Command Palette
Search for a command to run...
Online Tutorial | GLM-Image: Accurately Understanding Instructions and Writing Correct Text Based on a Hybrid Architecture of Autoregressive + Diffusion Decoder

In the field of image generation, diffusion models have gradually become mainstream due to their stable training and strong generalization ability. However,When faced with "knowledge-intensive" scenarios such as posters, PPTs, and science infographics that require accurately conveying complex information,Traditional models have the drawback of being unable to simultaneously achieve both instruction comprehension and detailed characterization.Another long-standing problem is that the text in the generated images often has stroke errors or is difficult to recognize, which seriously affects its practical value.
Based on this,In January 2026, Zhipu, in collaboration with Huawei, open-sourced its next-generation image generation model, GLM-Image.The model was trained using the Ascend Atlas 800T A2 and the MindSpore AI framework.Its core feature is the adoption of an innovative hybrid architecture of "autoregressive + diffusion decoder" (9B autoregressive model + 7B DiT decoder).This combines the deep understanding capabilities of language models with the high-quality generation capabilities of diffusion models.
Furthermore, by improving the Tokenizer strategy, the model natively supports the generation of images with any scale from 1024×1024 to 2048×2048 without the need for retraining. The innovation of GLM-Image is also reflected in the following two aspects:
*Solve the text rendering problem:In authoritative evaluations such as CVTG-2K and LongText-Bench, its key metrics, including text accuracy, ranked first among open-source models, significantly improving the accuracy of text generation in images.
*Define high-performance, cost-effective applications:In API call mode, the cost of generating a single image is only 0.1 yuan, which is only 1/10 to 1/3 of the cost of mainstream closed-source models, providing a cost-effective option for commercial applications.
at present,The "GLM-Image Accurate Semantic High-Fidelity Image Generation Model" is now available on the HyperAI website (hyper.ai) in the tutorial section.Unleash your boundless creativity!
Online experience:https://go.hyper.ai/BSF7G
Effect example:

Demo Run
1. After entering the hyper.ai homepage, select "GLM-Image Precise Semantic High-Fidelity Image Generation Model", or select it from the "Tutorials" page. After the page redirects, click "Run this tutorial online".
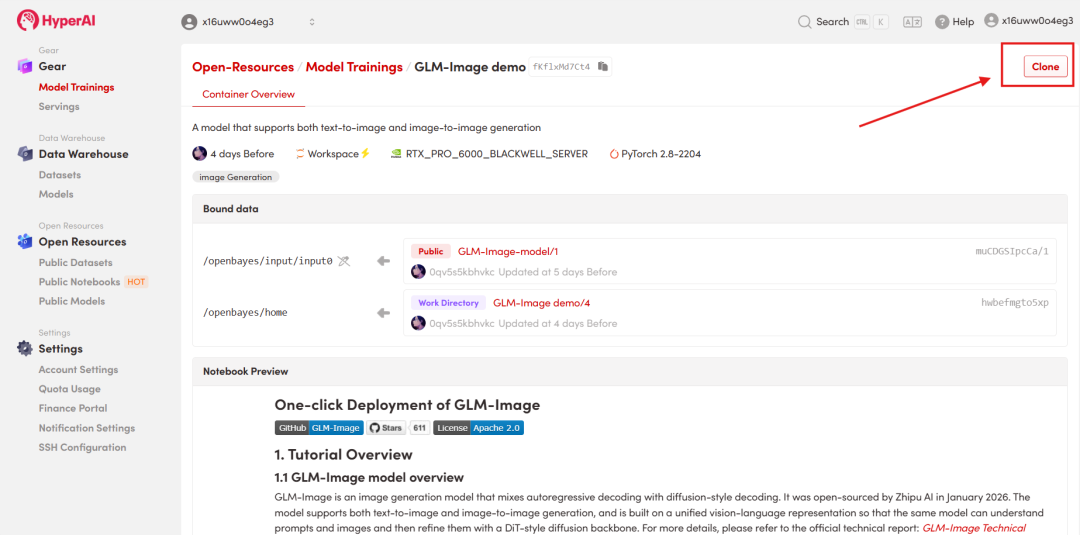
2. After the page jumps, click "Clone" in the upper right corner to clone the tutorial into your own container.
Note: You can switch languages in the upper right corner of the page. Currently, Chinese and English are available. This tutorial will show the steps in English.
3. Select the "NVIDIA RTX Pro 6000" and "PyTorch" images, and choose "Pay As You Go" or "Daily Plan/Weekly Plan/Monthly Plan" as needed, then click "Continue job execution".
HyperAI is offering a registration bonus for new users: for just $1, you can get 20 hours of RTX 5090 computing power (originally priced at $7), and the resources are valid indefinitely.


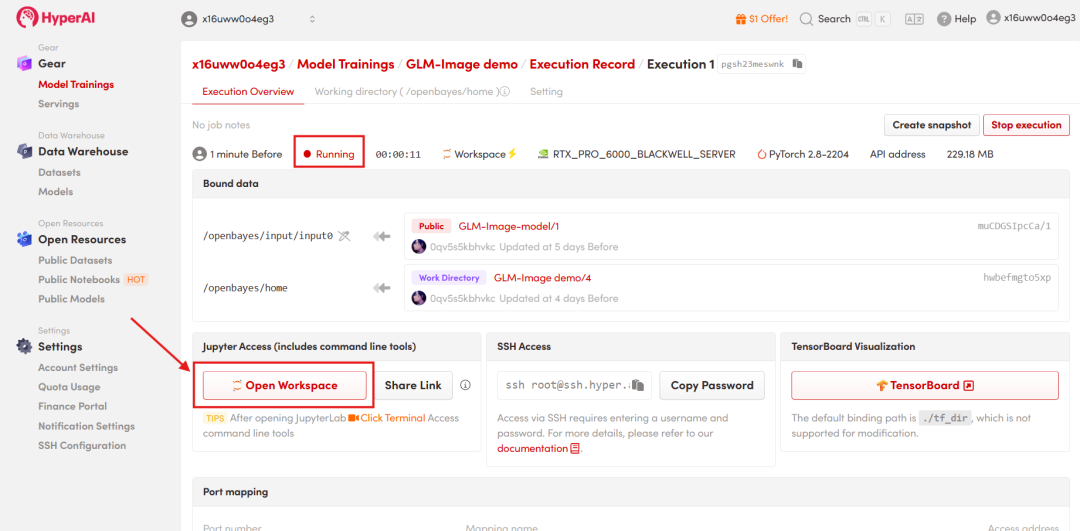
4. Wait for resources to be allocated. Once the status changes to "Running", click "Open Workspace" to enter the Jupyter Workspace.
Effect Demonstration
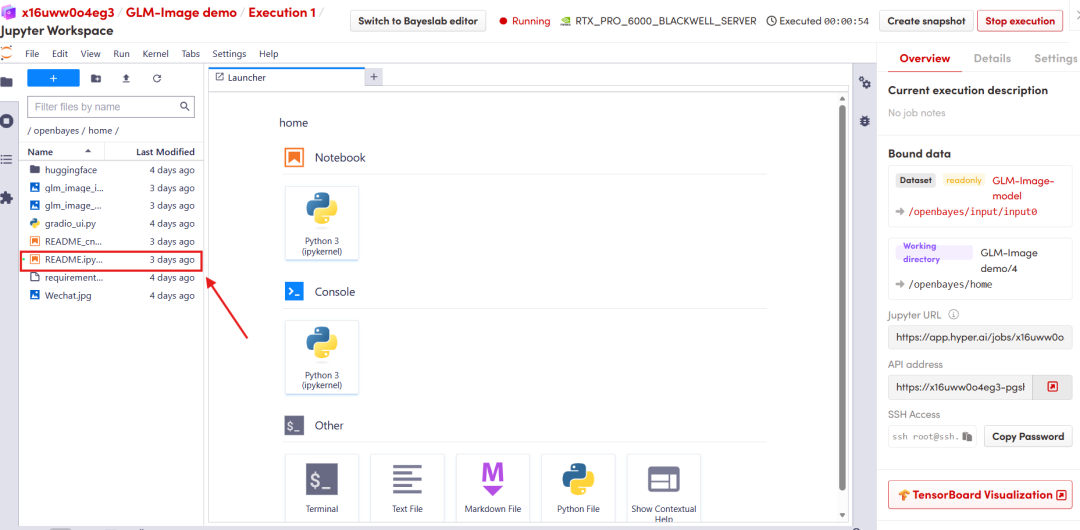
After the page redirects, click on the README page on the left, and then click Run at the top.
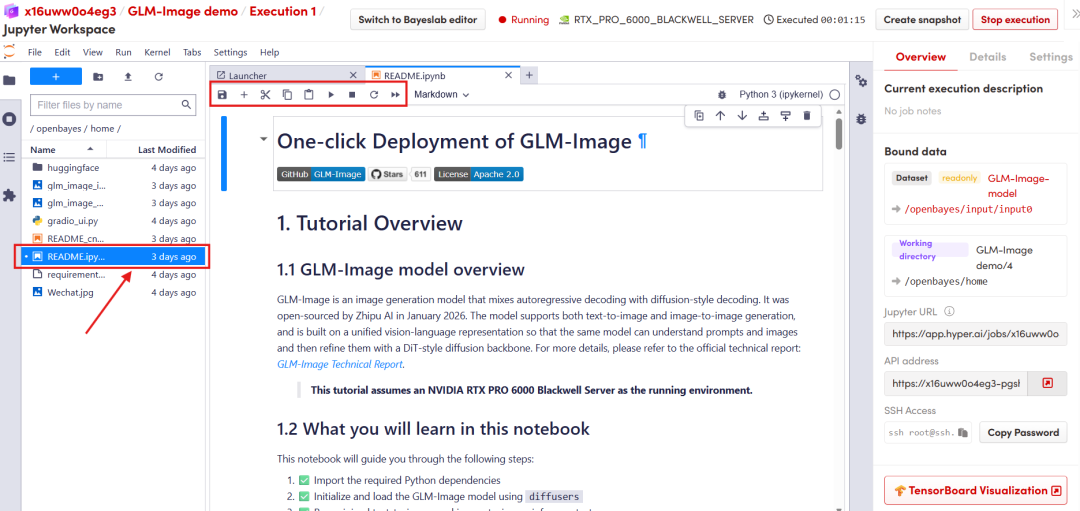
Once the process is complete, click the API address on the right to go to the demo page.
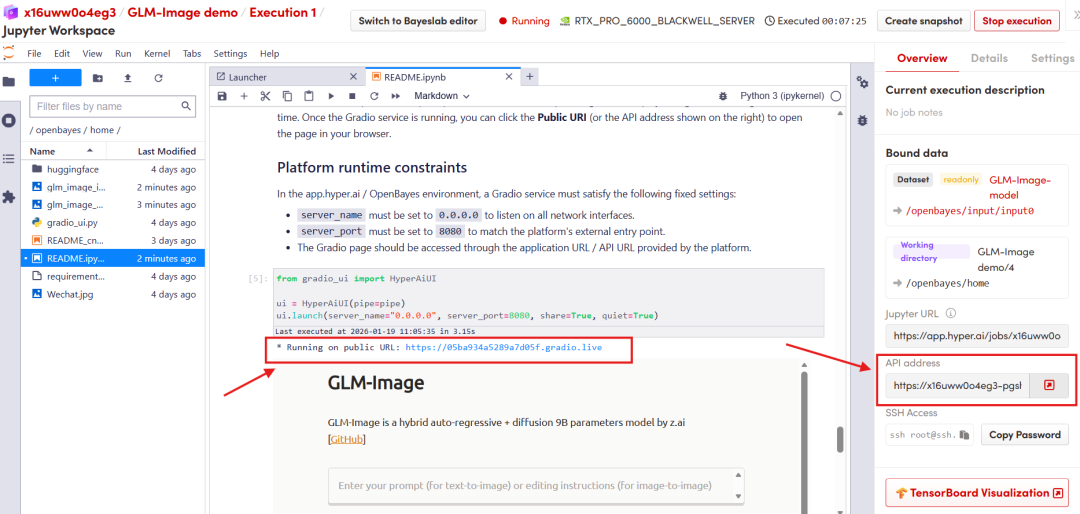

The above is the tutorial recommended by HyperAI this time. Everyone is welcome to come and experience it!
Tutorial Link:








