Command Palette
Search for a command to run...
6 Ensembles De Données d'apprentissage Automatique Classiques, Votés Par Plus De 3 semaines d'utilisateurs, Recommandés Pour La Collecte

Aperçu du contenu : Ce numéro résume 6 ensembles de données avec le plus grand nombre de téléchargements de super neurones, couvrant des domaines tels que la reconnaissance d'images, la traduction automatique et l'imagerie par télédétection. Ces ensembles de données sont de haute qualité et de grand volume, et méritent d’être collectés et conservés en raison de leur certification de popularité. Mots-clés : Ensemble de données, Traduction automatique, Vision artificielle
Les ensembles de données constituent la base de la formation des modèles d’apprentissage automatique. Des ensembles de données publiques de haute qualité sont d’une grande importance pour les effets de formation des modèles et la fiabilité des résultats de recherche.
Depuis son lancement, HyperAI a fourni un grand nombre d’ensembles de données publiques de haute qualité aux praticiens de la science des données.Dans ce numéro, nous avons sélectionné 6 ensembles de données populaires.Son nombre total de téléchargements a atteint 32 569 fois.J'espère que ces ensembles de données pourront servir davantage les développeurs~
Remarque : les ensembles de données triés dans cet article proviennent tous du site Web :
N° 6 : Ensemble de données de reconstruction 3D du temple des chars
Agence d'édition :Intel Labs
Quantité incluse :Vidéo HD de 21 types d'objets
Type de données :vidéo
Taille estimée :52,53 Go
Heure de sortie :2017
Adresse de téléchargement :hyper.ai/datasets/5148

L'ensemble de données d'images du temple Tanks fournit des vidéos haute résolution à partir desquelles les chercheurs peuvent collecter des images.Effectuer une reconstruction tridimensionnelle à partir de l'image.L'ensemble de données comprend deux catégories : les données d'entraînement et les données de test, où les données de test sont divisées en groupe intermédiaire et groupe avancé.
N° 5 : Ensemble de données d'images aériennes DOTA
Agence d'édition :Université de Wuhan
Quantité incluse :2 806 images aériennes
Type de données :images
Taille estimée :35,38 Go
Heure de sortie :2017
Adresse de téléchargement :hyper.ai/datasets/4920

DOTA signifie « ensemble de données à grande échelle pour la détection d'objets dans les images aériennes ». Il s’agit d’un ensemble de données d’images contenant 2 806 images aériennes.Il est utilisé pour la détection de cibles dans les images aériennes afin de trouver et d'évaluer les objets dans l'image.
Ces sources d’images incluent différents capteurs et plates-formes. La taille des pixels de chaque image varie de 800*800 à 4000*4000 et contient des objets d'échelles, d'orientations et de formes différentes.
Pour les versions précédentes, veuillez visiter :
Ensemble de données DOTA : 2 806 images de télédétection, près de 190 000 instances annotées
N° 4 : Ensemble de données de reconnaissance faciale VGG-Face2
Agence d'édition :Université d'Oxford
Quantité incluse :3,31 millions d'images
Type de données :images
Taille estimée :37,49 Go
Heure de sortie :2015
Adresse de téléchargement :hyper.ai/datasets/5711

VGG-Face2 est un ensemble de données d'images de visage qui contient les données faciales de 9131 personnes au total. Les images proviennent toutes de la recherche d'images de Google.Les personnes figurant dans l’ensemble de données varient considérablement en termes de posture, d’âge, de race et de profession.Cet ensemble de données a été publié par le groupe de géométrie visuelle du département des sciences de l'ingénieur de l'université d'Oxford en 2015, et l'article associé est « Deep Face Recognition ».
N° 3 : Ensemble de données d'images de télédétection UCAS-AOD
Agence d'édition :Université de l'Académie chinoise des sciences
Quantité incluse :910 images
Type de données :images
Taille estimée :3,24 Go
Heure de sortie :2014
Adresse de téléchargement :hyper.ai/datasets/5419

UCAS-AOD est un ensemble de données d'images de télédétection.Pour l'inspection des aéronefs et des véhicules.Cet ensemble de données a été publié pour la première fois par l'Université des sciences et technologies de Chine en 2014 et complété en 2015. Les articles connexes incluent « Détection d'objets robuste à l'orientation dans les images aériennes à l'aide d'un réseau neuronal convolutionnel profond »
N° 2 : Ensemble de données de traduction automatique de bandes dessinées OpenMantra
Agence d'édition :Université de Tokyo
Quantité incluse :214 pages de bandes dessinées
Type de données :Fichiers JSON, images
Taille estimée :32,46 Mo
Heure de sortie :2020
Adresse de téléchargement :hyper.ai/datasets/14137
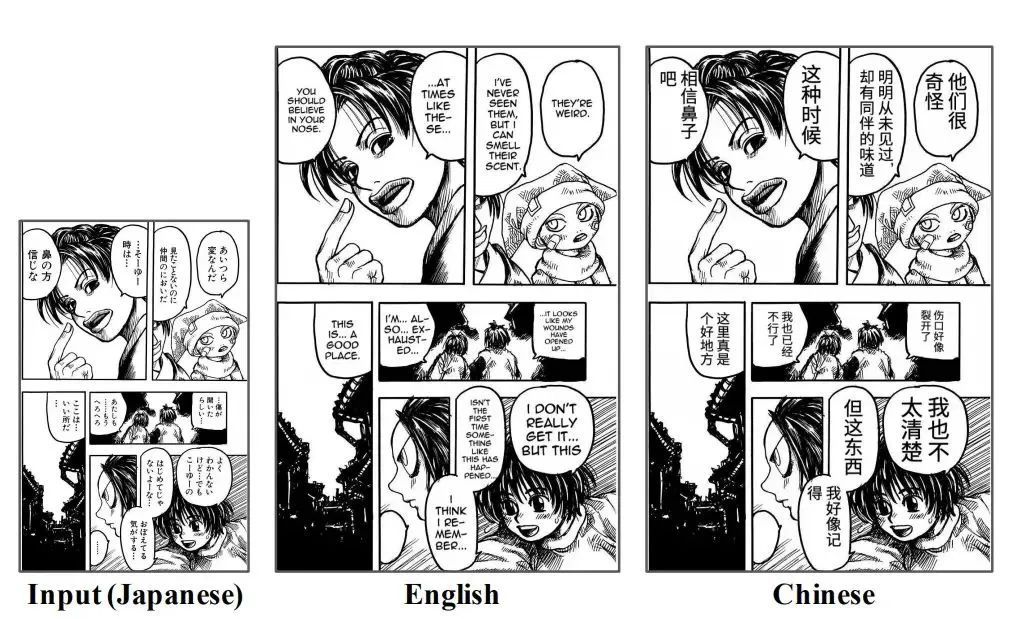
OpenMantra est un ensemble de données d'évaluation de traduction automatique pour les bandes dessinées japonaises, contenant des bandes dessinées dans cinq styles différents (fantastique, romance, bataille, mystère, tranche de vie).L'ensemble de données contient 1593 phrases, 848 scènes et 214 pages de bandes dessinées.Publié par Mantra Team, Université de Tokyo.
Pour les poussées précédentes, veuillez consulter :
HyperAI : traduction de bandes dessinées, IA Word intégrée, article de l'Université de Tokyo inclus dans AAAI'21 3 mentions J'aime · 1 commentaire
N° 1 : Ensemble de données de reconnaissance d'images ImageNet 10
Agence d'édition :Université de Princeton
Quantité incluse :15 millions d'images
Type de données :images
Taille estimée :860,55 Go
Heure de sortie :2009
Adresse de téléchargement :hyper.ai/datasets/4889

ImageNet est actuellement la plus grande base de données de reconnaissance d'images au monde, créée par le professeur Fei-Fei Li de l'Université de Stanford et d'autres.Principalement utilisé pour la classification d'images et la détection de cibles dans le domaine de la vision artificielle.
L'ensemble de données est organisé selon la hiérarchie WordNet, où chaque nœud (également appelé catégorie) se compose de centaines, voire de milliers d'images. L'ensemble de données contient un total de 22 000 catégories d'images et environ 15 millions d'images.
Pour les versions précédentes, veuillez visiter :
Cette décision a fait de Fei-Fei Li la reine de l'industrie de l'IA. mp.weixin.qq.com/s/VyKUmG512pFJ3XTgVf4Qjg
Les éléments ci-dessus sont les 6 ensembles de données hyper.ai fréquemment téléchargés et recommandés dans ce numéro. Pour plus d’ensembles de données publiques de haute qualité pour la science des données, cliquez à la fin de l’article.Lire l'article original,Ou visitez le lien suivant pour télécharger :
Cet article a été publié pour la première fois sur le compte public WeChat « HyperAI Super Neural Network »6 ensembles de données d'apprentissage automatique classiques, votés par plus de 3 semaines d'utilisateurs, recommandés pour la collecte』
-- sur--








