Command Palette
Search for a command to run...
Achieving fine-grained Characterization of TCR Sequences! The Deep Learning Framework DeepTCR Expands Immunology Research Methods; Backed by 50,000 Lung Cancer Patient Data! Lung Cancer Risk Details Lung Cancer Risk factors.

T cell receptor sequencing (TCR-Seq) is an important application of next-generation sequencing (NGS) technology, enabling researchers to systematically characterize the diversity of adaptive immune responses. When analyzing T cell receptor sequencing data, traditional methods (such as motif searching or sequence alignment) have achieved results, but have also gradually exposed their limitations.When identifying low-frequency antigen-specific T cell responses in the body, their signals are often overwhelmed by a large number of nonspecific T cell backgrounds.This reflects the challenges that traditional methods face in identifying signals from noise.
As the demand for more refined characterization of TCR sequences continues to grow, researchers have turned their attention to deep learning technologies represented by convolutional neural networks (CNNs).DeepTCR emerged as a deep learning-based immune receptor sequencing analysis framework.The framework can learn CDR3 sequences, V/D/J gene usage, and MHC molecule type characteristics from TCR sequencing immune repertoire data and construct a joint representation to model highly complex TCR sequencing data.
DeepTCR systematically applies the deep learning framework to TCR sequence analysis, which not only expands the analytical methods of immunological research, but also further demonstrates the wide application of deep learning technology in different fields.
HyperAI's official website has launched "DeepTCR: Predicting TCR-Peptide Affinity Using Deep Learning." Come and try it out!
Online use:https://go.hyper.ai/gKmgi
From September 8th to September 12th, here’s a quick overview of the hyper.ai official website updates:
* High-quality public datasets: 10
* Selected high-quality tutorials: 2
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in September: 5
Visit the official website:hyper.ai
Selected public datasets
1. New Plant Diseases Plant Disease Image Dataset
New Plant Diseases is an image dataset for plant disease identification and leaf classification research. It covers healthy leaves and various disease types. It is widely suitable for developing and evaluating machine learning and deep learning models, especially in crop health monitoring, disease identification, precision agriculture models and academic research, and has important benchmark value.
Direct use: https://go.hyper.ai/RKYtW

2. Intel Image Classification Natural Scene Image Classification Dataset
Intel Image Classification is an image classification dataset released by Intel that aims to classify images of natural and man-made scenes. The dataset contains approximately 25,000 color images distributed across six categories, including buildings and forests.
Direct use: https://go.hyper.ai/qgbeX

3. LongPage novel reasoning dataset
LongPage is the first comprehensive dataset for training artificial intelligence models to write complete novels with complex reasoning capabilities. It supports cold-start supervised fine-tuning to reinforcement learning training processes and is suitable for training large-scale language models with hierarchical reasoning capabilities and improving the coherence and planning of long-form writing.
Direct use: https://go.hyper.ai/odoKA
4. Lung Cancer Risk Dataset
Lung Cancer Risk is a tabular dataset for lung cancer risk prediction and health factor analysis. It aims to explore the association between smoking habits, lifestyle, and lung cancer risk through multidimensional features. It is suitable for lung cancer risk modeling, medical machine learning research, health prediction system development, and teaching experiments. It is particularly valuable in classification modeling and risk assessment scenarios.
Direct use:https://go.hyper.ai/YGFzG
5. IFEval-Inverse Reverse Instruction Evaluation Dataset
IFEval-Inverse is an adversarial instruction evaluation dataset for large language models released by ByteDance Seed in collaboration with Nanjing University, Tsinghua University, and other institutions. It aims to test whether the model can break the training inertia and achieve true instruction compliance when faced with reverse or abnormal instructions.
Direct use: https://go.hyper.ai/IcTqj
6. FinReflectKG Financial Knowledge Graph Dataset
FinReflectKG is a large-scale knowledge graph dataset for the financial sector. It aims to extract structured semantic relationships from corporate regulatory documents and promote the development of knowledge graph research in the financial field. It is suitable for entity recognition, relationship extraction, knowledge graph construction, time series analysis, and large-scale language model-driven information extraction evaluation and downstream financial intelligent application development in the financial field.
Direct use: https://go.hyper.ai/EB5em
7. WenetSpeech Yue Cantonese corpus dataset
WenetSpeech Yue is a large, multi-dimensionally annotated speech corpus for Cantonese speech recognition (ASR) and text-to-speech synthesis (TTS). It aims to fill the gap in resources in the Cantonese field and promote the training and evaluation of high-quality Cantonese models.
Direct access: https://go.hyper.ai/cICOv
8. UCIT Continuous Instruction Tuning Dataset
UCIT is a benchmark dataset for continuous instruction tuning of large multimodal language models. Each sample in this dataset consists of a task description (prompt/instruction) and the corresponding correct execution expectation (ground-truth response), which is used to measure the performance of the model under zero-shot conditions.
Direct use: https://go.hyper.ai/TZPwY
9. LoongBench Multi-Domain Reasoning Benchmark Dataset
LoongBench is a multi-domain reasoning evaluation dataset designed to provide LLM with a multi-domain, verifiable training and evaluation resource. The dataset contains 8,729 natural language questions, covering 12 reasoning-intensive domains, including advanced mathematics and advanced physics.
Direct use: https://go.hyper.ai/AcFOZ
10. CA‑1 Human Preference Alignment Dataset
CA-1 focuses on humans' value judgments and preferences for the default behaviors of AI models. It is a human feedback behavior dataset that combines model-generated content and annotator evaluations. It is suitable for studying group alignment differences, guiding model behavior norms, and developing value-sensitive reward mechanisms.
Direct use: https://go.hyper.ai/mXznO
Selected Public Tutorials
1. Wan2.2-S2V-14B: Film-grade audio-driven video generation
Wan2.2-S2V-14B is an open-source audio-driven video generation model developed by the Alibaba Tongyi Wanxiang team. Using only a single still image and audio, it can generate cinematic-quality digital human videos up to minutes long, supporting a variety of image types and image sizes. The model integrates multiple innovative technologies to enable audio-driven video generation for complex scenes, supporting long video generation and multi-resolution training and inference.
Run online: https://go.hyper.ai/TlSai
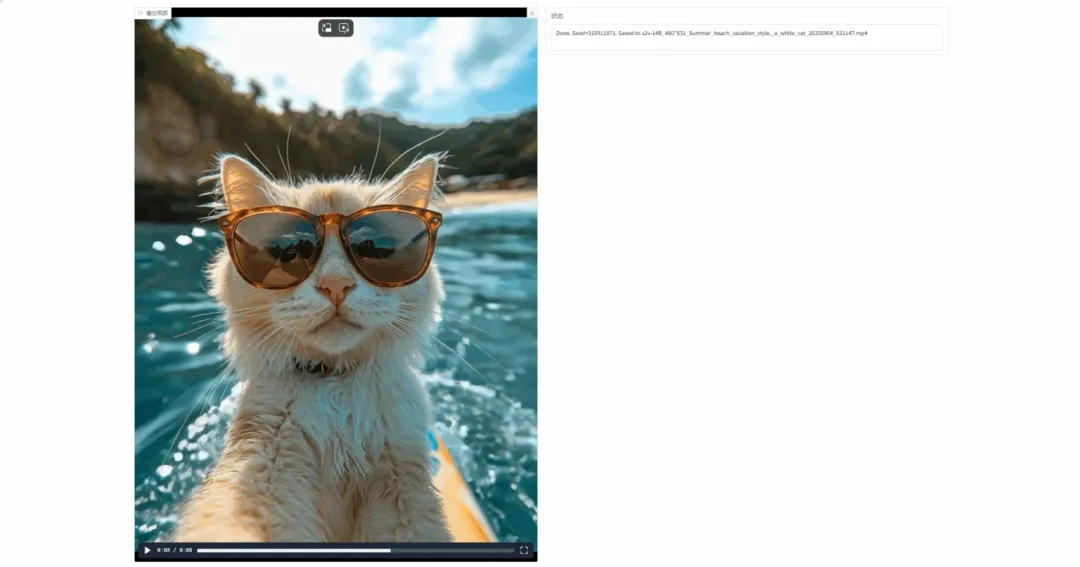
2. DeepTCR: Deep Learning to Predict TCR-Peptide Affinity
DeepTCR is a deep learning-based immune receptor sequencing analysis framework that can predict affinity from TCR sequencing immune repertoire data, extract and learn TCR CDR3 sequences, V/D/J gene usage or MHC molecule type characteristics, and jointly represent TCRs to model highly complex TCR sequencing data. It can extract antigen-specific TCRs from single-cell RNA-Seq with background noise and T cell culture-based assays.
Run online: https://go.hyper.ai/gKmgi
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

This week's paper recommendation
1. Sharing is Caring: Efficient LM Post-Training with Collective RL Experience Sharing
This paper proposes Swarm sAmpling Policy Optimization (SAPO), a fully decentralized and asynchronous reinforcement learning post-training algorithm. SAPO is designed for decentralized networks of heterogeneous computing nodes. Each node autonomously manages its own policy model while "sharing" its trajectory with other nodes. The algorithm does not rely on explicit assumptions about latency, model homogeneity, or hardware configuration, and nodes can operate independently on demand.
Paper link: https://go.hyper.ai/MWeWF
2. Why Language Models Hallucinate
This paper proposes that the fundamental reason language models experience hallucinations is that their training and evaluation mechanisms tend to reward guesswork rather than acknowledge uncertainty. It further analyzes the statistical roots of hallucinations in modern training processes. The systematic penalty imposed by large models on uncertain responses suggests that current mainstream, yet biased, benchmark scoring methods should be revised, rather than introducing additional metrics to assess hallucinations.
Paper link: https://go.hyper.ai/eXoOR
3. Reverse-Engineered Reasoning for Open-Ended Generation
This paper proposes a new paradigm—Reverse-Engineered Reasoning (REER)—that fundamentally changes the way reasoning is constructed. Unlike traditional methods that construct reasoning processes from the bottom up through trial and error or imitation, REER adopts a "reverse" strategy. Starting from known high-quality solutions, it computationally discovers the potential, step-by-step, deep reasoning paths that can generate these solutions.
Paper link: https://go.hyper.ai/xFygJ
4. Parallel-R1: Towards Parallel Thinking via Reinforcement Learning
This paper presents Parallel-R1, the first reinforcement learning (RL) framework for complex real-world reasoning tasks that enables parallel thinking behaviors. This framework uses a progressive curriculum design to explicitly address the cold-start problem of training parallel thinking in RL.
Paper link: https://go.hyper.ai/s2OlH
5. WebExplorer: Explore and Evolve for Training Long-Horizon Web Agents
Leveraging a carefully constructed, high-quality dataset, this paper successfully trained a state-of-the-art web proxy model, WebExplorer-8B, through supervised fine-tuning combined with reinforcement learning. This model supports context lengths up to 128KB and can execute up to 100 tool calls, enabling the solution of long-term problems. On multiple information retrieval benchmarks, WebExplorer-8B achieved state-of-the-art performance among models of similar size.
Paper link: https://go.hyper.ai/NusbG
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
Researchers from the Chinese University of Hong Kong, the Mohamed bin Zayed University for Artificial Intelligence, and other institutions have proposed a scalable transcriptome-guided diffusion model, MorphDiff, specifically designed to simulate the response of cell morphology to perturbations with high fidelity. This model, based on the Latent Diffusion Model (LDM) architecture, uses L1000 gene expression profiles as conditional input for denoising training.
View the full report: https://go.hyper.ai/f7WeP
A joint research team from China University of Petroleum and Yonsei University has integrated multiple advanced technologies to develop a new framework, called AlphaPPIMI. Combining a large-scale pre-trained model with an adaptive learning mechanism, this tool aims to address the core challenge of discovering modulators that specifically target the PPI interface, providing strong support for the future development of PPI-targeted drugs.
View the full report: https://go.hyper.ai/4tp0M
At 1:00 AM Beijing time on September 10th, Apple's 2025 Fall Conference focused entirely on AI, announcing AI upgrades for three core products: the iPhone 17, Apple Watch Series 11, and AirPods Pro 3. Apple Intelligence has evolved from a concept showcase last year to a full-scale implementation, covering scenarios such as real-time translation, health monitoring, and visual intelligence. The next-generation A19 and M19 Pro chips serve as the cornerstone of its computing power.
View the full report: https://go.hyper.ai/IimjS
Research teams from Wuhan University and Nanyang Technological University jointly released a Healthcare Agent consisting of three components: dialogue, memory, and processing. It can identify patients' medical purposes and automatically detect medical ethics and safety issues.
View the full report: https://go.hyper.ai/AdG2j
In early September, Apple was reportedly interested in acquiring French startup Mistral AI. Semiconductor giant ASML followed suit, leading its Series C funding round with €1.3 billion. The company's valuation has now soared to $14 billion, making it a leading force in the European AI field.
View the full report: https://go.hyper.ai/zsQBu
Popular Encyclopedia Articles
1. DALL-E
2. Reciprocal sorting fusion RRF
3. Pareto Front
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
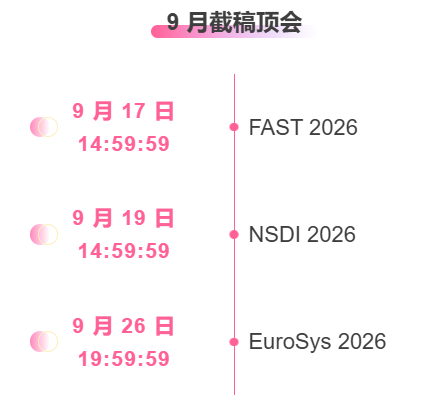
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1800+ public datasets
* Includes 600+ classic and popular online tutorials
* Interpretation of 200+ AI4Science paper cases
* Supports 600+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








