Command Palette
Search for a command to run...
Real-time Object Detection State-of-the-art! YOLOv13 Expands Global Awareness Capabilities; Selected for NeurIPS 2025, UltraHR-100K Unlocks ultra-high Resolution Textural images.

Real-time object detection has long been a cutting-edge research area in computer vision. From industrial detection to autonomous driving, the pursuit of "speed" and "accuracy" by the scientific and industrial communities has never ceased. In this field, the YOLO series of models has occupied a mainstream position due to its excellent balance between inference speed and accuracy.
However,From early versions of YOLO to the recent YOLOv11, and even YOLOv12 which uses a region self-attention mechanism, all face limitations in handling complex scenarios:Convolutional operations can only aggregate information within a fixed local receptive field, and their modeling ability is limited by the size of the convolutional kernel and the network depth. Although the self-attention mechanism expands the receptive field, it still needs to balance the high computational cost of global modeling and perception. More importantly, self-attention can essentially only model binary correlations between pixels.
To address these challenges, the YOLO series has been updated to its latest version, YOLOv13.The new version introduces a hypergraph-based adaptive relevance enhancement (HyperACE) mechanism, which adaptively utilizes potential higher-order relevances. This overcomes the limitations of previous methods, which were restricted to pairwise relevance modeling based on hypergraph computation, and achieves efficient global cross-location and cross-scale feature fusion and enhancement. Building upon the advantages of real-time detection in the YOLO series, the new version also introduces a series of new mechanisms such as higher-order semantic modeling and lightweight structural reconstruction.This extends traditional region-based pairwise interaction modeling to global high-order association modeling.
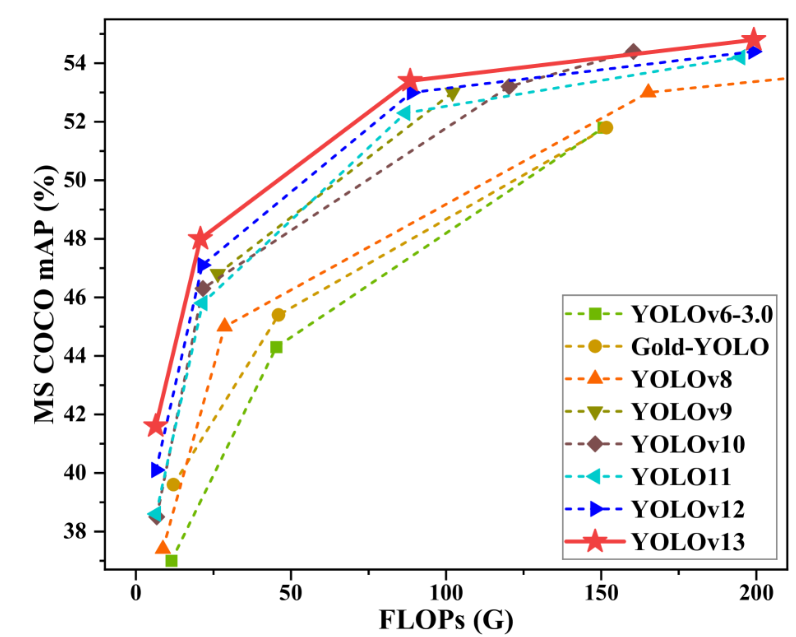
YOLOv13 has achieved comprehensive leadership on mainstream datasets such as MS COCO and Pascal VOC.It demonstrates stronger generalization capabilities and deployment practicality, providing more advanced performance options for applications in complex scenarios.
The HyperAI website now offers a one-click Yolov13 deployment feature. Give it a try!
Online use:https://go.hyper.ai/PAcy1
A quick overview of updates to the hyper.ai website from November 3rd to November 7th:
* High-quality public datasets: 10
* Selection of high-quality tutorials: 3
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
Top conferences with November deadlines: 5
Visit the official website:hyper.ai
Selected public datasets
1. Diabetes Health Indicators Dataset
Diabetes Health Indicators is a comprehensive health and medical analytics dataset designed to support diabetes risk prediction, public health research, and machine learning modeling. The dataset contains 31 diabetes feature fields, covering four main categories of variables: demographic characteristics, lifestyle, medical history, and clinical indicators.
Direct use:https://go.hyper.ai/nVnPo
2. Nemotron Personas USA: A dataset of American persona datasets.
Nemotron-Personas-USA is a large-scale synthetic user profile dataset released by NVIDIA, designed to support the training and evaluation of large language models (LLMs) and intelligent agent systems in tasks such as dialogue generation, role simulation, user modeling, and diverse behavior analysis.
Direct use:https://go.hyper.ai/lMA6r
3. UltraHR-100K Ultra-High Resolution Image Dataset
UltraHR-100K is a large-scale, high-quality dataset for the ultra-high resolution (UHR) text-to-image (T2I) task, designed to improve the ability of diffusion models in fine-grained detail synthesis, content diversity representation, and visual fidelity. The dataset contains approximately 100,000 ultra-high resolution images, covering a wide range of subjects including people and architecture. Each image has a resolution exceeding 3K and is accompanied by high-quality rich text descriptions.
Direct use:https://go.hyper.ai/I3Fwl

4. Lifestyle Data
Lifestyle Data is a comprehensive health and fitness behavior dataset designed to provide a high-quality data foundation for personalized health recommendation systems, exercise analysis, and lifestyle prediction modeling. This dataset integrates information on individuals across multiple dimensions, including daily diet, exercise, physiological indicators, and body composition, and is presented in a structured table (CSV) format with complete fields covering multi-level variables such as individual characteristics, exercise performance, dietary structure, and fitness behavior.
Direct use:https://go.hyper.ai/SGK9K
5. Global Earthquake-Tsunami Risk Dataset
The Global Earthquake-Tsunami Risk Assessment is a global dataset for earthquake and tsunami risk assessment, designed to provide a standardized and computable data foundation for tsunami risk prediction, earthquake event analysis, and earthquake hazard assessment.
Direct use:https://go.hyper.ai/a9Nrz
6. ShiftySpeech speech distribution evaluation dataset
ShiftySpeech is a large-scale synthetic speech detection benchmark released by Johns Hopkins University. It aims to study the generalization ability of speech synthesis detection models in the real world when faced with "distribution drift" (including changes in language, speaker, generation model, and recording conditions).
Direct use:https://go.hyper.ai/YMKSP
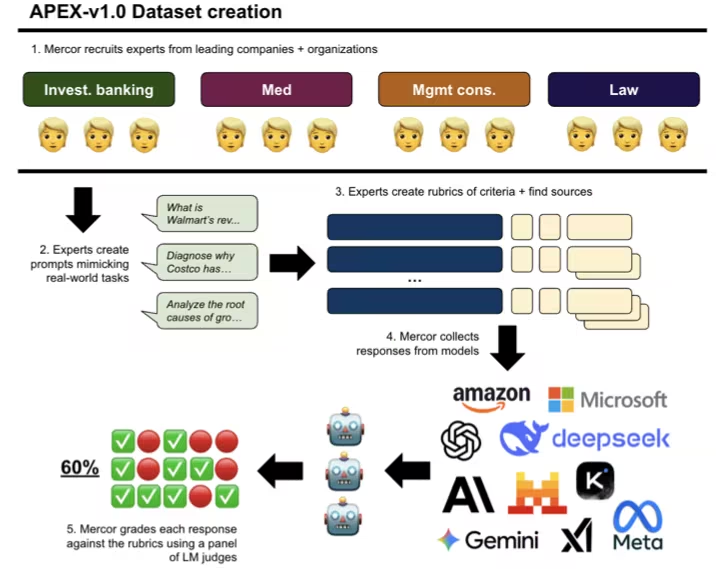
7. APEX AI Productivity Benchmark Dataset
APEX is a comprehensive benchmark dataset first released by the Mercor research team in collaboration with Harvard Law School and the Scripps Research Institute. It is used to evaluate the performance of cutting-edge artificial intelligence models in high-economic-value knowledge work. It aims to measure the performance of cutting-edge artificial intelligence models in real economic tasks, rather than just staying at the level of abstract reasoning.
Direct use:https://go.hyper.ai/3E2on
8. Multi-LMentry Multilingual Basic Task Benchmark Dataset
Multi-LMentry is a multilingual benchmark dataset designed to systematically evaluate the cross-lingual generalization ability of large language models (LLMs) for low-level language understanding and basic reasoning tasks in multilingual environments. The dataset covers nine languages, including English and German. The tasks are manually redesigned by native speakers, similar in form to the original LMentry framework, but not directly translated, to ensure naturalness and cultural fit.
Direct use:https://go.hyper.ai/o2uJC
9. Ditto-1M instruction-driven video editing dataset
Ditto-1M is an instruction-driven video editing dataset developed by the Hong Kong University of Science and Technology in collaboration with Ant Group, Zhejiang University, and other institutions. It aims to promote the development of video editing models based on natural language instructions and improve the model's understanding of complex instructions and the accuracy of video generation through large-scale, high-quality synthetic samples.
Direct use:https://go.hyper.ai/o2uJC

10. Reac-Discovery Chemical Reactor Performance Dataset
Reac-Discovery, released by Jaume I University, is a dataset for AI-driven flow reactor design and reaction performance optimization. This dataset is automatically generated during experiments using the team's self-developed Reac-Discovery platform, without using any external publicly available data sources. The dataset covers three categories of data: geometry, printability, and reaction performance, corresponding to the platform's Reac-Gen, Reac-Fab, and Reac-Eval functional modules.
Direct use:https://go.hyper.ai/bMxVY
Selected Public Tutorials
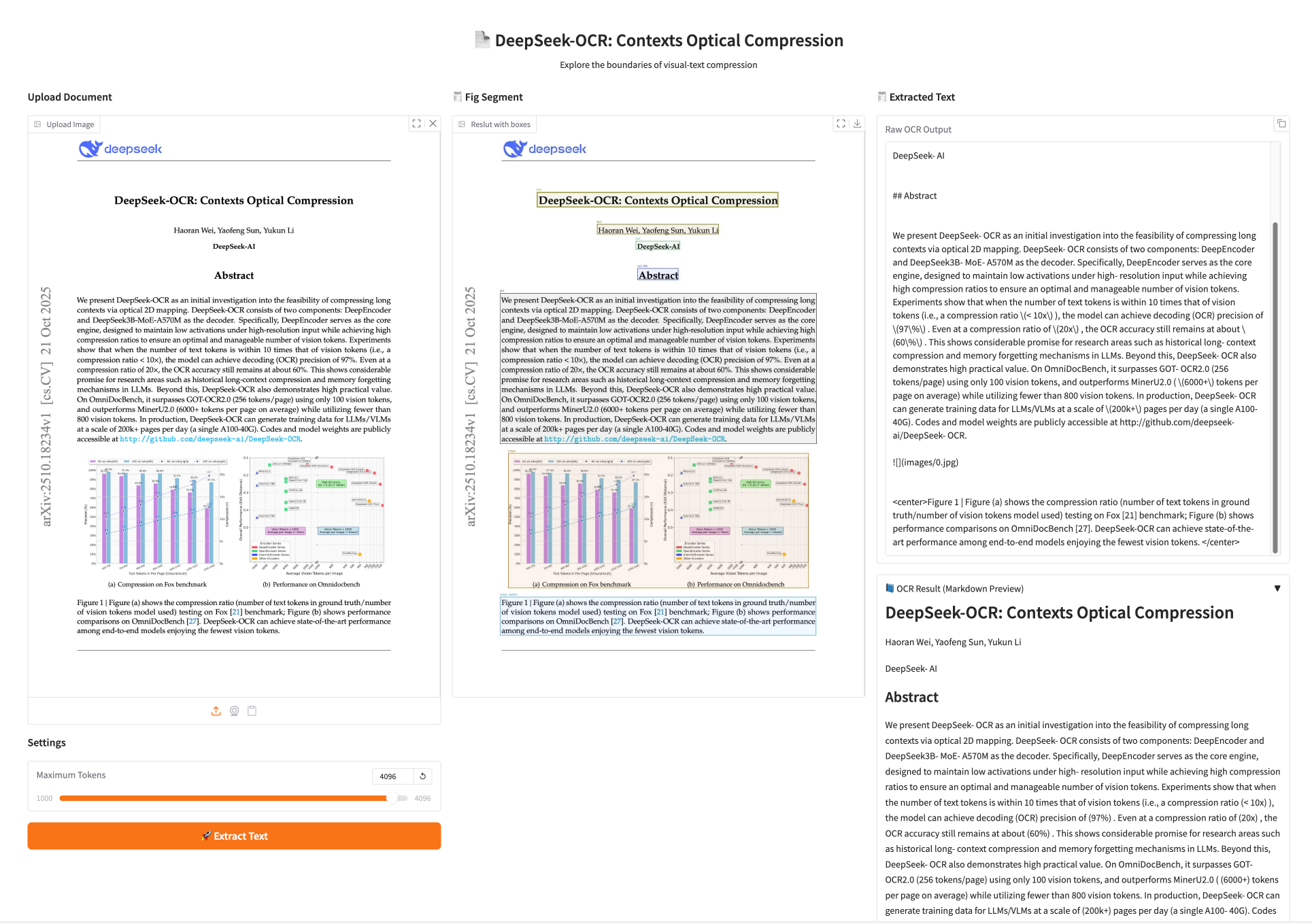
1. DeepSeek-OCR: "Visual Compression" Replaces Traditional Character Recognition
DeepSeek-OCR, released by DeepSeek Inc., is a preliminary study on the feasibility of compressing long contexts from images. Experiments show that when the number of text tokens does not exceed 10 times that of visual tokens (i.e., compression ratio < 10×), the model can achieve a decoding (OCR) accuracy of 971 TP3T. Even at a compression ratio of 20×, the OCR accuracy is still approximately 601 TP3T.
Run online:https://go.hyper.ai/wmghV
2. Nanonets-OCR2-3B: More accurate interpretation of visual elements in complex documents
Nanonets-OCR2-3B is an image-to-Markdown model released by Nanonets. Nanonets-OCR2-3B can not only convert documents into structured Markdown, but also leverage intelligent content recognition, semantic tagging, and context-aware visual question answering to gain a deeper understanding and more accurate interpretation of complex documents.
Run online: https://go.hyper.ai/3DWbb
3. One-click deployment of Yolov13
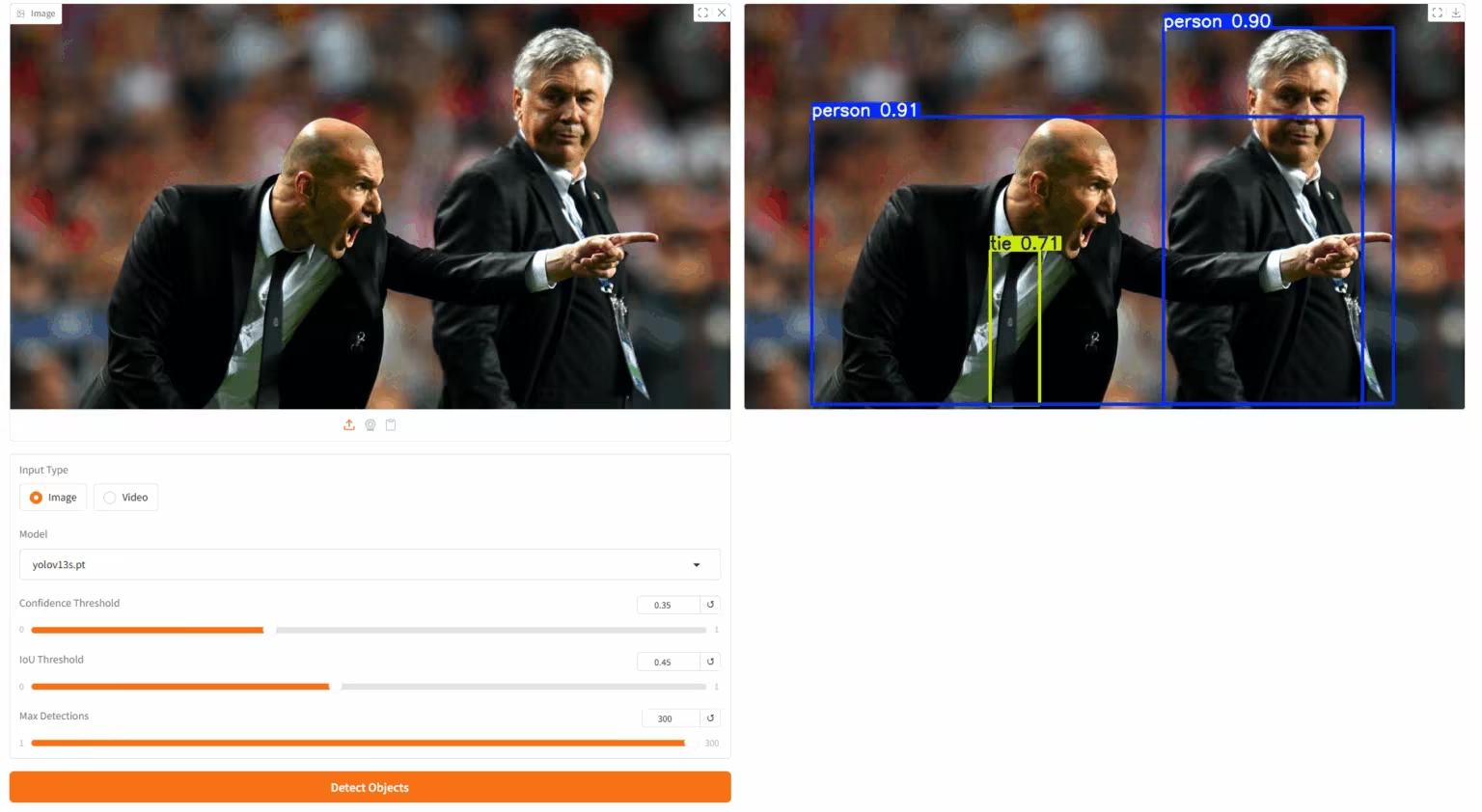
YOLOv13 is an object detection model proposed by a joint research team from Tsinghua University, Taiyuan University of Technology, Xi'an Jiaotong University, and other universities. Building upon the advantages of real-time detection in the YOLO series, this model introduces a series of new mechanisms such as hypergraph enhancement, high-order semantic modeling, and lightweight structural reconstruction. It achieves comprehensive leadership on mainstream datasets such as MS COCO and Pascal VOC, demonstrating stronger generalization ability and practical deployment.
Run online:https://go.hyper.ai/PAcy1
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

This week's paper recommendation
1. Every Activation Boosted: Scaling General Reasoner to 1 Trillion Open Language Foundation
This article introduces Ling 2.0, a language foundation model for serialized reasoning tasks built on the core principle of "enhancing reasoning ability with each activation." Under a unified Mixture-of-Experts (MoE) architecture, this model can scale from billions to trillion parameters, emphasizing high sparsity, cross-scale consistency, and efficiency guided by empirical scaling laws.
Paper link:https://go.hyper.ai/O4pRV
2. ThinkMorph: Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning
This paper constructs ThinkMorph—a unified model fine-tuned on 24,000 high-quality interleaved reasoning trajectories, covering a variety of tasks with varying levels of visual involvement, capable of generating progressively advancing graph-text reasoning steps, and maintaining coherent semantic logic while manipulating visual content.
Paper link:https://go.hyper.ai/AGtSS
3. Don't Blind Your VLA: Aligning Visual Representations for OOD Generalization
This study systematically examined the preservation of representations during the fine-tuning of Vision-Language-Action (VLA) models, finding that direct action fine-tuning leads to a degradation in visual representation performance. To characterize and measure this impact, researchers explored the hidden representations of VLA models and analyzed their attention maps. Furthermore, a series of targeted tasks and methods were designed to compare VLA models with their corresponding VLM models, thereby isolating the changes in visual-language ability caused by action fine-tuning.
Paper link:https://go.hyper.ai/xNU6P
4. OS-Sentinel: Towards Safety-Enhanced Mobile GUI Agents via Hybrid Validation in Realistic Workflows
This paper proposes a novel hybrid security detection framework, OS-Sentinel, which collaboratively detects explicit system-level violations through a formal verifier, while simultaneously evaluating contextual risks and proxy behaviors using a VLM-based contextual judge.
Paper link:https://go.hyper.ai/bG6b5
5. VCode: a Multimodal Coding Benchmark with SVG as Symbolic Visual Representation
This paper proposes VCode—a benchmark framework that refactors multimodal understanding into a code generation task: given an image, the model must generate SVG code that preserves symbolic semantics to support downstream inference. The framework covers three domains: general commonsense understanding (MM-Vet), subject-specific knowledge (MMMU), and visual perception-centric tasks (CV-Bench).
Paper link:https://go.hyper.ai/UNmqK
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
In October 2025, Google DeepMind CEO Demis Hassabis graced the cover of Time magazine's TIME 100 list. From AlphaGo to AlphaFold, Hassabis adhered to the scientific orientation of AI4S, but with DeepMind's integration into Google, numerous media outlets criticized DeepMind's commercial ambitions and ethical controversies.
View the full report:https://go.hyper.ai/vSqZI
Neuphonic's latest open-source end-to-end speech synthesis model, NeuTTS-Air, achieves state-of-the-art (SOTA) performance among open-source models, particularly in hyper-realistic synthesis and real-time inference benchmarks. It can also generalize to new scenarios such as embedded agents and style transfer, supports 3-second audio cloning, and generates natural-sounding dialogue content.
View the full report:https://go.hyper.ai/5kAIi
A joint team from ETH Zurich, Caltech, and the University of Alberta has proposed a deep learning framework called NOBLE. It is the first large-scale deep learning framework to validate its performance using experimental data from the human cerebral cortex, and for the first time, it directly learns the nonlinear dynamics of neurons from experimental data, achieving simulation speeds 4200 times faster than traditional numerical solvers.
View the full report:https://go.hyper.ai/oQ74B
Founded by three college dropouts who were only 22 years old, Mercor raised $350 million in Series C funding in less than three years, with its valuation soaring to $10 billion. The company reduces traditional recruitment efficiency to mere seconds through its AI-powered recruitment model and launched the APEX benchmark, providing a new standard for assessing the economic value of AI.
View the full report:https://go.hyper.ai/kBj1w
A research team led by Professor David Baker from the University of Washington has developed a graph neural network called PLACER, which can accurately generate the structures of various organic small molecules based on the atomic composition and bonding information of small molecules; and, given the macroscopic structure of proteins, it can construct the detailed structures of small molecules and protein side chains for protein-small molecule docking tasks.
View the full report:https://go.hyper.ai/sisqO
Popular Encyclopedia Articles
1. DALL-E
2. HyperNetworks
3. Pareto Front
4. Bidirectional Long Short-Term Memory (Bi-LSTM)
5. Reciprocal Rank Fusion
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
November deadline for the summit
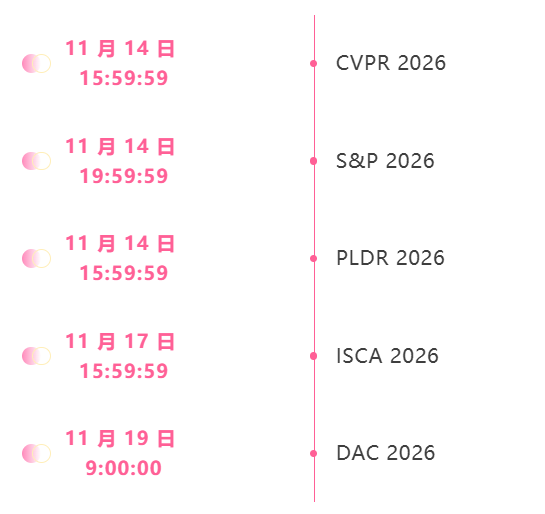
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








