Command Palette
Search for a command to run...
Microsoft and Tencent Compete in Technology, TRELLIS Leads the New Direction of multi-format Support in the Field of 3D Generation; More Than 5k Questions Correct! VIS-Bench Allows AI to Learn "spatial Memory"

Last November, Tencent launched the Hunyuan3D generative model, which is the industry's first open source large model that supports 3D generation from both text and images. Less than a month later, Microsoft released a new framework, TRELLIS, to join the competition in the field of 3D asset generation. TRELLIS supports multiple formats of output, including radiation field, 3D Gaussian and mesh, providing maximum flexibility for different needs.
Both models are now available on the hyper.ai official website. Come and try to see which one is better.
Use Hunyuan3D online:https://go.hyper.ai/Rsrno
Using TRELLIS online:https://go.hyper.ai/JE5s5
From January 6 to January 11, hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 6
* Community Article Selection: 8 articles
* Popular encyclopedia entries: 5
* Top conferences with deadlines in January: 7
Visit the official website:hyper.ai
Selected public datasets
1. VSI-Bench Visual Spatial Intelligence Benchmark
The dataset contains more than 5k question-answer pairs, covering nearly 290 real indoor scene videos, involving a variety of environments such as residences, offices, and factories, and covering multiple issues such as object recognition, position relationship, and action prediction.
Direct use:https://go.hyper.ai/q0DYA

2. Facial Feature Extraction Dataset Facial Feature Extraction Dataset
This dataset is a labeled dataset containing 750 images for detecting eyebrows, eyes, nose, lips, and beard regions of the face. The data labeling process was performed in Roboflow and exported from in YOLOv8 format.
Direct use:https://go.hyper.ai/O3kER

3. Sentiment and Emotion Analysis Dataset Sentiment and Emotion Analysis Dataset
The dataset contains 422,000 sentiment analysis sentences and 3,309 emotion analysis sentences as supplements. The sentiment analysis is labeled with 6 different emotions: joy, sadness, anger, fear, love, and surprise.
Direct use:https://go.hyper.ai/wFNO6
4. Eurus-2-RL-Data Mathematical Programming Problem Training Dataset
This dataset is a high-quality dataset specifically used for reinforcement learning training. It is mainly used to solve mathematical and programming problems. It contains about 455k mathematical problems and 27k programming problems.
Direct use:https://go.hyper.ai/Wdo1k
5. Medical o1 Reasoning SFT Medical reasoning dataset
This dataset is designed for fine-tuning the HuatuoGPT-o1 medical language model to improve its performance in complex medical reasoning tasks. The construction of the dataset relies on GPT-4o, which ensures the accuracy and reliability of the data by searching for verifiable medical questions and verifying the answers using a medical verifier.
Direct use:https://go.hyper.ai/XMtXp
6. MCTS Chinese Text Simplified Dataset
The dataset contains 723 complex structured sentences selected from news corpus based on the Penn Chinese Treebank (CTB) standard, and each sentence is equipped with multiple manually simplified versions, making it the largest and most referenced evaluation dataset for the Chinese text simplification task.
Direct use:https://go.hyper.ai/UR3CN
7. educhat-sft-002-data-osm Educational dialogue dataset
The dataset contains 4 million data points, covering a variety of educational verticals, such as open question-and-answer, essay grading, heuristic teaching, emotional support, and course tutoring.
Direct use:https://go.hyper.ai/nQw0K
8. GOAT arithmetic task fine-tuning dataset
This dataset has two files: dataset.json and dataset.ipynb. The dataset.json file contains about 1.7 million synthetic data generated by dataset.ipynb for arithmetic tasks.
Direct use:https://go.hyper.ai/8ZAvG
9. NaturalProofs Mathematical Reasoning Dataset
The dataset is a multi-domain corpus for studying mathematical reasoning in natural language. It contains approximately 30k theorem statements and proofs, 15k definitions, and 2k additional pages (e.g., axioms, corollaries), all written in natural mathematical language.
Direct use:https://go.hyper.ai/Bk4WE
10. TransGPT-pt&sft traffic dialogue pre-training dataset
This dataset is part of TransGPT, the first comprehensive transportation model in China. It contains about 346,000 pieces of text data in the transportation field, which are used for pre-training in the field, and about 58,000 pieces of dialogue data in the transportation field, which are used for fine-tuning.
Direct use:https://go.hyper.ai/vuDHa
Selected Public Tutorials
1. Hunyuan3D: Generate 3D assets in just 10 seconds
Hunyuan3D is a 3D generative diffusion model, including a lightweight version and a standard version, both of which support the generation of high-quality 3D assets from text and image inputs. After qualitative and quantitative multi-dimensional evaluation, Hunyuan3D-1.0 performs very well in terms of geometric details, texture details, texture-geometry consistency, 3D rationality, and instruction compliance.
This tutorial is a lightweight version of Hunyuan3D. Click the link below and follow the tutorial instructions to experience 3D model generation.
Run online:https://go.hyper.ai/Rsrno
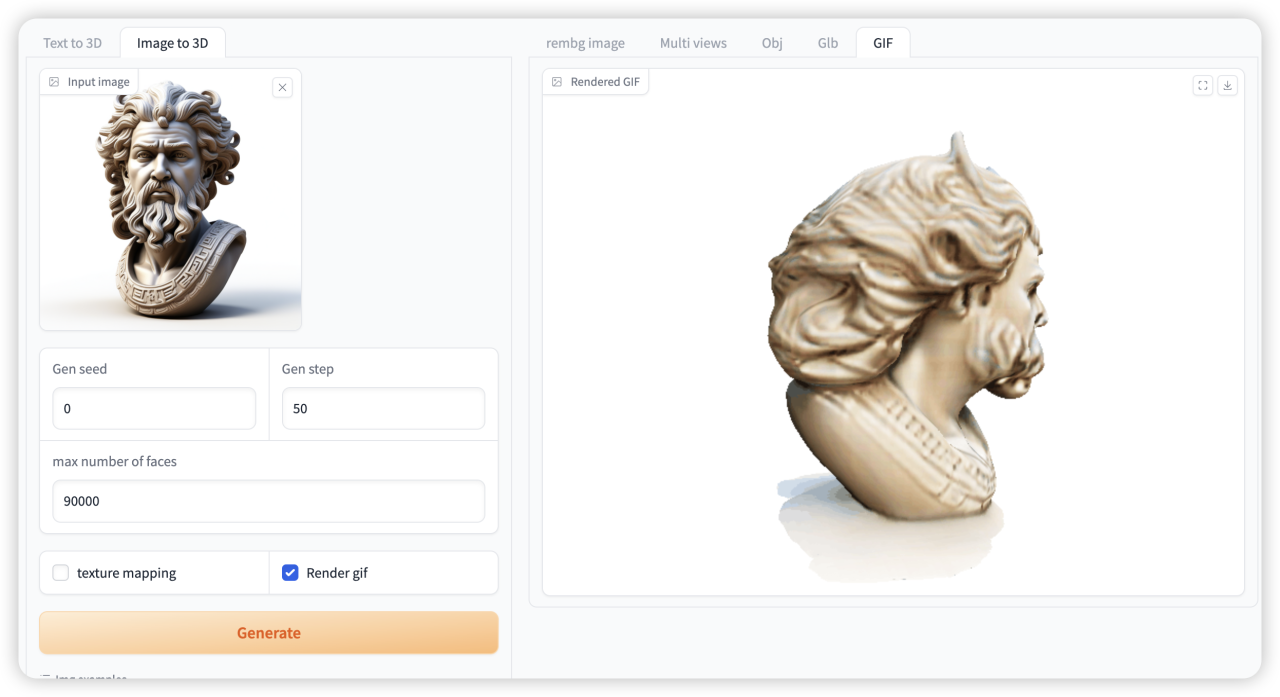
2. TRELLIS: Microsoft's open source 3D asset generation model demo
TRELLIS is a graph neural network-based interpretability framework developed by the Microsoft team in 2024. It aims to provide efficient model interpretability by learning the characteristics of graph structured data.
The model and environment have been deployed. You can use the large model to convert images into 3D images according to the tutorial instructions.
Run online:https://go.hyper.ai/JE5s5

3.Quick deployment of ChatGLM2-6b-32k
ChatGLM-6B is an open-source, bilingual Chinese-English conversational language model based on the General Language Model (GLM) architecture with 6.2 billion parameters. Combined with model quantization technology, users can perform local (INT4 quantization) on consumer-grade graphics cards with as little as 6 GB of video memory.
Follow the tutorial steps and directly copy the generated API address to use ChatGLM-6B.
Run online:https://go.hyper.ai/B0b7V
4. Natural Language Processing with NLTK
NLTK is one of the most popular platforms for creating Python programs that work with natural language data. In addition to text processing libraries for classification, tokenization, stemming, tagging, parsing, and semantic reasoning, it provides simple interfaces to more than 50 large structured text datasets (corpora) and lexical resources.
This tutorial shows how to use NLTK to perform various NLP operations at the text processing stage and create a Keras model with the help of some NLTK tools for sentiment analysis text classification.
Run online:https://go.hyper.ai/BFZ10
5. Audio LDM Audio Editing Tutorial
AudioLDM is a latent text-to-audio diffusion model capable of generating realistic audio samples given any textual input. AudioLDM takes a textual prompt as input and predicts the corresponding audio. It can generate text-conditioned sound effects, human speech, and music.
This project can generate a front-end interactive interface through the Gradio interface. The relevant models and dependencies have been deployed. Click the link below to edit the audio.
Run online:https://go.hyper.ai/BCOWL
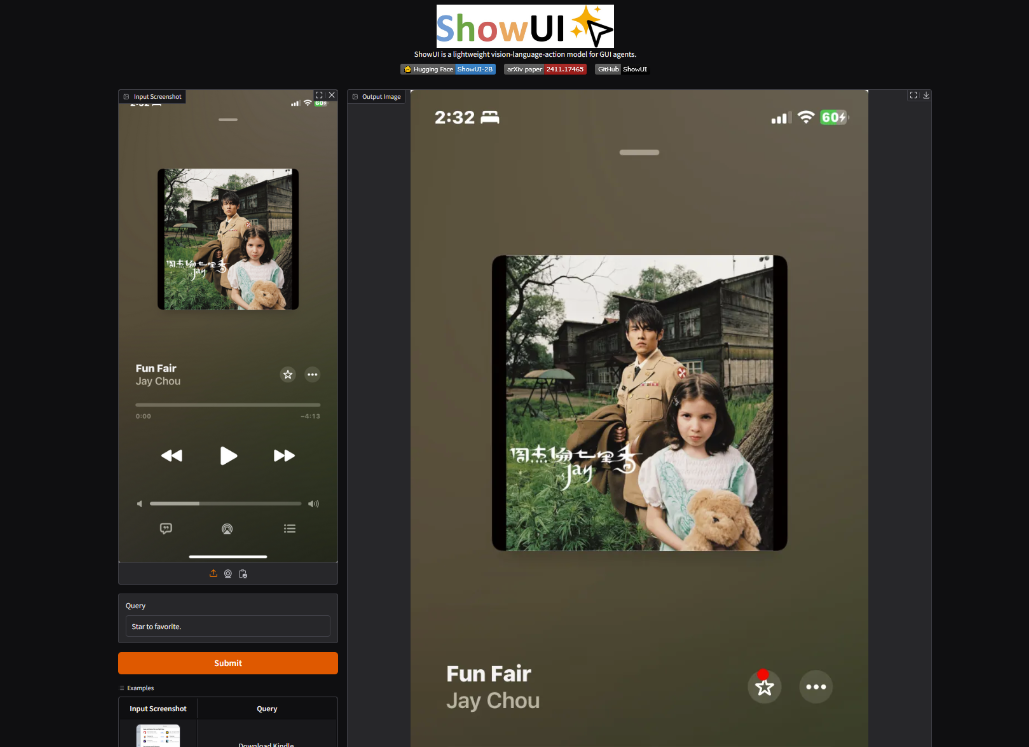
6. ShowUI: A vision-language-action model focusing on GUI automation
The ShowUI model understands the content of the screen interface and performs interactive actions such as clicking, inputting, scrolling, etc. It supports web and mobile application scenarios and can automatically complete complex user interface tasks. ShowUI can parse screenshots and user instructions to predict interactive actions on the interface.
This tutorial is a one-click deployment demo of the model. You only need to clone and start the container and directly copy the generated API address to experience the model.
Run online:https://go.hyper.ai/reHs7
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

Community Articles
During the Christmas season, HyperAI has prepared 10 Christmas-related data sets for you, which support online use and accelerated downloading. Come and experience them.
View the dataset summary:https://go.hyper.ai/if7Lc
Biotech company E11 Bio has launched PRISM technology, which can map the connections between millions of cells in the entire brain at a very low cost. This series of innovations is expected to reduce the overall cost of whole-brain connectomics by at least 100 times, making it possible to explore the human brain in the future. This article is a detailed report on the company, click to read it quickly.
View the full report:https://go.hyper.ai/ISc4j
HyperAI has compiled and reviewed the high-impact events in the field of AI for Science in 2024. Click here to view the detailed report.
View the full report:https://go.hyper.ai/d2Dlv
Against the backdrop of continued global warming, rare extreme climate events have begun to occur frequently. Research teams from Stanford University, Colorado State University, and ETH Zurich used artificial intelligence convolutional neural network systems to predict global warming and found that even if we can achieve rapid emissions reductions, global temperatures are still likely to continue to rise by 90%. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/vDt3e
Xu Zhengtong, a third-year doctoral student at Purdue University, shared his two major research results, the reactive grasping controller LeTac-MPC and UniT for unified tactile representation of robots, with the topic of "Data-efficient tactile representation for robot learning". This article is a summary of the sharing content, click to read it quickly.
View the full report:https://go.hyper.ai/IPIjj
CASP has always been regarded by the industry as a benchmark for protein structure prediction. In this context, HyperAI had the honor of having an in-depth interview with Professor Zheng Wei. Through CASP, an international competition with industry benchmark significance, he analyzed the current development trend in the field of protein structure prediction for us. Full of dry goods, click to read quickly.
View the full report:https://go.hyper.ai/Y83iz
In a recent study, a research team from MIT and Toyota Research Institute deeply studied the complexity of different advanced generative models in polymer generation and proposed a de novo design method that can continuously generate and evaluate new polymer electrolytes based on GPT and diffusion models, providing new candidates for experimental verification. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/PDc8J
At the CES 2025 conference, Nvidia officially announced the RTX 5090, which is the fastest GeForce RTX GPU to date. The initial price is 14,000 yuan, and the Chinese version 5090 D is priced at 16,000 yuan. The RTX 5090 also adds FP4 support, which takes up less memory space and runs generative AI models 2 times faster than the previous generation. This article is a detailed introduction to the product, click to read it quickly.
View the full report:https://go.hyper.ai/dyyZS
Popular Encyclopedia Articles
1. Nuclear Norm
2. Paired t-Test
3. Large-scale Multi-task Language Understanding (MMLU)
4. Sigmoid function
5. The least square method
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
January deadline for the top conference
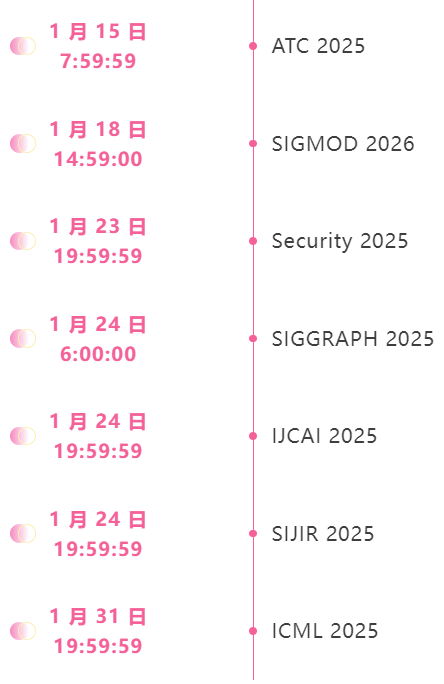
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1700+ public data sets
* Includes 500+ classic and popular online tutorials
* Interpretation of 200+ AI4Science paper cases
* Supports 600+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:
Finally, I recommend a "Creator Incentive Program". Interested friends can scan the QR code to participate!









