Command Palette
Search for a command to run...
A New state-of-the-art Document Parsing Platform! MinerU's New Version Innovates a two-stage "coarse-to-fine" Parsing Strategy; S2S Domain Benchmark Debuts! Tencent's Latest Benchmark Dataset Evaluates Speech Model capabilities.

In the wave of digitalization, all walks of life have accumulated massive amounts of unstructured document data, especially academic papers, reports, forms, etc. mainly in PDF format.Efficiently and accurately converting these documents into machine-readable structured data is an important prerequisite for achieving automated information extraction, document management and intelligent analysis, and is also a key step in unlocking the value of data.
Based on the continuously growing demand for OCR,OpenDataLab and Shanghai AI Lab jointly launched the visual language model MinerU2.5-2509-1.2B.It focuses on converting complex format documents such as PDF into structured machine-readable data (such as Markdown, JSON, etc.), and is designed for high-precision and high-efficiency document parsing tasks.The new version of the model achieves efficient parsing through a two-stage strategy of "from coarse to fine":The first stage uses efficient layout analysis to identify structural elements and outline the document framework; the second stage performs fine recognition within the cropped area at the original resolution to ensure that details such as text, formulas, and tables are restored.
MinerU2.5-2509-1.2B decouples global layout analysis from local content recognition, demonstrating powerful document parsing capabilities.It outperforms general and vertical field models in multiple recognition tasks.At the same time, it demonstrates significant advantages in computational overhead. It is not only a technically superior model, but also a tool that effectively improves technical efficiency, providing strong support for downstream user needs such as data analysis, information retrieval, and corpus construction.
The HyperAI official website has released "MinerU2.5-2509-1.2B: Document Parsing Demo." Come and try it out!
Online use:https://go.hyper.ai/emEKs
From October 13th to October 17th, here’s a quick overview of the hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 11
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
* Top conference with deadline in October: 1
Visit the official website:hyper.ai
Selected public datasets
1. FDAbench-Full Heterogeneous Data Analysis Benchmark Dataset
FDAbench-Full is the first heterogeneous data analysis task benchmark for data agents, released by Nanyang Technological University, the National University of Singapore, and Huawei Technologies Co., Ltd. It aims to evaluate the model's capabilities in database query generation, SQL understanding, and financial data analysis.
Direct use:https://go.hyper.ai/AUjv5
2. PubMedVision Medical Multimodal Evaluation Dataset
PubMedVision is a dataset for evaluating medical multimodal capabilities, covering a variety of medical imaging modalities and anatomical regions. It aims to provide standardized testing resources for multimodal large language models (MLLMs) in medical vision-text understanding tasks to test their visual knowledge fusion and reasoning performance in the medical field.
Direct use:https://go.hyper.ai/qdvVe
3. Verse-Bench audio-visual joint generation evaluation dataset
Verse-Bench is a benchmark dataset for evaluating the joint generation of audio and video, released by StepFun in collaboration with the Hong Kong University of Science and Technology, the Hong Kong University of Science and Technology (Guangzhou), and other institutions. It aims to enable generative models to not only generate videos but also maintain strict temporal alignment with audio content (including ambient sound and speech).
Direct use:https://go.hyper.ai/mvau0

4. MMMC Educational Video Generation Benchmark Dataset
MMMC is a large-scale multidisciplinary educational video generation benchmark dataset for teaching video generation released by the Show Lab of the National University of Singapore. It aims to provide high-quality training and evaluation resources for educational artificial intelligence models and support research on automatically generating professional teaching videos from structured code and teaching content.
Direct use:https://go.hyper.ai/AELav
5. T2I-CoReBench Multimodal Image Generation Benchmark Dataset
T2I-CoReBench is a comprehensive evaluation benchmark for text-driven image generation models proposed by the University of Science and Technology of China, Kuaishou Technology's Kling team, and the University of Hong Kong. It aims to simultaneously measure the combination and reasoning capabilities of image generation models.
Direct use:https://go.hyper.ai/SLyED
6. WildSpeech-Bench Speech Understanding and Generation Benchmark Dataset
WildSpeech-Bench is the first benchmark released by Tencent for evaluating the speech-to-speech capabilities of SpeechLLM. It aims to measure the model's ability to understand and generate complete speech input to speech output (S2S) in real voice interaction scenarios.
Direct use:https://go.hyper.ai/Cy63e
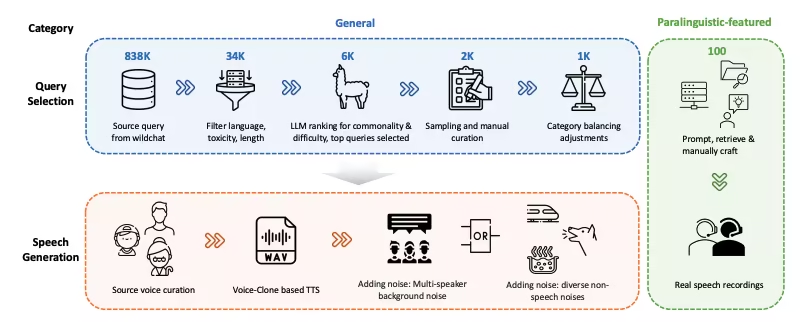
7. OmniRetarget global robot motion remapping dataset
OmniRetarget is a high-quality trajectory dataset for full-body motion remapping of humanoid robots, released by Amazon in collaboration with MIT, the University of California, Berkeley, and other institutions. It contains the motion trajectories of the G1 humanoid robot when interacting with objects and complex terrain, covering three scenarios: robot carrying objects, walking on terrain, and object-terrain mixed interaction.
Direct use:https://go.hyper.ai/xfZY4

8. Paper2Video paper video benchmark data
Paper2Video is the first benchmark dataset of paper and video pairs released by the National University of Singapore. It aims to provide a standard benchmark and evaluation resource for the task of automatically generating presentation videos (including slides, subtitles, audio, and speaker portraits) from academic papers.
Direct use:https://go.hyper.ai/NeRuV
9. FoMER Bench Multimodal Evaluation Dataset
FoMER Bench is a Foundational Model Embodied Reasoning (FoMER) benchmark covering three different robot types and multiple robot modes, designed to evaluate the reasoning ability of LMMs in complex embodied decision-making scenarios.
Direct use:https://go.hyper.ai/Tiy5w
10. OCRBench-v2 Text Recognition Benchmark Dataset
OCRBench-v2 is a multimodal large-scale optical character recognition (OCR) benchmark released by Huazhong University of Science and Technology in collaboration with South China University of Technology, ByteDance, and other institutions. It aims to evaluate the OCR capabilities of large multimodal models (LMMs) in different text-related tasks.
Direct use:https://go.hyper.ai/hhGFR
Selected Public Tutorials
This week we have compiled 4 categories of quality public tutorials:
* OCR tutorials: 2
* AI4S Tutorials: 2
* Large model tutorial: 1
* Multimodal tutorials: 6
OCR Tutorial
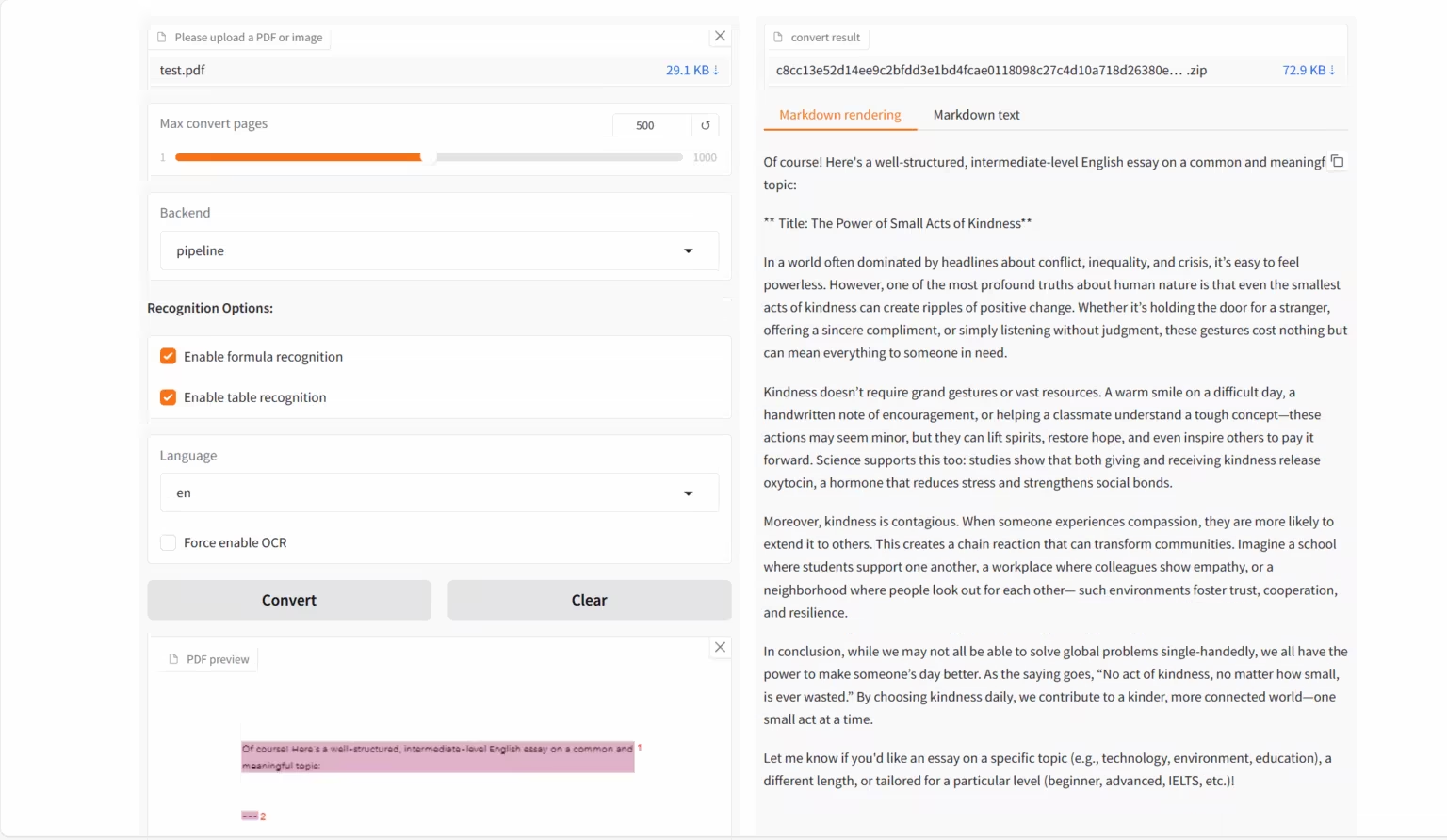
1. MinerU2.5-2509-1.2B: Document Parsing Demo
MinerU 2.5-2509-1.2B is a visual language model developed by OpenDataLab and Shanghai AI Lab, specifically designed for high-precision and efficient document parsing. It is the latest iteration of the MinerU series, focusing on converting complex document formats like PDF into structured, machine-readable data (e.g., Markdown and JSON).
Run online:https://go.hyper.ai/emEKs
2. Dolphin Multimodal Document Image Parsing
Dolphin is a multimodal document parsing model developed by the ByteDance team. This model uses a two-stage approach: first analyzing structure and then parsing content. The first stage generates a sequence of document layout elements, and the second stage uses these elements as anchors to parse the content in parallel. Dolphin has demonstrated outstanding performance across a variety of document parsing tasks, surpassing models such as GPT-4.1 and Mistral-OCR.
Run online: https://go.hyper.ai/lLT6X

AI4S Tutorial
1. BindCraft: Protein Binder Design
BindCraft, an open-source, one-click protein binder design pipeline developed by Martin Pacesa, boasts a claimed experimental success rate of 10–100%. It directly utilizes AlphaFold2 pre-trained weights to generate nanomolar-affinity de novo binders in silico, eliminating the need for high-throughput screening, experimental iteration, or even the need for known binding sites.
Run online:https://go.hyper.ai/eSoHk
2. Ml-simplefold: A lightweight protein folding prediction AI model
Ml-simplefold is a lightweight AI model for protein folding prediction launched by Apple. Based on flow matching technology, the model bypasses complex modules like multiple sequence alignment (MSA) and directly generates the three-dimensional structure of proteins from random noise, significantly reducing computational costs.
Run online: https://go.hyper.ai/Y0Us9
Large Model Tutorial
1. SpikingBrain-1.0: A large-scale brain-like spike model based on intrinsic complexity
SpikingBrain-1.0 is a large, domestically developed, controllable brain-inspired spiking model, released by the Institute of Automation, Chinese Academy of Sciences, in collaboration with the National Key Laboratory of Brain Cognition and Brain-Inspired Intelligence, Muxi Integrated Circuit Co., Ltd., and other institutions. Inspired by brain mechanisms, this model integrates a hybrid high-efficiency attention mechanism, a MoE module, and spike coding into its architecture, supported by a universal conversion pipeline compatible with the open source model ecosystem.
Run online:https://go.hyper.ai/i3zHC
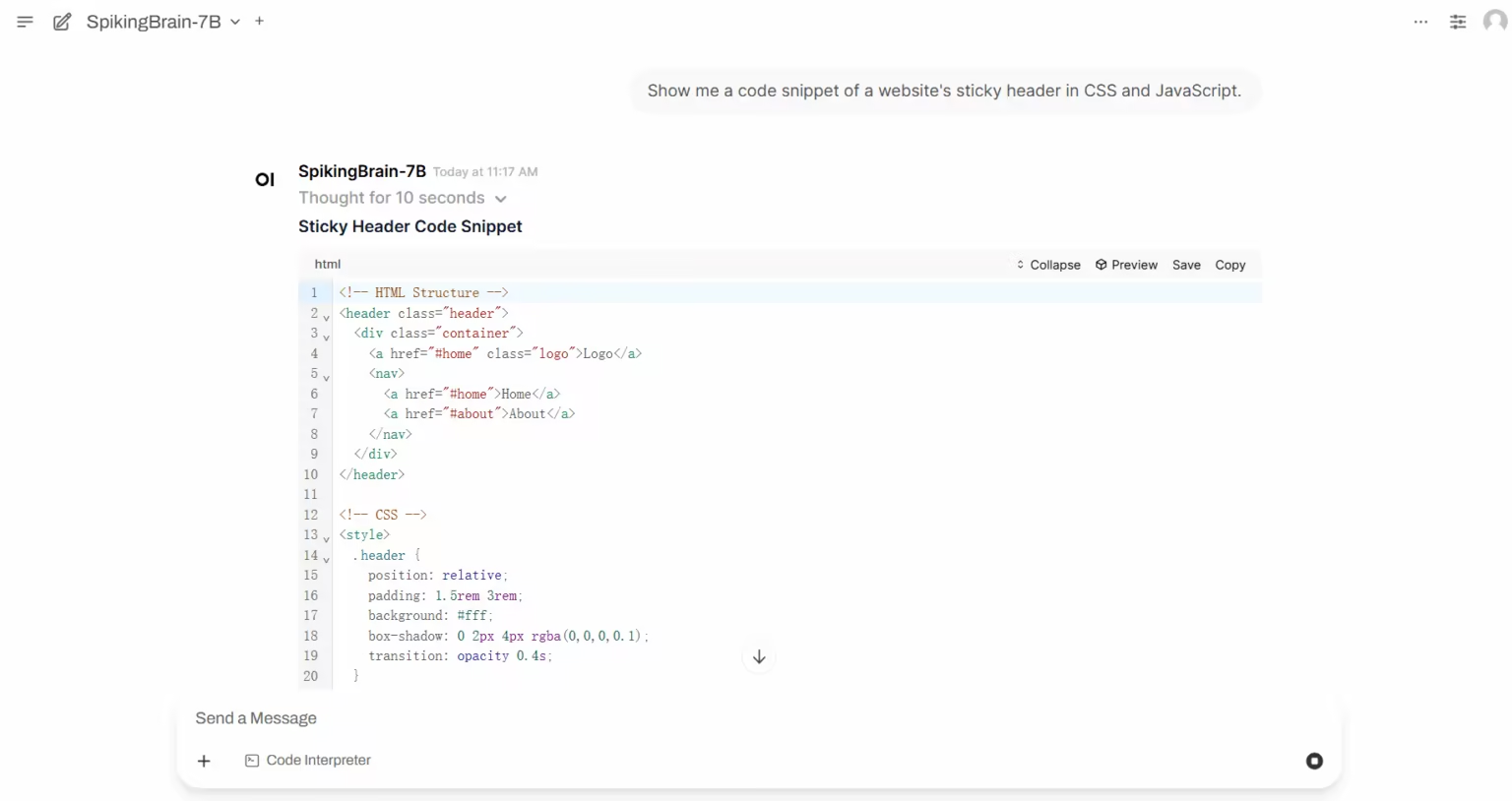
Multimodal Tutorial
1. HuMo-1.7B: Multimodal Video Generation Framework
HuMo is a multimodal video generation framework developed by Tsinghua University and ByteDance's Intelligent Creation Lab. It focuses on human-centric video generation and can generate high-quality, detailed, and controllable human-like videos from multiple modal inputs, including text, images, and audio.
Run online:https://go.hyper.ai/Xe4dM
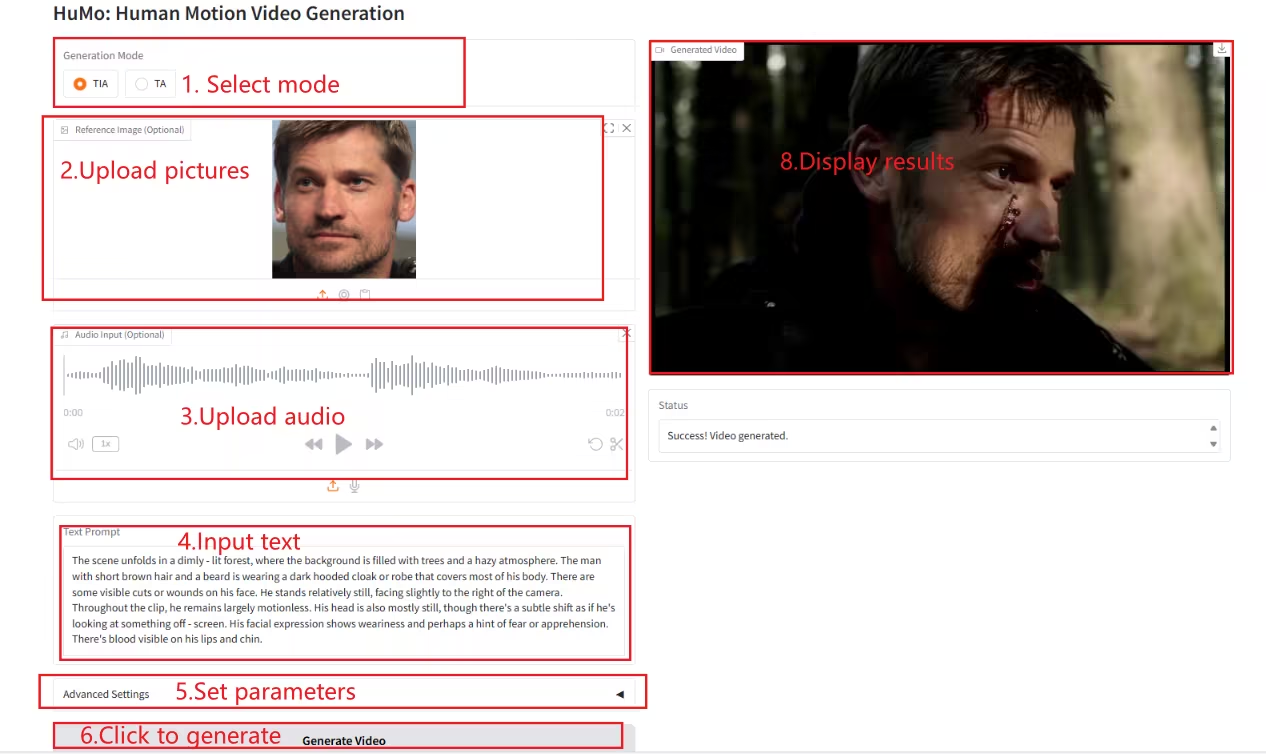
2. NeuTTS-Air: A lightweight and efficient voice cloning model
NeuTTS-Air is an end-to-end text-to-speech (TTS) model released by Neuphonic. Based on the 0.5B Qwen LLM backbone and the NeuCodec audio codec, it demonstrates few-shot learning capabilities in on-device deployment and instant voice cloning. System evaluations show that NeuTTS Air achieves state-of-the-art performance among open-source models, particularly on hyper-realistic synthesis and real-time inference benchmarks.
Run online:https://go.hyper.ai/7ONYq
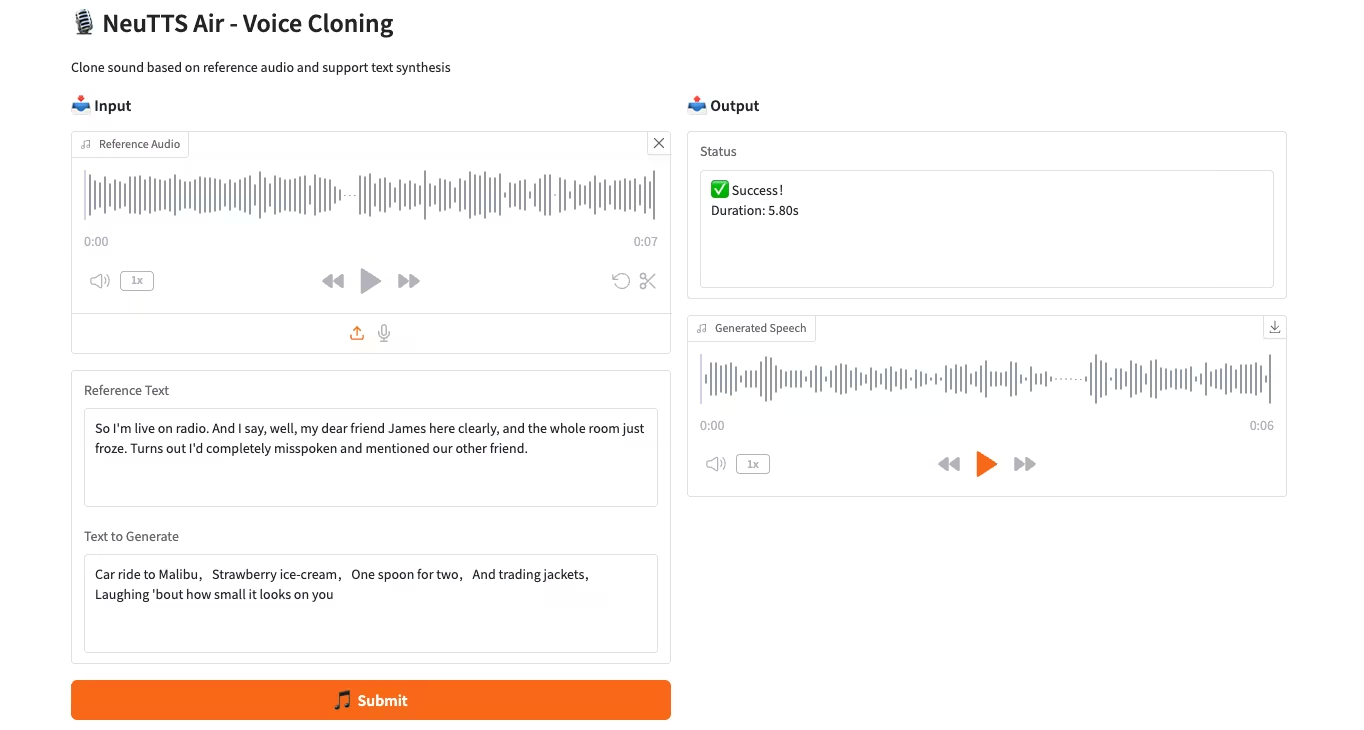
3. Moondream3-preview: Modular Visual Language Understanding Model
Moondream3, a visual language model based on a hybrid expert architecture proposed by the Moondream team, boasts 9 billion parameters (2 billion of which are activation parameters). This model provides state-of-the-art visual reasoning capabilities, supports a maximum context length of 32KB, and can efficiently process high-resolution images.
Run online:https://go.hyper.ai/eKGcP
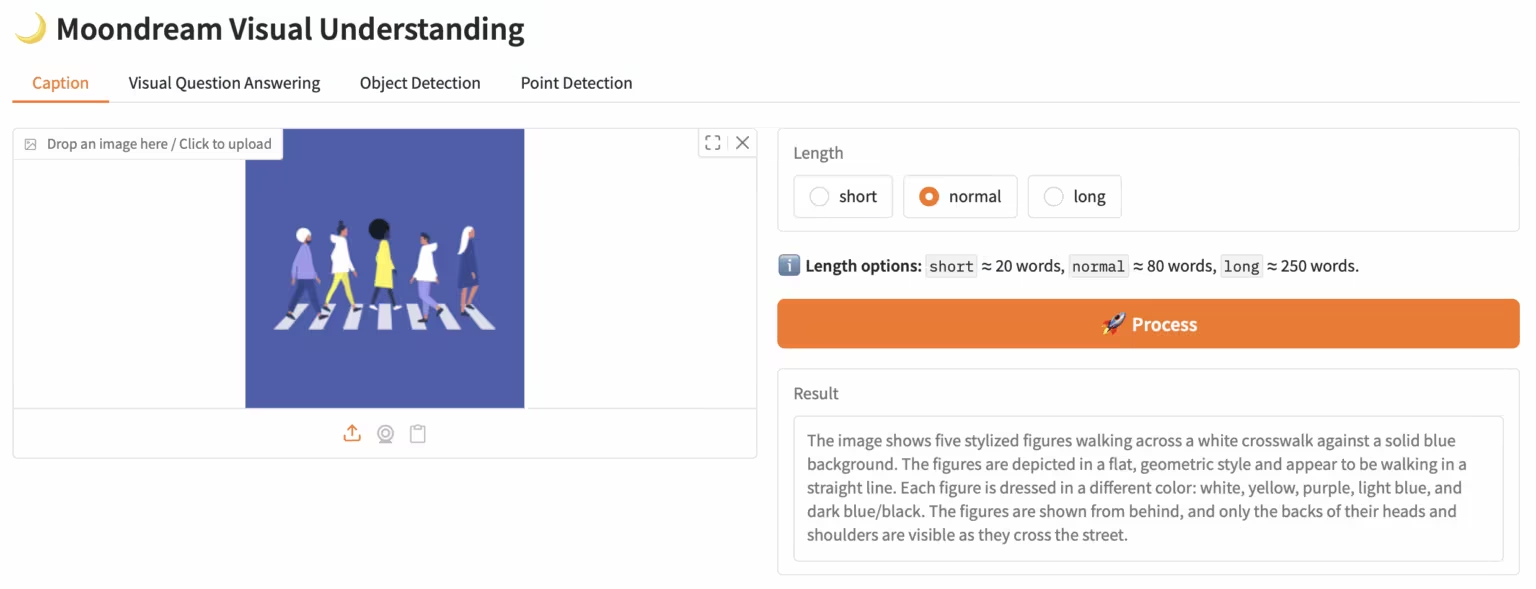
4. LiveCC: Real-time video commentary large model
LiveCC is a video language model project focused on large-scale streaming speech transcription. The project aims to train the first video language model with real-time commentary capabilities through an innovative video-automatic speech recognition (ASR) streaming method. It has achieved the current state-of-the-art in both streaming and offline benchmarks.
Run online:https://go.hyper.ai/3Gdr2
5. Hunyuan3D-Part: Component-based 3D Generative Model
Hunyuan3D-Part, a 3D generative model developed by the Tencent Hunyuan team, consists of P3-SAM and X-Part. It pioneered high-precision, controllable, component-based 3D model generation, supporting the automatic generation of over 50 components. It has broad applications in areas such as game modeling and 3D printing, such as separating a car model into its body and wheels to facilitate game-specific scrolling logic or step-by-step 3D printing.
Run online:https://go.hyper.ai/1w1Jq

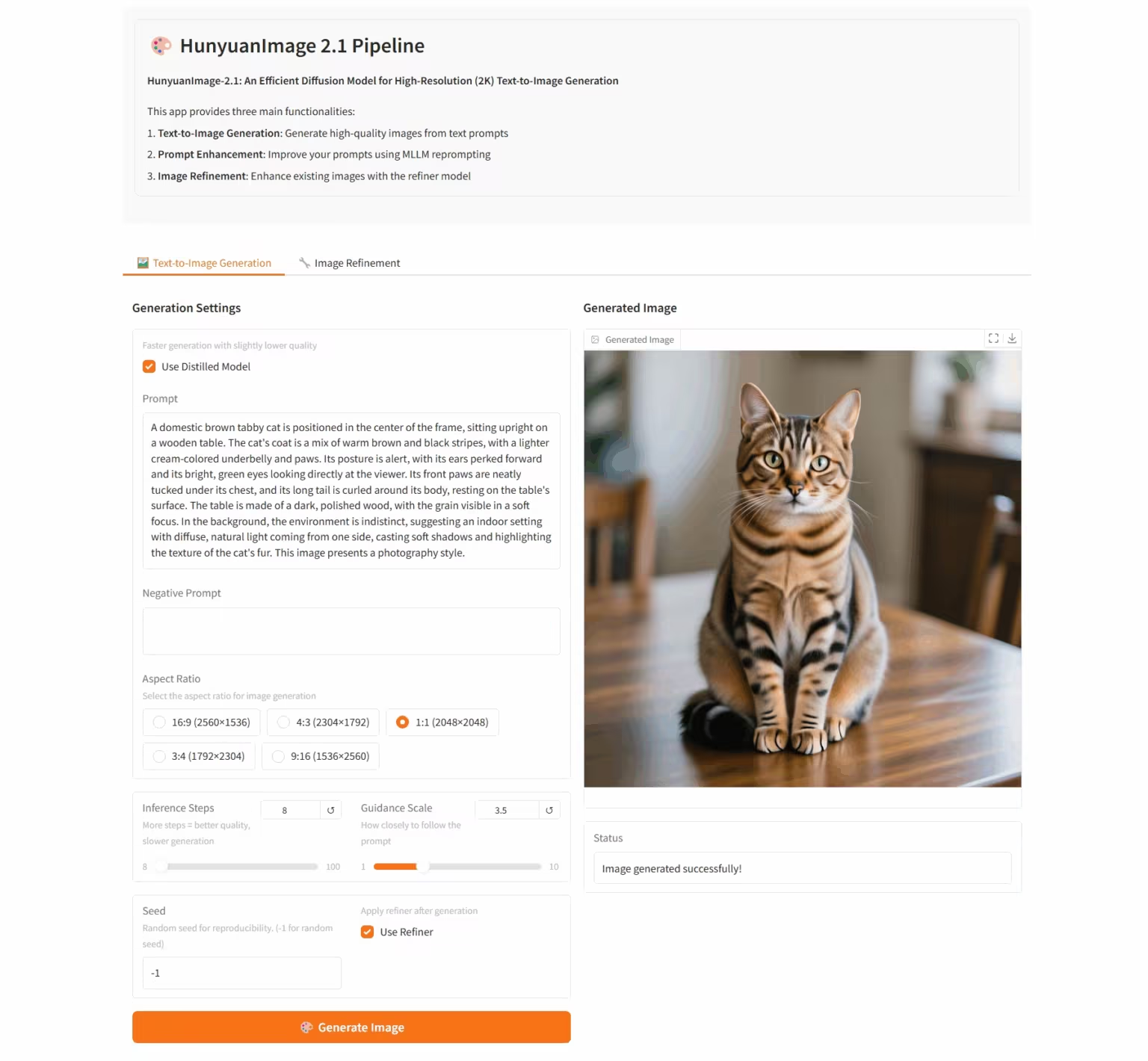
6. HunyuanImage-2.1: Diffusion Model for High-Resolution (2K) Wensheng Images
HunyuanImage-2.1 is an open-source text-based image model developed by the Tencent Hunyuan team. It supports native 2K resolution and possesses powerful complex semantic understanding capabilities, enabling accurate generation of scene details, character expressions, and actions. The model supports both Chinese and English input and can generate images in a variety of styles, such as comics and action figures, while maintaining robust control over text and details within the images.
Run online:https://go.hyper.ai/i96yp
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

This week's paper recommendation
1. QeRL: Beyond Efficiency — Quantization-enhanced Reinforcement Learning for LLMs
This paper proposes QeRL, a quantization-enhanced reinforcement learning framework for large language models. By combining NVFP4 quantization with Low-Rank Adaptation (LoRA), this model accelerates the RL sampling phase while significantly reducing memory overhead. QeRL is the first framework capable of training large reinforcement learning models with 32 billion parameters (32B) on a single H100 80GB GPU, while also improving overall training speed.
Paper link: https://go.hyper.ai/catLh
2. Diffusion Transformers with Representation Autoencoders
This paper explores replacing VAEs with pre-trained representation encoders (such as DINO, SigLIP, and MAE) combined with pre-trained decoders to construct a new architecture we call representation autoencoders (RAEs). These models not only achieve high-quality reconstruction, but also possess a semantically rich latent space and support scalable Transformer-based architecture design.
Paper link: https://go.hyper.ai/fqVs4
3. D2E: Scaling Vision-Action Pretraining on Desktop Data for Transfer to Embodied AI
This paper proposes the D2E (Desktop to Embodied AI) framework, demonstrating that desktop interaction can serve as an effective pre-training foundation for robotic embodied AI tasks. Unlike previous approaches that are limited to specific domains or data-enclosed, D2E establishes a complete technical chain from scalable desktop data collection to embodied domain verification and migration.
Paper link: https://go.hyper.ai/aNbE4
4. Thinking with Camera: A Unified Multimodal Model for Camera-Centric Understanding and Generation
This paper proposes Puffin, a unified, camera-centric multimodal model that extends spatial perception along the camera dimension, fuses language regression with diffusion-based generation techniques, and can parse and generate scenes from arbitrary viewpoints.
Paper link: https://go.hyper.ai/9JBvw
5. DITING: A Multi-Agent Evaluation Framework for Benchmarking Web Novel Translation
This paper proposes DITING, the first comprehensive evaluation framework for online novel translation. It systematically assesses the narrative consistency and cultural fidelity of translations along six dimensions: idiom translation, lexical ambiguity handling, terminology localization, tense consistency, zero pronoun resolution, and cultural safety, and is supported by over 18,000 expert-annotated Chinese-English sentence pairs.
Paper link:https://go.hyper.ai/KRUmn
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
1. The Hong Kong University of Science and Technology and others proposed the incremental weather forecast model VA-MoE, which has 751 parameters simplified and still achieves state-of-the-art performance.
Research teams from the Hong Kong University of Science and Technology and Zhejiang University have developed the Variable Adaptive Mixture of Experts (VA-MoE) model. This model uses phased training and variable index embedding to guide different expert modules to focus on specific meteorological variables. When new variables or stations are added, the model can be expanded without full retraining, significantly reducing computational overhead while maintaining accuracy.
View the full report:https://go.hyper.ai/nPWPN
2. NeurIPS 2025 | Huazhong University of Science and Technology and others released OCRBench v2. Gemini won the Chinese ranking but only received a passing score.
Bai Xiang's team from Huazhong University of Science and Technology, in collaboration with South China University of Technology, the University of Adelaide and ByteDance, launched the next-generation OCR evaluation benchmark OCRBench v2, which evaluated 58 mainstream multimodal models around the world from 2023 to 2025 in both Chinese and English.
View the full report:https://go.hyper.ai/AL1ZJ
3. Selected for NeurIPS 2025, the University of Toronto and others proposed the Ctrl-DNA framework to achieve "targeted control" of gene expression in specific cells.
A team from the University of Toronto, in collaboration with Changping Laboratory, developed a constrained reinforcement learning framework called Ctrl-DNA, which can maximize the regulatory activity of CRE in target cells while strictly limiting its activity in non-target cells.
View the full report:https://go.hyper.ai/eVORr
4. AI predicts plasma runaway. MIT and others use machine learning to achieve high-precision predictions of plasma dynamics with small sample sizes.
A research team led by MIT used scientific machine learning to intelligently fuse the laws of physics with experimental data. They developed a neural state-space model that can predict plasma dynamics and potential instabilities during the Tokamak Configuration Variable (TCV) ramp-down process using minimal data.
View the full report:https://go.hyper.ai/HQgZx
5. MOF structure wins Nobel Prize after 36 years: When AI understands chemistry, metal-organic frameworks are moving towards the era of generative research.
On October 8, 2025, Susumu Kitagawa, Richard Robson, and Omar Yaghi were awarded the Nobel Prize in Chemistry for their contributions to the field of metal-organic frameworks (MOFs). Over the past three decades, the MOF field has evolved from structural design to industrialization, laying the foundation for computable chemistry. Today, artificial intelligence is reshaping MOF research with generative models and diffusion algorithms, ushering in a new era of chemical design.
View the full report:https://go.hyper.ai/U5XgN
Popular Encyclopedia Articles
1. DALL-E
2. HyperNetworks
3. Pareto Front
4. Bidirectional Long Short-Term Memory (Bi-LSTM)
5. Reciprocal Rank Fusion
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
October deadline for the conference

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1800+ public datasets
* Includes 600+ classic and popular online tutorials
* Interpretation of 200+ AI4Science paper cases
* Supports 600+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:








