Command Palette
Search for a command to run...
Google's Global Flood Forecasting System Has Been Upgraded to Version 2, Extending Reliable Forecast Duration by 6 Days and Significantly Improving accuracy.

Floods are among the most widespread and devastating natural disasters globally. The accuracy of river runoff prediction and the timely issuance of flood warnings directly impact a river basin's disaster prevention and mitigation capabilities, ecological security, and the stability of its socio-economic operations. For this reason, hydrology has long considered "how to more accurately predict floods" as one of its core issues.
Over the past few decades, machine learning has undergone continuous evolution in the fields of hydrological simulation and flood forecasting. Early research mainly focused on conceptual rainfall-runoff models.These methods have played an important role in "data-free watersheds" where observational data is scarce and there are few field measurement stations.With the increase in data scale and computing power, the research focus has gradually shifted from simply improving prediction accuracy to more complex directions such as model interpretability, uncertainty quantification, data assimilation, and the integration of mechanistic models with deep learning, driving hydrological forecasting into a new stage driven by the synergy of "data + mechanism".
Against this backdrop, Google Research recently deployed a business-validated machine learning hydrological model on a large scale to the global flood forecasting system.Its second version (v2) of the global flood forecasting system has been officially launched and has become the core engine of Google FloodHub's river forecasting module.Compared to the first version, v2 proposes systematic improvements to address three key long-standing issues hindering operational deployment: insufficient training data, limited time series length, and input data distribution bias. These improvements significantly enhance the stability and reliability of global-scale runoff forecasts.
However, moving from "model effectiveness" to "community reproducibility and scalability" requires addressing issues such as algorithm transparency and data openness. With this in mind, the research team, along with releasing the v2 system, also publicly disclosed key implementation details of the development process and the challenges currently faced.They also launched the Google Runoff Reanalysis and Reforecasting Dataset (GRRR).This dataset covers more than one million river stations worldwide and includes decades of historical simulation and re-forecast results, providing an important data foundation for subsequent methodological research and model iteration.
The relevant datasets are available online:
The related research findings, titled "Extending Medium-Range Global Flood Forecasts: The Google Global Flood Forecasting Model Version 2", have been published in EGUsphere.
Research highlights:
* Introduced the second version of the Global Flood Forecasting System, significantly improving the effective duration of reliable forecasts.
* In 1,223 test basins worldwide, the second version of the integrated forecast demonstrated superior accuracy compared to the first version and two third-party baseline models.
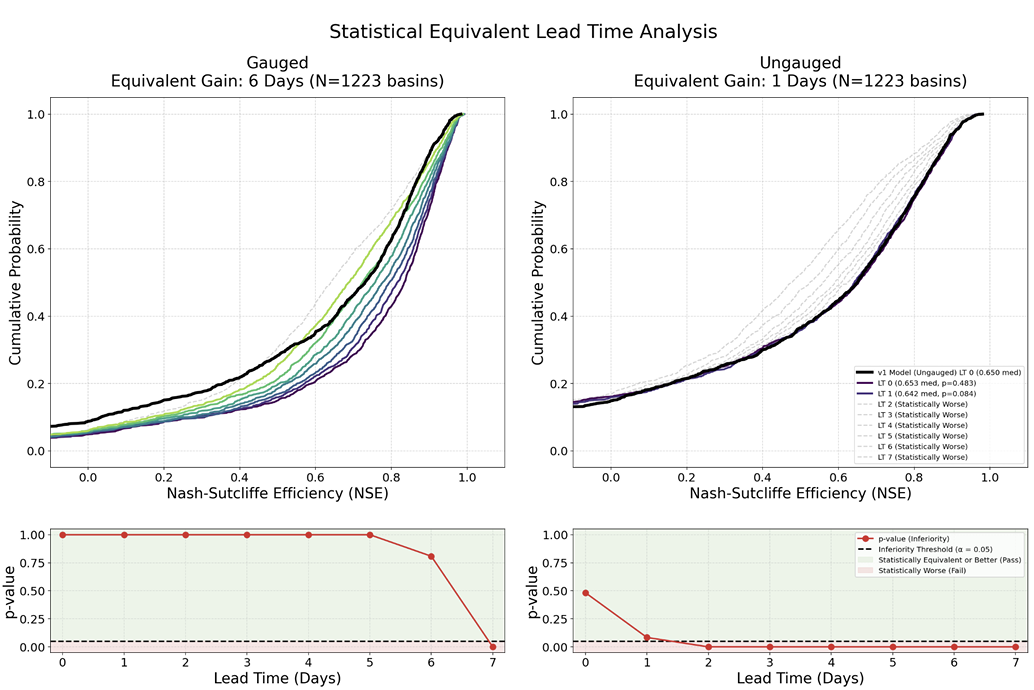
* Using NSE as the evaluation metric: Compared to the first version of the live forecast, the second version extends the reliable forecast duration by 6 days in watersheds with actual observation stations and by 1 day in watersheds without actual observation stations.

View the paper:
https://egusphere.copernicus.org/preprints/2026/egusphere-2026-2283/
Datasets: Static Attributes, Dynamic Drivers, and Runoff Observations
The core task of river forecasting models is to predict the average daily runoff at the outlet of each basin.The model input mainly consists of three parts: static watershed attributes, dynamic meteorological driving data, and target runoff data.
Static watershed attributes are used to describe the long-term, stable, and time-invariant physical characteristics of a watershed.The study used a total of 92 spatial average attributes.The data is primarily derived from HydroATLAS and combined with ERA5-Land reanalysis data to calculate hydroclimatic statistics, covering various aspects such as topography, climate, land cover, soil, and human activities, including average elevation, aridity, precipitation seasonality, forest cover, soil hydraulic properties, and population density.
Dynamic meteorological data is used to characterize weather processes that trigger hydrological responses. Existing research has shown that multi-source meteorological data fusion can significantly improve the predictive power of LSTM-like models; therefore, the v2 system simultaneously integrates multiple global meteorological products, including the European Centre for Medium-Range Weather Forecasts (HRES), the National Oceanic and Atmospheric Administration (CPA) CPC, GraphCast, and the National Aeronautics and Space Administration (IMERG). Input variables cover key meteorological factors such as total precipitation and 2-meter temperature, and are uniformly aggregated into daily-scale data. Compared to single meteorological sources, this multi-source fusion approach can better mitigate error problems across different regions and time scales.
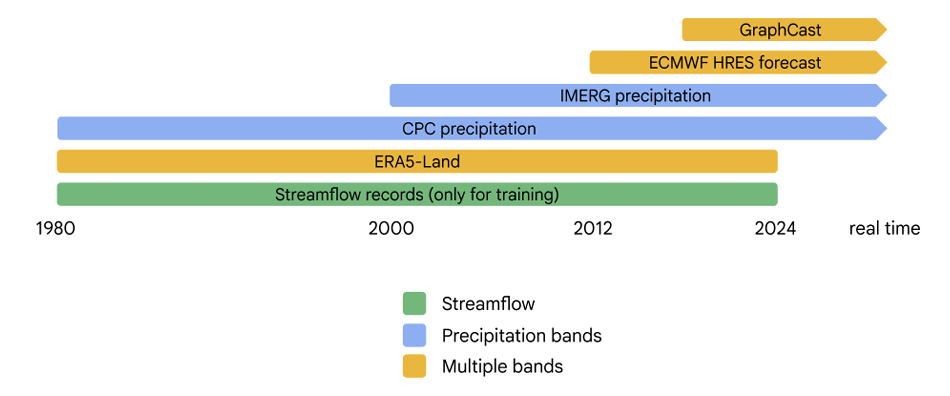
Temporal availability of dynamic input datasets and target runoff data
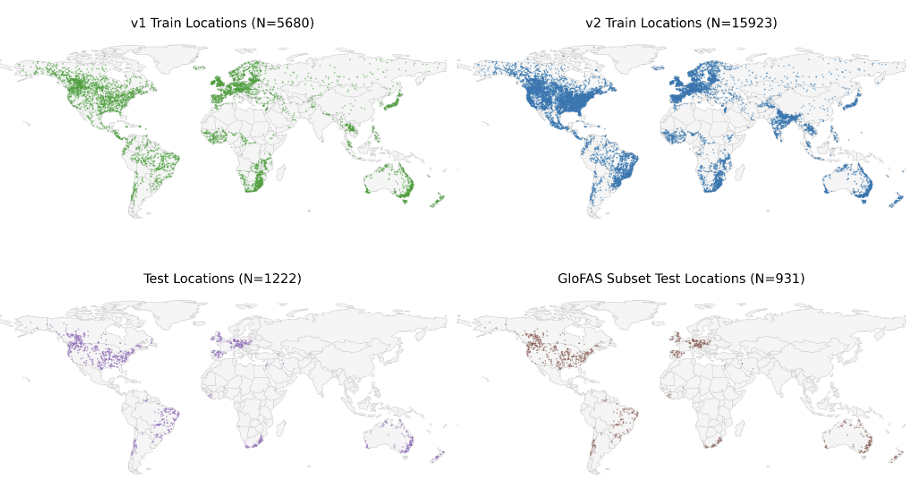
Regarding runoff data,The v2 system is trained using three datasets: Caravan, GRDC, and BANDAS.v1 relied solely on GRDC. To ensure comparability, the GRDC test sites used in v1 were fully retained in the v2 test set. As shown in the figure below, the expanded training samples cover different climate zones and hydrological environments globally, significantly enhancing spatial representativeness. Caravan itself is a large-sample open-source watershed dataset built on the CAMELS system, integrating data resources from multiple countries and research institutions.
The model distinguishes between two stages in business operations: "post-reporting" and "forecasting".The post-reporting phase primarily utilizes 0-day lead time data from HRES and GraphCast, while CPC and IMERG are excluded from future time-series forecasts due to their inability to provide real-time forecasts. Since the operational archives of HRES and GraphCast begin in 2012 and 2016 respectively, while ERA5-Land and runoff observations date back to 1980, the research team used ERA5-Land to fill in the missing early periods, maintaining consistency in long-term series training.
Architecture upgrade completely resolves the defect of sudden changes in forecast initialization.
The core of Google's second version of the global flood forecasting system is the mean-embedded long short-term memory network (ME-LSTM).Compared to the encoder-decoder LSTM (ED-LSTM) used in the first version, ME-LSTM is better suited for handling missing inputs and long-term time series forecasts, and it also solves the problem of prediction mutations that easily occur when switching between the post-report and forecast stages in v1.
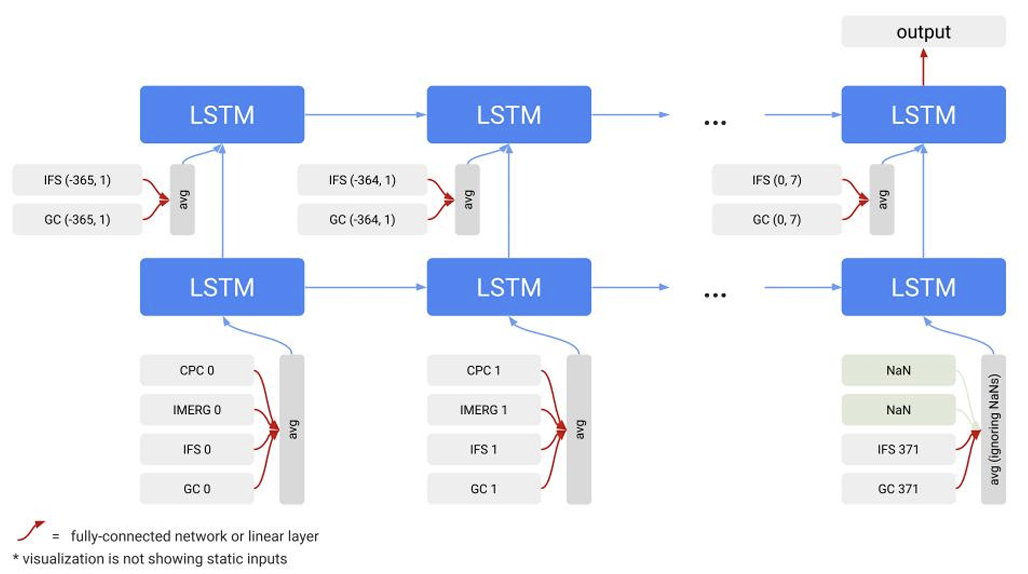
In v1, the post-evaluation and forecast are processed by two independent LSTMs. The hidden states and cell states output by the post-evaluation network are transformed by a small neural network and used to initialize the forecast network. The purpose of this design is to allow the post-evaluation and forecast stages to learn different data distributions, thereby mitigating the discrepancies between observed data, reanalysis data, and weather forecast data. However, in actual operational use…This structure can easily lead to instability in the initial forecast state, causing the model to prioritize adjusting its internal state rather than responding promptly to the actual hydrological process, thus resulting in discontinuous forecast results.
To address this issue, ME-LSTM no longer directly stitches together all meteorological inputs.Instead, each weather product is treated as an independent input source and mapped to a shared hidden space through a dedicated embedded network.Before embedding, static watershed attributes are concatenated with the corresponding dynamic inputs. Subsequently, the model automatically aggregates data from different sources using a masked mean mechanism, while ignoring missing inputs, thereby enhancing its robustness to missing data and input distribution shifts.
At the time series modeling levelME-LSTM uses two stacked LSTM layers to process the complete time series uniformly, eliminating the need for manually separating the forecast and prediction stages. Therefore, the model state can evolve continuously.This fundamentally eliminates the state transition problem in v1. The first LSTM layer is responsible for processing the complete input sequence and generating aggregated features, while the second LSTM layer uses these features to complete runoff prediction.
Both models employ a mixed density output layer to achieve probabilistic forecasting, outputting countable mixture asymmetric Laplace distribution (CMAL) parameters to characterize the uncertainty of future runoff. The deterministic results presented in this paper are derived from the mean of the predicted distribution.
For training, v2 uses the Adam optimizer and the CMAL likelihood loss function, and improves model robustness through strategies such as Gaussian noise injection, gradient pruning, and random input discarding. The design of randomly discarding some temporal input features enhances the model's ability to handle missing data in real-world business environments. The entire training process consists of 125 epochs to improve the model's generalization ability in complex global hydrological environments.
Enhanced temporal correlation leads to a significant improvement in the accuracy of the second version of the integrated forecast.
This study primarily evaluates the performance of the v2 system in two types of scenarios:One category is watersheds with actual measured hydrological stations, and the other is "data-free watersheds" that have no local measured data and can only rely on cross-watershed generalization capabilities for prediction. Compared to the randomized 10-fold cross-validation used in v1, v2 further uses independent test sets for evaluation, making the experiment closer to the real business deployment environment.
Because v2 not only updated the model architecture, but also expanded the training data and meteorological inputs,The research team also built a simplified version that removed the GraphCast input, for analyzing the contribution of AI weather forecast data separately.The experiment used the Nash-Satcliffe efficiency coefficient (NSE) and the Kling-Gupta efficiency coefficient (KGE) as core indicators. The former measures the overall fitting ability, while the latter analyzes the model performance from dimensions such as temporal consistency, water balance, and flow fluctuation. The test period covered 2016 to 2023.
Considering that the model requires a long historical sequence for initialization, researchers reserved a one-year isolation interval before and after the test year, and completely removed these intervals from the training set to avoid leakage of temporal information. Ultimately, a total of 1,222 shared test watersheds were selected for unified evaluation. Benchmarks included traditional operational models such as the Global Flood Awareness System (GloFAS) and the European Flood Awareness System (EFAS).
The results show thatv2 significantly outperforms v1 globally, across different forecast durations, and in both scenarios.Meanwhile, both generations of Google's models significantly outperform traditional business models. The upgraded model architecture and expanded training data primarily improved performance in watersheds with measured data points; while the gains from GraphCast were more pronounced in medium- and long-term forecasts, improving both measured and unmeasured scenarios. KGE decomposition results further indicate that this improvement mainly stems from enhanced capabilities in characterizing runoff temporal variations and flow fluctuations.
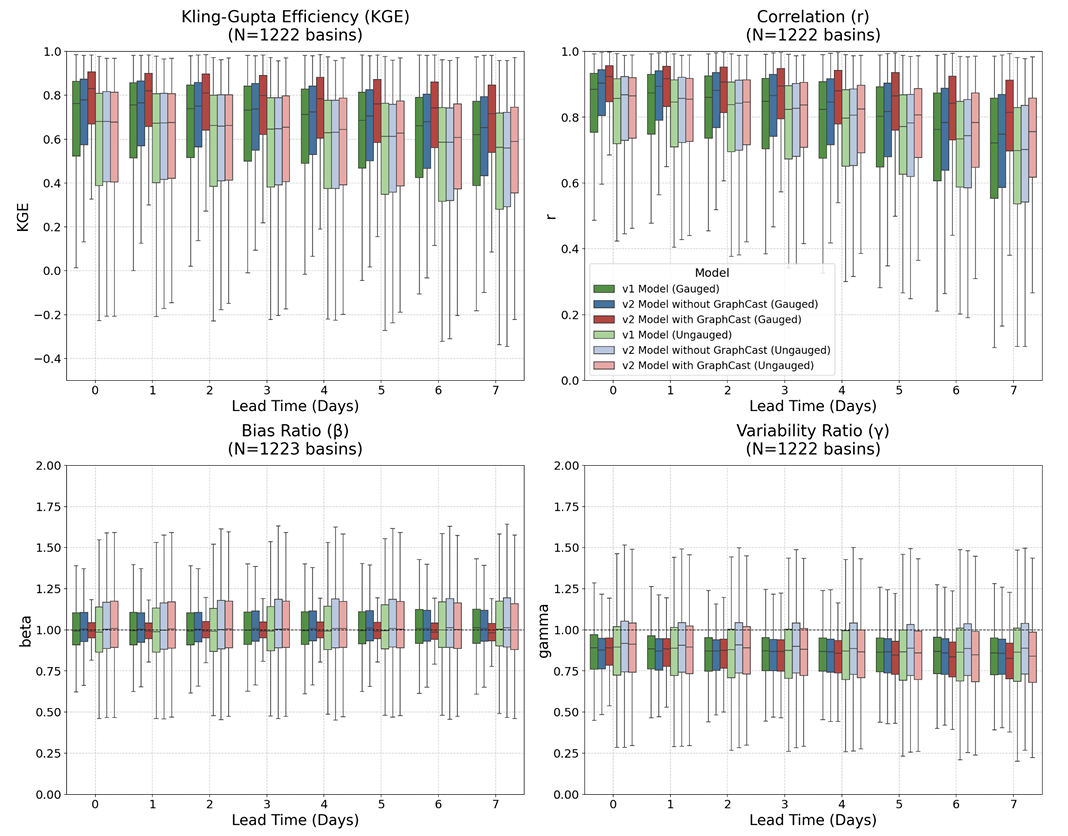
A typical result is that in watersheds with available measured data, the forecast accuracy of v2 on day 6 can reach or even exceed the real-time forecast level of v1; while in watersheds without measured data, the forecast lead time is only slightly extended. This also indicates that...Local observation data remains a key factor affecting model performance.
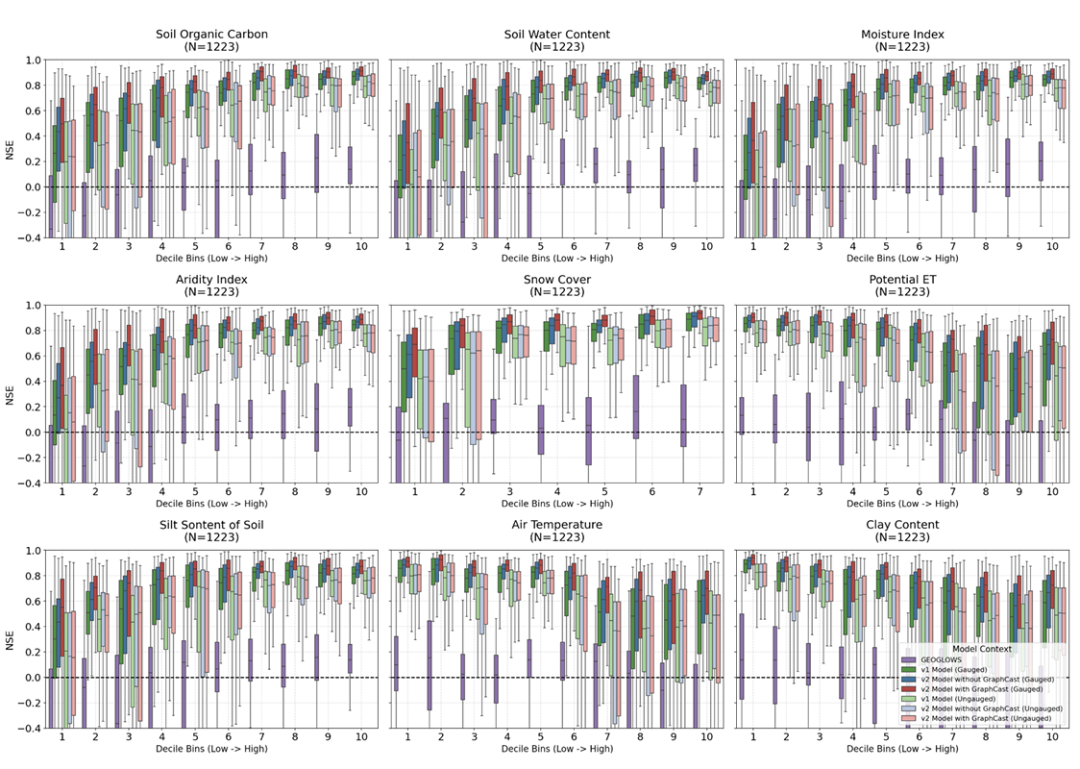
The study also found that the natural characteristics of a watershed significantly affect prediction accuracy. Generally, watersheds with high humidity, abundant snow cover, and good vegetation cover are more likely to produce stable predictions, while arid regions typically experience larger errors due to drastic runoff fluctuations. However, given measured data...The improvement of v2 is more pronounced in arid watersheds.In contrast, watersheds with numerous reservoirs and artificial control facilities showed limited improvement even after model upgrades, indicating that current deep learning models are still insufficient in characterizing complex human-controlled processes.
Final Thoughts
From model development and operational deployment to open-sourcing data and code, the v2 system reflects an increasingly clear trend in the field of machine learning hydrological modeling: the research goal is no longer just "improving accuracy by a few percentage points," but is beginning to place greater emphasis on the model's stability, generalization ability, and scalability in real and complex environments. Of course, the current system still has significant limitations. Arid watersheds, artificially regulated areas, and scenarios with no actual measurement stations remain challenges in global flood forecasting; the model's dependence on local observation data has not yet been truly eliminated.
This work demonstrates at least one point: when high-quality training data, multi-source meteorological information at a global scale, and a deep learning architecture designed for operational scenarios are combined, machine learning can support a truly global flood forecasting system. This is undoubtedly a significant and noteworthy development for future flood control and disaster reduction, water resource allocation, and extreme climate risk management.








