Command Palette
Search for a command to run...
GPT-5 Leads Across the Board; OpenAI Releases FrontierScience, Using a Dual Approach of "inference + Research" to Test the Capabilities of large-scale models.
As model reasoning and knowledge capabilities continue to improve, more challenging benchmark tests are crucial for measuring and predicting a model’s ability to accelerate scientific research. On December 16, 2025, OpenAI launched FrontierScience, a benchmark designed to measure expert-level scientific capabilities.According to preliminary evaluations, GPT-5.2 scored 25% and 77% on the FrontierScience-Olympiad and Research tasks, respectively, outperforming other cutting-edge models.
OpenAI stated in an official statement, "Accelerating scientific progress is one of the most promising opportunities for artificial intelligence to benefit humanity, so we are improving our models for complex mathematical and scientific tasks and working to develop tools that can help scientists make the most of these models."
Previous science benchmarks have mostly focused on multiple-choice questions, either with an overly dense question format or lacking a science-centric focus. In contrast, FrontierScience is written and validated by experts in physics, chemistry, and biology, unlike previous benchmarks.It includes both Olympic-style and research-based question types, enabling it to measure both scientific reasoning and scientific research abilities.In addition, FrontierScience-Research includes 60 original research sub-tasks designed by PhD scientists, with a level of difficulty comparable to what PhD scientists might encounter during their research.
Regarding the future and limitations of benchmarking, OpenAI stated in its official report, "FrontierScience has the limitation of a narrow scope and cannot cover all aspects of scientists' daily work. However, the field needs more challenging, more original, and more meaningful scientific benchmarks, and FrontierScience is a step in that direction."
The project's research findings have been published under the title "FrontierScience: evaluating AI's ability to perform expert-level scientific tasks".
Paper address:
https://hyper.ai/papers/7a783933efcc
More papers:
View more benchmarks:

The FrontierScience dataset enables a dual-track approach of "reasoning + research".
In this project, the research team constructed the FrontierScience evaluation dataset to systematically evaluate the capabilities of large models in expert-level scientific reasoning and research sub-tasks.The dataset adopts a design mechanism of "expert creation + two-level task structure + automatic scoring mechanism" to form a scientific reasoning evaluation benchmark that is challenging, scalable and reproducible.
Dataset address:
https://hyper.ai/datasets/47732
Based on the different task formats and evaluation objectives, the FrontierScience dataset is divided into two subsets, corresponding to two types of abilities: closed-ended exact reasoning and open-ended scientific reasoning.
* Olympiad dataset: Originally designed by medal winners and national team coaches of the International Physics, Chemistry and Biology Olympiads, with problem difficulty comparable to top international competitions such as IPhO, IChO and IBO; Focusing on short answer reasoning tasks, requiring models to output a single numerical value, algebraic expression or biological terminology that can be fuzzily matched, in order to ensure the verifiability of the results and the stability of automatic evaluation.
* Research Dataset: Constructed by PhD students, postdoctoral fellows, professors, and other active researchers, the questions simulate sub-problems that may be encountered in real scientific research, covering the three major fields of physics, chemistry, and biology. Each question is accompanied by a fine-grained score of 10 points to evaluate the model's performance in several key aspects, beyond just the correctness of the answer, including the completion of modeling assumptions, reasoning paths, and intermediate conclusions.
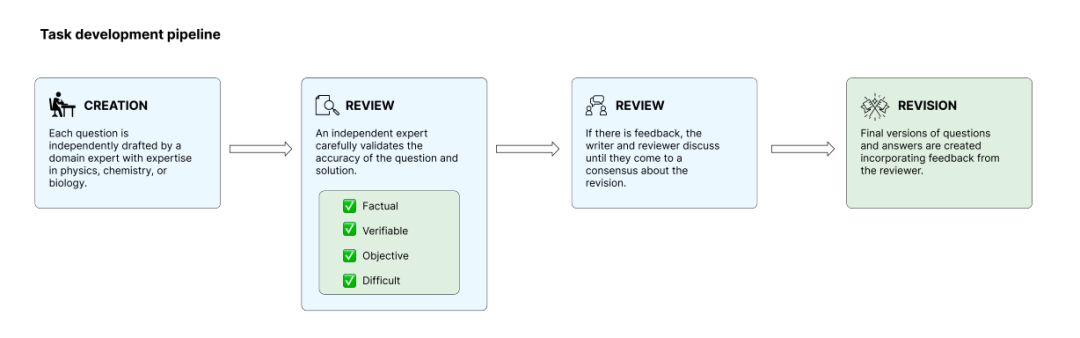
To ensure the originality and rigor of the questions, the research team screened the questions during the internal model testing phase, removing those that could be easily solved by existing models to reduce the risk of evaluation saturation. The training tasks undergo a total of four phases: creation, review, resolution, and revision. Independent experts review each other's tasks to ensure they meet the standards.Ultimately, the team selected 160 open-source questions from hundreds of candidate questions, while the remaining questions were kept as a reserve for subsequent pollution detection and long-term evaluation.
Independent subset sampling and other models like GPT-5.2 achieved impressive scores.
To stably and reproducibly evaluate the scientific reasoning ability of large models without relying on external retrieval, the research team designed a rigorous evaluation process and scoring mechanism.
This study selected several mainstream cutting-edge large models as evaluation objects, covering different institutions and technical approaches, in order to reflect the overall capability level of current general-purpose large models in the field of scientific reasoning as much as possible.All models were disabled from the internet during the evaluation process to ensure that their output was based solely on their internal knowledge and reasoning abilities, and was not influenced by real-time information retrieval or external tools.This reduces the interference of differences in information acquisition capabilities among different models on the results.
Considering the inherent randomness of large models in generative responses, the research team conducted statistical analysis by taking multiple independent samples and averaging the results from the two subsets, Olympiad and Research, to avoid random fluctuations.Regarding the scoring method, the paper designs automated evaluation strategies for the two types of tasks, taking into account their different characteristics:
* FrontierScience-Olympiad subset: Emphasizes closed-ended reasoning, with scoring primarily based on answer equivalence determination, allowing numerical approximations within a reasonable error range, equivalent transformations of algebraic expressions, and fuzzy matching of terms or names in biological questions, while avoiding oversensitivity to the form of expression;
* FrontierScience-Research subset: closely approximating real-world research sub-tasks, where each question breaks down the research reasoning process into multiple independent, verifiable key steps. The model's answers are scored item by item against rubrics, rather than solely based on the correctness of the final conclusion.
Overall, the FrontierScience benchmark shows a clear trend of performance differentiation in the two types of tasks.
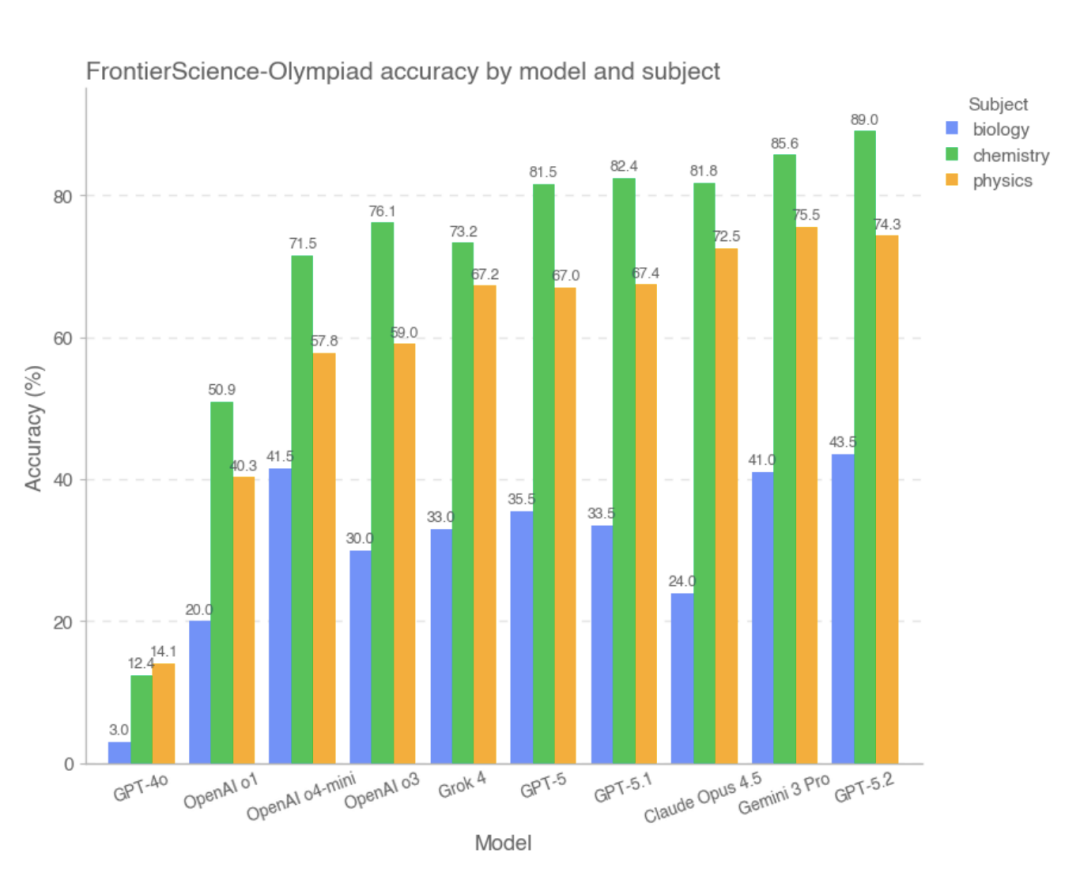
On the Olympiad subset, most cutting-edge models achieved high scores. Among them,The top three models with the best overall scores are GPT-5.2, Gemini 3 Pro, and Claude Opus 4.5, while GPT-4o and OpenAI-o1 performed relatively poorly.The study indicates that in this type of problem with clear conditions, relatively closed reasoning paths, and verifiable answers, most models have been able to stably complete complex calculations and logical deductions, and their overall performance is close to that of high-level human problem solvers.
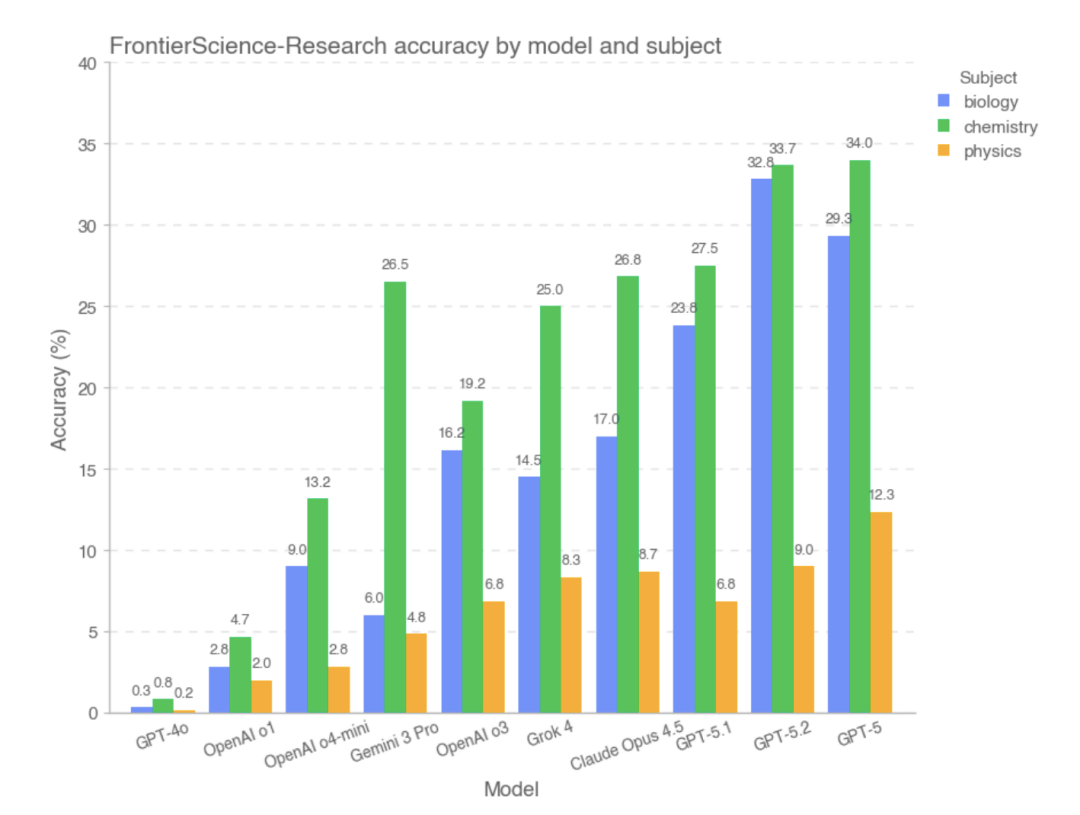
However, on the FrontierScience-Research subset, the model's overall score was significantly lower..In the Research subset, the model is more prone to bias during the decomposition of complex research problems.For example, there may be an incomplete understanding of the problem objective, improper handling of key variables or assumptions, or a gradual accumulation of logical errors within a long chain of reasoning. Compared to Olympiad-style problems, large-scale models still show a significant capability gap when faced with tasks that are more open-ended and closer to real-world research processes. Based on experimental data,The models that performed well in the Research section were GPT-5, GPT-5.2, and GPT-5.1.
This study also compared the accuracy performance of GPT-5.2 and OpenAI-o3 on the FrontierScience-Olympiad and FrontierScience-Research test sets under different inference intensities. The results show that...As the number of tokens used in testing increased, GPT-5.2's accuracy improved from 67.51 TP3T to 77.11 TP3T on the Olympiad dataset, and from 181 TP3T to 251 TP3T on the research dataset.It is worth noting that, on the research dataset, the o3 model actually performs slightly worse under high inference intensity than under medium inference intensity.
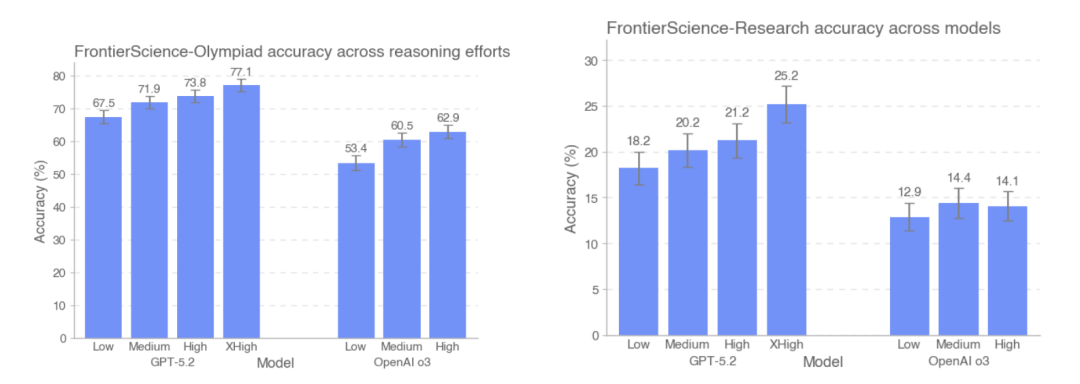
Based on the overall design and experimental results of FrontierScience,The large model has been able to perform stably in scientific problems with clear structures and closed conditions, and its performance on some tasks has approached the level of human experts.However, its capabilities remain significantly limited once it enters research sub-tasks that require continuous modeling, problem decomposition, and maintaining consistency in long-chain reasoning.
Beyond the correctness of the answer, large-scale models are ushering in a new standard of capability.
In its official explanation, OpenAI explicitly points out that FrontierScience does not cover all dimensions of scientists' daily work; its tasks are still primarily text-based reasoning and do not yet involve experimental operations, multimodal information, or real-world research collaboration processes. However, given the general saturation of existing scientific evaluation methods, FrontierScience offers a more challenging and diagnostically valuable assessment path: it not only focuses on the correctness of the model's answers but also begins to systematically measure whether the model possesses the ability to complete research sub-tasks. From this perspective, the value of FrontierScience lies not only in the leaderboard itself but also in providing a new benchmark for subsequent model improvement and scientific intelligence research. As model reasoning capabilities continue to evolve, this type of benchmark, emphasizing originality, expert participation, and process evaluation, may become an important window into whether artificial intelligence is truly moving towards the stage of research collaboration.
Reference Links:
1.https://cdn.openai.com/pdf/2fcd284c-b468-4c21-8ee0-7a783933efcc/frontierscience-paper.pdf
2.https://openai.com/index/frontierscience/
3.https://huggingface.co/datasets/openai/frontierscience








