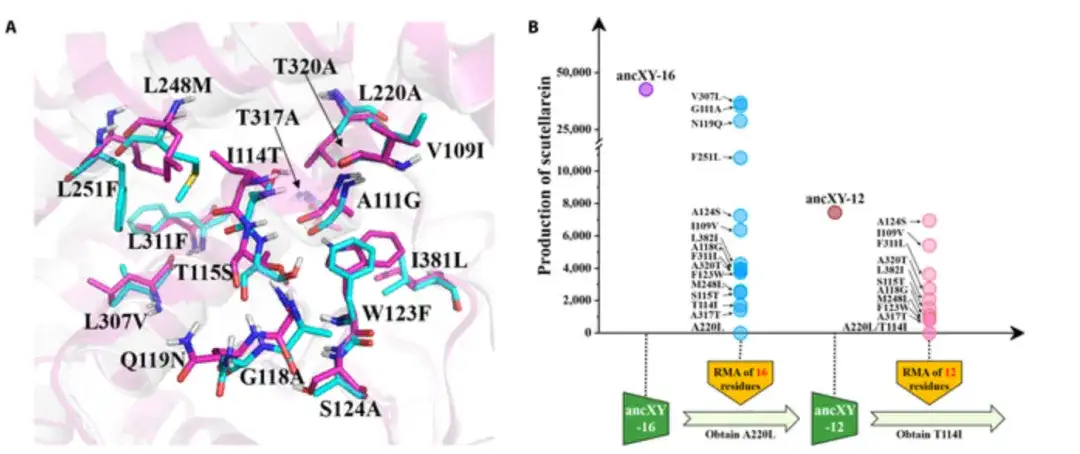
Étant donné que les positions des résidus dans la poche catalytique sont différentes dans l’espace tridimensionnel, tous les résidus ne contribuent pas de manière significative à la reconnaissance et à la liaison du substrat. Les chercheurs ont donc tenté d'identifier le résidu fondateur dans la poche catalytique grâce à un test de mutation inverse (RMA : évaluation de l'effet de mutation de chaque résidu dans la poche catalytique d'ancXY-16 en le ramenant à son type ancestral). Pour identifier plus rapidement les résidus fondateurs, les chercheurs ont également utilisé une stratégie d’accumulation progressive vers l’avant (PFA) pour ajouter progressivement des mutations importantes à ancXY jusqu’à ce que le mutant acquière la fonction F6H.
Enfin, l'expérience a révélé que la mutation de 5 acides aminés (L220A/I114T/T317A/W123F/L248M) jouait un rôle fondateur (résidu fondateur) dans le processus d'innovation fonctionnelle de F6H d'ancXY à ancX.
Étape 2 : Élucider les principes de conception de la poche catalytique avec une innovation fonctionnelle.
En analysant en profondeur le modèle de liaison de l'apigénine dans ancXY-5, les chercheurs ont mieux interprété le mécanisme potentiel des cinq résidus fondateurs impliqués dans l'innovation fonctionnelle. Sur la base des mutations des cinq résidus fondateurs, la poche catalytique semble suivre le principe de « fixation en trois points ».
La « fixation en trois points » fait référence aux interactions clés avec les trois pôles de la molécule d’apigénine.Il s'agit notamment de : le 4'-OH (premier hub) de la molécule d'apigénine est fixé par des liaisons hydrogène fournies par T114, le cycle « B » de l'apigénine (deuxième hub) est fixé par des interactions d'empilement π entre F123 et M248, et le 7-OH de l'apigénine (troisième hub) est fixé par des liaisons hydrogène avec le groupe fer-oxyle de CpdI.
Le modèle maintient le substrat apigénine dans une conformation proche de la réaction (NAC), maintenant l'orientation relative entre le site de réaction de l'apigénine et le groupe fer-oxyle CpdI à une distance et un angle favorables (3,6 Å et 155°), initiant ainsi la réaction de 6-hydroxylation de l'apigénine pendant le processus catalytique.
Les chercheurs ont proposé que la « fixation en trois points » puisse être utilisée comme principe de conception de poche catalytique pour l'innovation fonctionnelle naturelle de F6H, ce qui fournit également de nouvelles idées pour la conception d'enzymes P450 avec les fonctions souhaitées.
Étape 3 : Combinez le principe de conception de poche catalytique avec le modèle de probabilité de diffusion de débruitage qui fonctionne bien dans la génération d'images pour concevoir un modèle artificiel de génération d'enzyme P450 P450Diffusion.
Les chercheurs ont combiné le modèle de diffusion avec les principes de conception de la poche catalytique F6H pour concevoir une enzyme P450 avec la fonction souhaitée à partir de zéro, comme le montre la figure ci-dessous. Le processus de conception de nouvelles enzymes P450 comprend la construction du modèle de diffusion P450, la génération de séquences, le criblage et la vérification expérimentale.
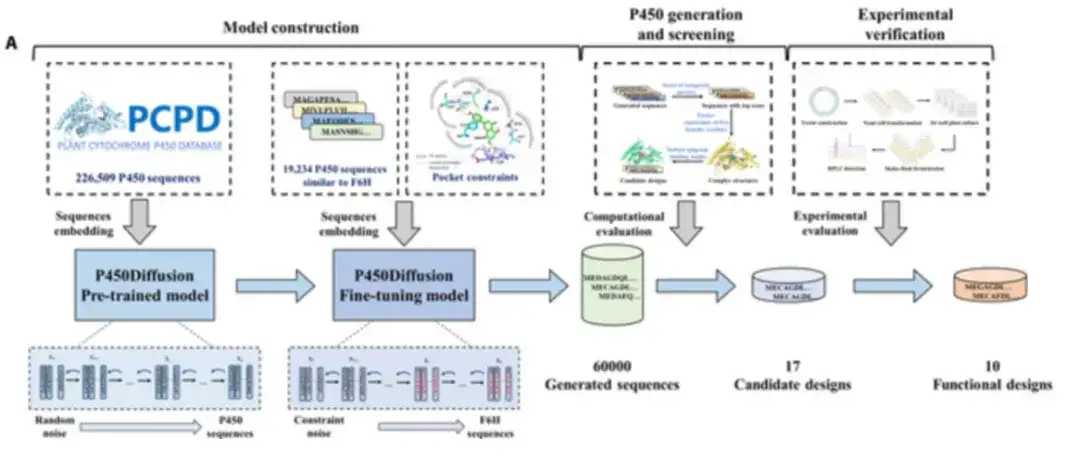
P450Diffusion se compose principalement de deux modèles, à savoir le modèle pré-entraîné et le modèle de réglage fin.
d'abord,226 509 séquences d’enzymes P450 naturelles ont été collectées pour former le modèle de diffusion de séquences P450 pré-entraîné.
Le modèle pré-entraîné se compose de deux sous-processus : un sous-processus de diffusion directe qui ajoute progressivement du bruit gaussien à la représentation de la séquence enzymatique P450 jusqu'à ce qu'il devienne un bruit aléatoire ; et un sous-processus de génération inverse qui démarre à partir d'un bruit aléatoire et débruite progressivement la représentation de la séquence enzymatique P450 pour générer de nouvelles séquences P450. Après 150 547 cycles d’entraînement, le modèle de diffusion pré-entraîné peut générer une grande variété de séquences, avec des similitudes avec des séquences naturelles allant de 20% à 50%.
Deuxièmement,Le modèle de diffusion pré-entraîné a été affiné à l'aide de 19 202 séquences d'enzymes P450 présentant une similarité significative avec la sous-famille CYP706X pour garantir que les séquences générées avaient une structure similaire à celle de F6H.
De plus, des contraintes ont été imposées aux cinq résidus fondateurs, T114, F123, A220, M248 et A317, pour garantir que le principe de conception « fixe en trois points » puisse être reproduit dans les séquences générées de novo. Le modèle qui combine le réglage fin de l’ensemble d’entraînement avec la génération contrainte est appelé modèle de diffusion à réglage fin.
Alors,Pour améliorer le taux de réussite de la validation expérimentale, les chercheurs ont effectué un criblage virtuel de 60 000 séquences générées en utilisant trois critères : le score calculé d'un indicateur complet pour évaluer la qualité des séquences générées, les contraintes de poche tridimensionnelles des cinq résidus fondateurs et la robustesse du mode de liaison de l'apigénine.
Après la projection virtuelle,Les chercheurs ont soigneusement sélectionné 17 enzymes P450 non naturelles prometteuses pour une exploration plus approfondie.
Résultats de la recherche : Capacité catalytique augmentée de 1,3 à 3,5 fois
Les chercheurs ont testé expérimentalement si les séquences générées par P450Diffusion étaient d’authentiques enzymes P450 et remplissaient des fonctions F6H.
Après un criblage virtuel, les chercheurs ont synthétisé les 17 modèles sélectionnés et les ont exprimés dans un système d’expression de levure. Comparé au CYP706X1,Ces conceptions ont montré une identité de séquence de 70% à 87%,Cela met en évidence leur potentiel en tant que nouveaux catalyseurs.
En nourrissant l'apigénine comme substrat et en cultivant la levure recombinante pendant 4 jours et en effectuant une analyse HPLC, les chercheurs ont trouvé 10 modèles avec une activité F6H significative, comme le montre la figure ci-dessous.
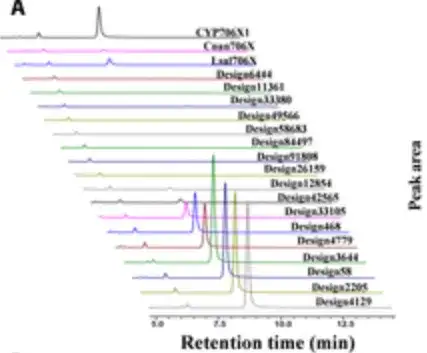
Étonnamment,Six modèles ont montré des augmentations de 1,3 à 3,5 fois de la capacité catalytique pour la production d'oléandrine par rapport au CYP706X1.Comme le montrent les 6 barres sur le côté droit de la figure ci-dessous, les 4 conceptions actives restantes ont également montré des activités comparables à celles d'autres enzymes F6H naturelles (c'est-à-dire Cnan706X et Lsal706X).
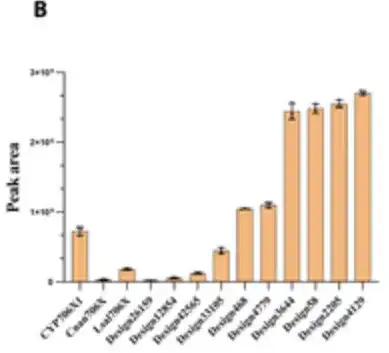
Les résultats ont montré que P450Diffusion peut non seulement capturer les principes de conception de base de la poche catalytique F6H et générer efficacement des séquences enzymatiques P450 avec une activité F6H,Il est également possible de filtrer les enzymes P450 qui sont meilleures que les séquences naturelles de l'espace de séquences enzymatiques P450.
L'apprentissage automatique basé sur les données accélère l'évolution des enzymes
Les enzymes présentes dans la nature ont diverses fonctions et ont été appliquées dans la production industrielle et la recherche universitaire. Cependant, les propriétés et les fonctions de bon nombre de ces enzymes ne peuvent pas répondre pleinement aux besoins de l’application. L’amélioration de certaines propriétés de ces enzymes par modification est une tâche importante de l’ingénierie enzymatique.
dans,L’évolution dirigée peut augmenter le taux d’évolution des enzymes en simulant le processus évolutif dans la nature.Elle est devenue une technologie clé pour la modification des molécules enzymatiques. L’évolution dirigée joue un rôle important dans la biocatalyse et la conception de médicaments, mais le grand nombre de mutants générés par le caractère aléatoire des mutations pose un énorme défi aux capacités de criblage expérimental. Ces dernières années, les technologies émergentes telles que l’intelligence artificielle et le traitement des mégadonnées sont devenues des méthodes de recherche importantes dans le domaine de la biocatalyse. Parmi eux, l’apprentissage automatique obtient la cartographie de la séquence/structure à la fonction enzymatique d’une manière basée sur les données, contribuant ainsi à améliorer l’efficacité de l’ingénierie enzymatique.
Bien que les gènes codant les enzymes puissent être facilement identifiés, dans la grande majorité des cas (plus de 991 TP3T), la fonction exacte de la synthétase est inconnue car la caractérisation expérimentale de la fonction enzymatique, c'est-à-dire quelles molécules de départ sont converties en quelles molécules finales spécifiques par une enzyme particulière, prend énormément de temps.
Pour relever ce défi, des chercheurs de l’Université de Düsseldorf (HHU) ont développé un modèle général d’apprentissage automatique ESP pour prédire les paires enzyme-substrat.Surpasse le 91% en termes de précision sur des données de test indépendantes et diverses. L'ESP peut être appliqué avec succès aux enzymes très diverses et à la large gamme de métabolites inclus dans les données de formation, surpassant les modèles conçus pour des familles d'enzymes individuelles et bien étudiées.
L'étude a été publiée dans Nature Communications en mai 2023 sous le titre « Un modèle général pour prédire les substrats de petites molécules d'enzymes basé sur l'apprentissage automatique et profond ».
Lien vers l'article :
https://www.nature.com/articles/s41467-023-38347-2
La conception d’enzymes de novo, bien que passionnante, est également remise en question par la complexité de la catalyse enzymatique. Les chercheurs de la société d'ingénierie enzymatique sans cellules Enzymit présentent CoSaNN (Conformational Sampling using Neural Networks), une nouvelle stratégie de conception d'enzymes.Exploiter les avancées de l’apprentissage profond pour la prédiction de structure et l’optimisation de séquence.En contrôlant la conformation de l’enzyme, les chercheurs peuvent étendre l’espace chimique au-delà du champ de la simple mutagenèse.
En outre, l'équipe a développé davantage SolvIT,Il s’agit d’un réseau neuronal graphique formé pour prédire la solubilité des protéines dans E. coli.En tant que couche supplémentaire d’optimisation pour la production d’enzymes hautement exprimées. En utilisant cette approche, les chercheurs ont conçu de nouvelles enzymes avec des niveaux d'expression supérieurs, avec 54% conçues pour être exprimées dans E. coli et avec une stabilité thermique améliorée, avec plus de 30% conçues pour avoir un Tm plus élevé que l'enzyme modèle.
L'étude, intitulée «Context-Dependent Design of Induced-fit Enzymes using Deep Learning Generates Well Expressed, Thermally Stable and Active Enzymes», a été publiée sur la plateforme de pré-impression bioRxiv en août 2023.
Lien vers l'article :
https://www.biorxiv.org/content/10.1101/2023.07.27.550799v3

Les données montrent que d’ici 2023, le marché mondial des enzymes industrielles à lui seul vaudra 7,4 milliards de dollars américains. À l’avenir, en exploitant la puissance de l’intelligence artificielle et en apprenant des informations caractéristiques sur la composition et l’évolution des protéines, les chercheurs seront en mesure de résoudre de nombreux types de problèmes d’ingénierie enzymatique, tels que la prédiction de mutations ayant des effets bénéfiques, l’optimisation de la stabilité des protéines, l’amélioration de l’activité catalytique, etc. Cela réduira encore le coût de la biofabrication et apportera une valeur commerciale plus élevée.
Références :
1.https://spj.science.org/doi/10.34133/research.0413
2.https://www.cas.cn/syky/202407/t20240718_5026250.shtml
3.https://biotech.aiijournal.com/CN/10.13560/j.cnki.biotech.bull.1985.2022-0724
4.https://www.jiqizhixin.com/articles/2023-06-25-12
5.https://www.jiqizhixin.com/articles








