Command Palette
Search for a command to run...
Sélectionné Pour NeurIPS 2025, Le Zhiyuan, l'Université De Pékin Et l'Université Des Postes Et Télécommunications De Pékin Ont Proposé Un Cadre De Génération Vidéo À Contrôle multi-flux Qui Permet Une Synchronisation audio-visuelle Précise Basée Sur Le Démixage audio.

Comparativement au texte, l'audio possède intrinsèquement une structure temporelle continue et une riche information dynamique, permettant un contrôle temporel plus précis pour la génération vidéo. De ce fait, avec le développement des modèles de génération vidéo, la génération vidéo pilotée par l'audio est progressivement devenue un axe de recherche important dans le domaine de la génération multimodale. Actuellement, les recherches connexes couvrent de multiples scénarios tels que l'animation du locuteur, la vidéo synchronisée avec la musique et la génération de synchronisation audio-visuelle ; cependant, obtenir un alignement audio-visuel stable et précis dans un contenu vidéo complexe demeure un défi majeur.
La principale limite des méthodes existantes réside dans la modélisation des signaux audio. La plupart des modèles intègrent le signal audio d'entrée comme une condition globale au processus de génération, sans distinguer visuellement les rôles fonctionnels des différents composants audio tels que la parole, les effets sonores et la musique. Cette approche simplifie la modélisation dans une certaine mesure.Cependant, cela brouille également la correspondance entre l'audio et le visuel, rendant difficile le respect simultané des exigences de synchronisation labiale, d'alignement temporel des événements et de contrôle global de l'ambiance visuelle.
Pour résoudre ce problème,L'Académie d'intelligence artificielle de Pékin, l'Université de Pékin et l'Université des postes et télécommunications de Pékin ont conjointement proposé un cadre pour la génération de vidéos synchronisées audio-visuelles basé sur le démixage audio.Le signal audio d'entrée est divisé en trois pistes : parole, effets sonores et musique, chacune servant à piloter différents niveaux de génération visuelle. Ce système, grâce à un réseau de contrôle temporel multi-flux et à un ensemble de données et une stratégie d'entraînement adaptés, permet d'obtenir une correspondance audio-visuelle plus précise aux niveaux temporel et global. Les données expérimentales montrent que cette méthode améliore durablement la qualité vidéo, l'alignement audio-visuel et la synchronisation labiale, validant ainsi l'efficacité du démixage audio et du contrôle multi-flux pour les tâches complexes de génération vidéo.
Les résultats de recherche associés, intitulés « Génération vidéo audio-synchronisée avec contrôle temporel multi-flux », ont été sélectionnés pour NeurIPS 2025.
Adresse du document :
https://arxiv.org/abs/2506.08003
Points saillants de la recherche :
* Nous construisons l'ensemble de données DEMIX, composé de cinq sous-ensembles qui se chevauchent pour la génération de vidéos synchronisées avec l'audio, et proposons une stratégie d'entraînement en plusieurs étapes pour apprendre les relations audiovisuelles.
Ce système propose un cadre MTV qui divise l'audio en trois pistes : parole, effets sonores et musique. Ces pistes contrôlent différents éléments visuels tels que les mouvements des lèvres, le rythme des événements et l'ambiance visuelle générale, permettant ainsi un contrôle sémantique plus précis.
* Concevoir un réseau de contrôle temporel multi-flux (MST-ControlNet) pour gérer simultanément la synchronisation fine des intervalles de temps locaux et l'ajustement global du style au sein du même cadre de génération, prenant en charge structurellement le contrôle différencié des différents composants audio sur une échelle de temps.
Capacité de génération multifonctionnelle
MTV possède des capacités de génération multifonctionnelles, telles que des récits centrés sur les personnages, des interactions entre plusieurs personnages, des événements déclenchés par le son, une ambiance créée par la musique et des mouvements de caméra.
L'ensemble de données DEMIX introduit des annotations de pistes démixées pour permettre un entraînement par phases.
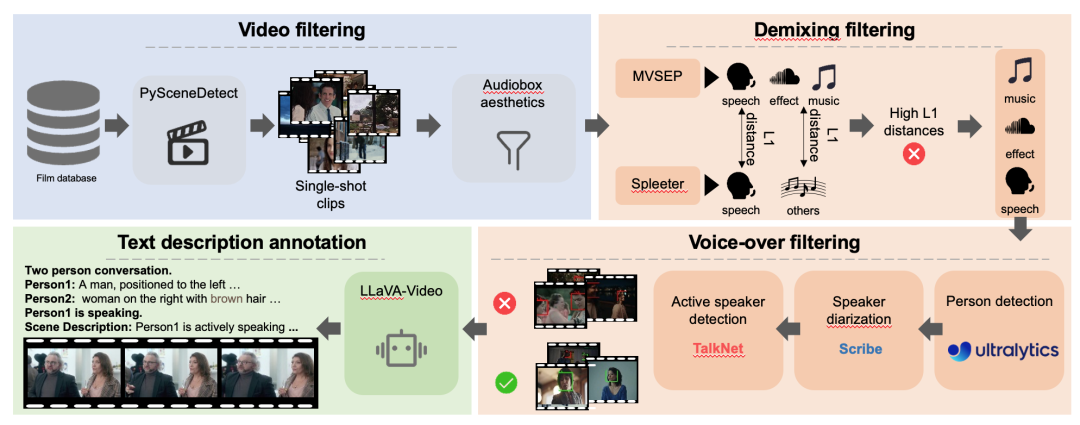
Cet article commence par obtenir l'ensemble de données DEMIX grâce à un processus de filtrage détaillé. Les données DEMIX filtrées sont ensuite structurées en cinq sous-ensembles qui se chevauchent :Caractéristiques faciales de base, effets individuels, effets multi-personnages, effets sonores d'événements et ambiance. Basé sur cinq sous-ensembles qui se chevauchent.Cet article présente une stratégie de formation en plusieurs étapes.Le modèle est progressivement complexifié. Dans un premier temps, il est entraîné sur un sous-ensemble facial de base pour apprendre les mouvements des lèvres ; puis, il apprend la pose humaine, l’apparence de la scène et les mouvements de caméra sur un sous-ensemble d’une seule personne ; ensuite, il est entraîné sur un sous-ensemble de plusieurs personnes pour gérer des scènes complexes avec plusieurs locuteurs ; puis, l’entraînement se concentre sur la chronologie des événements, et la compréhension du sujet est étendue des humains aux objets grâce à un sous-ensemble d’effets sonores d’événements ; enfin, le modèle est entraîné sur un sous-ensemble d’ambiance sonore pour améliorer sa représentation des émotions visuelles.
Grâce à un mécanisme de contrôle de synchronisation multi-flux, un mappage audiovisuel précis et un alignement temporel exact sont obtenus.
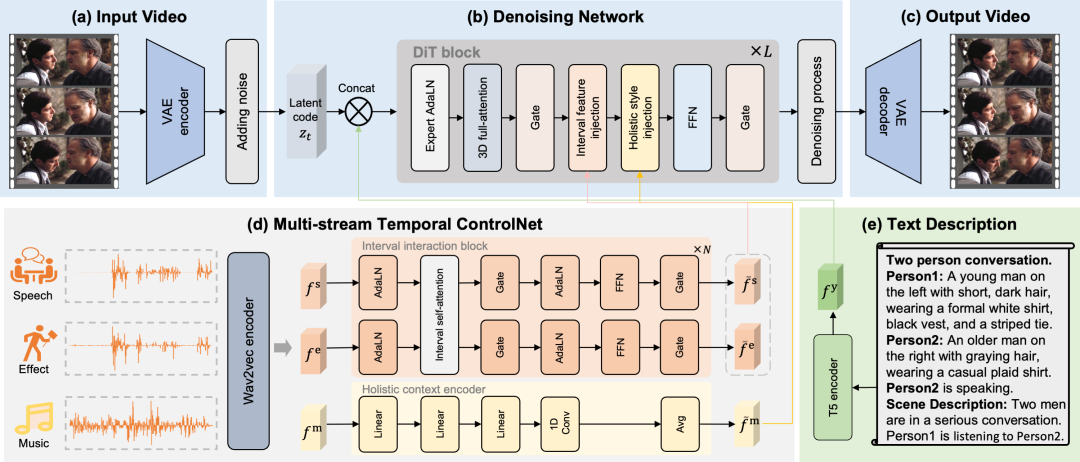
Cet article divise explicitement l'audio en trois pistes de contrôle distinctes : la parole, les effets sonores et la musique.Ces pistes distinctes permettent au cadre MTV de contrôler précisément les mouvements des lèvres, le timing des événements et les émotions visuelles, résolvant ainsi le problème des correspondances ambiguës. Afin de rendre le cadre MTV compatible avec diverses tâches, cet article propose un modèle pour la construction de la description textuelle. Ce modèle commence par une phrase indiquant le nombre de participants, par exemple « Conversation à deux ». Il liste ensuite chaque personne, en commençant par un identifiant unique (Personne1, Personne2) et en décrivant brièvement son apparence. Après avoir listé les participants, le modèle identifie explicitement la personne qui parle. Enfin, une phrase fournit une description générale de la scène. Pour obtenir un alignement temporel précis, cet article propose un réseau de contrôle temporel multi-flux qui gère les mouvements des lèvres, le timing des événements et les émotions visuelles grâce à des pistes vocales, d'effets et musicales explicitement séparées.
Injection de caractéristiques d'intervalle
Concernant les fonctionnalités vocales et sonoresCet article décrit un flux d'intervalles permettant de contrôler avec précision les mouvements des lèvres et le timing des événements.Les caractéristiques de chaque piste audio sont extraites par le module d'interaction d'intervalles, et l'interaction entre la parole et les effets sonores est simulée par le mécanisme d'auto-attention. Enfin, les caractéristiques interactives de la parole et des effets sonores sont injectées dans chaque intervalle temporel par attention croisée, un mécanisme appelé injection de caractéristiques d'intervalles.
Injection de fonctionnalités globales
Concernant les caractéristiques musicales,Cet article propose un schéma global pour contrôler l'émotion visuelle de l'ensemble du segment vidéo.Les caractéristiques musicales étant l'expression d'une esthétique globale, l'émotion visuelle générale est d'abord extraite de la musique grâce à un encodeur de contexte global, puis un regroupement moyen est appliqué pour obtenir les caractéristiques globales de l'ensemble du segment. Enfin, ces caractéristiques globales servent d'embeddings, et le code latent vidéo est modulé par AdaLN ; ce mécanisme est appelé injection de caractéristiques globales.
Générer avec précision une vidéo synchronisée audio de qualité cinématographique.
Indicateurs d'évaluation complète
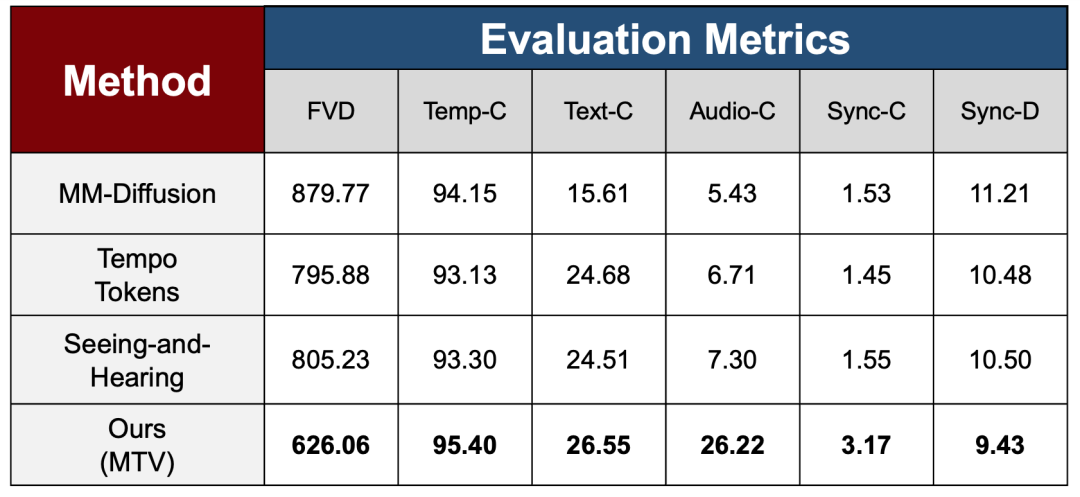
Pour vérifier l'efficacité de la stratégie d'entraînement multi-étapes dans différentes phases d'apprentissage, l'article utilise un ensemble de métriques d'évaluation complètes couvrant la qualité vidéo, la cohérence temporelle et la capacité d'alignement multimodal dans la section expérimentale afin d'évaluer systématiquement la stabilité globale et les performances de cohérence du modèle après l'introduction progressive de signaux de contrôle complexes, et le compare à trois méthodes de pointe.
Concernant la qualité de génération et la stabilité temporelle, l'étude utilise le FVD pour mesurer la différence de distribution entre les vidéos générées et les vidéos réelles, et le Temp-C pour évaluer la continuité temporelle entre les images adjacentes. Les résultats montrent que MTV surpasse significativement les méthodes existantes en termes de FVD, indiquant que le modèle ne sacrifie pas la qualité globale de génération tout en maintenant une stabilité temporelle élevée sur Temp-C, même avec l'introduction d'un contrôle audio plus complexe.
Au niveau de l'alignement multimodal, l'étude mesure la cohérence entre la vidéo et le texte/l'audio à l'aide des métriques Text-C et Audio-C, respectivement. MTV a démontré une amélioration significative de la métrique Audio-C, surpassant largement les méthodes de comparaison, ce qui témoigne de l'efficacité du démixage audio et des mécanismes de contrôle multiflux pour renforcer la correspondance audiovisuelle.
Pour résoudre les problèmes clés dans les scénarios pilotés par la voix, cet article introduit deux métriques de synchronisation, Sync-C et Sync-D, pour évaluer respectivement la confiance de la synchronisation et l'ampleur de l'erreur, et permet d'obtenir des performances optimales.
Résultats de comparaison

Comme le montre la figure ci-dessus, les chercheurs ont comparé le cadre MTV aux résultats les plus récents. D'un point de vue visuel, les méthodes existantes souffrent généralement d'une stabilité insuffisante face à des descriptions textuelles complexes ou des scènes cinématographiques.
Par exemple, même après un réglage fin de MM-Diffusion sur plus de 320 000 étapes sur huit GPU NVIDIA A100 à l'aide du code officiel, cette méthode peine encore à générer des images visuellement cohérentes et structurées narrativement, le style général tendant vers un assemblage de fragments. TempoTokens, quant à lui, a tendance à produire des expressions faciales et des mouvements artificiels dans les scènes complexes, notamment dans les scénarios à plusieurs personnages ou à grande gamme dynamique, ce qui nuit considérablement au réalisme des résultats. Concernant la synchronisation audio-visuelle, la méthode de Xing et al. peine à synchroniser l'audio pour certaines séquences d'événements, ce qui entraîne des erreurs de rendu dans les gestes des personnages lorsqu'ils jouent de la guitare (comme illustré à droite de l'image ci-dessus).
En revanche, le framework MTV peut maintenir une haute qualité visuelle et une synchronisation audio-visuelle stable dans divers scénarios, et peut générer avec précision des vidéos synchronisées audio avec une qualité cinématographique.
Liens de référence :
1.https://arxiv.org/abs/2506.08003








