Command Palette
Search for a command to run...
A New Paradigm for Audio Aesthetics Assessment! Audiobox-Aesthetics Pioneered four-dimensional Audio Quantification; 6.7 Million Cases! Caselaw Unlocks the Compliance Blueprint for Legal Reference

Traditional audio evaluation usually relies on manual listening, and its subjective bias makes it difficult to unify the evaluation standards. Although existing evaluation methods and tools can give certain evaluation results, most of them only focus on the overall audio quality and lack targeted analysis of local details.
to this end,Meta AI launched Audiobox-Aesthetics, an audio quality assessment tool.Realize multi-dimensional automatic analysis of speech, music and environmental sounds.Comprehensively evaluate audio quality through four core dimensions: Production Quality, Production Complexity, Content Enjoyment, and Content Usefulness.It not only makes up for the inherent defects of manual listening and existing tools, but also provides professional-level quantitative analysis for audio creators, engineers and researchers, and provides precise guidance for audio optimization.
At present, the HyperAI official website has launched the "AudioBox-Aesthetics Audio Aesthetics Evaluation Demo", come and try it~
Online use:https://go.hyper.ai/FNpIQ
From July 21st to July 25th, hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 8
* This week's recommended papers: 5
* Community article interpretation: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in August: 9
Visit the official website:hyper.ai
Selected public datasets
1. Medical Information Drug Information Dataset
The Medical Information Dataset (MID dataset) is currently the largest and most representative drug information dataset. The dataset contains data from 44 different therapeutic categories, covering more than 192,000 drugs, and aims to provide accurate and authoritative drug information, support drug classification and therapeutic labels, and improve the prediction and efficiency of clinical trial management.
Direct use:https://go.hyper.ai/qmGCW
2. Nemotron-Math-HumanReasoning Mathematical Reasoning Dataset
Nemotron-Math-HumanReasoning is a mathematical reasoning dataset released by NVIDIA, which aims to simulate the extended reasoning style of models such as DeepSeek-R1. The dataset contains 50 math problems from the OpenMathReasoning dataset, 200 manually written answers, and an additional 50 answers generated by QwQ-32B-Preview.
Direct use:https://go.hyper.ai/udrjz
3. Updesh Indic synthetic text dataset
Updesh is an Indian language synthetic text dataset released by Microsoft, which aims to promote the post-training of large language models (LLMs) for Indian languages. The dataset contains 6,800,000 inference data and 2,100,000 generated data, covering languages such as Assamese and Bengali.
Direct use:https://go.hyper.ai/wMWci
4. QMOF150 quantum chemistry dataset
QMOF150 is a quantum chemistry dataset released by Meta and the University of Cambridge to accelerate the discovery of quantum materials. The dataset contains about 14,000 metal organic frameworks (MOFs) and coordination polymers. Among them, the calculated properties of experimentally characterized MOFs after structural relaxation by DFT are included, including but not limited to optimized geometry, energy, band gap, charge density, state density, partial charge, spin density and bond order.
Direct use:https://go.hyper.ai/2rxVD
5. Safety Vests Detection Safety Vest Detection Dataset
Safety Vests Detection is a safety vest detection dataset designed to benchmark new object detection architectures (YOLOv8, Faster-RCNN, SSD, etc.), transfer learning of related PPE detection tasks (helmets, gloves, goggles), and prototype development of edge-deployed safety monitors, helping to develop and train models to automatically identify and detect people wearing safety vests and improve workplace safety. The dataset includes 3,897 high-definition photos, bounding box annotations, and image context.
Direct use:https://go.hyper.ai/q0aEL

6. Open-Omega-Atom-1.5M Mathematical and Scientific Reasoning Dataset
Open-Omega-Atom-1.5M is a mathematical and scientific reasoning dataset designed to enhance reasoning capabilities in the fields of mathematics and science. The dataset contains about 1.5 million pieces of data and is designed for mathematics, science, and code applications, with mathematical data playing an important role in its composition.
Direct use:https://go.hyper.ai/ctAbA
7. AF-Chat Audio Conversation Text Dataset
AF-Chat is an audio conversation text dataset released by NVIDIA for training and evaluating conversation generation models. The dataset contains about 75,000 multi-turn, multi-audio conversations (average 4.6 segments and 6.2 rounds; range 2-8 segments and 2-10 rounds), covering speech, environmental sounds, and music.
Direct use:https://go.hyper.ai/mx6G0
8. rStar Coder competition-level coding problem dataset
rStar Coder is a large-scale competition-level coding problem dataset released by Microsoft, which aims to enhance the code reasoning ability of large language models, especially in dealing with competition-level coding problems. The dataset contains 418,000 competition-level programming problems, 580,000 long reasoning solutions, and a rich variety of test cases (with different levels of difficulty). Each solution has been verified by various simulated test cases of different difficulty levels.
Direct use:https://go.hyper.ai/uJXHe
9. Caselaw Legal Literature Dataset
Caselaw is a legal literature dataset published by the University of Toronto that contains 6.7 million cases from the Caselaw Access Project and Court Listener. The Caselaw Access Project and Court Listener obtain legal data from a variety of sources, including only documents that are in the public domain, such as the Harvard Law Library, the Law Library of Congress, and the Supreme Court Database.
Direct use:https://go.hyper.ai/a1bET
10. APM protein generation dataset
APM is a protein generation dataset released in 2025 by Hunan University, University of the Chinese Academy of Sciences, and ByteDance Seed Team. It consists of single-chain protein datasets and multi-chain protein datasets.
Direct use:https://go.hyper.ai/p4qgN
Selected Public Tutorials
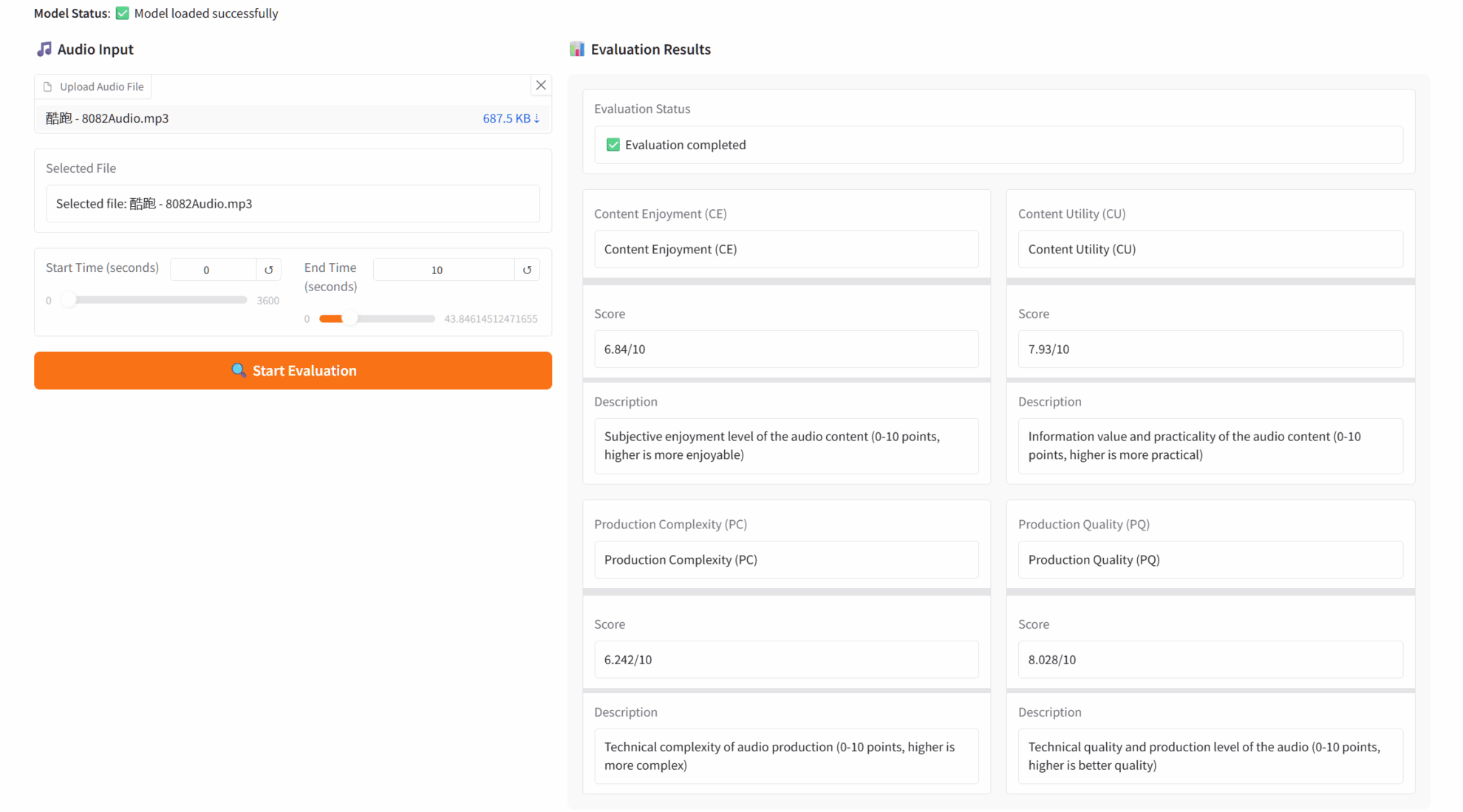
1. AudioBox-Aesthetics Audio Aesthetics Evaluation Demo
Audiobox-Aesthetics is an audio quality assessment tool released by Meta AI. Based on deep learning technology, the tool realizes multi-dimensional automatic analysis of speech, music and environmental sounds, comprehensively evaluates audio quality through four core dimensions, and provides professional-level quantitative analysis for audio creators, engineers and researchers.
Run online:https://go.hyper.ai/FNpIQ
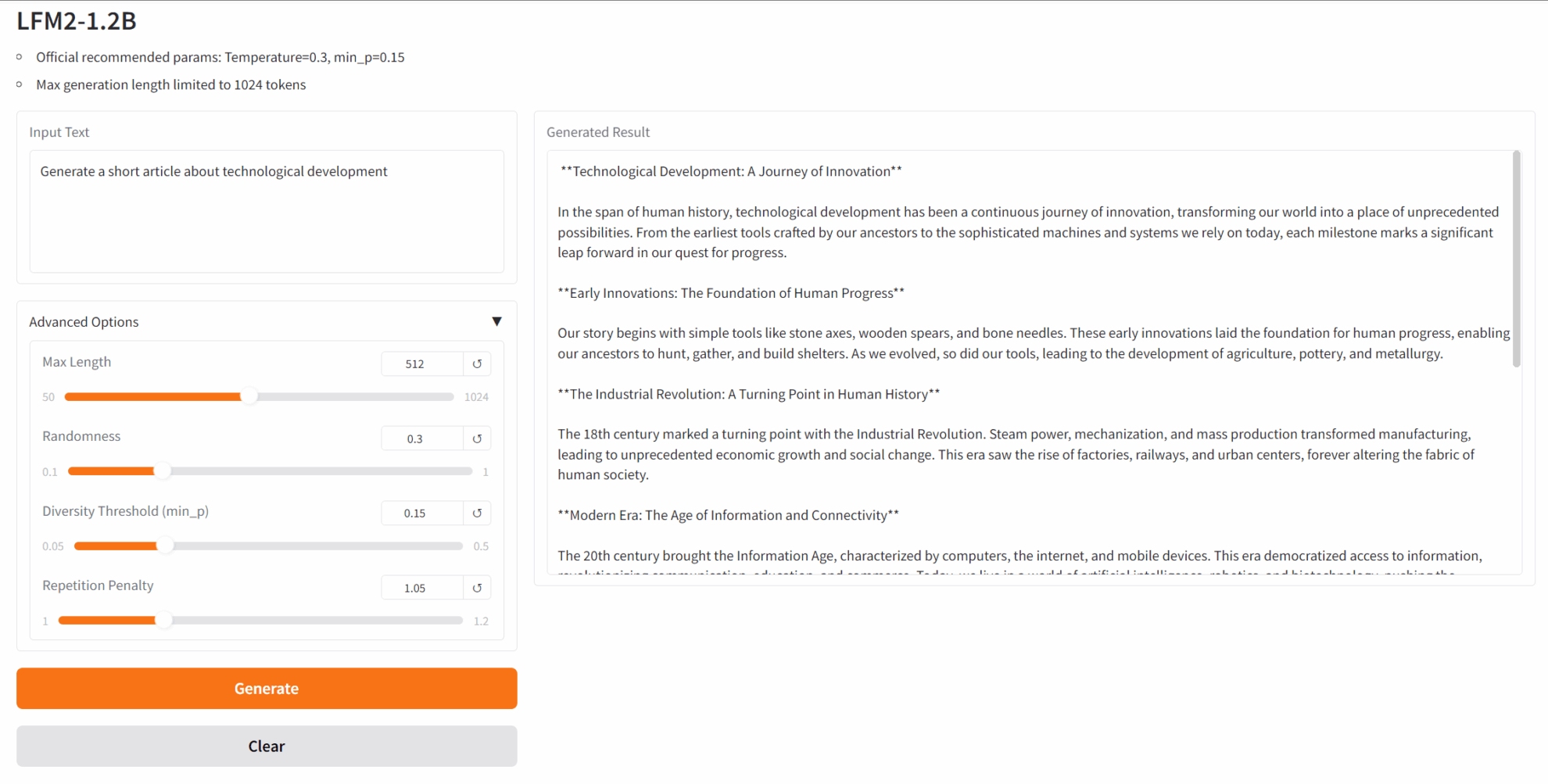
2. LFM2-1.2B: Efficient Edge-Deployed Text Generation Model
LFM2-1.2B is the second generation of Liquid Foundation Models (LFMs) launched by Liquid AI. It is a generative AI model based on a hybrid architecture. It aims to provide the fastest on-device generative AI experience in the industry and is designed for low-latency on-device language model workloads.
Run online:https://go.hyper.ai/fEtm9
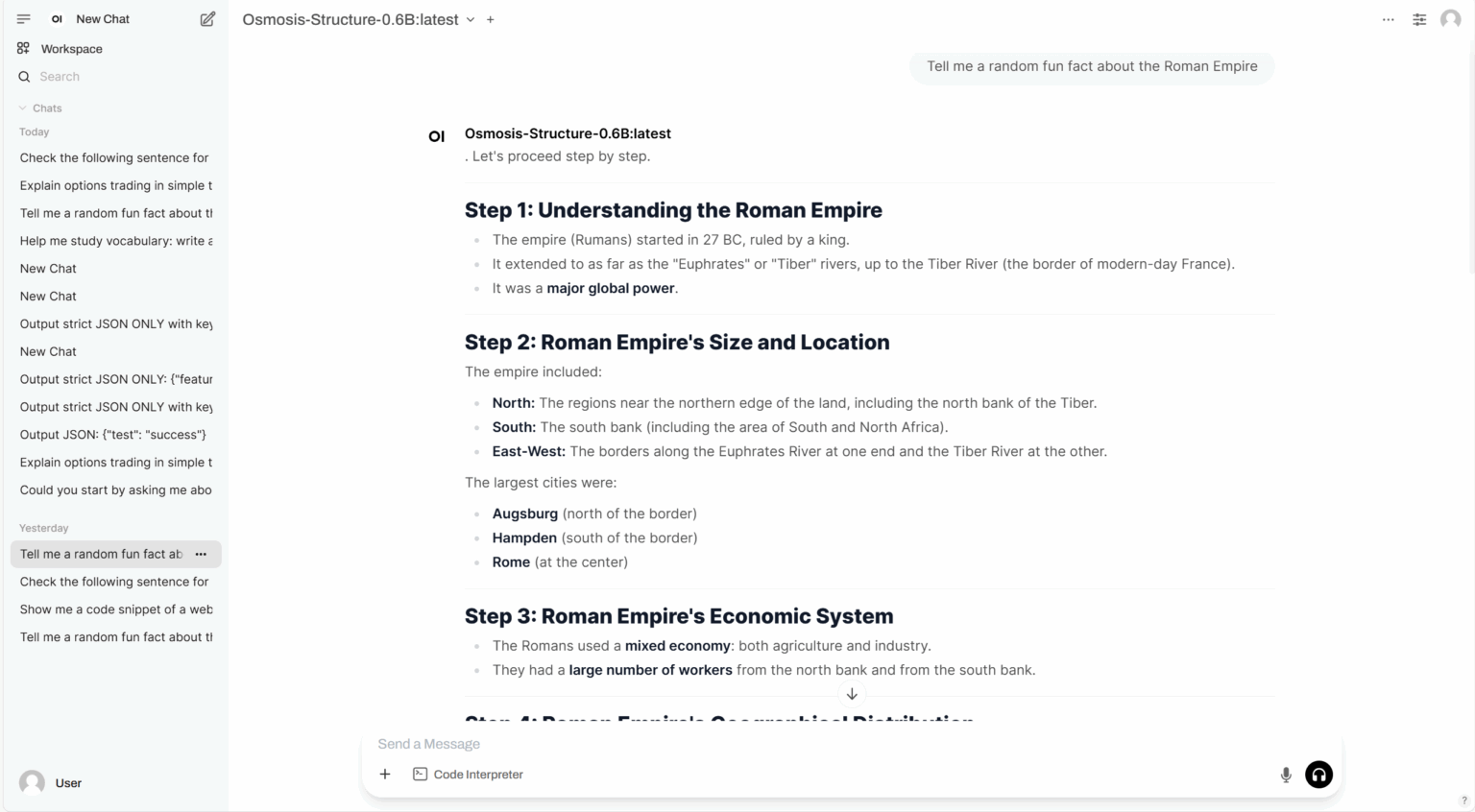
3. Osmosis-Structure-0.6B: A small language model with structured output
Osmosis-Structure-0.6B is a specialized small language model (SLM) launched by Osmosis, designed to complete structured output generation tasks. Despite its parameter size of only 0.6B, the model shows excellent performance in extracting structured information when used in conjunction with supported frameworks.
Run online:https://go.hyper.ai/ayrhc
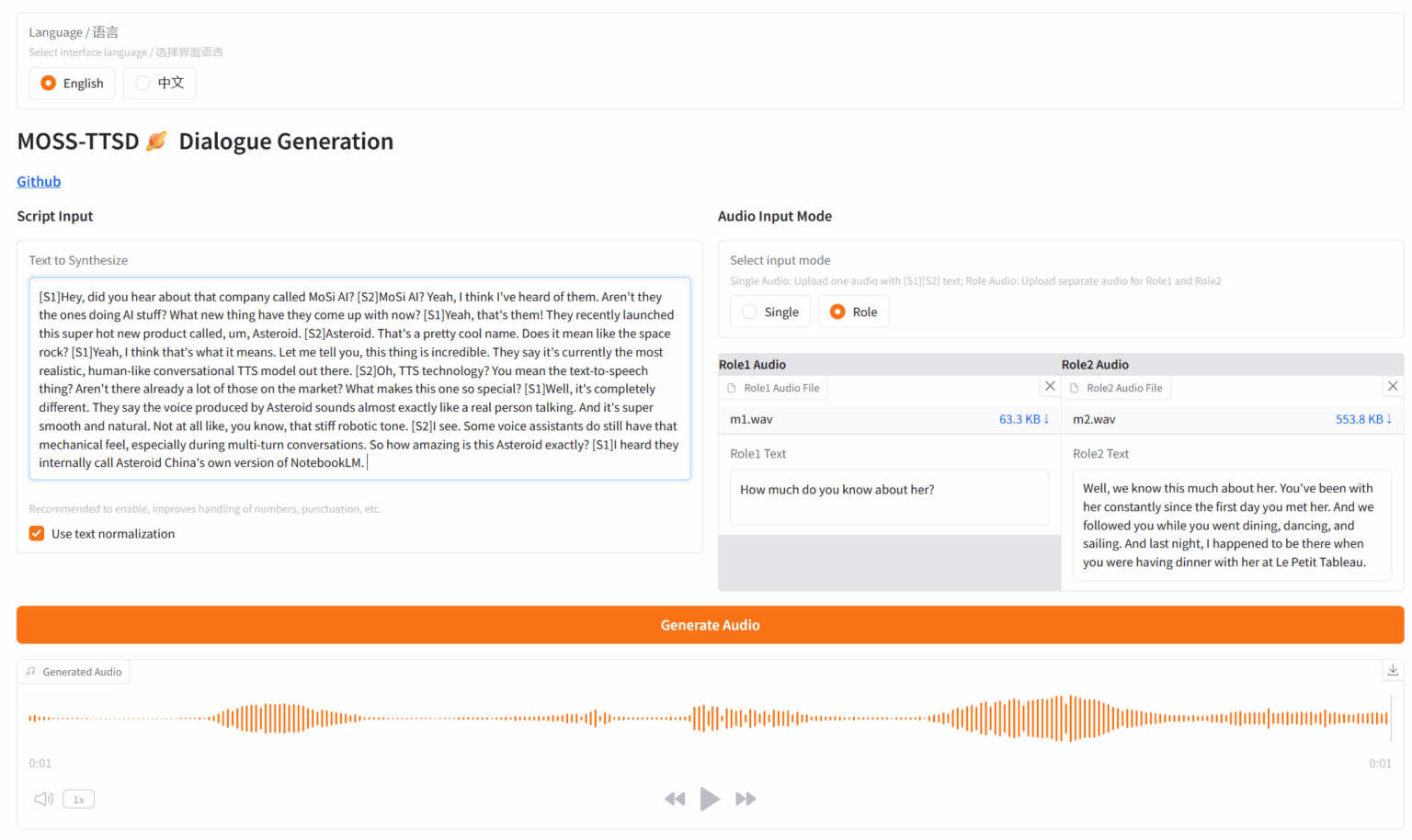
4. MOSS: Text-to-Spoken Dialogue Generation
MOSS-TTSD is an open source bilingual spoken dialogue synthesis model released by the OpenMOSS team, supporting Chinese and English. It is able to convert a conversation script between two speakers into natural, expressive conversational speech. MOSS-TTSD supports voice cloning and long single-segment speech generation, making it an ideal choice for AI podcast production.
Run online:https://go.hyper.ai/FOpMa
5. isometric-skeumorphic-3d-bnb: Isometric 3D style icon generation
isometric-skeumorphic-3d-bnb is a LoRA model released by the group multimodalart, which focuses on generating 3D isometric icons with both skeuomorphic design aesthetics and stylized characteristics. The model performs well when dealing with real-world objects and architectural landmarks, and can transform them into highly recognizable icon-style illustrations.
Run online:https://go.hyper.ai/3BnDy

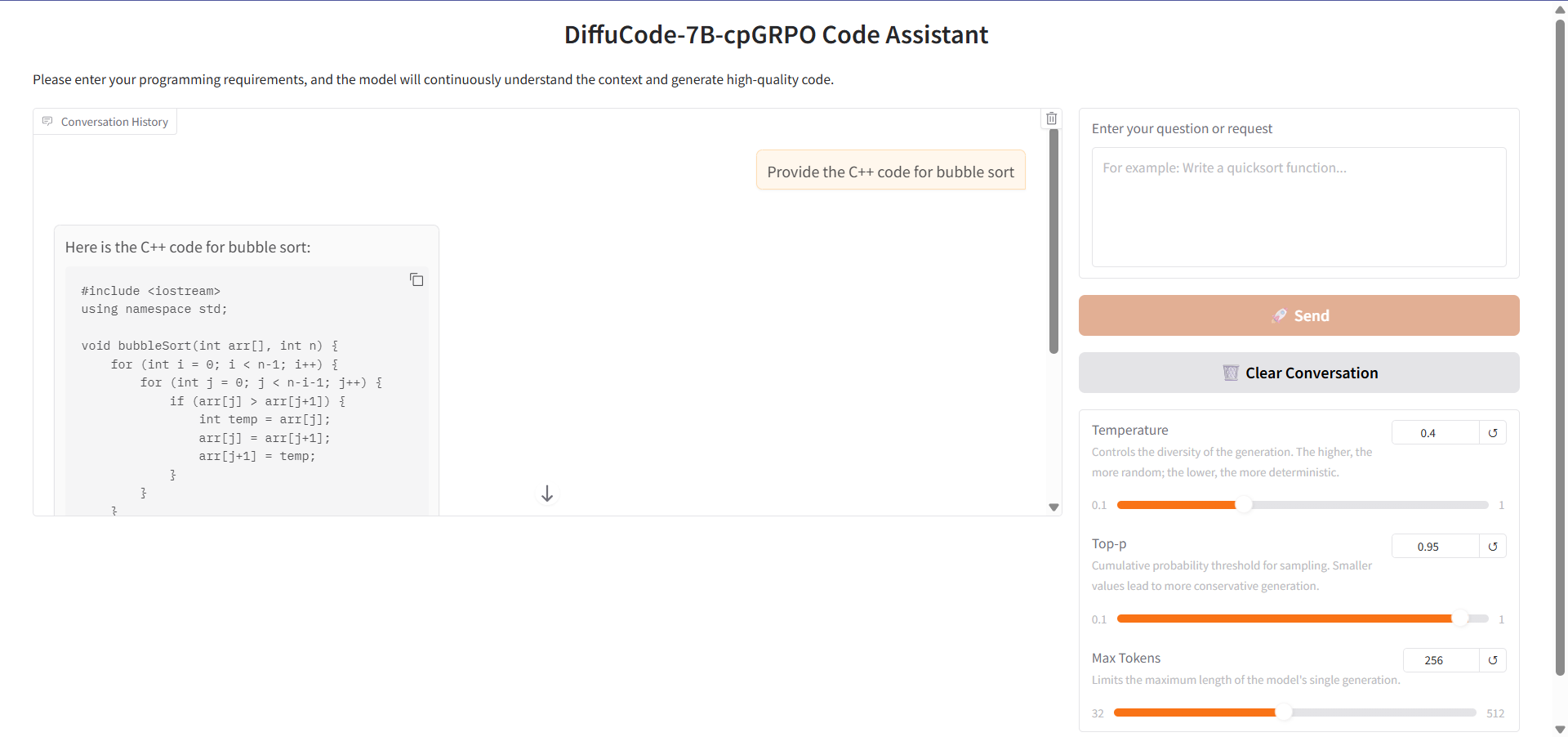
6. DiffuCode-7B-cpGRPO: Code Generation Model Based on Mask Diffusion Technology
DiffuCoder-7B-cpGRPO is a masked diffusion-based code generation model (dLLM) proposed by the Apple team. The model aims to generate and edit code through iterative noise reduction rather than the traditional left-to-right autoregressive generation.
Run online:https://go.hyper.ai/CMfWm
7. LAMMPS: Taking single crystal aluminum as an example, simulating uniaxial tension of materials
LAMMPS (Large-scale Atomic/Molecular Massively Parallel Simulator) is a classic molecular dynamics simulation code that focuses on material modeling. In this tutorial, we simulate the situation of applying uniaxial strain to the material by changing the lattice constant of the material, and then calculate and plot the strain-stress curve of the material.
Run online:https://go.hyper.ai/LAqAs
8. Voxtral-Mini-3B-2507 Speech Understanding Model Demo
Voxtral is an advanced audio model launched by Mistral AI. Based on its excellent voice transcription and deep understanding capabilities, it promotes voice as a natural way of human-computer interaction. The model supports multiple languages, long text context processing, built-in question-answering and summarization functions, and can directly trigger backend function calls. Voxtral's performance exceeds existing open source models and proprietary APIs in multiple benchmarks, while being lower in cost and widely used in various scenarios, helping to popularize voice interaction.
Run online:https://go.hyper.ai/PpjOs
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

This week's paper recommendation
1. GUI-G^2: Gaussian Reward Modeling for GUI Grounding
Inspired by the fact that human click behavior naturally forms a Gaussian distribution centered on the target element, this paper introduces GUI Gaussian Localization Reward (GUI-G^2), a principle-based reward framework that models GUI elements as continuous Gaussian distributions on the interface. Research analysis shows that continuous modeling provides better robustness to interface changes and stronger generalization to unseen layouts, establishing a new paradigm for spatial reasoning in GUI interaction tasks.
Paper link:https://go.hyper.ai/wLUhD
2. MiroMind-M1: An Open-Source Advancement in Mathematical Reasoning via Context-Aware Multi-Stage Policy Optimization
Large language models have recently evolved from fluent text generation to advanced reasoning across multiple domains, giving rise to Reasoning Language Models (RLMs). To promote greater transparency in the development of RLMs, researchers have launched the MiroMind-M1 series, a set of fully open source RLMs built on the Qwen-2.5 framework with performance comparable to or exceeding existing open source RLMs.
Paper link:https://go.hyper.ai/EGWPq
3.Beyond Context Limits: Subconscious Threads for Long-Horizon Reasoning
The limitation of context length of large language models (LLMs) restricts the accuracy and efficiency of reasoning. To overcome this limitation, this paper proposes the Thread Inference Model (TIM), a family of LLMs specifically for recursive and decomposition problem solving. It also proposes TIMRUN, a reasoning runtime environment that enables long-horizon structured reasoning beyond context limitations.
Paper link:https://go.hyper.ai/18j9w
4. The Invisible Leash: Why RLVR May Not Escape Its Origin
This study provides new insights into the potential limitations of RLVR through theoretical and empirical analysis, revealing the potential limitations of RLVR in extending the boundaries of reasoning. Breaking this invisible constraint may require future algorithmic innovations, such as explicit exploration mechanisms or hybrid strategies to introduce probabilistic mass into underrepresented regions of the solution space.
Paper link:https://go.hyper.ai/kkRo2
5. The Devil behind the mask: An emergent safety vulnerability of Diffusion LLMs
Diffusion-based Large-Scale Language Models (dLLMs) have recently emerged as a powerful alternative to autoregressive large-scale language models, providing faster inference speed and higher interactivity through parallel decoding and bidirectional modeling. However, existing alignment mechanisms fail to protect dLLMs from context-aware adversarial prompt attacks with masked inputs, exposing new vulnerabilities. To this end, this paper proposes DIJA, the first jailbreak attack framework that systematically studies and builds a unique security weakness for dLLMs, highlighting the urgency of rethinking secure alignment mechanisms for this emerging class of language models.
Paper link:https://go.hyper.ai/dyDhr
More AI frontier papers:https://go.hyper.ai/iSYSZ
Community article interpretation
In the keynote speech "Triton-distributed: Native Python Programming for High-Performance Communication", Zheng Size, Seed Research Scientist from ByteDance, analyzed in detail the breakthrough in communication efficiency of Triton-distributed in large-model training, cross-platform adaptability, and how to achieve deep integration of communication and computing through Python programming.
View the full report:https://go.hyper.ai/L2rfl
The group of Professor Zheng Yinqiang from the University of Tokyo and the group of Professor Ding Jun from McGill University jointly proposed a method for modeling spatial transcriptome data, SUICA, which is a deep learning model based on implicit neural representation and graph autoencoder. The results show that spatial transcriptome data processed by SUICA can have higher quality, lower noise and stronger biological signals. The relevant research results have been selected for ICML 2025.
View the full report:https://go.hyper.ai/5esoL
Dr. Wang Lei, the founder of the TileAI community, gave a speech titled "Bridge Programmability and Performance in Modern AI Workloads", in which he introduced the innovative operator programming language TileLang in an easy-to-understand manner and shared its core design concepts and technical advantages.
View the full report:https://go.hyper.ai/AkeOJ
Hunan University, in collaboration with the University of the Chinese Academy of Sciences and ByteDance Seed team, proposed a new all-atom protein generation model APM (All-Atom Protein Generative Model). This model integrates atomic-level information and supports the generation, folding, and reverse folding of multi-chain proteins without relying on pseudo-sequence connections. It can achieve performance that exceeds the existing SOTA in downstream tasks such as antibody design and peptide binding design.
View the full report:https://go.hyper.ai/fJvpi
Researchers from Google DeepMind, in collaboration with the University of Nottingham, the University of Warwick and other universities, published a research paper titled "Contextualizing ancient texts with generative neural networks" in the world's top academic journal Nature, announcing that Aeneas achieved the first arbitrary-length restoration of ancient Roman inscriptions.
View the full report:https://b23.moe/cYtSI
Popular Encyclopedia Articles
1. DALL-E
2. Reciprocal sorting fusion RRF
3. Pareto Front
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
August deadline for the summit
August 1 7:59:59 INFOCOM 2026
August 1 7:59:59 KDD 2026
August 2 7:59:59 HPCA 2026
August 2 7:59:59 UbiComp 2025
August 2 11:59:59 VLDB 2026
August 2 19:59:59 AAAI 2026
August 7 7:59:59 NDSS 2026
August 21 11:59:59 ASPLOS 2026
August 27 7:59:59 USENIX Security Symposium 2025
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








