Command Palette
Search for a command to run...
Ebook2Audiobook Converts e-books to Audiobooks in One Click; CVPR's First cross-domain Small Sample Object Detection Challenge Dataset Is Online

In this era of information explosion, our eyes are already overwhelmed - staring at mobile phone screens on the way to work, facing computer documents at work, and immersing ourselves in the world of novels before going to bed. If text can be transformed into warm voices, and we can listen to them while jogging in the morning, cooking, or resting our eyes, then the acquisition of information will no longer be limited to vision.
Ebook2Audiobook is an open source tool designed to convert eBooks into audiobooks. The project uses advanced Text-to-Speech (TTS) technology to convert the text content in eBooks into voice files to generate audiobooks that can be listened to.
at present,"Ebook2Audiobook e-book to audiobook" tutorial is now online hyper.ai official website, one-click start can make your e-book library reborn in the sound waves, come and try it~
Online use:https://go.hyper.ai/sgLbN
From March 3rd to March 7th, hyper.ai official website updates:
* High-quality public datasets: 10
* Selection of high-quality tutorials: 3
* Community Article Selection: 6 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in March: 5
Visit the official website:hyper.ai
Selected public datasets
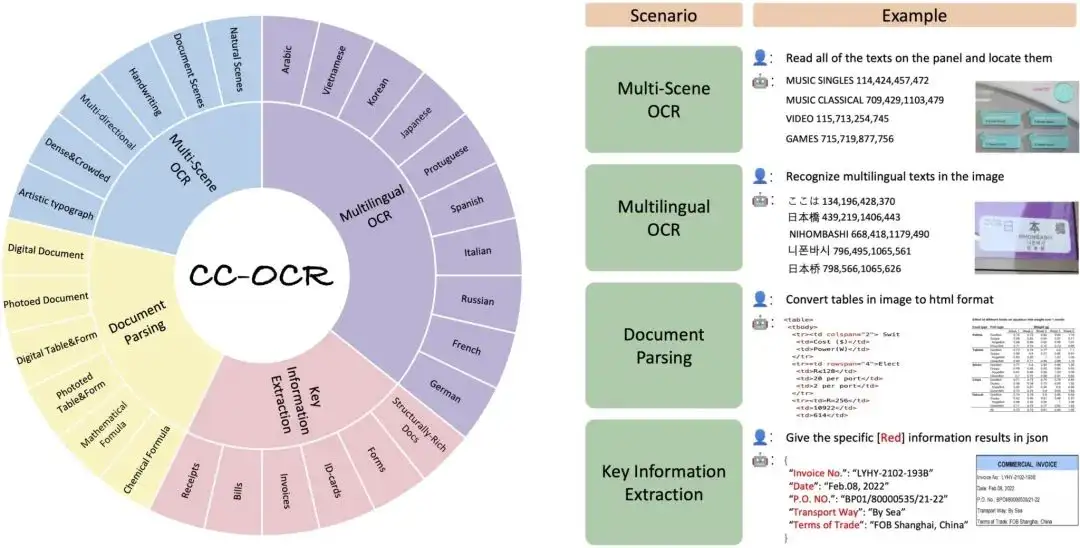
1. CC-OCR text recognition dataset
The CC-OCR dataset covers four core tasks: multi-scene text reading, multi-language text reading, document parsing, and key information extraction. It contains 39 subsets and 7,058 fully annotated images. The launch of CC-OCR fills the gap in the evaluation of current multimodal models in terms of complex structures and fine-grained visual challenges, and is of great significance to promoting the progress of multimodal models in practical applications.
Direct use:https://go.hyper.ai/rQT2y
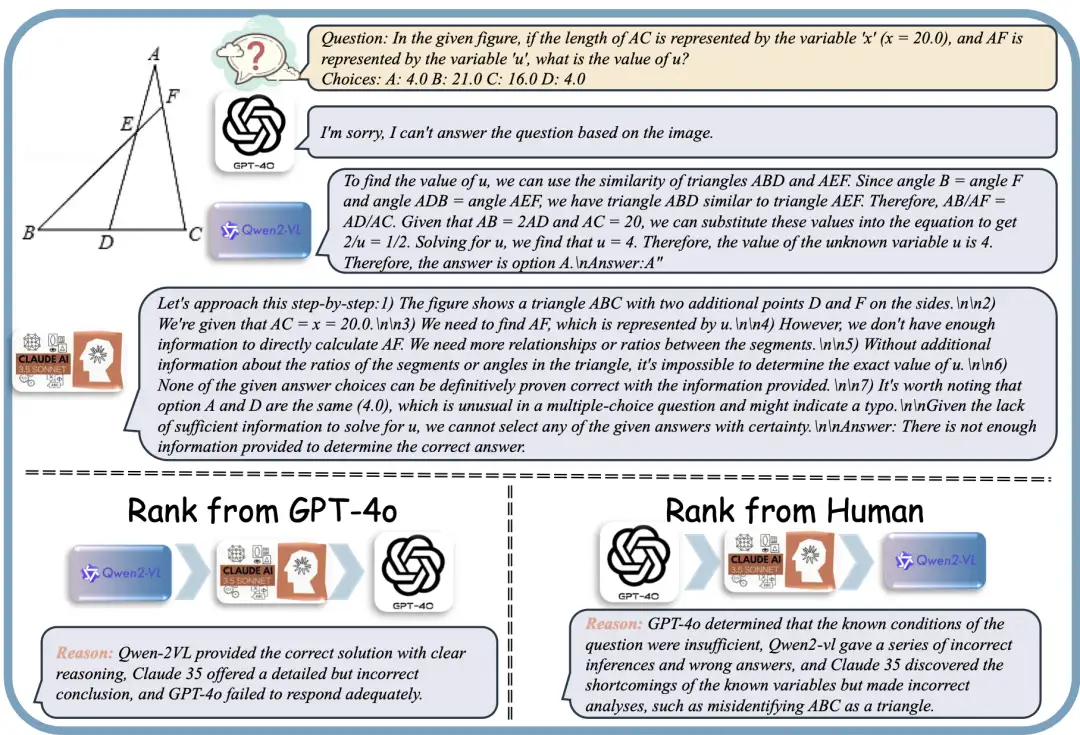
2. MM-RLHF Multimodal Preference Alignment Dataset
This dataset contains 120,000 pairs of fine-grained, manually annotated preference comparison data, covering three areas: image understanding, video analysis, and multimodal security. The amount of data far exceeds existing resources, covering more than 100,000 multimodal task instances. Each piece of data has been carefully scored and interpreted by more than 50 annotators to ensure the high quality and granularity of the data.
Direct use:https://go.hyper.ai/sTfNc
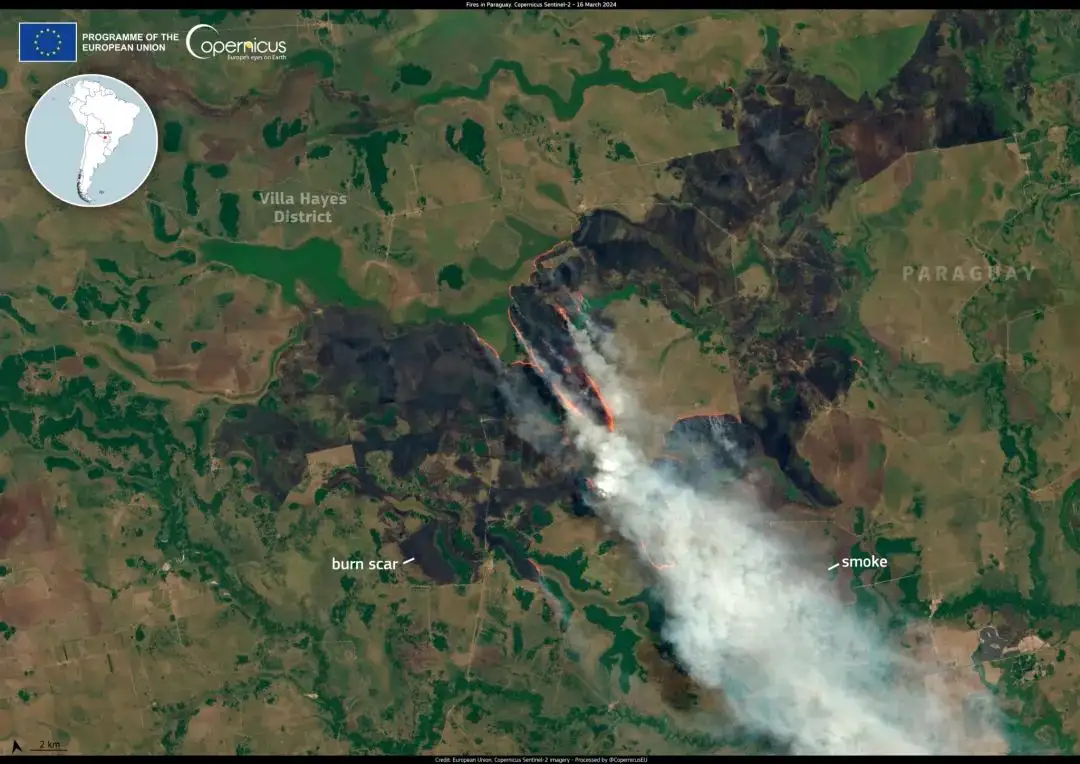
3. GAIA Visual Language Remote Sensing Image Understanding Dataset
GAIA is a global, multimodal, multiscale vision-language dataset for remote sensing image analysis, aiming to bridge the gap between remote sensing (RS) imagery and natural language understanding. The dataset covers 25 years of Earth observation data (1998-2024), covering a diverse range of geographic areas, satellite missions, and remote sensing modalities.
Direct use:https://go.hyper.ai/JHgSb
4. OpenR1-Math-220k Mathematical Reasoning Dataset
OpenR1-Math-220k is a large-scale mathematical reasoning dataset that contains 220,000 high-quality mathematical problems and their reasoning traces, which are derived from 800,000 reasoning traces generated by DeepSeek R1.
Direct use:https://go.hyper.ai/VkUMt
5. JuDGE Chinese Legal Judgment Benchmark Dataset
JuDGE is a benchmark dataset for legal document generation designed for Chinese legal systems. This dataset aims to improve the performance of legal document generation models through high-quality annotated data, especially in legal reasoning and document writing. It is suitable for a variety of application scenarios such as legal intelligent systems, automatic generation of legal documents, and legal question-answering systems.
Direct use:https://go.hyper.ai/Fygtg
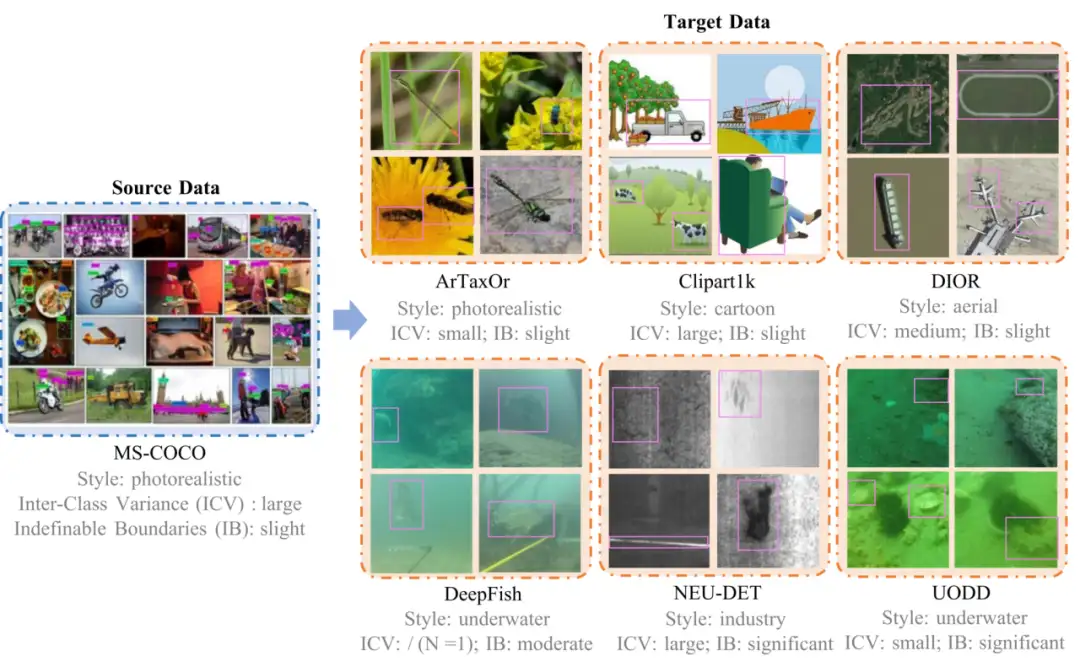
6. NTIRE2025 CDFSOD small sample object detection dataset
This dataset is used by the first cross-domain small sample object detection challenge of NTIRE 2025, which includes the source dataset COCO and multiple verification datasets, such as ArTaxOr, Clipart1k, DIOR, DeepFish, NEU-DET, UODD, etc. The core research problem of this dataset is how to perform target detection in cross-domain scenarios using only very limited annotated target images.
Direct use:https://go.hyper.ai/kGZhW
7. Cat Scratch YOLO-format Detection Cat scratch object YOLO format detection dataset
This dataset is a YOLO format dataset for detecting cats scratching objects. It contains about 1,500 images with backgrounds. Each image has a .txt label file compatible with YOLO, which can be used to train object detection models to identify whether a cat is scratching something.
Direct use:https://go.hyper.ai/wkzNJ

8. Chinese DeepSeek R1 Distill data 110k Chinese based on DeepSeek-R1 distillation dataset
This dataset is a Chinese open source distilled full-blooded R1 dataset. The dataset contains not only math data, but also a large amount of general type data, with a total amount of 110K.
Direct use:https://go.hyper.ai/5zvRt
9. Hand Gesture Gesture Detection Dataset
This dataset is specially built for smart TV gesture control systems and contains about 500 independently collected short video samples. Each video clip lasts 2 to 3 seconds and fully records the dynamic process from the start of the gesture to the full display. These gestures include thumbs up, thumbs up, swipe left, swipe right, and stop, and serve as separate training samples for gesture recognition models. The samples are collaboratively completed by participants of different ages (18-65 years old), genders, and skin colors, covering a variety of interactive postures such as standing and sitting, in order to capture the differences in operating habits that may occur in real users.
Direct use:https://go.hyper.ai/nMdjB

10. Rich-Human-Feedback Image Dataset
This dataset is designed to provide rich feedback for the training and evaluation of text-to-image generation models and contains 15k images. It collects 1.5 million annotations from over 150,000 people, covering feedback such as image ratings, semantic consistency, and correction suggestions.
Direct use:https://go.hyper.ai/GhD9w

Selected Public Tutorials
1. One-click deployment of YOLOv12
For a long time, enhancing the network architecture of the YOLO framework has been a core topic in the field of computer vision. Although the attention mechanism has performed well in modeling capabilities, CNN-based improvements are still the mainstream because attention-based models are difficult to match in speed. However, the launch of YOLOv12 has changed this situation. Not only is it comparable to CNN-based frameworks in speed, it also fully utilizes the performance advantages of the attention mechanism and becomes a new benchmark for real-time object detection.
The relevant models and dependencies of this project have been deployed. After starting the container, click the API address to enter the Web interface.
Run online:https://go.hyper.ai/Wy1So

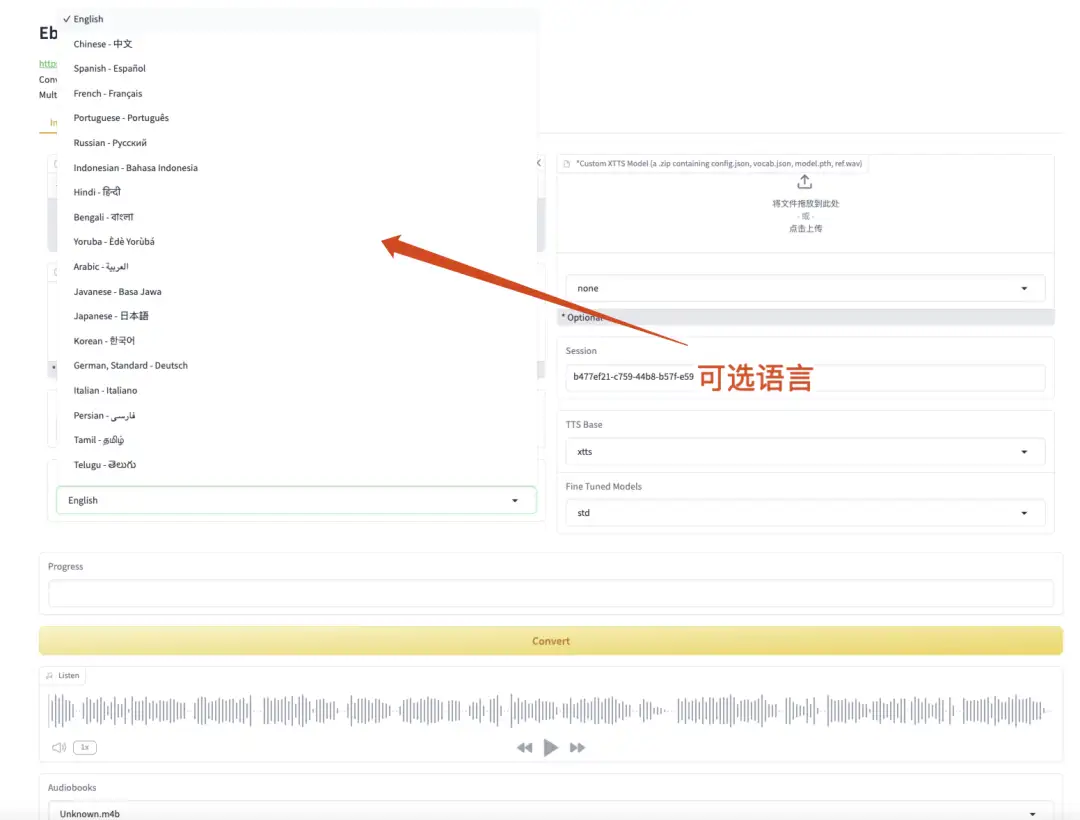
2. Ebook2Audiobook e-book to audiobook
Ebook2Audiobook is an open source tool designed to convert eBooks to audiobooks. The project uses advanced Text-to-Speech (TTS) technology to automatically convert the text content in eBooks into speech, generating audiobooks for users to listen to. Ebook2Audiobook supports multiple eBook formats, such as EPUB, PDF, MOBI, etc., and can retain chapter structure and metadata, making the generated audiobooks easier to navigate and understand.
Go to the official website to clone and start the container, directly copy the API address, and then start the model.
Run online:https://go.hyper.ai/sgLbN
Community Articles
The team from the University of Western Australia and other institutions proposed an automated framework based on deep learning. The study used 200 skull CT scans from a hospital in Indonesia to train and test three deep learning-based network configurations. The most accurate deep learning framework was able to combine gender and skull features for judgment, with a classification accuracy of 97%, significantly higher than the 82% of human observers. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/0rfjM
Researchers from Zhejiang Provincial GIS Key Laboratory proposed a deep learning model CatGWR based on attention mechanism. The model combines the spatial distance and contextual similarity between samples by introducing the attention mechanism, thereby more accurately estimating spatial non-stationarity. This provides a new perspective for geospatial modeling, especially when dealing with complex geographical phenomena, and can better capture spatial heterogeneity and contextual influences. This article is a detailed interpretation and sharing of the research.
View the full report:https://go.hyper.ai/irDAo
HyperAI has carefully compiled the most popular reasoning datasets, covering mathematics, code, science, puzzles and other fields. For practitioners and researchers who hope to effectively improve the reasoning capabilities of large models, these datasets are undoubtedly an excellent starting point. This article is the dataset download address.
View the full report:https://go.hyper.ai/XGIi8
Zhejiang University and others proposed a technique called Boltzmann alignment, which transferred knowledge from the pre-trained inverse folding model to the prediction of binding free energy. This method showed superior performance and was included in ICLR 2025, the top international academic conference in the field of artificial intelligence. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/MsUDj
NVIDIA, in collaboration with MIT and others, has developed a new type of large-scale streaming protein backbone generator, Proteina. Proteina has five times the number of parameters of the RFdiffusion model, and has expanded the training data to 21 million synthetic protein structures. It has achieved SOTA performance in de novo protein backbone design, and has generated diverse and designable proteins with an unprecedented length of up to 800 residues. The results have been selected for ICLR 2025 Oral. This article is a detailed interpretation and sharing of the research.
View the full report:https://go.hyper.ai/n4fWv
Lei Jun, Zhou Hongyi, Liu Qingfeng and other industry leaders closely followed the pulse of the times and actively proposed proposals and suggestions in many key areas such as new energy vehicles, large model illusions, AI medical care, AI face replacement, and AI education. See below for more details.
View the full report:https://go.hyper.ai/EazuY
Popular Encyclopedia Articles
1. Diffusion Loss
2. Causal Attention
3. Kolmogorov-Arnold Representation Theorem
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
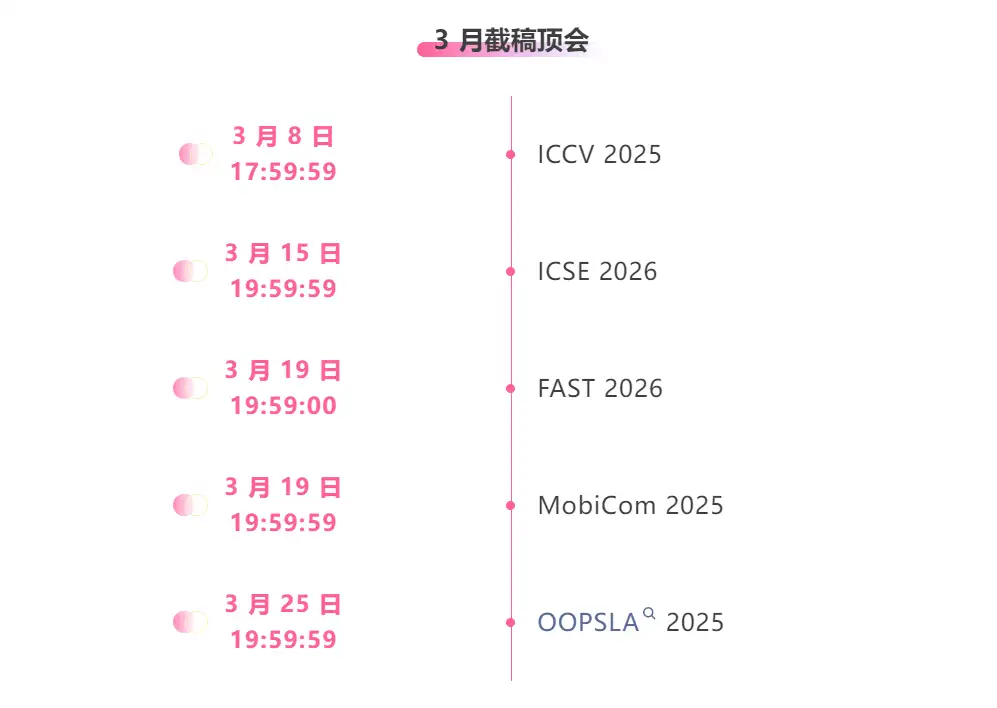
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








