Command Palette
Search for a command to run...
The Hong Kong University of Science and Technology Proposes a Fusion Neural Network Framework to Efficiently Predict multi-metal Binding Sites in Protein Sequences
Metal ions play an indispensable role in life. Zinc acts as a Lewis acid in hydrolase catalysis, iron is a key carrier of electron transport in the respiratory chain, and magnesium is essential for RNA to fold into a stable tertiary structure. Despite the accumulation of a large number of high-resolution metalloprotein structures in the Protein Data Bank, experimental identification of metal-protein interactions remains time-consuming, laborious, and costly.Therefore, computational prediction of metal binding sites based on the residue level has become an effective alternative strategy.
Existing methods for predicting multimetallic compounds are severely limited by their architecture, while structure-based predictors rely on computationally expensive programs, hindering their practical application. While protein language models have emerged as a promising prediction method, their substantial computational requirements and long inference times limit their practical application.
To address this issue, a research team from the Hong Kong University of Science and Technology proposed a fusion neural network framework to predict multi-metal binding sites in protein sequences.This framework employs a two-stage architecture, combining a convolutional neural network (CNN) with a fusion network. By introducing an imbalance-aware loss function, integrated evaluation, and a modular architecture, it effectively addresses the class imbalance between positive and negative samples of different metals and the complex interactions between them. Its structure-independent design enables fast, robust, and high-quality holistic predictions on large datasets without requiring structural input, significantly advancing the potential of metal-protein interaction mining.
The related research was published on bioRxiv under the title "A Modular Fusion Neural Network Approach to Efficiently Predict Multi-Metal Binding Sites in Protein Sequences."
Research highlights:
* A two-stage fusion neural network framework combining CNN and fusion network;
* By introducing a weighted binary cross entropy loss function, the class imbalance problem in metal binding site prediction is effectively handled.
Paper address:
Follow the official account and reply "Multi-metal binding sites" to get the full PDF
More AI frontier papers:
Building a stable and representative dataset
In order to construct a high-quality dataset suitable for training and evaluation, the research team performed secondary processing based on the existing MbPA database.First, a comprehensive dataset of metal-binding proteins was retrieved from the MbPA database. A total of 91,593 proteins capable of binding zinc (Zn), iron (Fe), and magnesium (Mg) were screened, retaining their verified binding site information and the corresponding metal ions. Building on this foundation, the research team further completed sequence normalization and integer encoding (uniform length of 500 amino acids), multi-label annotation of binding sites, stratified sampling (15% test set, 85% development set), and class imbalance treatment. The class imbalance treatment involved a three-stage pre-processing and independent training process to address class imbalance while simultaneously implementing metal-specific predictors. The implementation process was as follows: metal-specific label generation, positive sample counting, and weighted binary cross-entropy loss.
* MbPA (Metal Binding Protein Atlas) is a resource library of metal binding proteins. Currently, the database contains 106,373 entries and 440,187 sites, involving 54 metal ions and 8,169 species.

Two-stage deep learning framework and modular fusion
The research team proposed a sequence-based two-stage deep learning framework for efficiently predicting multi-metal binding sites in protein sequences.The overall idea is to first train independent prediction models for single metal ions to generate single-residue probability maps. These maps are then integrated through a lightweight fusion network to model inter-metallic dependencies and ultimately optimize prediction performance.
In the first stage, a one-dimensional convolutional neural network (Single-metal CNN) was used for each single metal, Zn, Fe, and Mg, to predict the positional association probability of a specific metal ion. After the aforementioned processing, each protein sequence was uniformly represented as a 500-dimensional representation. Integer-encoded residues were mapped to an embedding layer of a 64-dimensional trainable vector. The sequence was then passed through four Conv1D layers (number of convolution kernels: 512, 256, 128, 64, kernel sizes: 15, 7, 5, 3), using a uniform Rectangular Unit (ReLU) activation function. A dropout layer with a dropout rate of 0.3 was added after the convolutional layers. After convolutional feature extraction and regularization, the sequence features were input to a time-distributed fully connected layer, which outputs the predicted binding probability bit by bit using a sigmoid activation function.
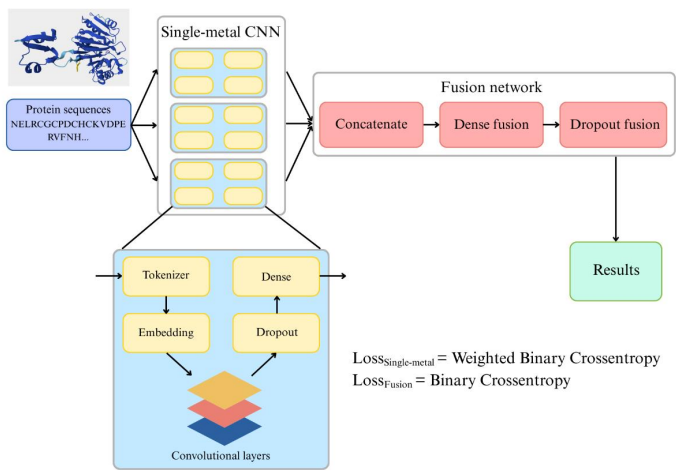
Phase IIThe research team designed a multi-metal integrated fusion network (Fusion network).The predictions for the three metals are concatenated into a tensor of shape (Lmax, M), where Lmax = 500 amino acids and M = 3 metal channels. This tensor is fed into a fully connected layer with 256 hidden units and ReLU activations, learning the nonlinear interactions between metal-specific features at each residue level. A dropout layer with a dropout rate of 0.2 is then introduced to regularize the fusion weights and prevent overfitting. Finally, M sigmoid outputs are used in the dense layer to provide accurate binding probabilities for Zn, Fe, and Mg for each residue. The fusion network uses standard binary cross-entropy as the loss function and is trained with the Adam optimizer, thereby learning how to correct for correlation errors and improving overall accuracy.
In addition, the unique feature of the framework is that it relies entirely on protein sequence data, thus eliminating the dependence on structure.This enables the entire process to be completed in under an hour on a single NVIDIA A800 GPU, and its efficiency helps accelerate the experimental process and real-time parameter adjustment.
Multi-dimensional comprehensive experimental evaluation
The research team used multi-dimensional indicators to conduct experimental evaluation.This combined metric includes precision, recall, F1 score, and Matthews correlation coefficient (MCC). A decision threshold τ is applied to the predicted binding probability: if the predicted probability of a residue exceeds τ, it is classified as a metal-binding site; otherwise, it is classified as a non-metal-binding site. Compared to evaluation methods that only consider a single value, this combined metric system better reflects the framework's true performance in class imbalance scenarios.
Figure (a) below shows the relationship between each metal and the macro-average F1 score and the decision threshold τ. The results show that Fe performs well in prediction, with F1 scores exceeding 0.81 when τ values range from 0.25 to 0.60. The single-metal models for Zn and Mg also achieve F1 scores exceeding 0.79 in the τ = 0.25–0.50 and 0.25–0.60 ranges. Overall, the macro-average F1 score peaks at 0.855 when the threshold is set between 0.40–0.45, which is the optimal choice for balancing precision and recall for all metals. Figure (b) shows the relationship between MCC and threshold, further demonstrating that the framework can still achieve good balance even in the case of severe class imbalance.
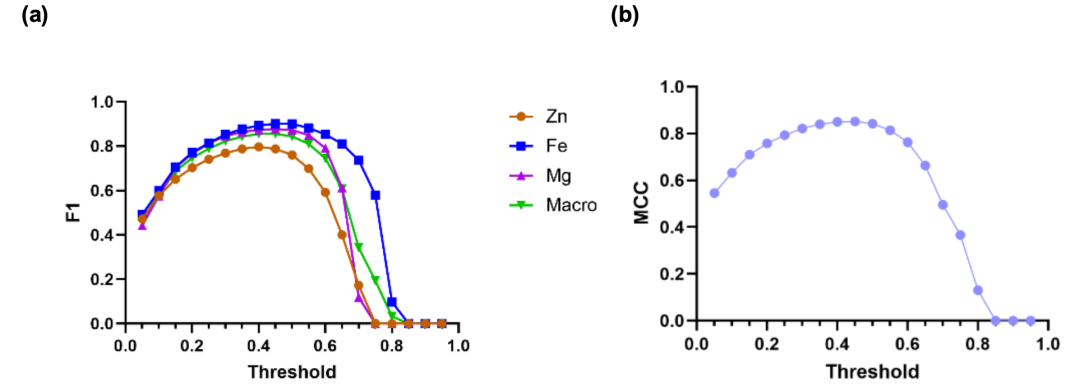
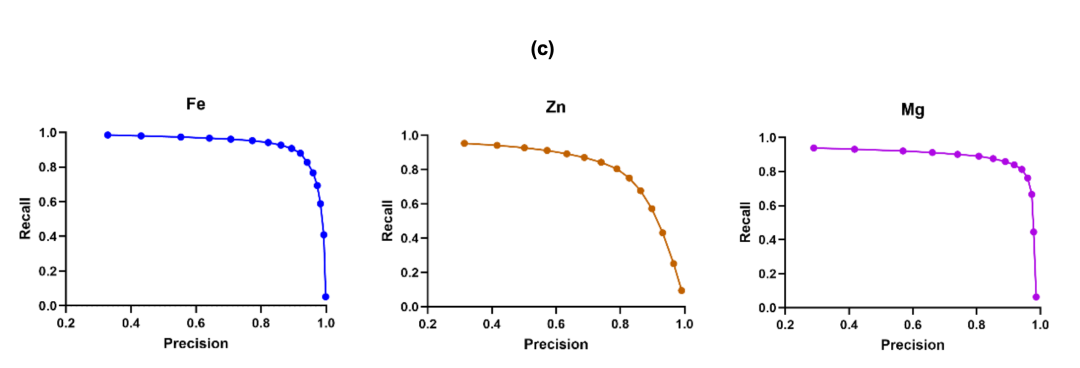
Figure (c) shows the precision-recall curves for the three metals. The prediction of Fe maintains high precision at high recall levels, demonstrating its suitability for comprehensive site screening. The prediction indices for Zn and Mg also perform well, demonstrating the robustness of the framework for applications requiring moderately high recall and sustained precision.
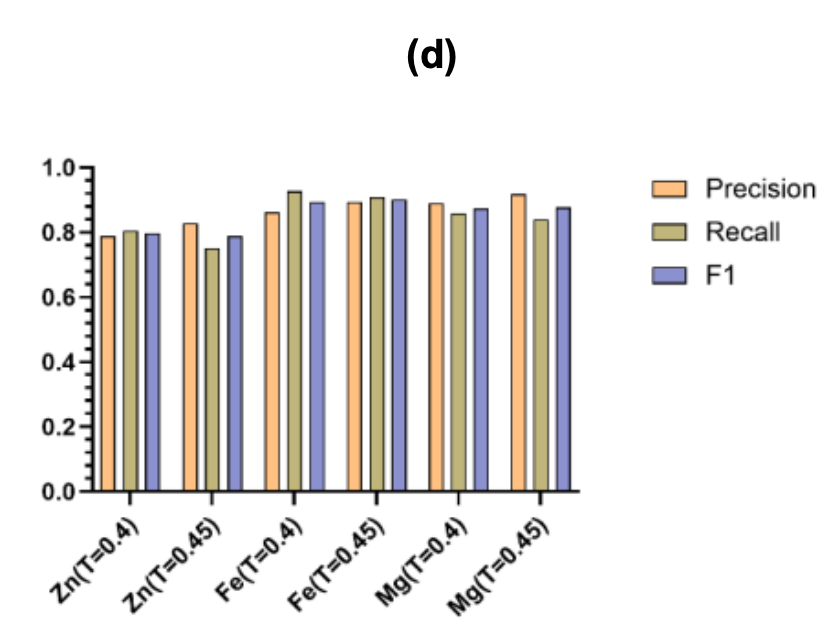
Finally, Figure (d) shows the precision, recall, and F1 score of different metal predictions at the two optimal thresholds of τ = 0.40 and 0.45.The results show that the framework can be flexibly adjusted according to the characteristics of different metals. It can be used in coverage-priority screening scenarios and can also meet high-precision experimental verification needs.
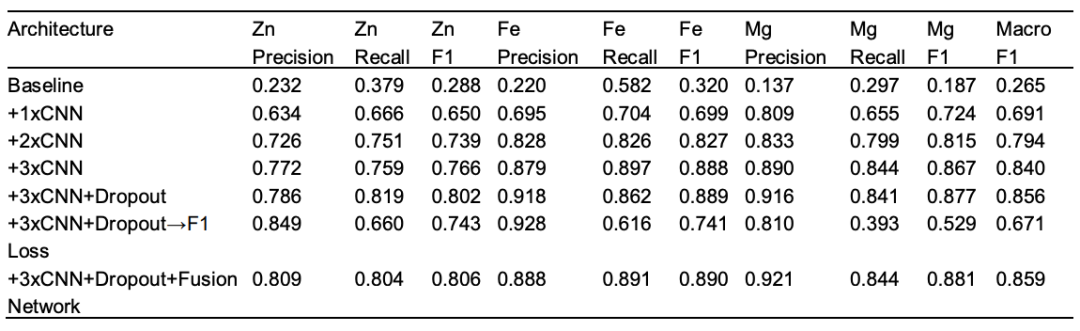
To evaluate the contribution of each architectural component, the research team also conducted systematic ablation experiments to verify two core design principles:(1) The weighted binary cross-entropy loss function is crucial for handling the class imbalance problem in metal binding site prediction. (2) The fusion network architecture enhances prediction consistency and captures cross-metal relationships that cannot be exploited by individual models independently.
Starting with the most basic single CNN layer, the average F1 was only 0.265. Performance improved significantly with increasing convolutional layers, with a three-layer CNN increasing the average F1 to 0.840, demonstrating the crucial role of hierarchical feature extraction. Introducing dropout increased the F1 to 0.856, preventing overfitting and improving generalization. To address class imbalance, the research team designed a weighted binary cross-entropy loss function, which significantly improved recall without sacrificing overall accuracy. Finally, adding a fusion layer further improved the average F1 to 0.859. This fusion layer effectively models intermetallic dependencies, enhancing the accuracy and robustness of residue-level predictions.
A new engine to accelerate metal-protein interaction mining
This novel framework has advanced metalloprotein annotation and is becoming a crucial engine for accelerating the analysis of metal-protein interactions. The importance of exploring metal-protein interactions in biology is undeniable, and this research direction has garnered significant attention. Scholars from various research teams are actively exploring new approaches and tools from a variety of perspectives. Two high-quality achievements are listed below:
Two tools—Metal3D and Metal1D—developed by the Swiss Federal Institute of Technology in Lausanne (EPFL) have been developed to improve the prediction of zinc ion locations in protein structures. The Metal3D framework can be extended to other metals by modifying the training data. The related research, titled "Metal3D: A general deep learning framework for accurate metal ion location prediction in proteins," was published in Nature Communications.
Paper address:
https://www.nature.com/articles/s41467-023-37870-6
A study published on arXiv titled "Interpretable Multimodal Learning for Tumor Protein-Metal Binding: Progress, Challenges, and Perspectives" systematically summarizes the latest progress and ongoing challenges in using machine learning to predict tumor protein-metal binding. It also proposes two promising directions for the design of efficient metal drugs: integrating protein-protein interaction data to provide structural insights into metal binding; and predicting structural changes in tumor proteins after metal binding.
Paper address:
https://arxiv.org/abs/2504.03847
Reference Links:
1.https://pubs.acs.org/doi/10.1021/cr300014x








