Command Palette
Search for a command to run...
From "assistant" to "user," Microsoft UserLM-8B Simulates Real Human Conversations, Driving a New Wave of LLM optimization. Designed for Lightweight Performance, Extract-0 Helps small-parameter Models Achieve Accurate Information extraction.

With the rapid development of large language models (LLMs), we have witnessed the emergence of powerful models that act as “assistants”, dedicated to providing detailed and structured responses to meet the user’s explicit needs.existIn real conversation scenarios, users often do not express their intentions completely at once, but gradually reveal information in multiple rounds of conversation. Their language style also generally shows the characteristics of fragmentation, personalization and instant adjustment.In contrast, traditional "assistant" models are not very good at simulating users. Furthermore, the better the LLM assistant, the more distorted its "user" impersonation. This limitation also exposes a key pain point in the current LLM evaluation system: due to the lack of high-quality "user" personas that can accurately simulate human conversations, existing evaluation environments are often overly idealized and significantly outmatched by the complex contexts of real applications.
It is in this context thatMicrosoft has launched the latest user language model UserLM-8B,Unlike typical LLMs, which typically serve as assistants, this model, trained on the WildChat conversation corpus, can be used to simulate the "user" role in conversations, engaging in multiple rounds of dialogue and serving as a useful tool for evaluating the capabilities of large-scale models. When using UserLM to simulate programming and math conversations, GPT-4o's score dropped from 74.61 TP3T to 57.41 TP3T, confirming that more realistic simulation environments can lead to performance degradation for the "assistant" due to its difficulty in responding to the nuances of user expression.
The launch of UserLM-8B provides a more realistic and robust testing environment for evaluating large models. By simulating user conversations, even state-of-the-art assistant models can significantly degrade in performance, enabling researchers and developers to more accurately identify model weaknesses in real-world interactions.This further promotes LLM competency assessment to move beyond a single, static benchmark test and score comparison, and gradually emphasizes "actual combat exercises" that are closer to reality.Let LLM better understand the user's true intentions and continuously optimize the human user experience.
The "UserLM-8b: User Conversation Simulation Model" is now available on HyperAI's official website. Come and try it out!
Online use:https://go.hyper.ai/EHcdQ
From October 20th to October 24th, here’s a quick overview of the hyper.ai official website updates:
* High-quality public datasets: 8
* High-quality tutorial selection: 7
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
* Top conference with deadline in October: 1
Visit the official website:hyper.ai
Selected public datasets
1. CP2K_Benchmark performance benchmark dataset
The CP2K Benchmark dataset is a set of performance testing and validation inputs specifically designed for high-performance computing (HPC) environments. This dataset, derived from the open-source first-principles simulation software CP2K, is used to evaluate the performance of quantum chemistry and molecular dynamics calculations under different hardware platforms, parallelization strategies (MPI/OpenMP), and compilation optimization settings.
Direct use:https://go.hyper.ai/BGnLb
2. Smilei_Benchmark plasma dynamics simulation benchmark dataset
Smilei, short for Simulation of Matter Irradiated by Light at Extreme Intensities, is an open-source, easy-to-use electromagnetic particle-in-cell (PIC) code designed to provide a high-precision, high-performance, and scalable plasma dynamics simulation platform for fields such as laser-plasma interaction, particle acceleration, strong-field QED, and space physics.
Direct use:https://go.hyper.ai/6VCxB
3. Gatk_benchmark genome analysis example dataset
GATK (Genome Analysis Toolkit) is an open-source bioinformatics toolkit developed by the Broad Institute, a joint venture between MIT and Harvard University. The project aims to provide a standardized analysis pipeline for high-throughput sequencing (NGS) data.
Direct use:https://go.hyper.ai/0VAuf
4. LAMMPS-Bench Molecular Dynamics Benchmark Dataset
LAMMPS Bench datasets are used to test and compare the performance of LAMMPS (molecular dynamics simulation software) on different hardware and configurations. These datasets are not scientific experimental data, but rather are used to evaluate computational performance (speed, scaling, and efficiency). They contain specific architectures, force field files, input scripts, initial atomic coordinates, and more. LAMMPS provides these datasets in the `bench/` folder.
Direct use:https://go.hyper.ai/L4gye
5. PromptCoT-2.0-SFT-4.8M supervised fine-tuning prompt SFT dataset
PromptCoT-2.0-SFT-4.8M is a large-scale synthetic prompt dataset designed to provide high-quality reasoning prompts for large language models, either for fine-tuning or self-training. This dataset contains approximately 4.8 million fully synthetic prompts with reasoning traces, covering two major reasoning domains: mathematics and programming.
Direct use:https://go.hyper.ai/f188j
6. Extract-0 document information extraction data
Extract-0 is a high-quality training and evaluation dataset designed specifically for document information extraction tasks. It aims to support performance optimization research of small-scale parameter models in complex extraction tasks.
Direct use:https://go.hyper.ai/z9BQO
7. EmoBench-M emotion perception benchmark dataset
EmoBench-M is a benchmark dataset proposed by Shenzhen University, Guangming Laboratory, University of Macau and other institutions to evaluate the emotion understanding capabilities of multimodal large language models (MLLMs). It aims to fill the gaps in existing unimodal or static emotion datasets in dynamic and multimodal interaction scenarios, and to be closer to the complexity of human emotional expression and perception in real environments.
Direct use:https://go.hyper.ai/WafXo
8. GeoReasoning-10K Geometric Multimodal Reasoning Dataset
GeoReasoning-10K is a multimodal reasoning dataset for geometry, designed to bridge the gap between visual and linguistic modalities in geometry. The dataset contains 10,000 geometric image-text pairs with detailed geometric reasoning annotations. Each pair maintains consistency in geometric structure, semantic expression, and visual presentation, resulting in highly accurate cross-modal semantic alignment.
Direct use:https://go.hyper.ai/7qisY

Selected Public Tutorials
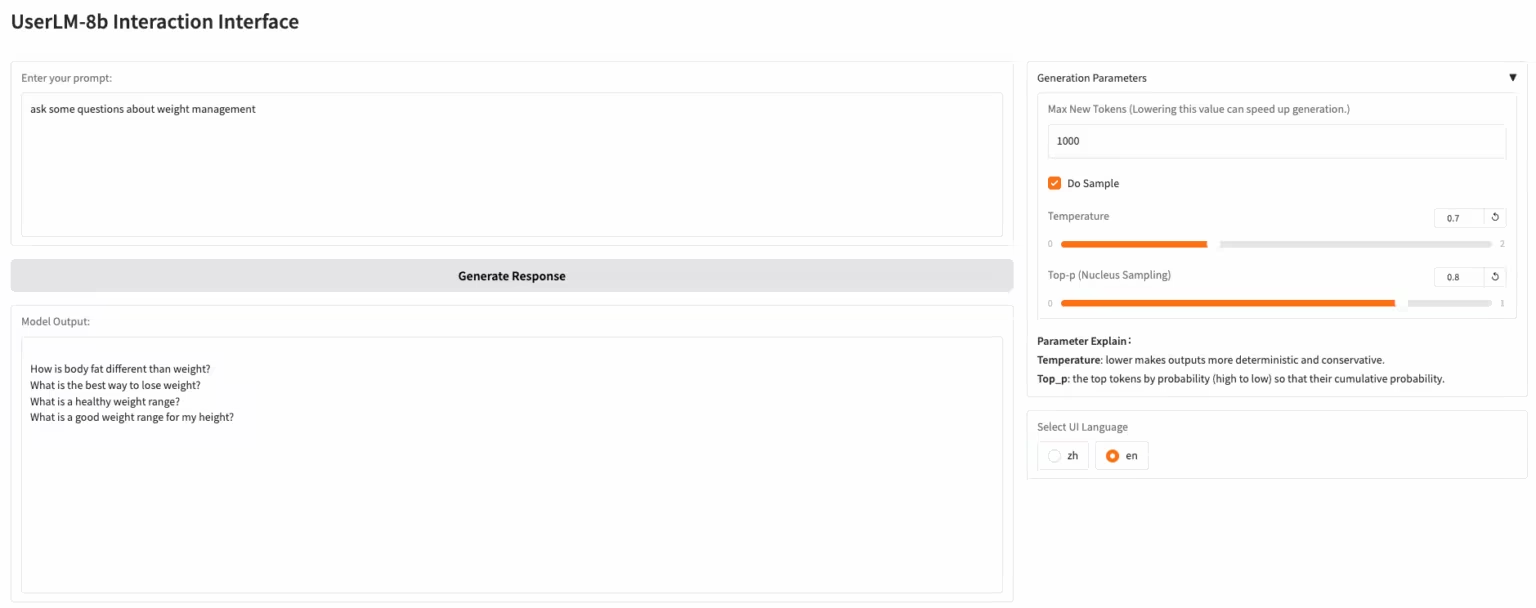
1. UserLM-8b: User Dialogue Simulation Model
UserLM-8b is a user behavior simulation model released by Microsoft. Unlike typical LLMs, which play the role of "assistant" in conversations, UserLM-8b simulates the "user" role in conversations (trained on the WildChat conversation corpus) and can be used to evaluate the capabilities of large-scale assistants. This model is not a typical large-scale assistant and cannot simulate more realistic conversations or solve problems, but it can help develop more powerful assistants.
Run online:https://go.hyper.ai/EHcdQ
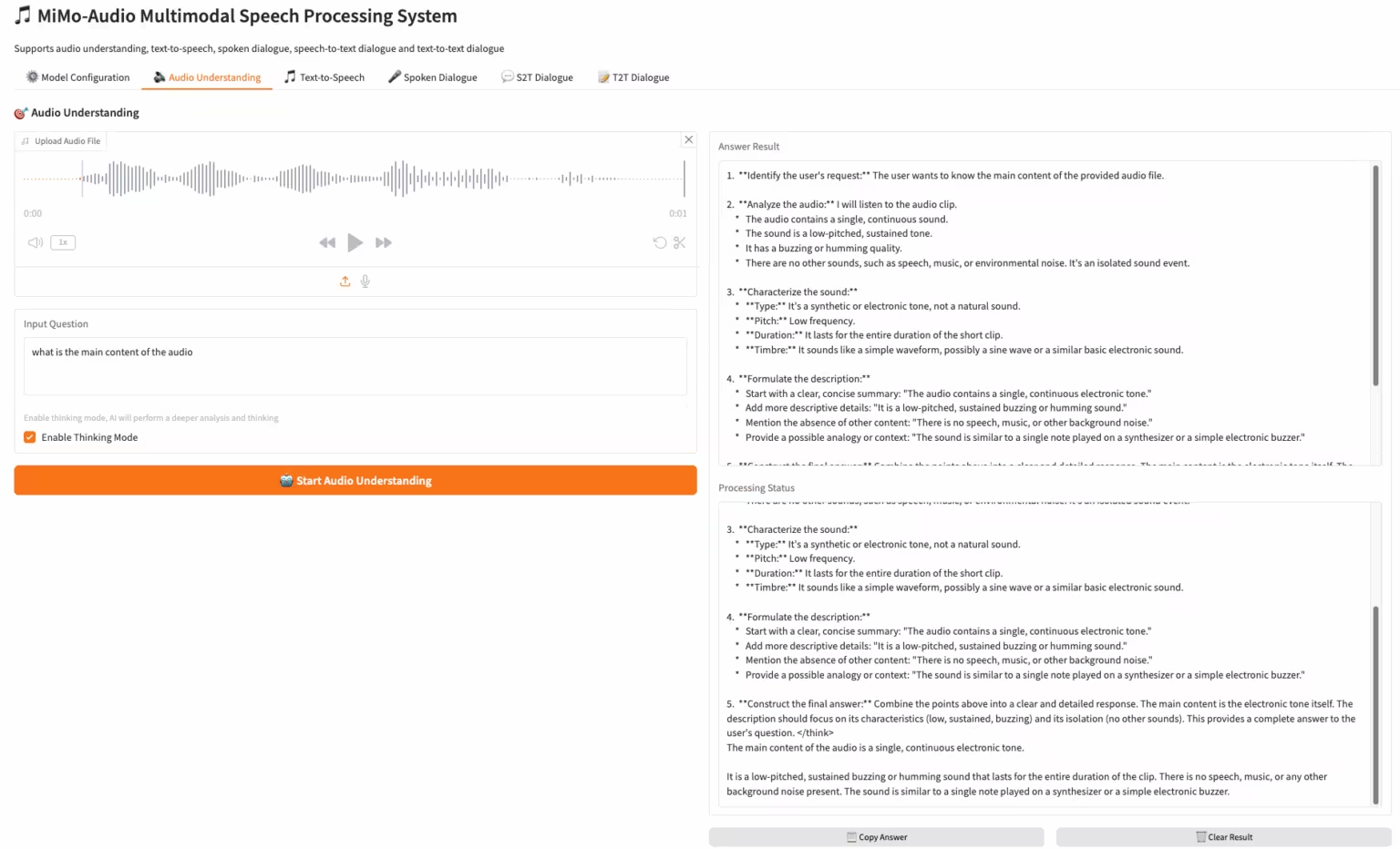
2. MiMo-Audio-7B-Instruct: Xiaomi's open-source end-to-end voice model
MiMo-Audio is an end-to-end speech model released by Xiaomi. Pre-training data has been expanded to over 100 million hours, and researchers have observed that it demonstrates few-shot learning capabilities across a variety of audio tasks. The team systematically evaluated these capabilities and found that MiMo-Audio-7B-Base achieved state-of-the-art performance (SOTA) on both speech intelligence and audio understanding benchmarks for open-source models.
Run online:https://go.hyper.ai/3DWbb
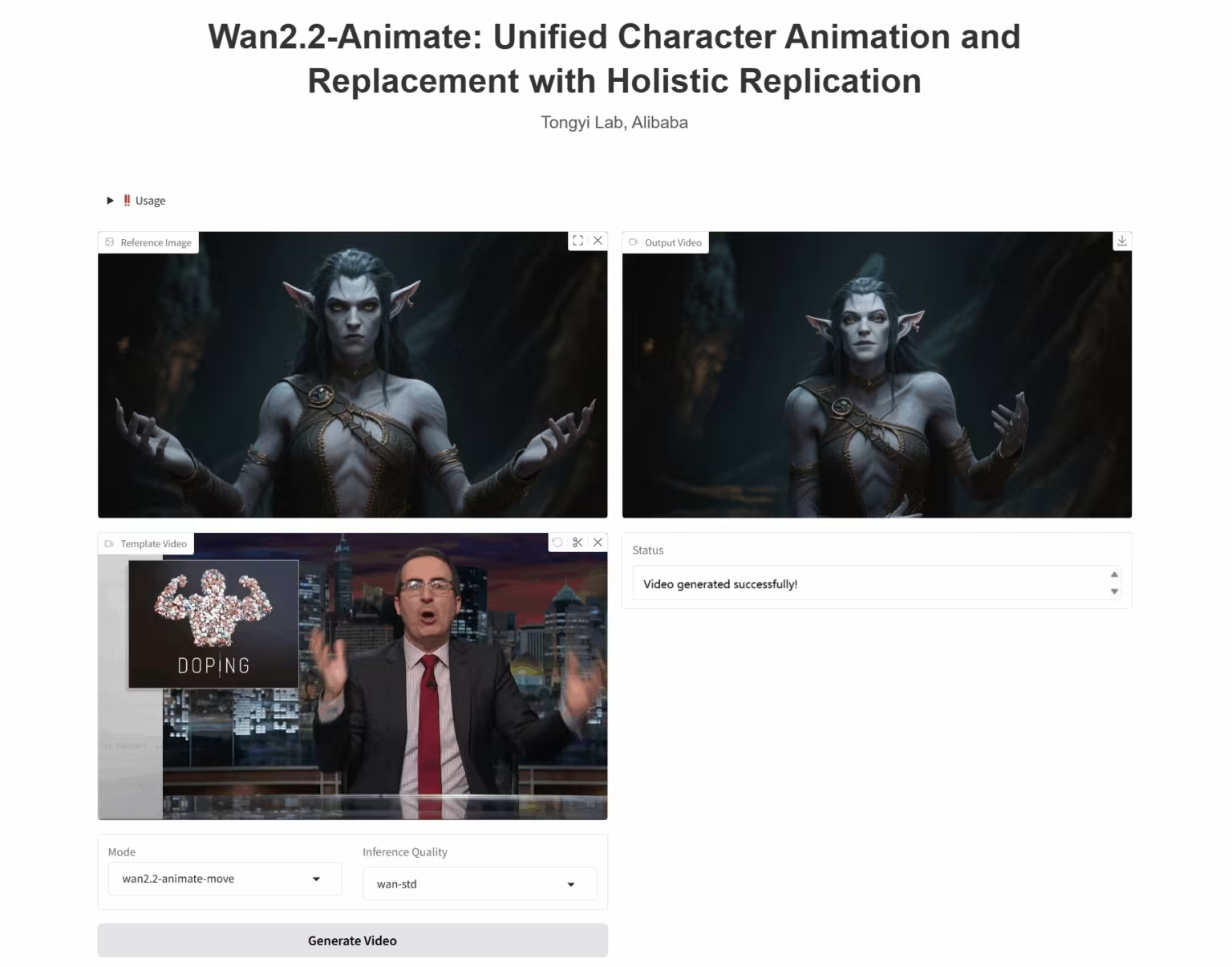
3. Wan2.2-Animate-14B: Open Advanced Large-Scale Video Generation Model
Wan2.2-Animate-14B is an open-source motion generation model developed by the Alibaba Tongyi Wanxiang team. The model supports both motion imitation and role-playing modes. Based on performer videos, it can accurately replicate facial expressions and movements to generate highly realistic character animation videos.
Run online: https://go.hyper.ai/UbtSO
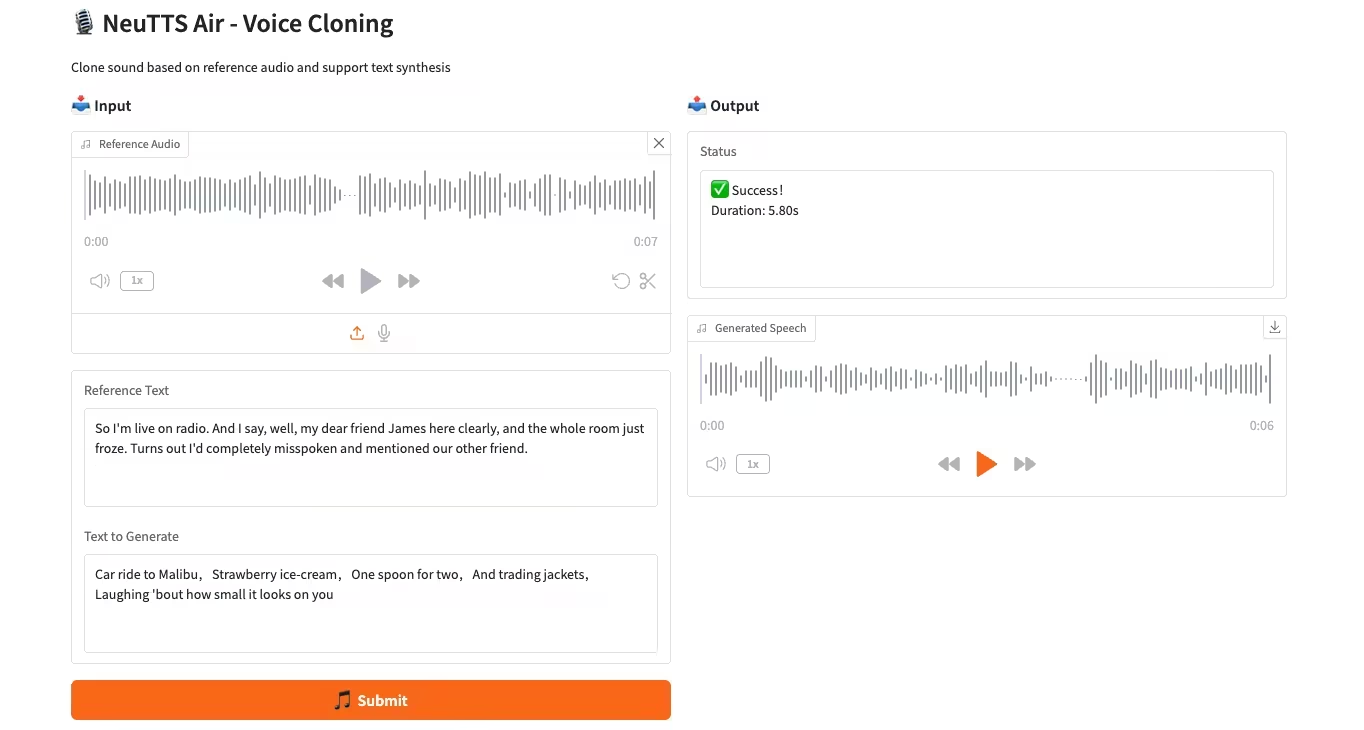
4. CPU deployment of NeuTTS-Air voice cloning model
NeuTTS-Air is an end-to-end text-to-speech (TTS) model released by Neuphonic. Based on the 0.5B Qwen LLM backbone and the NeuCodec audio codec, the model demonstrates few-shot learning capabilities in on-device deployment and instant voice cloning. System evaluations show that NeuTTS Air achieves state-of-the-art performance among open-source models, particularly on hyper-realistic synthesis and real-time inference benchmarks.
Run online:https://go.hyper.ai/KMMG1
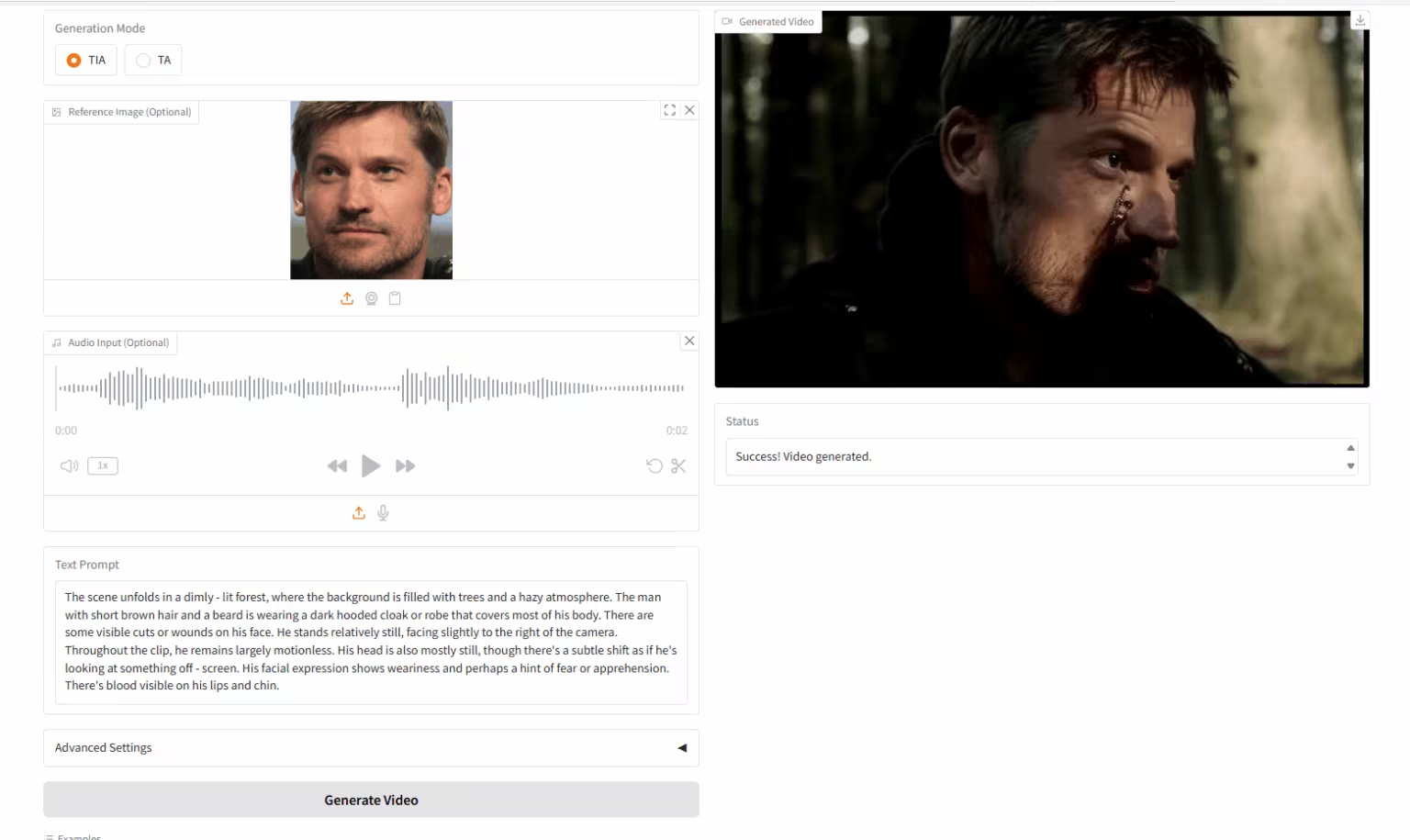
5. HuMo-1.7B: Multimodal Video Generation Framework
HuMo is a multimodal video generation framework developed by Tsinghua University and ByteDance's Intelligent Creation Lab, focusing on human-centered video generation. It generates high-quality, detailed, and controllable human-like videos from multimodal inputs, including text, images, and audio. The model supports robust text-cue following, consistent subject preservation, and audio-driven motion synchronization.
Run online:https://go.hyper.ai/tnyQU
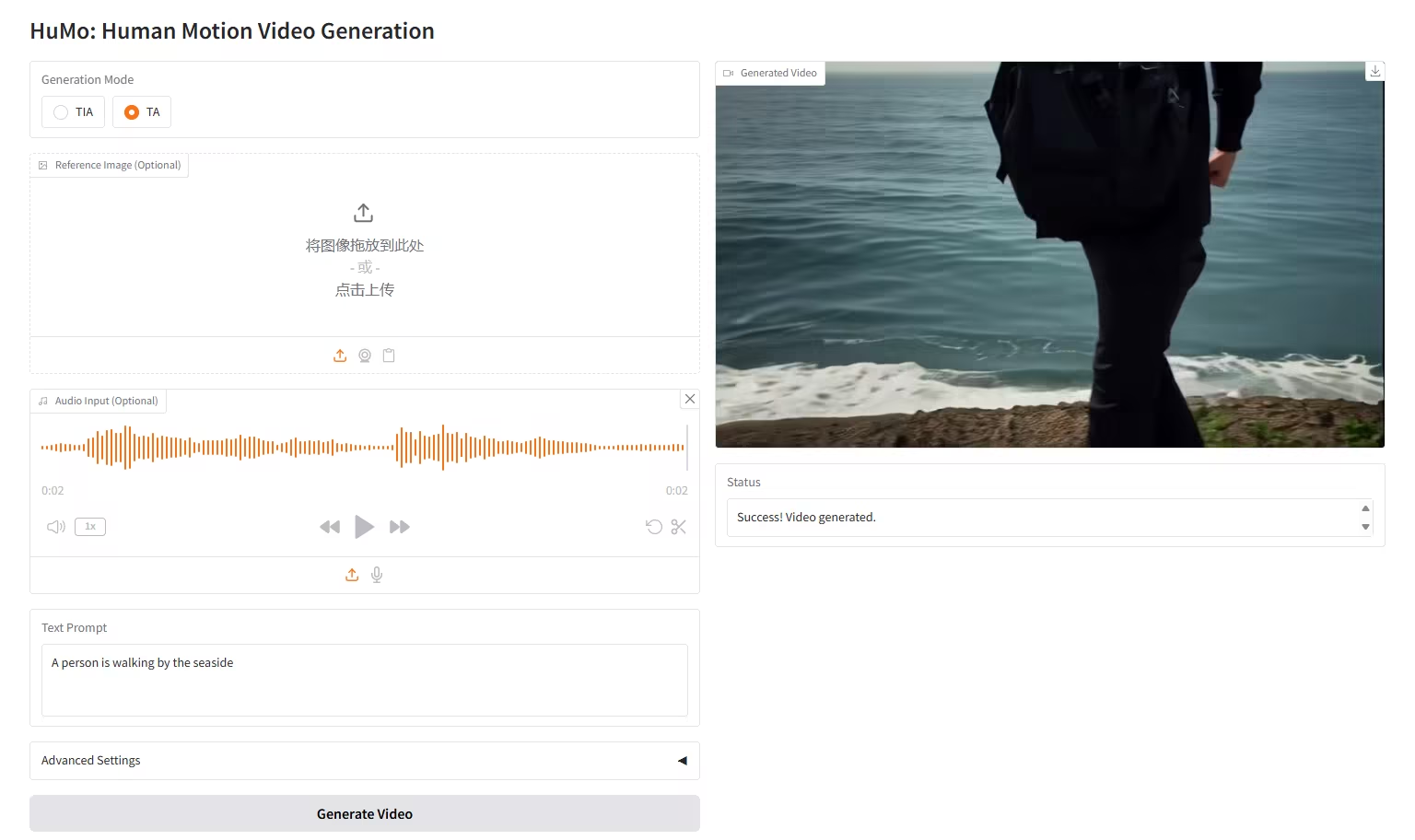
6. HuMo-17B: Trimodal Collaborative Creation
HuMo is a multimodal video generation framework released by Tsinghua University and ByteDance Intelligent Creation Lab. It supports generating videos from text-image (VideoGen from Text-Image), text-audio (VideoGen from Text-Audio), and text-image-audio (VideoGen from Text-Image-Audio).
Run online:https://go.hyper.ai/liAti
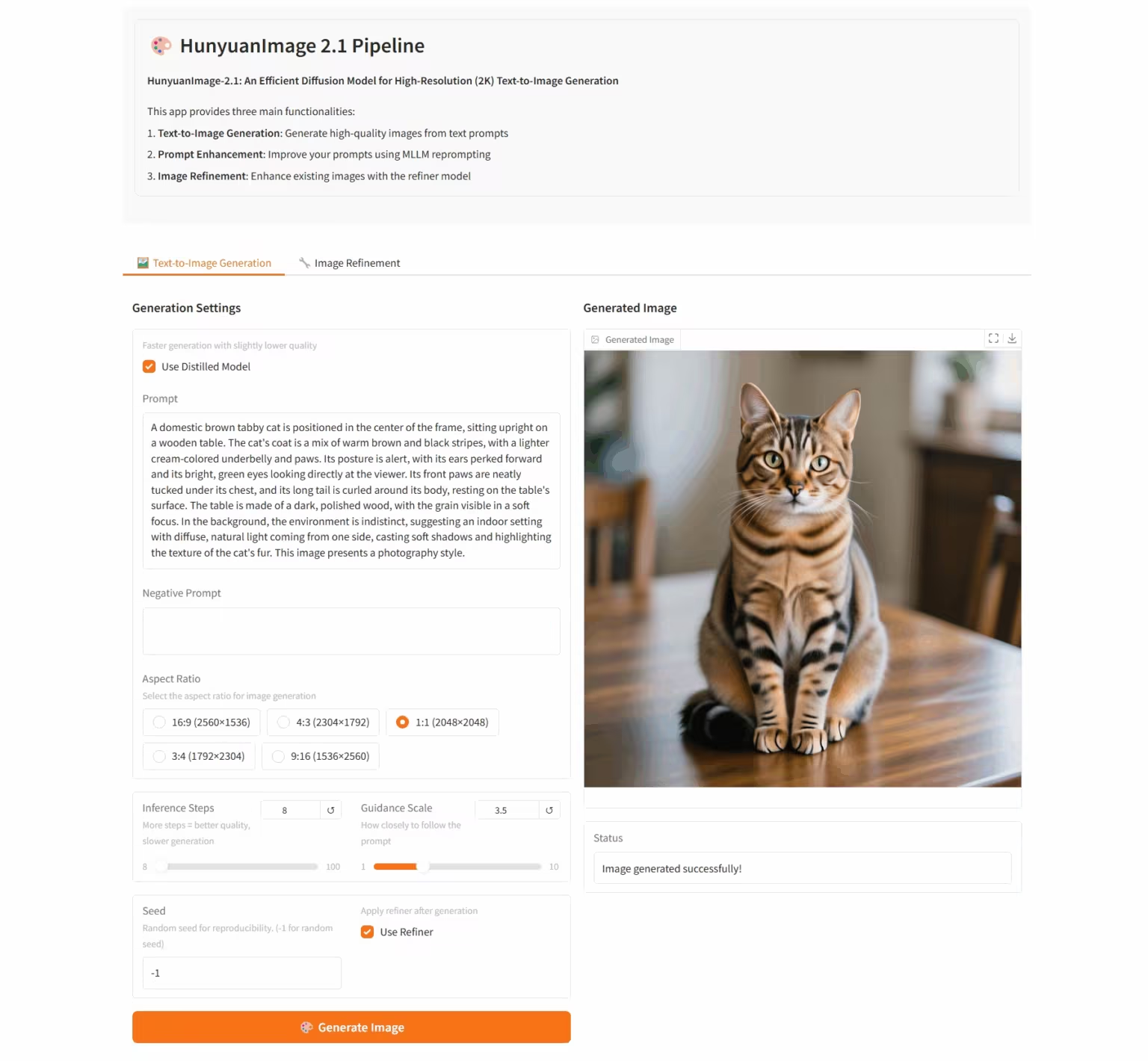
7. HunyuanImage-2.1: Diffusion Model for High-Resolution (2K) Wensheng Images
HunyuanImage-2.1 is an open-source text-based image model developed by the Tencent Hunyuan team. It supports native 2K resolution and possesses powerful complex semantic understanding capabilities, enabling accurate generation of scene details, character expressions, and actions. The model supports both Chinese and English input and can generate images in a variety of styles, such as comics and action figures, while maintaining robust control over text and details within the images.
Run online:https://go.hyper.ai/hpWNA
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

This week's paper recommendation
1. A Theoretical Study on Bridging Internal Probability and Self-Consistency for LLM Reasoning
This paper proposes RPC (Perplexity-Consistency and Reasoning Pruning), a hybrid approach that integrates theoretical insights and consists of two core components: perplexity consistency and reasoning pruning. Both theoretical analysis and empirical results on seven benchmark datasets demonstrate RPC's significant potential for reducing reasoning error. Notably, RPC achieves reasoning performance comparable to self-consistency while significantly improving confidence reliability and reducing sampling cost by 50%.
Paper link:https://go.hyper.ai/V3reH
2. Every Attention Matters: An Efficient Hybrid Architecture for Long-Context Reasoning
This technical report proposes a series of Ring-linear models, including Ring-mini-linear-2.0 and Ring-flash-linear-2.0. Both models adopt a hybrid architecture that effectively integrates linear attention and softmax attention, significantly reducing I/O overhead and computational burden in long-context reasoning scenarios.
Paper link:https://go.hyper.ai/xLhP3
3. BAPO: Stabilizing Off-Policy Reinforcement Learning for LLMs via Balanced Policy Optimization with Adaptive Clipping
This paper proposes a simple and efficient method, Balanced Policy Optimization with Adaptive Clipping (BAPO), which dynamically adjusts the clipping boundaries, adaptively rebalances positive and negative contributions, effectively maintains policy entropy, and significantly improves the stability of RL optimization.
Paper link:https://go.hyper.ai/EGQ4A
4. DeepAnalyze: Agentic Large Language Models for Autonomous Data Science
This paper presents DeepAnalyze-8B, the first large-scale language model designed specifically for autonomous data science. It automates the end-to-end process from data source to analyst-grade in-depth research reports. Experimental results demonstrate that, using only 8 billion parameters, this model outperforms previous workflow agents built on top of most state-of-the-art proprietary large-scale language models.
Paper link:https://go.hyper.ai/UTdwP
5. OmniVinci: Enhancing Architecture and Data for Omni-Modal Understanding LLM
This paper proposes the OmniVinci project, which aims to build a powerful and open-source omnimodal Large Language Model (LLM). Researchers conducted in-depth research on model architecture design and data construction strategies, designed and implemented a data construction and synthesis process, and generated a dataset of 24 million unimodal and omnimodal conversations.
Paper link:https://go.hyper.ai/c3yQW
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
1. Selected for NeurIPS 2025, NVIDIA proposed the ERDM model to solve long-term forecasting problems, and its medium- and long-term forecasts continue to lead the EDM benchmark.
Based on the Elucidated Diffusion Model (EDM) framework, a research team from NVIDIA and the University of California, San Diego, systematically improved noise scheduling, denoising network parameterization, preprocessing procedures, loss weighting strategies, and sampling algorithms to meet the needs of sequence modeling, and constructed an enhanced sequence diffusion model (ERDM).
View the full report:https://go.hyper.ai/QZBBl
2. Included Tutorial | MIT et al. launch BindCraft, which directly calls AF2 to achieve intelligent design of protein complexes
A team from the Swiss Federal Institute of Technology in Lausanne (EPFL) and the Massachusetts Institute of Technology (MIT) proposed an open source automated process, BindCraft, for designing protein binders from scratch. The core idea is to backpropagate the hallucinated binder sequence through the AlphaFold2 weights and calculate the error gradient.
View the full report:https://go.hyper.ai/LqNeb
3. Three Nobel Prizes in Two Years: Alphabet's Long-Term Scientific Research Accumulation, AI+Quantum Computing Leads Technological Strength and Ambition
With the 2025 Nobel Prizes announced, scientists from Google's parent company, Alphabet, have once again won. As a tech giant that has won Nobel Prizes for two consecutive years, its achievement of "three awards and five winners in two years" is no accident. From winning the Chemistry and Physics Prizes for AI technology in 2024 to the quantum research breakthrough that won the Physics Prize this time, over a decade of ambitious planning and research strategies have fostered its strong scientific research capabilities.
View the full report:https://go.hyper.ai/mY9Z3
MIT builds a generative AI model based on physical priors, requiring only a single spectral modality input to achieve cross-modal spectral generation with experimental correlations up to 99%.
A research team from MIT has proposed SpectroGen, a generative AI model based on physical priors. Using only a single spectral modality as input, it can generate cross-modal spectra with a correlation of 99% with experimental results. This model introduces two key innovations: first, representing spectral data as mathematical distribution curves; second, constructing a variational autoencoder generative algorithm based on physical priors.
View the full report:https://go.hyper.ai/OsYY2
5. Google teams collaborate on Earth AI, focusing on three core data points and improving geospatial reasoning capabilities by 64%.
Multiple teams at Google have jointly developed "Earth AI," a geospatial artificial intelligence model and intelligent reasoning system. This system builds an interoperable family of GeoAI models and enables collaborative analysis of multimodal data through customized inference agents. Focusing on three core data types: imagery, population, and environment, the system connects these three models using Gemini-powered agents. This system transcends the limitations of single-point models, enabling even non-expert users to perform cross-domain real-time analysis and advancing Earth system research toward actionable, global insights.
View the full report:https://go.hyper.ai/djq48
Popular Encyclopedia Articles
1. DALL-E
2. HyperNetworks
3. Pareto Front
4. Bidirectional Long Short-Term Memory (Bi-LSTM)
5. Reciprocal Rank Fusion
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
October deadline for the conference

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1800+ public datasets
* Includes 600+ classic and popular online tutorials
* Interpretation of 200+ AI4Science paper cases
* Supports 600+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey: