Command Palette
Search for a command to run...
Online Tutorial | Deepseek-OCR Achieves State-of-the-Art in End-to-End Models With Minimal Number of Visual Tokens

As is well known, when large language models process texts of thousands, tens of thousands, or even longer, the amount of computation often increases dramatically, even leading to a "money-burning" game of computing power. This also limits the efficiency boundary of LLM in processing high-density text information scenarios.
As the industry continuously explores ways to optimize computational efficiency, Deepseek-OCR offers a completely new perspective: can we efficiently "read" text using the same methods we use to "see" it? Based on this bold idea, researchers have discovered that a single image containing document text can represent a wealth of information using far fewer symbols than equivalent numerical text. This means that when we choose to feed textual information as images to large models for understanding and memorization, overall efficiency can be effectively improved. This is no longer simply image processing.Instead, it is a clever "optical compression"—using visual modalities as an effective compression medium for text information, thereby achieving a compression ratio far higher than that of traditional text representation.
Specifically, DeepSeek-OCR consists of two components: DeepEncoder and DeepSeek3B-MoE-A570M. The encoder (DeepEncoder) is responsible for extracting image features, segmenting words, and compressing visual representations, while the decoder (DeepSeek3B-MoE-A570M) is used to generate the desired results based on image tags and prompts.DeepEncoder, as the core engine, is designed to maintain a low activation state under high-definition input while achieving a high compression rate, so as to ensure that the number of visual tokens is both optimized and easy to manage.Experiments show that when the number of text tokens is less than 10 times the number of visual tokens (i.e., compression ratio < 10×), the model can achieve a decoding (OCR) accuracy of 971 TP3T. Even with a compression ratio of 20×, the OCR accuracy remains at approximately 601 TP3T.
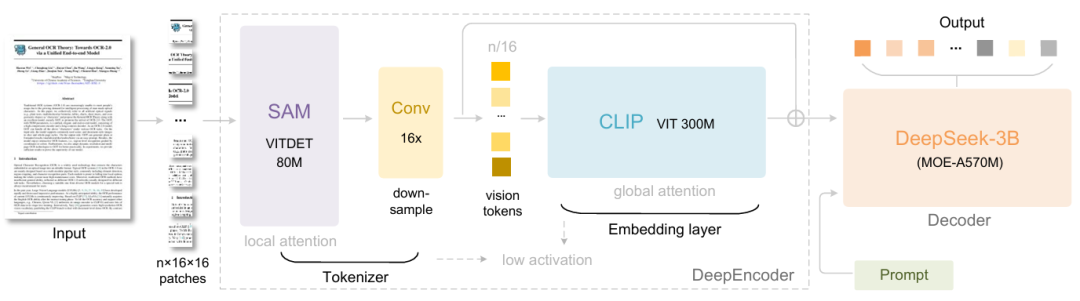
The release of DeepSeek-OCR is not only an advancement in OCR tasks, but also demonstrates enormous potential in cutting-edge research areas such as long context compression and exploring memory forgetting mechanisms in LLMs.
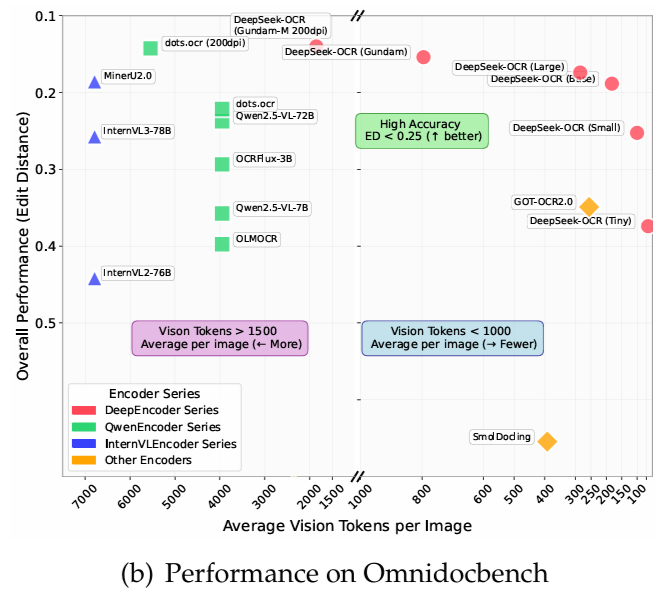
On OmniDocBench,It surpasses GOT-OCR2.0 (256 tokens per page) using only 100 visual tokens.Furthermore, it outperforms MinerU2.0 (6000+ tokens per page on average) when using fewer than 800 visual tokens. In a production environment, DeepSeek-OCR can generate over 200,000 pages of training data for LLMs/VLMs per day (using a single A100-40G).
"DeepSeek-OCR: Visual Compression Replaces Traditional Character Recognition" is now available on the "Tutorials" section of the HyperAI website (hyper.ai). Deploy and experience it with one click!
* Tutorial link:
* View related papers:
https://hyper.ai/papers/DeepSeek_OCR
Demo Run
1. After entering the hyper.ai homepage, select "DeepSeek-OCR: Visual Compression instead of traditional character recognition", or go to the "Tutorials" page and select "Run this tutorial online".
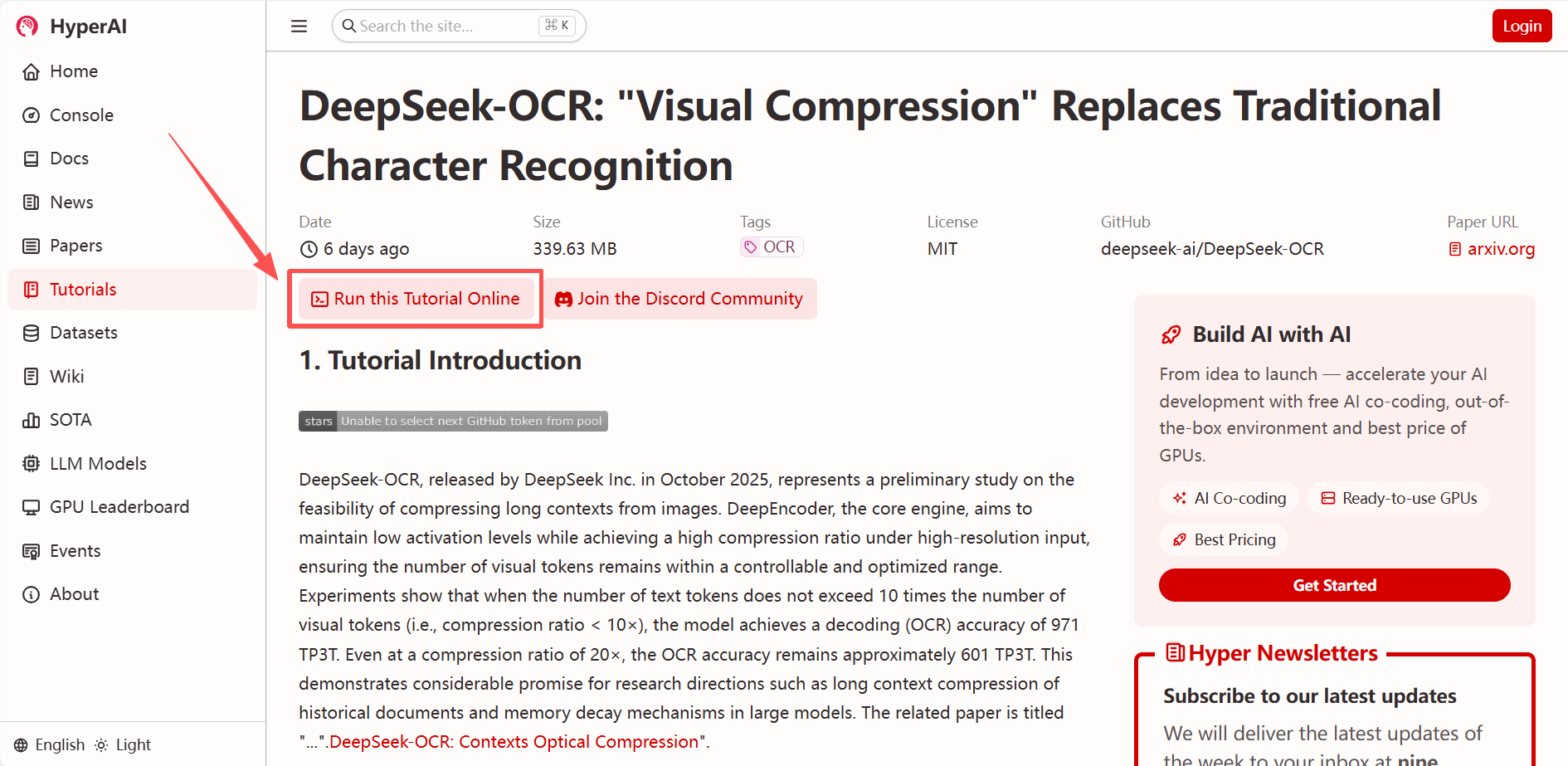
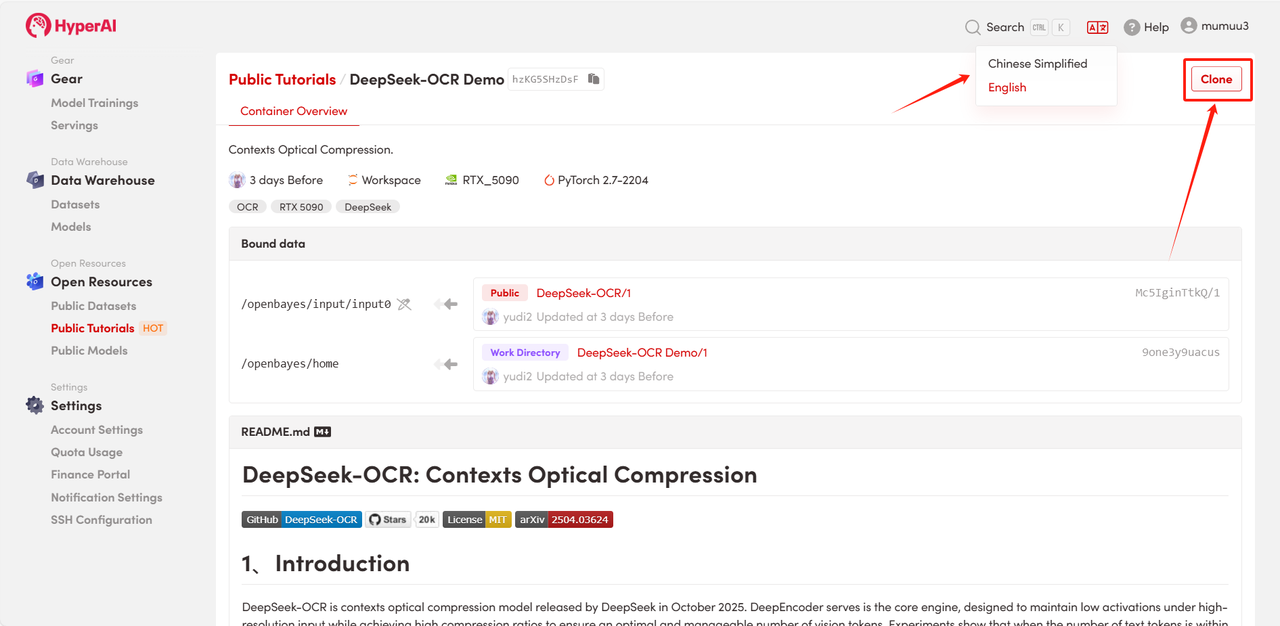
2. After the page redirects, click "Clone" in the upper right corner to clone the tutorial into your own container.
Note: You can switch languages in the upper right corner of the page. Currently, Chinese and English are available. This tutorial will show the steps in English.
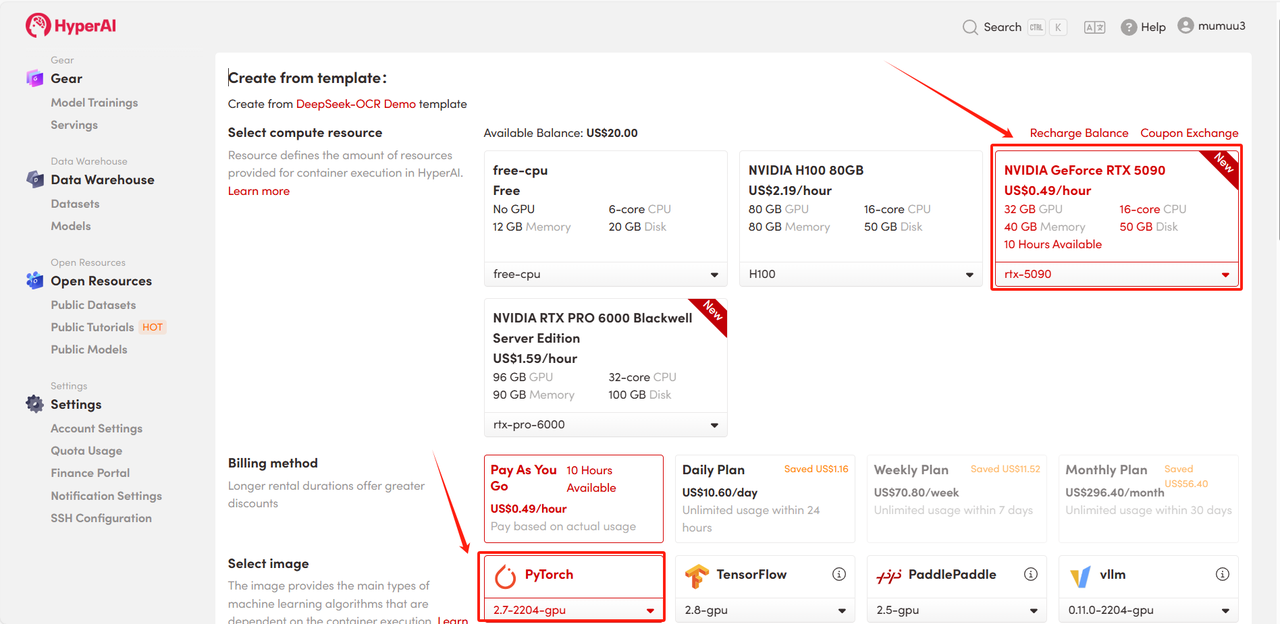
3. Select the "NVIDIA GeForce RTX 5090" and "PyTorch" images, and choose "Pay As You Go" or "Daily Plan/Weekly Plan/Monthly Plan" as needed, then click "Continue job execution".
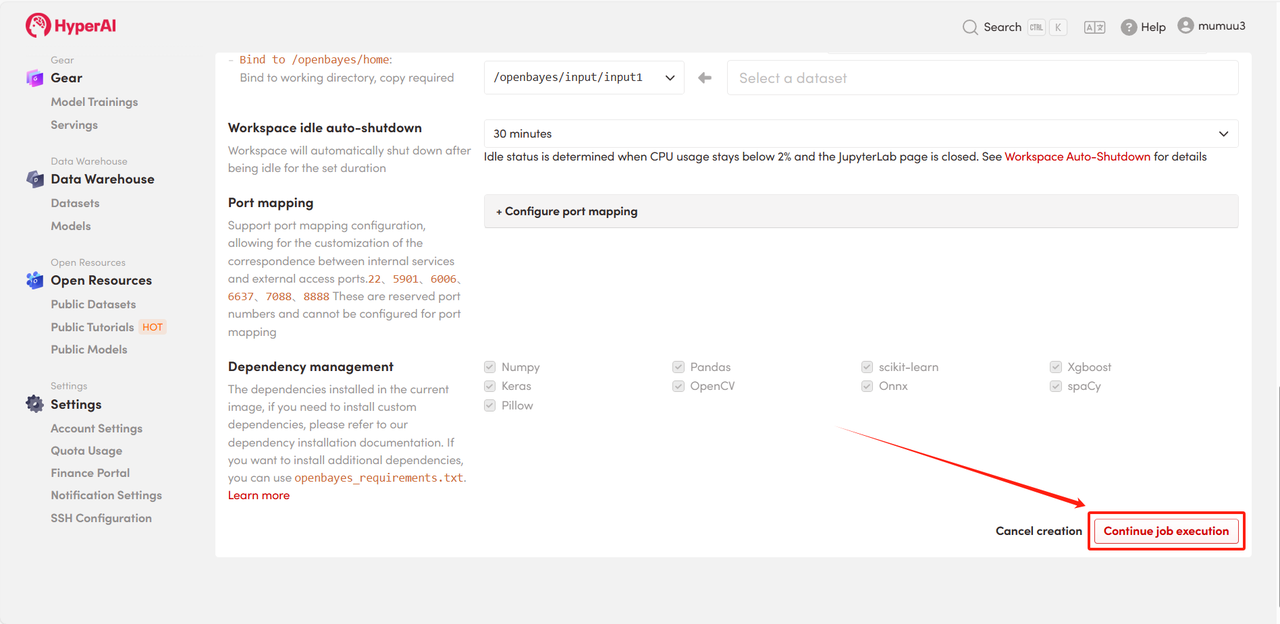
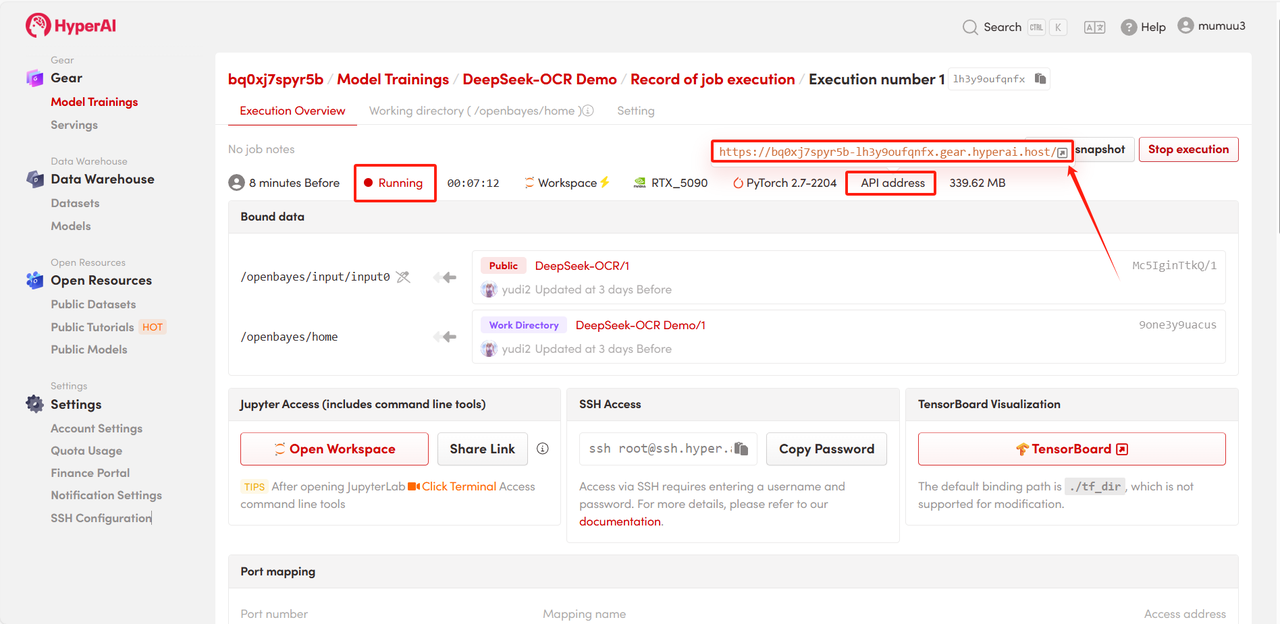
4. Wait for resource allocation. The first clone will take approximately 3 minutes. Once the status changes to "Running", click the jump arrow next to "API Address" to go to the Demo page.
Effect Demonstration
After entering the Demo running page, upload the document image to be parsed, and click "Extract Text" to start parsing.
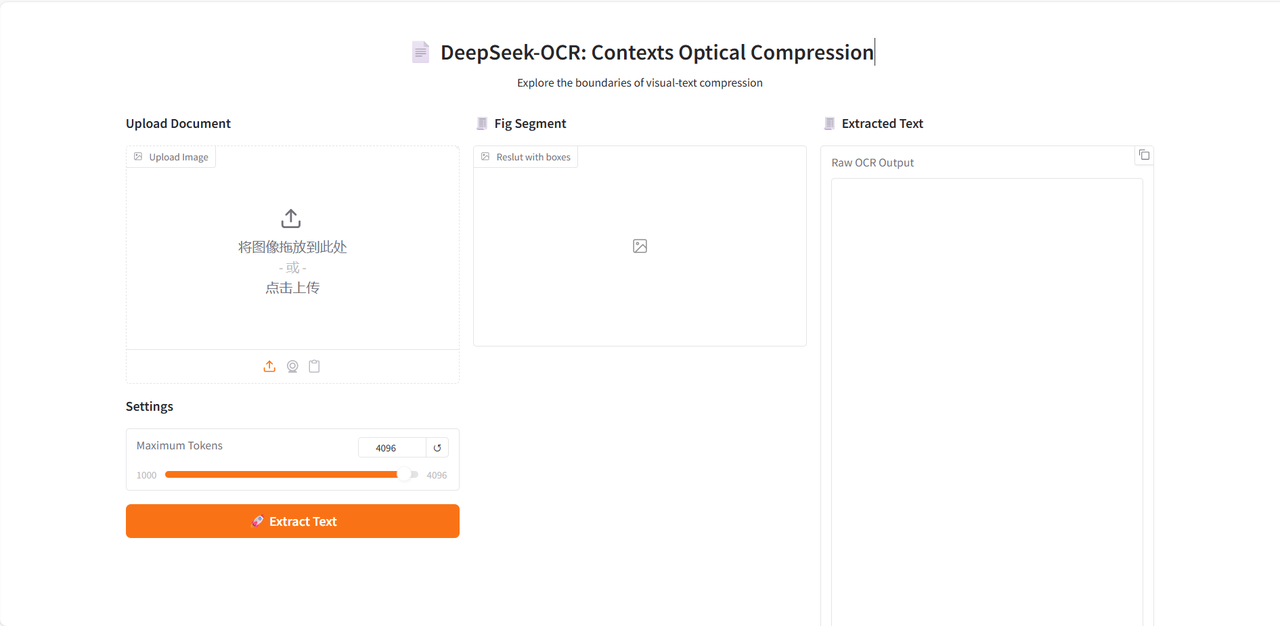
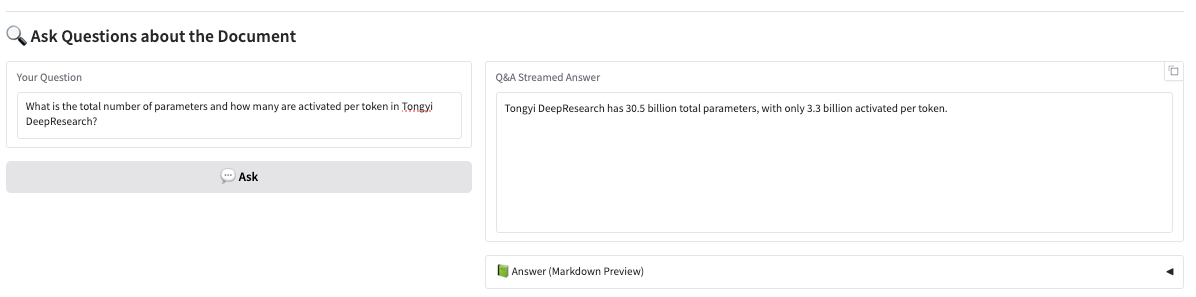
The model first divides the text or chart modules in the image, and then outputs the text in Markdown format.

The above is the tutorial recommended by HyperAI this time. Everyone is welcome to come and experience it!
* Tutorial link:








