Command Palette
Search for a command to run...
Une Boîte Noire Devient Transparente : l'UCLA Développe Un Réseau Neuronal Interprétable (SNN) Pour Prédire Les Glissements De Terrain

Contenu en un coup d'œil :La prévision des glissements de terrain a toujours été très difficile car elle implique de multiples facteurs de variation temporelle et spatiale. Les réseaux neuronaux profonds (DNN) peuvent améliorer la précision des prédictions, mais ils ne sont pas intrinsèquement interprétables. Dans cet article, les chercheurs de l’UCLA ont présenté le SNN. Le SNN présente les caractéristiques d'une interprétabilité complète, d'une grande précision, d'une grande capacité de généralisation et d'une faible complexité du modèle, ce qui améliore encore la capacité de prédiction du risque de glissement de terrain.
Mots-clés:Glissement de terrain SNN DNN
Cet article a été publié pour la première fois sur la plateforme publique HyperAI WeChat~
La survenue de glissements de terrain est affectée par une combinaison de facteurs, tels que les caractéristiques matérielles telles que le terrain, la pente, le sol, la roche, ainsi que les conditions environnementales telles que le climat, les précipitations et l’hydrologie. Par conséquent, il a toujours été très difficile de faire des prédictions pertinentes. En règle générale, les géologues utilisent des modèles physiques et statistiques pour estimer le risque de glissements de terrain.Bien que ces modèles puissent fournir des prédictions assez précises, la formation de modèles physiques nécessite beaucoup de temps et de ressources et ne convient pas aux applications à grande échelle.
Ces dernières années, les chercheurs ont formé des modèles d’apprentissage automatique, en particulier des réseaux neuronaux profonds (DNN), pour prédire les glissements de terrain. En tant que modèle de prédiction de haute précision, le DNN a des effets significatifs dans de nombreux domaines tels que la reconnaissance d'images, la reconnaissance vocale, le traitement du langage naturel, la biologie computationnelle et les big data financiers.Cependant, il comporte plusieurs couches de structures cachées en dehors de la couche d’entrée et de la couche de sortie et manque d’interprétabilité. Ce problème de boîte noire a toujours troublé les chercheurs.
Récemment, des chercheurs de l’Université de Californie à Los Angeles (UCLA) ont développé un réseau neuronal superposable (SNN). Contrairement au DNN, le SNN peut séparer les résultats de différentes entrées de données et mieux analyser les facteurs d’influence des catastrophes naturelles. Le modèle SNN surpasse les modèles physiques et statistiques et atteint des performances similaires à celles des DNN de pointe.Actuellement, les résultats de la recherche ont été publiés dans la revue Communications Earth & Environment, intitulée « Modélisation de la susceptibilité aux glissements de terrain par un réseau neuronal interprétable ».

Figure 1 : Les résultats de la recherche ont été publiés dans Communications Earth & Environment
Lire l'article complet :
https://www.nature.com/articles/s43247-023-00806-5#Sec4
Données sélectionnées sur les glissements de terrain dans l'Himalaya le plus oriental
Grâce à l’analyse des données, les chercheurs ont découvert que les victimes causées par les glissements de terrain entre 2004 et 2016 se sont produites principalement en Asie.La région la plus orientale de l’Himalaya est très exposée à des événements tels que des glissements de terrain sur de fortes pentes, des précipitations extrêmes et des inondations. Les chercheurs ont généré un inventaire des glissements de terrain (un enregistrement ou un ensemble de données sur les événements de glissement de terrain) dans l'Himalaya le plus oriental en combinant des zones de glissement de terrain délimitées manuellement avec un algorithme de détection semi-automatisé.Le nombre total de glissements de terrain cartographiés était de 2 289, dont la superficie s'étendait de 900 à 1,96 × 106 m2, sur toute la zone d'étude de 4,19 × 109 m2.

Figure 2 : Zone d'étude dans la partie la plus orientale de l'Himalaya
Les couleurs représentent l'altitude et la case jaune indique la zone d'étude dans les directions NS (Dibang), NW-SE (front de chaîne) et EW (Lohit).
L'encart montre l'Himalaya oriental, le cadre noir indique la zone d'étude et la ligne gris foncé indique la frontière nationale (coin supérieur droit).
Comme le montre la figure ci-dessus, les chercheurs ont sélectionné trois zones avec des conditions environnementales différentes (Dibang, Lohit et front de chaîne) dans la partie la plus orientale de l'Himalaya pour tester les performances et l'application du modèle SNN.Ci-après, les zones de Dibang, Lohit et du front de chaîne sont respectivement appelées NS, EW et NW-SE.
Adresse du jeu de données :
https://doi.org/10.25346/S6/D5QPUA
Développement de modèles : 6 étapes pour former un SNN
Dans cette étude, afin de contourner le manque d'interprétabilité du DNN tout en garantissant la précision, les chercheurs ont combiné l'extraction de modèles et des méthodes basées sur les caractéristiques pour générer un cadre d'optimisation ANN additif entièrement interprétable. L'ANN additif est un type de modèles additifs généralisés (GAM). Les méthodes d’extraction de modèles visent à former un modèle d’étudiant interprétable pour imiter le modèle de l’enseignant. Les méthodes basées sur les caractéristiques visent à analyser et à quantifier l’impact de chaque caractéristique d’entrée.
Les chercheurs appellent cette architecture ANN additive optimisation du réseau neuronal superposable (SNN).Contrairement au DNN, qui établit l'interdépendance entre les caractéristiques via des connexions entre différentes couches, le SNN établit l'interdépendance entre les caractéristiques via la fonction produit des caractéristiques d'entrée d'origine.La comparaison entre les deux est illustrée dans la figure ci-dessous :
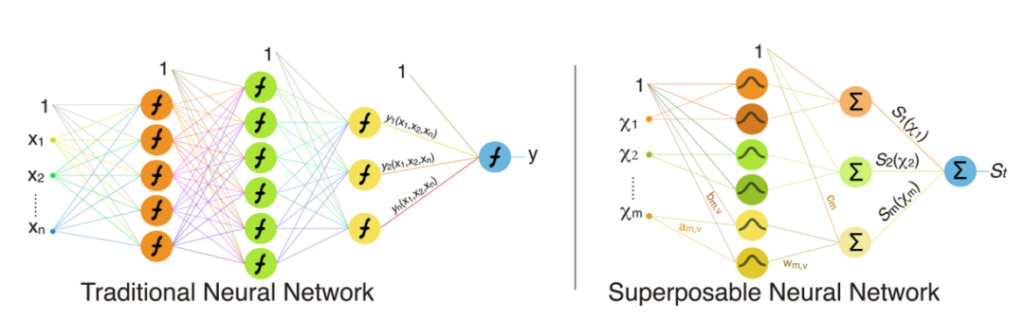
Figure 3 : DNN traditionnel et SNN
x1, x2, …, xn désignent un ensemble de n caractéristiques originales, χ1, χ2, …, χM désignent un ensemble de M caractéristiques combinées, et Y et St font référence aux résultats de susceptibilité dans DNN et SNN, respectivement.
Comme le montre la figure 3, dans les DNN traditionnels, les fonctionnalités sont représentées et apprises via des connexions dans le réseau. Cette dépendance est étroitement ancrée dans la structure du réseau, qui est très complexe et difficile à séparer.Dans les SNN, les chercheurs trouvent et attribuent explicitement des caractéristiques qui contribueront à la sortie à des entrées séparées à l'avance, et chaque neurone est connecté à une seule entrée.
Le diagramme de flux de formation SNN est le suivant :
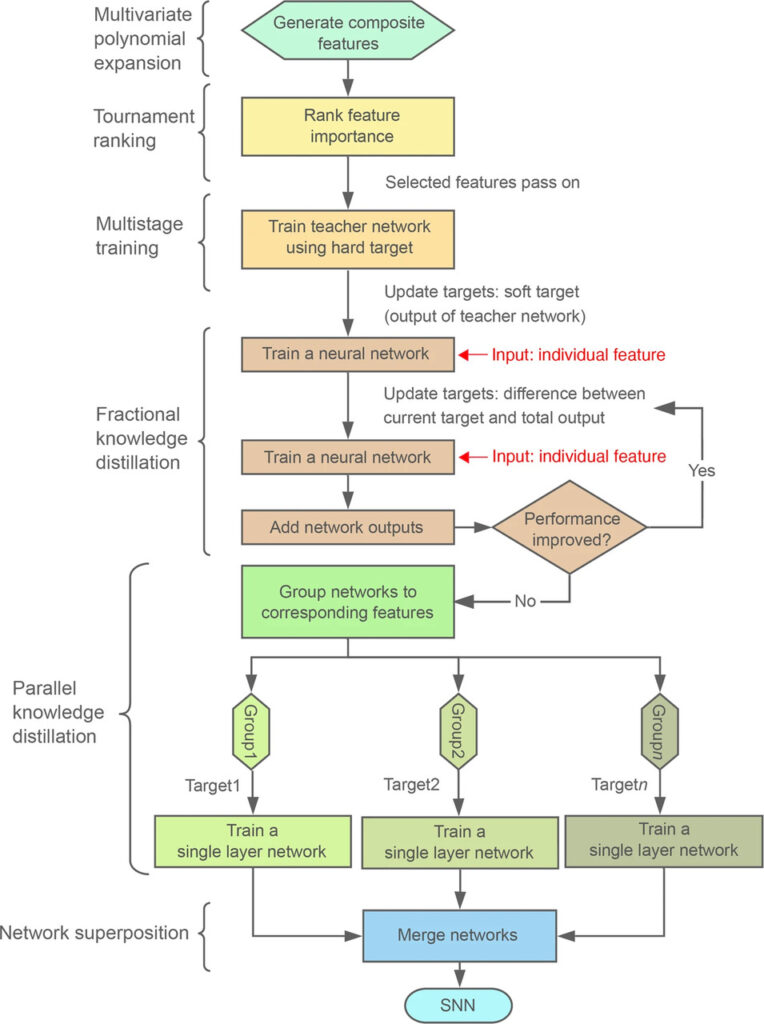
Figure 4 : Organigramme de la formation du SNN
Comme le montre la figure, les chercheurs ont adopté deux méthodes principales : le modèle de sélection de caractéristiques et la formation en plusieurs étapes.Le modèle de sélection de caractéristiques est utilisé pour sélectionner les caractéristiques les plus pertinentes pour l’analyse et la modélisation ultérieures ; La formation en plusieurs étapes signifie que le processus de formation est divisé en plusieurs étapes, chaque étape a des objectifs et des stratégies de formation spécifiques et optimise progressivement les performances du modèle.
Le processus de formation peut être résumé selon les étapes suivantes :
- Développement polynomial multivarié :Créer des entités composites.
- Classement du tournoi :Une méthode de sélection automatique de fonctionnalités pour trouver les fonctionnalités les plus pertinentes pour le modèle.
- Formation en plusieurs étapes (MST) :Une technique d’apprentissage profond de second ordre pour générer des réseaux d’enseignants de haute performance.
- Distillation fractionnée des connaissances :Utilisé pour séparer la contribution de chaque fonctionnalité au résultat final.
- Distillation parallèle des connaissances :Des techniques standard de distillation des connaissances sont appliquées au réseau correspondant à chaque fonctionnalité individuellement.
- Superposition de réseaux :Les réseaux monocouches correspondant à chaque fonctionnalité sont fusionnés en un seul SNN.
Résultats expérimentaux
La précision la plus élevée du SNN dépasse 99%
Sur la base des caractéristiques composites de plus haut niveau utilisées dans la formation des modèles, les chercheurs ont divisé le SNN en trois niveaux de modèles différents, à savoir le niveau 1, le niveau 2 et le niveau 3.Les expériences montrent que la précision du SNN de niveau 3 peut atteindre plus de 99% du DNN de l'enseignant SOTA, et la précision du SNN de niveau 2 dépasse 98%.Étant donné la faible différence de précision entre les deux, les chercheurs supposent que l’interprétabilité du SNN de niveau 2 est suffisante pour l’analyse.
Ensuite, les chercheurs ont comparé les SNN de niveau 1 et de niveau 2 avec le modèle d’enseignant SOTA DNN (MST, DNN basé sur l’optimisation du second ordre), ainsi qu’avec les méthodes traditionnelles (LogR et LR).Toutes les méthodes ont été appliquées à la même zone et en utilisant les mêmes données, et les résultats sont présentés dans la figure ci-dessous.
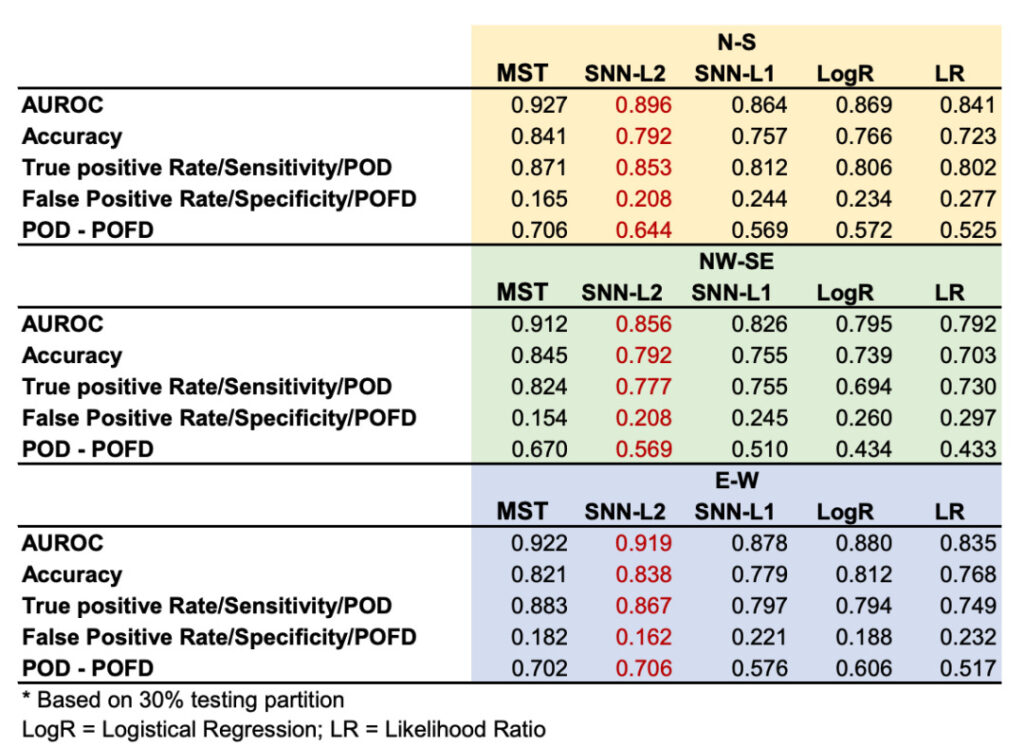
Figure 5 : Comparaison des performances de différents modèles
MST: Modèle d'enseignant SOTA DNN
LogR : Régression logistique (méthode traditionnelle)
LR : Rapport de vraisemblance (méthode traditionnelle)
Comme le montre la figure, les performances du SNN sont comparables à celles du modèle MST et surpassent les modèles traditionnels couramment utilisés. Les valeurs moyennes des trois zones d'étude ont été calculées et les AUROC des SNN de niveau 1 et de niveau 2 étaient respectivement de 0,856 et 0,890. L'AUROC du SNN de niveau 2 est environ 8% plus élevé que celui de LogR (AUROC = 0,848) et LR (AUROC = 0,823).
AUROC (aire sous la caractéristique de fonctionnement du récepteur) : une mesure de performance utilisée pour évaluer les modèles de classification. Plus l'AUROC est proche de 1, meilleures sont les performances du modèle.
Les SNN sont entièrement interprétables
SNN est un modèle entièrement interprétable avec un niveau d’interprétabilité comparable à la régression linéaire.
Les chercheurs ont divisé la zone d’étude en zones de glissement de terrain (ld) et zones sans glissement de terrain (nld). Le SNN fournit la contribution exacte des caractéristiques individuelles à la susceptibilité, ce qui permet de quantifier l’impact de chaque caractéristique sur la susceptibilité aux glissements de terrain.En calculant les différences dans les caractéristiques individuelles entre les régions ld et nld, les principaux facteurs de contrôle du glissement de terrain et leurs contributions relatives peuvent être déterminés.
Comme le montre la figure ci-dessous,MAP*Slope (le produit des précipitations annuelles moyennes et de la pente), NEE*Slope (le produit du nombre d'événements pluviométriques extrêmes et de la pente), Asp*Relief (le produit de l'aspect et du vent d'alimentation local) et Asp (aspect) ont des effets importants dans les trois régions.
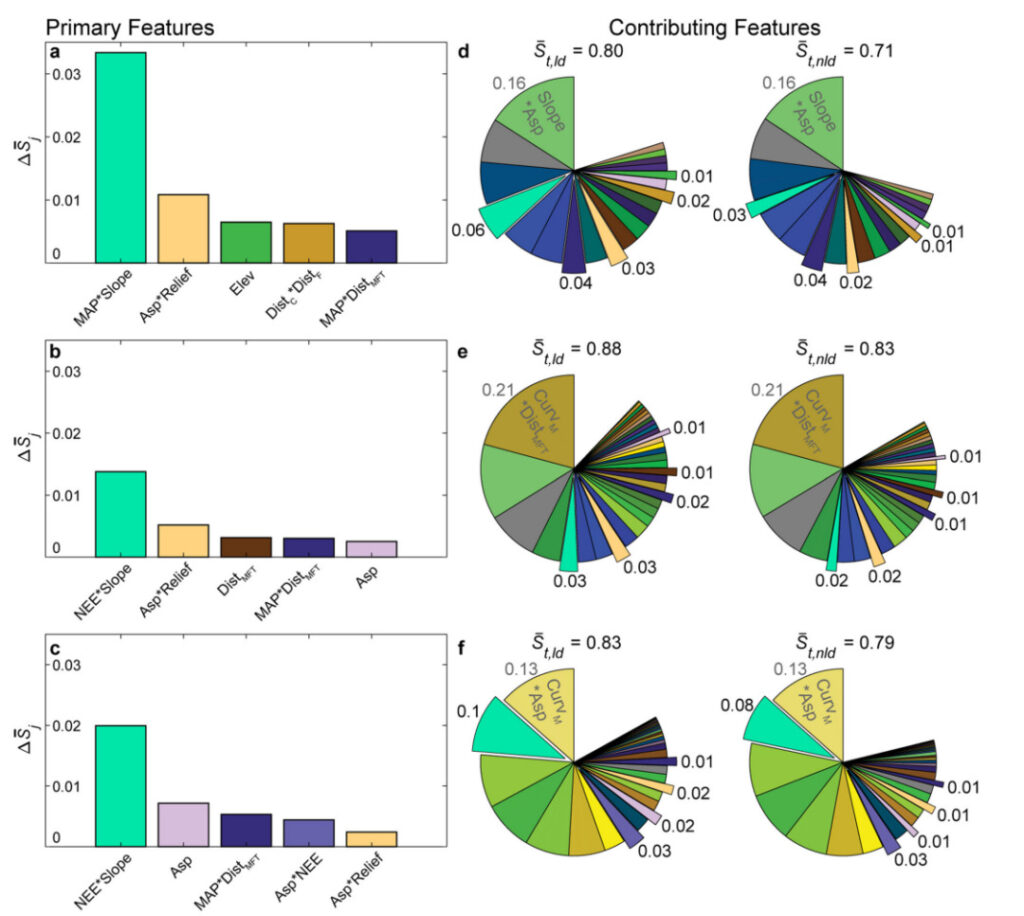
Figure 6 : Effet de diverses caractéristiques sur la susceptibilité aux glissements de terrain
(a, d) : zone d’étude de la Nouvelle-Écosse; (b, e) : zone d’étude NO-SE; (c, f) : zone d'étude EW.
Les graphiques à barres (a–c) représentent la différence de magnitude de chaque caractéristique entre les zones de glissement de terrain (ld) et les zones sans glissement de terrain (nld) par ordre décroissant ; les graphiques à secteurs (d–f) représentent l’impact moyen de chaque caractéristique sur les zones de glissement de terrain (ld) et de non-glissement de terrain (nld).
Précipitations annuelles moyennes (MAP), nombre d'événements pluviométriques extrêmes (NEE), exposition (Asp), altitude (Elev), courbure moyenne (CurvM), distance au lit de la rivière (DistC), toutes les failles (DistF) et principales zones de chevauchement et de fracture frontales (DistMFT), et relief local (Relief).
L'astérisque * indique la multiplication algébrique de deux caractéristiques.
En raison des capacités uniques du SNN,Les chercheurs ont pu isoler la distribution spatiale des principales caractéristiques de contrôle et leurs effets locaux.
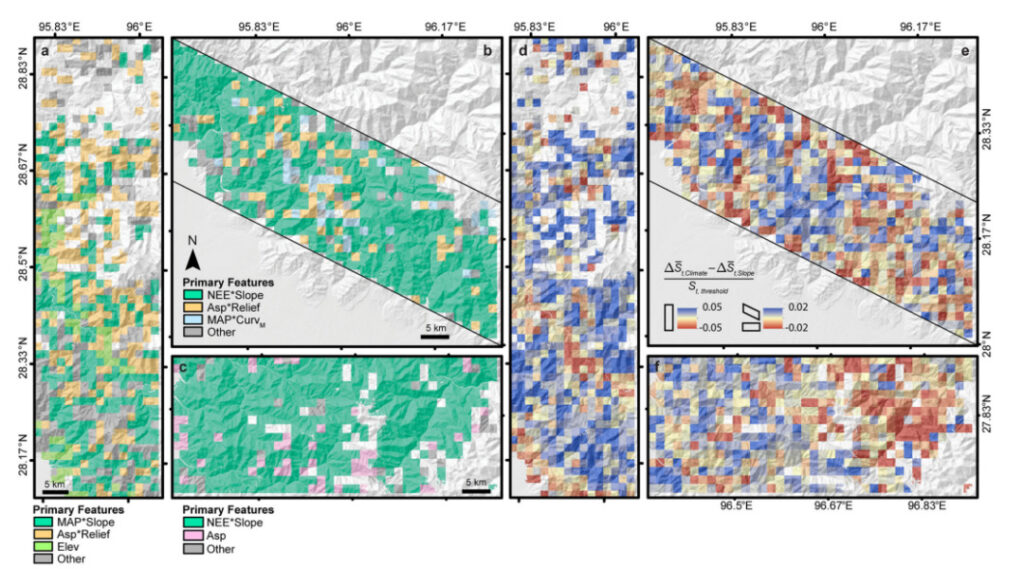
Figure 7 : Répartition spatiale de chaque caractéristique
ac : répartition spatiale des principales caractéristiques.
df : Effets du climat et de la pente sur la susceptibilité.
(a, d) : zone d’étude de la Nouvelle-Écosse; (b, e) : zone d’étude NO-SE; (c, f) : zone d'étude EW.
Les zones ayant une plus grande influence climatique sont en bleu, et les zones ayant une plus grande influence de la pente sont en rouge.
Précipitations annuelles moyennes (MAP), nombre d'événements pluviométriques extrêmes (NEE), exposition (Asp), altitude (Elev), courbure moyenne (CurvM), relief local (Relief).
L'astérisque * indique la multiplication algébrique de deux caractéristiques.
Comme le montre la figure df ci-dessus, dans les régions NS, NO-SE et EW,Les emplacements d'environ 74%, 54% et 54%, respectivement, sont plus affectés par les caractéristiques climatiques (telles que le nombre d'événements pluvieux extrêmes, les précipitations annuelles moyennes et l'exposition) que par le gradient de pente, comme le montre la zone bleue plus grande que la zone rouge, indiquant l'importance des caractéristiques climatiques dans le contrôle des glissements de terrain dans l'Himalaya le plus oriental.À mesure que les taux de précipitations augmentent progressivement vers l’est le long de l’Himalaya, les changements climatiques verticaux sont importants dans l’est de l’Himalaya. Ce gradient climatique est susceptible d’influencer la susceptibilité aux glissements de terrain dans l’est de l’Himalaya.
Adresse GitHub du code SNN :
https://GitHub.com/geosnn/geosnn.git
SNN relève les défis de la prévision des glissements de terrain
Les auteurs de l'étude, Louis Bouchard et Seulgi Moon, sont tous deux professeurs associés à l'UCLA, Khalid Youssef est chercheur postdoctoral à l'UCLA et Kevin Shao est doctorant en sciences de la terre, des planètes et de l'espace à l'UCLA.

Figure 8 : De gauche à droite : Louis Bouchard, Seulgi Moon, Khalid Youssef, Kevin Shao
Kevin Shao parle de « Les réseaux neuronaux profonds (DNN) peuvent fournir des estimations précises de la probabilité de glissements de terrain, mais ils ne peuvent pas déterminer quelles variables spécifiques provoqueront des glissements de terrain et pourquoi. »Le co-premier auteur Khalid Youssef a déclaré Le problème est que les différentes couches d'un DNN s'influencent constamment mutuellement pendant le processus d'apprentissage, ce qui rend impossible une analyse précise de leurs résultats. Cette recherche espère pouvoir séparer clairement les résultats des différentes données d'entrée, ce qui permettra de mieux identifier les facteurs les plus importants affectant les catastrophes naturelles.
Tout comme une autopsie permet de déterminer la cause d'un décès, l'identification du déclencheur exact d'un glissement de terrain nécessite toujours des mesures sur le terrain et des relevés historiques des conditions pédologiques, hydrologiques et climatiques, comme la quantité et l'intensité des précipitations, difficiles à obtenir dans des régions reculées comme l'Himalaya. Cependant, les réseaux de neurones profonds permettent d'identifier des variables clés et de quantifier leur contribution à la vulnérabilité aux glissements de terrain. Le professeur Seulgi Moon a déclaré. Louis Bouchard a dit « Contrairement aux DNN, qui nécessitent des serveurs informatiques puissants pour être entraînés, les SNN sont suffisamment petits pour fonctionner sur une Apple Watch. »
Les chercheurs prévoient d’étendre leurs travaux à d’autres régions du monde sujettes aux glissements de terrain, comme la Californie.En Californie, où les fréquents incendies de forêt et les tremblements de terre ont accru le risque de glissements de terrain, les SNN pourraient aider à développer des systèmes d’alerte précoce qui prennent en compte plusieurs signaux et prédisent une gamme d’autres dangers de surface.
Articles de référence :
[1]https://phys.org/news/2023-06-geologists-artificial-intelligence-landslides.html
[2]https://newsroom.ucla.edu/releases/artificial-intelligence-can-predict-landslides
[3]https://www.bccn3.com/news/ucla-geologists-develop-ai-model-to-predict-landslides
[4]https://static-content.springer.com/esm/
art10.1038s43247-023-00806-5/MediaObjects/43247_2023_806_MOESM1_ESM.pdf
Cet article a été publié pour la première fois sur la plateforme publique HyperAI WeChat~








