Command Palette
Search for a command to run...
Beyond GPT-4o! From HTML to Markdown, Organize Complex Web Pages With One Click; AI Dialogue Is No Longer Cold, Large Model Dialogue fine-tuning Data Set Makes the Response Smoother

How to quickly extract comprehensive core information from web pages with redundant information? The Reader-LM model provides you with a professional solution. Reader-LM can efficiently process ultra-long content up to 256K bytes and accurately convert HTML into clear Markdown format. Its performance even exceeds that of large language models such as GPT-4o, and its lightweight design also makes it more suitable for scenarios with limited resources.
at present,The Reader-LM model is now available on the hyper.ai website. You can experience efficient conversion with one-click startup. You no longer have to worry about organizing web information.
From January 13th to January 17th, hyper.ai official website updated quickly:
* High-quality public datasets: 10
* High-quality tutorials: 9
* Community article selection: 5 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in January: 5
Visit the official website: hyper.ai
Selected public datasets
1. Human Like DPO Dataset Large model dialogue fine-tuning dataset
This dataset is specially designed to improve the fluency and participation of large language model conversations, aiming to guide the model to generate more human-like responses. The dataset covers 256 topics and contains 10,884 samples, which are distributed in multiple fields such as technology, daily life, science, history and art.
Direct use:https://go.hyper.ai/zDsGL

2. MedQA Medical Text Question Answering Dataset
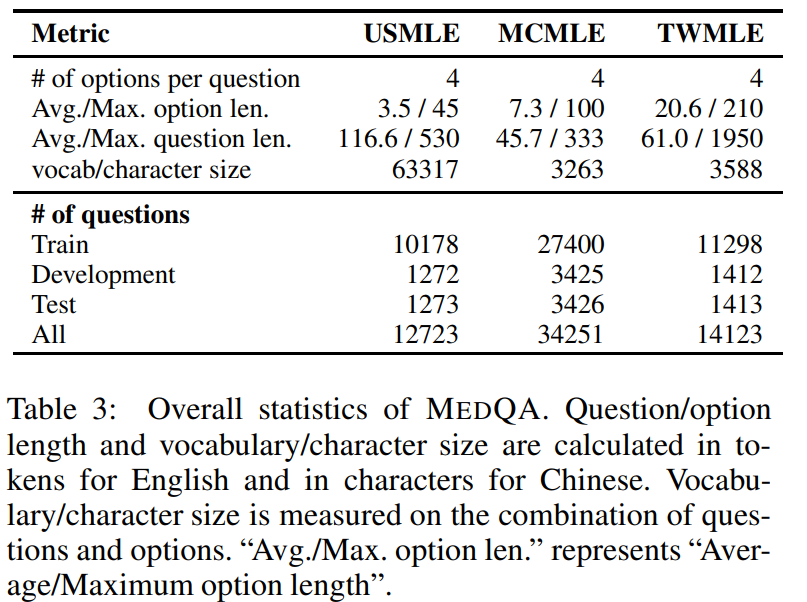
The MedQA dataset simulates the style of the United States Medical Licensing Examination (USMLE) and is designed to evaluate the model's understanding and application of medical knowledge. The dataset is collected from professional medical examinations and covers English, Simplified Chinese, and Traditional Chinese, containing 12,723, 34,251, and 14,123 questions, respectively.
Direct use:https://go.hyper.ai/cV2ei
3. Vegetable Identification Vegetable Image Recognition Dataset
The dataset contains images of six types of vegetables: eggplant, beans, okra, squash, potatoes, and onions, with 800 images of each type, for a total of 4,800 images. It aims to enhance the capabilities of machine learning and computer vision in vegetable detection, classification, and recognition.
Direct use:https://go.hyper.ai/mCZr4

4. China Street View Traffic Sign Dataset
The dataset consists of 9,898 street view images. Each photo contains at least one or more traffic signs, and the traffic sign coordinates and categories are annotated. The data comes from the China Traffic Sign Detection Database.
Direct use:https://go.hyper.ai/9wb5f

5. Pre-processed Snake Images
The dataset contains five snake species: northern water snake, common garter snake, De's brown snake, black rat snake, and western rattlesnake. The dataset has been preprocessed to increase brightness and contrast, and manually delete and crop images to make the images cleaner, uniform, and usable.
Direct use:https://go.hyper.ai/YAgyI

6. Chinese Traffic Signs Chinese traffic sign image data
The dataset contains 5,998 traffic sign images from 58 categories. Each image is a zoomed view of a single traffic sign. The annotations provide image properties (filename, width, height) as well as traffic sign coordinates within the image and category (e.g. 5 km/h speed limit).
Direct use:https://go.hyper.ai/Tvvh8

7. Human Style Preferences Images Image Generation Preference Dataset
This dataset is a human-annotated dataset for evaluating text-to-image generation models. It collects human consistency evaluations of image generation models by showing two pictures and asking participants which picture looks less strange or unnatural, and contains more than 1.2 million human consistency votes.
Direct use:https://go.hyper.ai/dErEz
8. M²E: Multi-line Mathematical Formula Dataset
This dataset contains 99,956 multi-line mathematical expression images and their annotations. All images are taken with mobile phones in real-world scenes. Multi-line mathematical formulas are captured from math test papers and exercise books and can be used for math formula recognition tasks.
Direct use:https://go.hyper.ai/5BMnN
9. Chinese Couplets Dataset
This dataset contains about 740k couplets. fixed_couplets_in.txt is the upper couplet and fixed_couplets_out.txt is the lower couplet.
Direct use:https://go.hyper.ai/oPxHl
10. Audio Noise Dataset
This dataset contains 10 different categories of noise and can be used for noise filtering, noise generation, and noise recognition in audio classification, audio recognition, audio generation, and audio-related machine learning.
Direct use:https://go.hyper.ai/MXXZy
Selected Public Tutorials
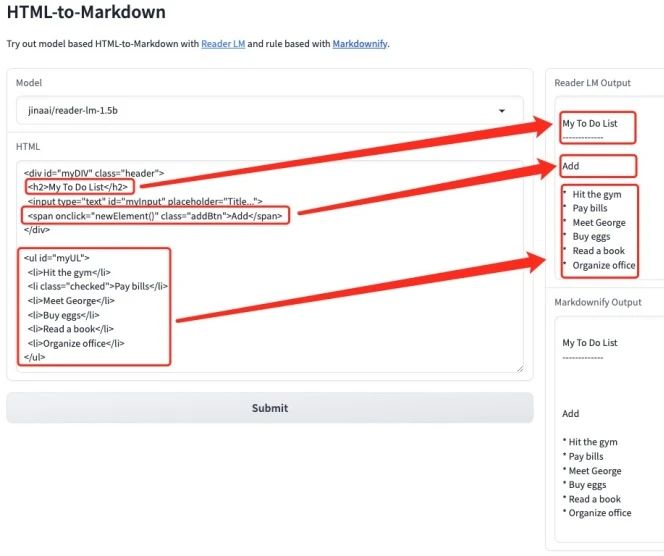
1. Reader-LM: Convert HTML to MarkDown quickly and efficiently
Reader-LM is a model specifically designed to convert raw HTML content from the web into a clear and tidy Markdown format. It excels in processing long text and multilingual content, and supports context lengths up to 256K bytes. It is designed to address the need for efficient and economical data extraction from noisy web content.
This tutorial demonstrates how to use reader-lm-1.5b or reader-lm-0.5b to convert HTML to markdown. Click the link below and follow the tutorial instructions to experience it.
Run online:https://go.hyper.ai/S15IL
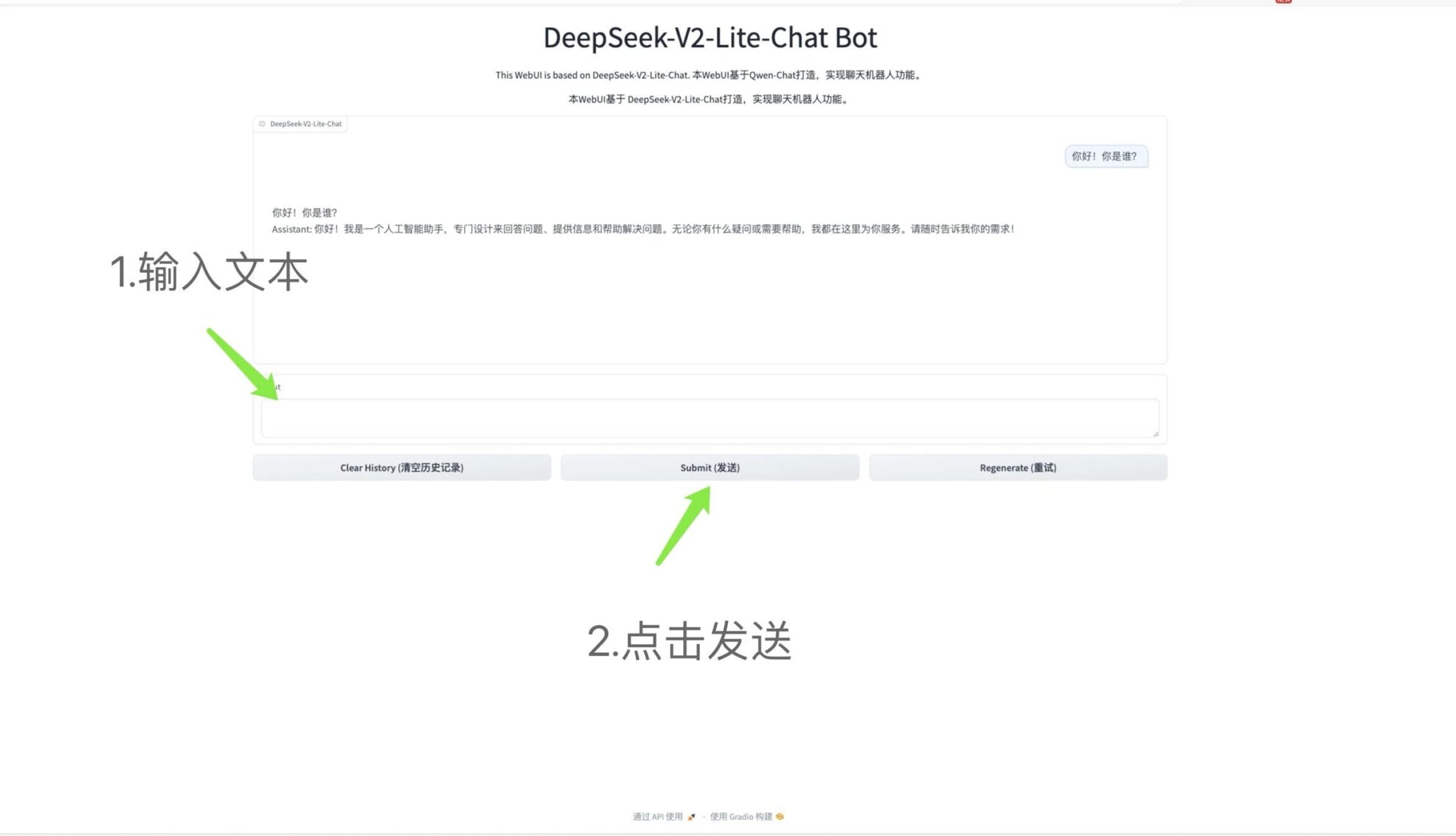
2. One-click deployment of DeepSeek-V2-Lite-Chat
DeepSeek-V2 is a powerful mixture of experts (MoE) language model that is economical to train and efficient to infer. It contains 236B parameters in total, including 21B parameters per token activation.
This tutorial is a one-click deployment demo of DeepSeek-V2-Lite-Chat. You only need to clone and start the container and directly copy the generated API address to experience the model inference.
Run online:https://go.hyper.ai/AD6XU
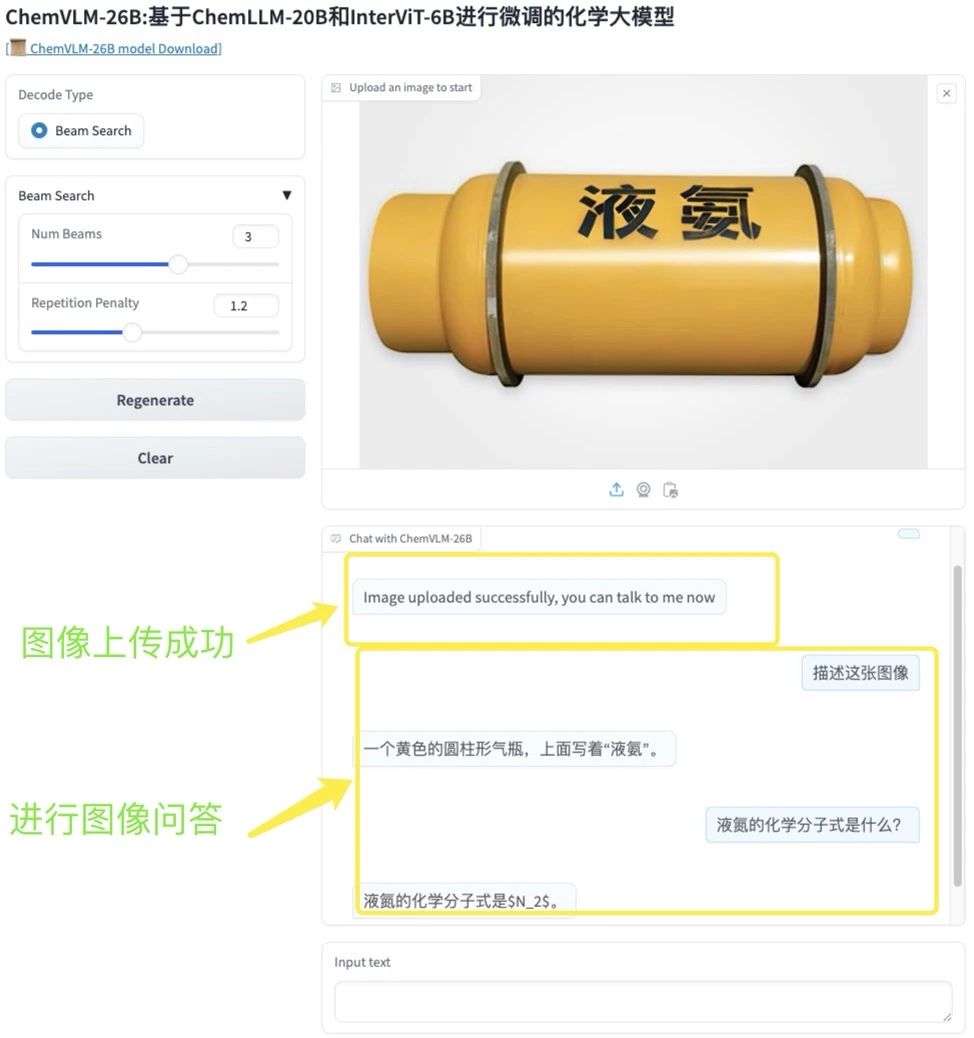
3.One-click deployment of ChemVLM-26B
ChemVLM is an open-source multimodal large language model for the chemistry field. The model aims to solve the incompatibility between chemical image understanding and text analysis, and achieves comprehensive reasoning of chemical images and text by combining the advantages of Visual Transformer (ViT), Multilayer Perceptron (MLP) and Large Language Model (LLM).
Follow the tutorial steps and directly copy the generated API address to use ChatVLM-26B.
Run online:https://go.hyper.ai/NRBXG
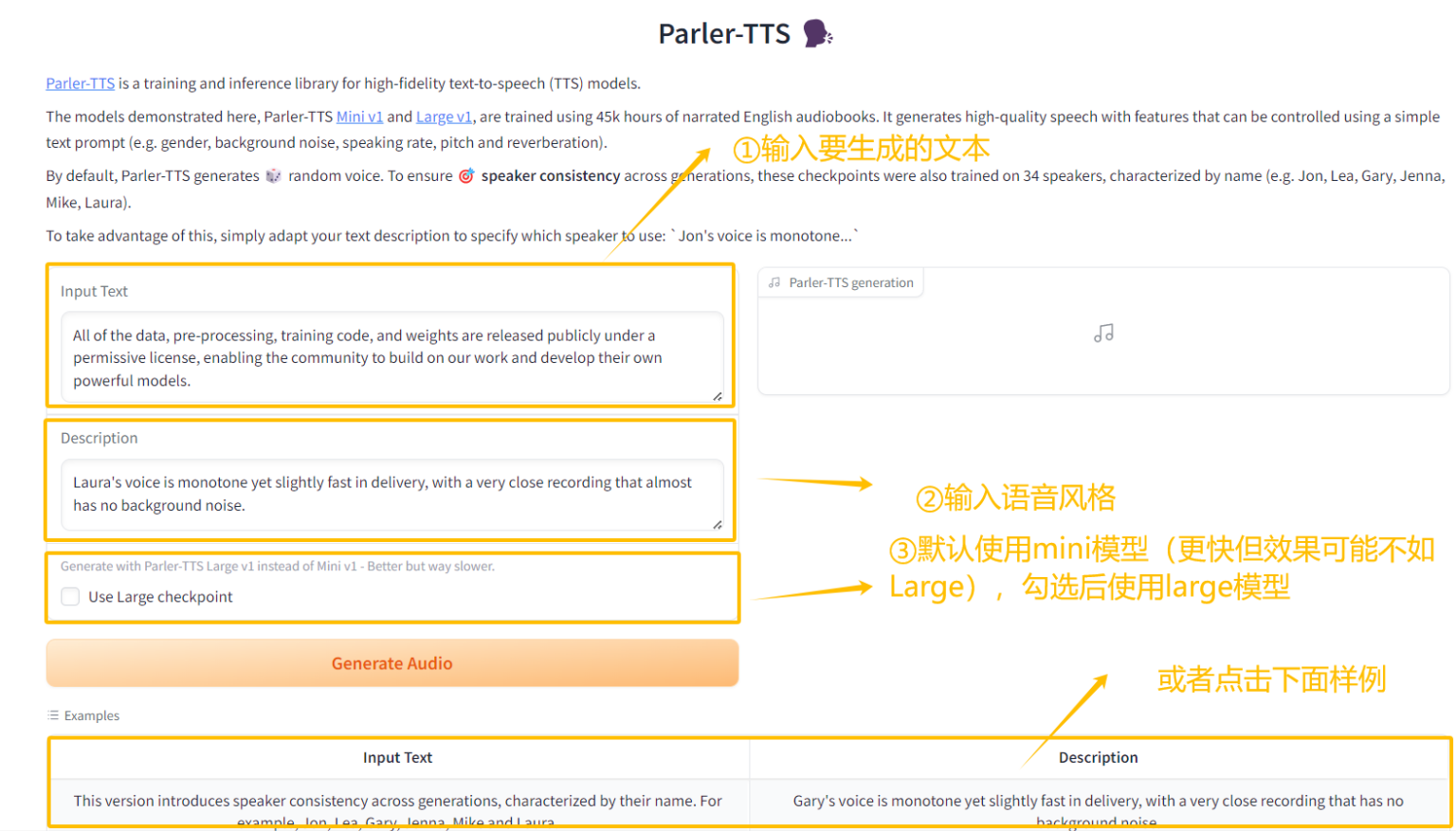
4. One-click deployment of Parler-TTS
Parler-TTS is a lightweight text-to-speech (TTS) model that can generate high-quality, natural speech in the style of a given speaker. It has a high degree of freedom and innovation, and can control the speaker's gender, timbre, intonation, and scene (indoors, outdoors, on the road, in a concert hall, etc.) through Prompt.
This project can generate a front-end interactive interface through the Gradio interface. The relevant models and dependencies have been deployed, and water audio files can be generated by starting with one click.
Run online:https://go.hyper.ai/pk6lF
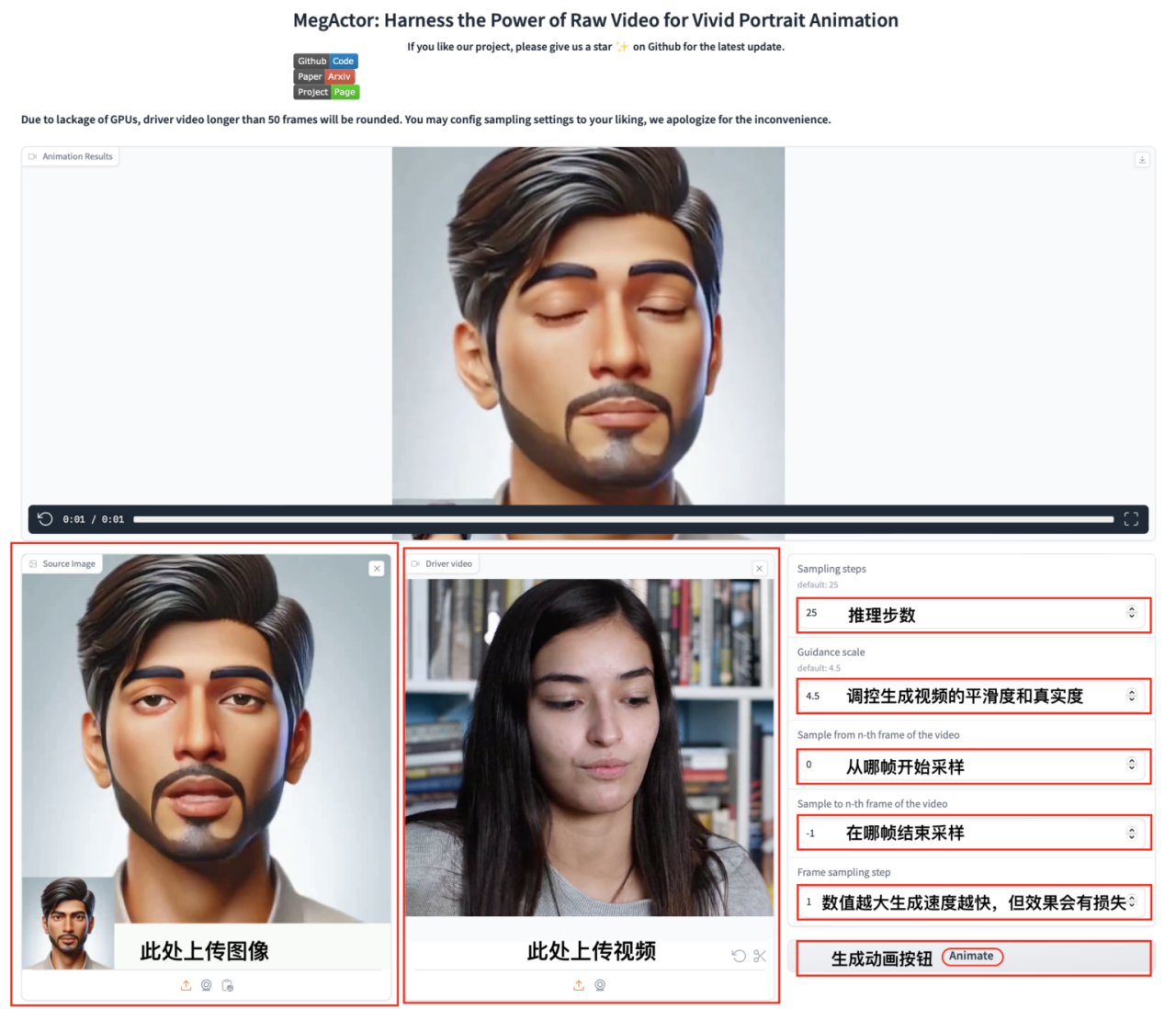
5. MegActor Portrait Animation Generator Demo
MegActor is a portrait animator that uses raw video as a driver to generate realistic and animated talking head videos.
Follow the tutorial steps, just clone the launcher and open the API address to generate vivid synthetic videos based on the original video content.
Run online:https://go.hyper.ai/wkCPo
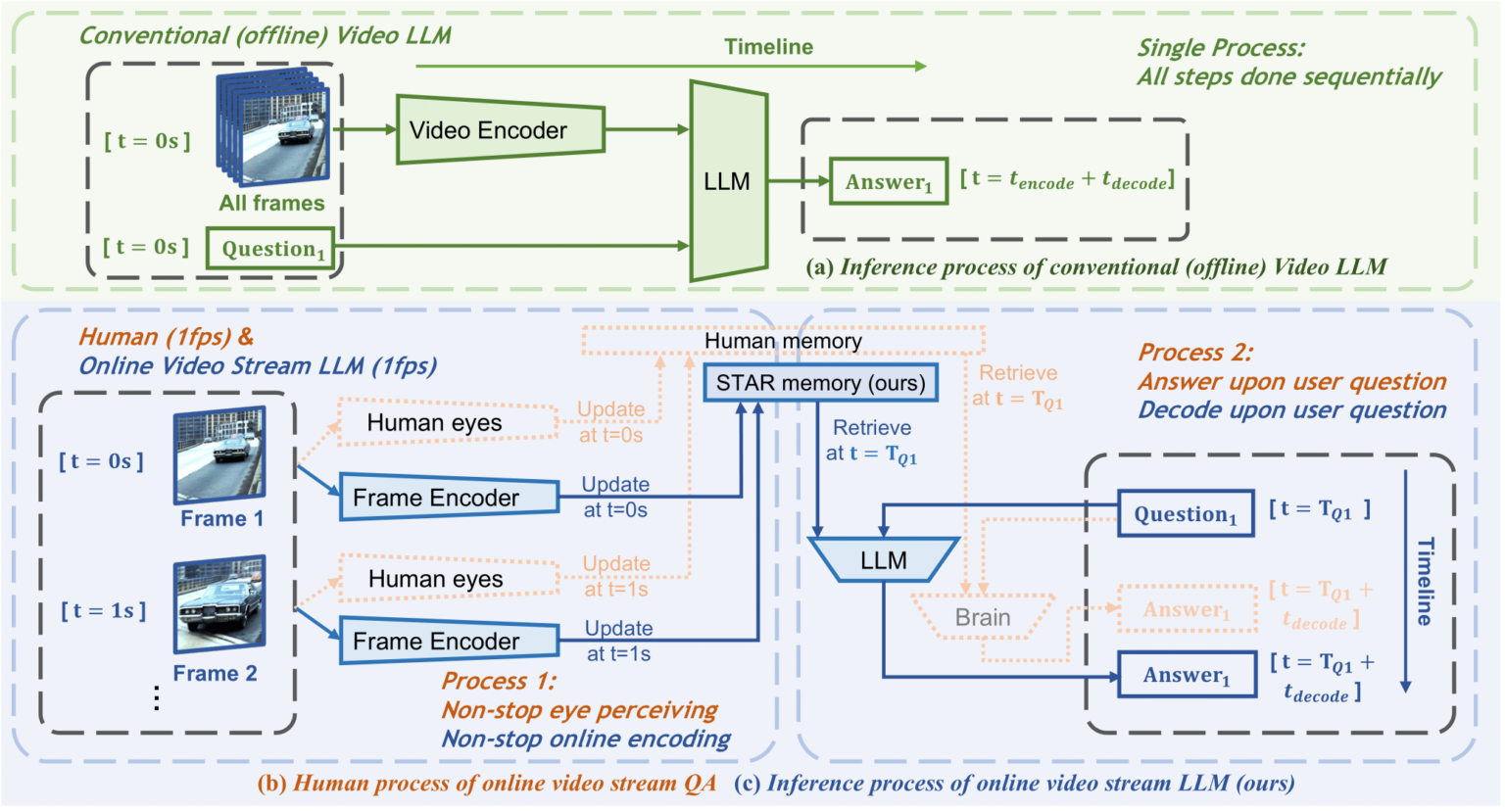
6. Flash-VStream video understanding Demo
Flash-VStream is a video language model that simulates human memory mechanisms. It can process extremely long video streams in real time and respond to user queries at the same time.
This tutorial is a one-click run demo of Flash-VStream. The relevant environment and dependencies have been installed. You can experience it by cloning and starting it with one click.
Run online:https://go.hyper.ai/M3pBO
7. PhotoMaker V2 generates personalized portrait pictures in seconds Demo
PhotoMaker is an efficient portrait customization model open-sourced by the Tencent team in 2024. It can quickly generate customized artistic style photos based on portraits. In addition to generating personalized portraits, it can also change the age and gender of the person, and integrate the characteristics of different people to create new person information.
This tutorial is the 2.0 version of PhotoMaker, which has greatly improved character consistency and controllability compared to V1.
Run online:https://go.hyper.ai/VcewN

8. StoryDiffusion Comic Video Generator Demo
StoryDiffusion is an AI tool focused on long-range image and video generation. This technology uses a consistent self-attention mechanism to ensure the continuity and consistency of image and video content, whether in the creation of comics, cartoon characters, or the generation of long videos, it can maintain the unity of style.
This tutorial is the latest version of StoryDiffusion one-click run package. You can experience StoryDiffusion with one-click cloning.
Run online:https://go.hyper.ai/HPu2p

9. Easy to use molecular dynamics simulator LAMMPS: npt temperature control to estimate the melting point of FCC Cu
LAMMPS can be used to model a variety of materials, including solid-state materials (metals, semiconductors), biomolecules, polymers, etc., and can provide a variety of particle interaction models for different materials.
This tutorial is an introductory tutorial for LAMMPS: estimating the melting point of FCC Cu using npt temperature control. You can run it using the CPU version of LAMMPS to experience molecular dynamics simulations.
Run online:https://go.hyper.ai/qQSqr
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

Community Articles
Meet AI Compiler The 6th Technical Salon Review is here. Four senior compiler experts from Horizon Robotics, Zhiyuan, ByteDance, and Lingchuan Technology showed everyone the latest research results of their respective teams. At the same time, they also combined rich practical application cases to explain in an easy-to-understand way the application process and effects of these results in solving practical problems.
View event recap:https://go.hyper.ai/KDzY3
HyperAI conducted an in-depth interview with Professor Xie Weidi, a tenured associate professor at Shanghai Jiao Tong University. Based on his personal experience, he shared with us his experience in transforming from computer vision to AI for Healthcare, and also deeply analyzed the future development trend of the industry. This is a detailed report on the interview content.
View the full report:https://go.hyper.ai/LqpqE
3. Tactile sensor based on flexible magnetic film
Tactile perception is one of the important capabilities of intelligent robots and human-computer interaction, but how to achieve high-precision and fast-response tactile sensing still faces many challenges. Dr. Yan Youcan from the French National Center for Scientific Research shared with everyone the design and application of tactile sensors based on flexible magnetic films, and introduced how to use the orthogonally magnetized Halbach array to achieve three-dimensional force self-decoupling. This article is a detailed report on the sharing content.
View the full report:https://go.hyper.ai/Y5uA0
Multimodal medical image fusion can mine a lot of valuable information and help doctors make more professional disease diagnoses, but a major challenge currently faced is that the features used for fusion and alignment are not reconcilable. Kunming University of Science and Technology and Ocean University of China jointly proposed a bidirectional stepwise feature alignment method BSAFusion, which can achieve multimodal medical image alignment and fusion. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/sTySj
The shortage of medical resources is a long-term problem that plagues the global medical system. To this end, research teams from four major universities proposed KG4Diagnosis. This is a new hierarchical multi-agent framework that can be used to automate the construction, diagnosis, treatment and reasoning of medical knowledge graphs, and help diagnose 362 common diseases across multiple medical fields such as obesity. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/0CPhV
Popular Encyclopedia Articles
1. Diffusion Loss
2. Causal Attention
3. Kolmogorov-Arnold Representation Theorem
4. Large-scale Multi-task Language Understanding (MMLU)
5. Contrastive Learning
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
January deadline for the top conference

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1700+ public data sets
* Includes 500+ classic and popular online tutorials
* Interpretation of 200+ AI4Science paper cases
* Supports 600+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:
Finally, I recommend a "Creator Incentive Program". Interested friends can scan the QR code to participate!









