Command Palette
Search for a command to run...
Running Llama 3.3 Online, the Only Open Source 70B Model, With Performance Comparable to 405B! LaTeX OCR Dataset Is Online to Help Mathematical Formula Recognition

Just this month, Meta released the only open source model of Llama 3.3, Llama-3.3-70B-Instruct. Although the parameter size is only 70B, it is comparable to the performance of the 405B model. This is the last model of the Llama 3 series. Zuckerberg said that goodbye is Llama 4!
The hyper.ai official website has launched "One-click deployment of Llama-3.3-70B-Instruct" in the tutorial section. Let's experience the final work of Llama 3 together~
Online use:https://go.hyper.ai/TthEw
From December 23rd to December 29th, hyper.ai official website updates:
* High-quality public datasets: 10
* Selection of high-quality tutorials: 3
* Community Article Selection: 6 articles
* Popular encyclopedia entries: 5
* Top conferences with deadlines in January: 9
Visit the official website:hyper.ai
Selected public datasets
1. CompreCap Image Description Dataset
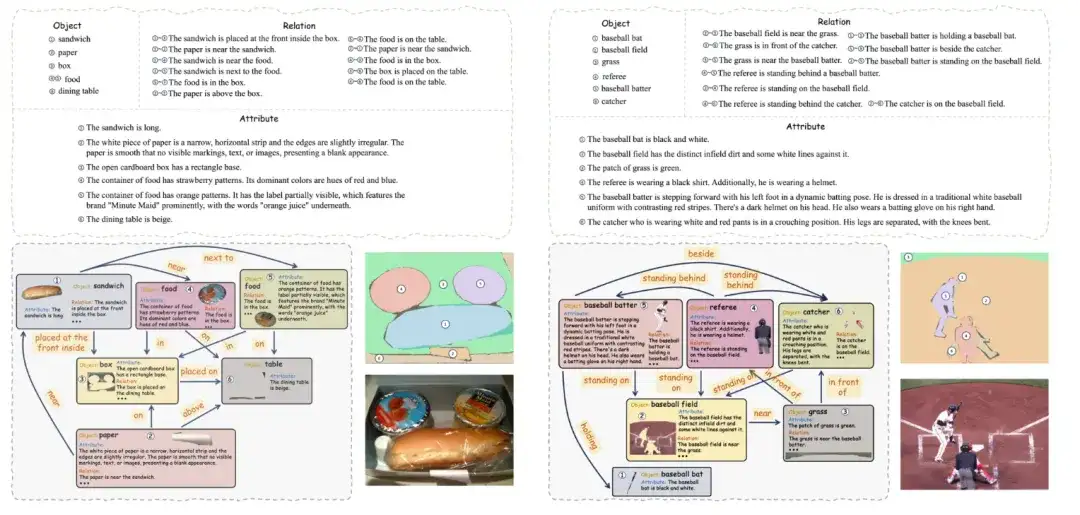
The dataset contains 560 images, each of which has been finely semantically segmented and annotated with objects, attributes, and relationships to form a complete oriented scene graph structure.
Direct use:https://go.hyper.ai/icfaH
2. HelmetViolations Helmet Recognition Dataset
The dataset contains a total of 1,004 images, annotated in YOLOv9 format, and includes 3 categories: license plate (Plate), helmet (WithHelmet), and no helmet (WithoutHelmet). The training set has 363 images (original + enhanced); the validation set has 53 images; the test set is included in the export for model evaluation.
Direct use:https://go.hyper.ai/N0Yyg

3. SynCamVideo-Dataset Multi-camera Synchronous Video Dataset
The dataset contains 1k different scenes, each captured by 36 cameras, generating a total of 36k videos, with 50 different animals as "main subjects" and using 20 different locations from Poly Haven as backgrounds.
Direct use:https://go.hyper.ai/oIJns

4. Airplain Image Classification Aircraft Image Classification Dataset
This dataset is a dataset containing 3,371 aircraft images, which are divided into 10 category folders, each category corresponding to a specific aircraft model: A10, A400M, AG600, AH64, AV8B, An124, An22, An225, An72 and B1, etc.
Direct use:https://go.hyper.ai/IL3uP

5. MangaZero comic image dataset
The MangaZero dataset is a large-scale, multi-character, multi-state comic image dataset designed specifically for comic generation tasks. It contains 43,264 pages of comics and 427,147 annotated panels. It supports the visualization of various character interactions and actions in consecutive frames and is suitable for multi-character, multi-state comic generation tasks.
Direct use:https://go.hyper.ai/IpkjL
6. LaTeX OCR Mathematical Formula Recognition Dataset
The LaTeX OCR dataset is a dataset that focuses on the complex mathematical formula recognition problem in the field of optical character recognition (OCR). The LaTeX OCR dataset contains multiple configurations, each with different features and data partitioning.
Direct use:https://go.hyper.ai/lyK1J
7. FSQ OS Places Open Source Location Dataset
This dataset contains more than 100 million global points of interest (POIs), covering more than 200 countries and regions, enabling researchers, developers and enterprises to access rich geospatial data. It provides 22 core attributes, including key information such as place name, address, longitude and latitude, which support a variety of applications such as geospatial analysis and location services.
Direct use:https://go.hyper.ai/7oN5M
8. ProcessBench Mathematical Reasoning Benchmark Dataset
This dataset contains 3.4k test examples, focusing on math problems of competition and Olympic difficulty. Each example is equipped with a step-by-step solution, and the errors are accurately marked by domain experts.
Direct use:https://go.hyper.ai/fk3hq
This Chinese medical dataset is a comprehensive resource for developing and training language models that can provide professional conversations and advice in the medical field. It combines multiple types of data, including encyclopedia knowledge, textbook texts, actual doctor-patient conversations, and evaluation data, aiming to improve the accuracy and practicality of the model.
Direct use:https://go.hyper.ai/wkAXX
10. splsoNet Anisotropy Correction and Misalignment Correction Tutorial Dataset
spIsoNet is an end-to-end self-supervised deep learning software used to solve the map anisotropy and particle misalignment problems caused by the preferred orientation problem. This dataset is used in research and the relevant results have been published in the international academic journal Nature Methods.
Direct use:https://go.hyper.ai/tFOqJ
Selected Public Tutorials
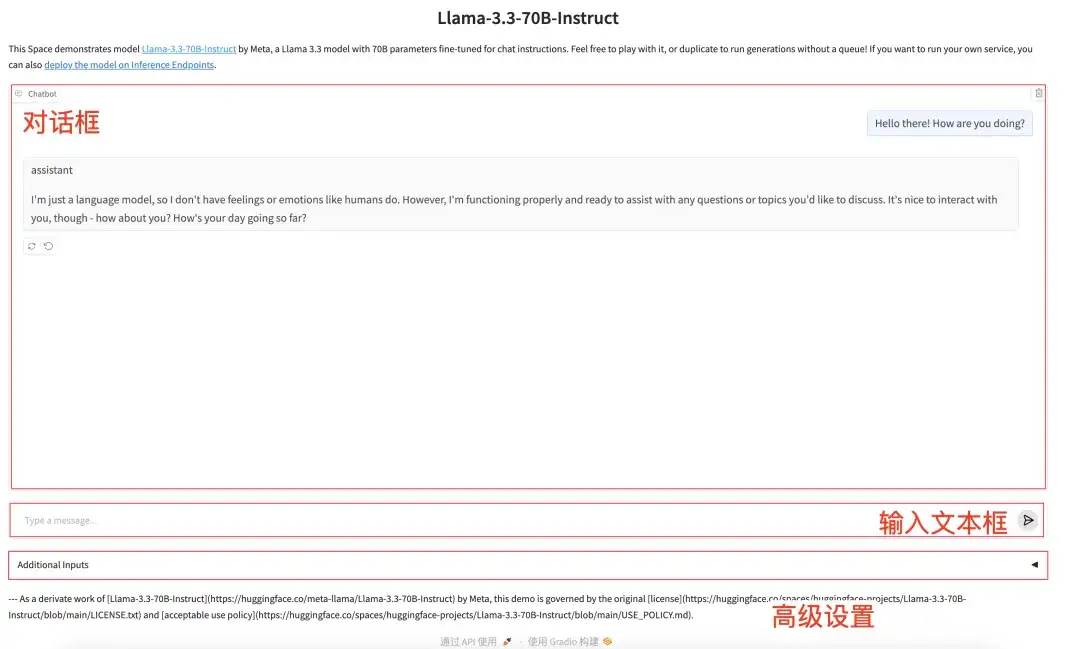
1. One-click deployment of Llama-3.3-70B-Instruct
Llama-3.3-70B-Instruct is a large language model launched by Meta in 2024. It is the only open source model in the Llama 3.3 series, and has a specially optimized instruction fine-tuning version.
The model has configured the environment and dependencies. You can start a conversation with the model by entering the API address.
Run online:https://go.hyper.ai/TthEw
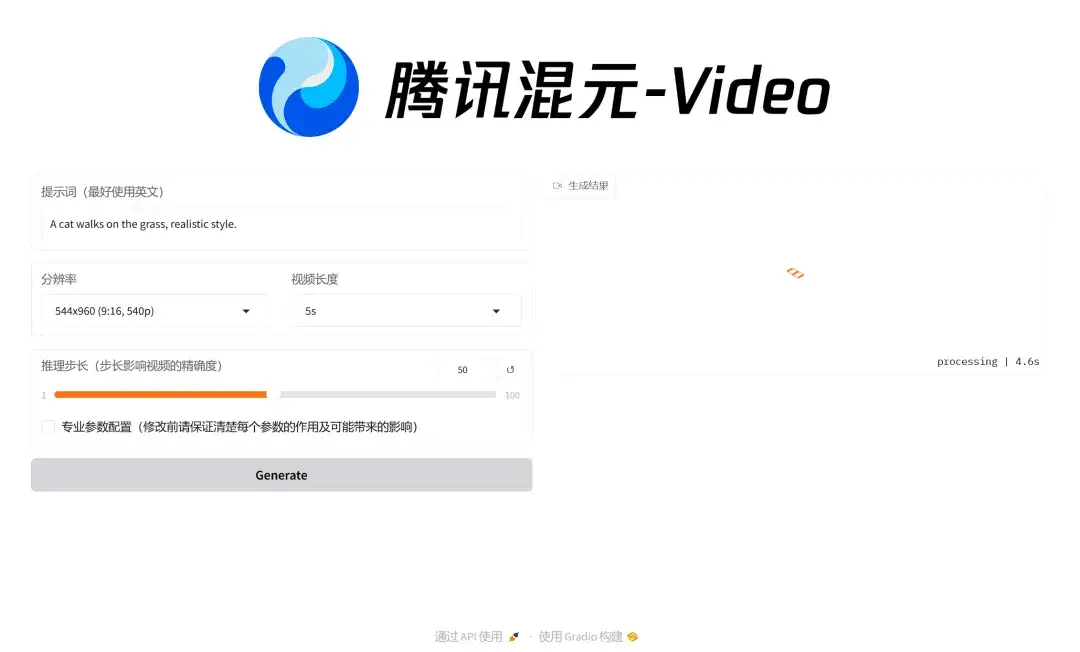
2. HunyuanVideo Tencent Hunyuan Wensheng Video Demo
HunyuanVideo aims to help users generate high-quality video content through artificial intelligence technology. HunyuanVideo is the Wensheng video model with the largest number of parameters among the current open source models, with 13 billion parameters. It can generate video content with high physical accuracy and scene consistency, providing users with a hyper-realistic visual experience and the ability to freely switch between real and virtual styles.
The project provides a convenient web interface, and users can generate videos of various styles by simply providing a simple text description or specifying conditions.
Run online:https://go.hyper.ai/hEkOw
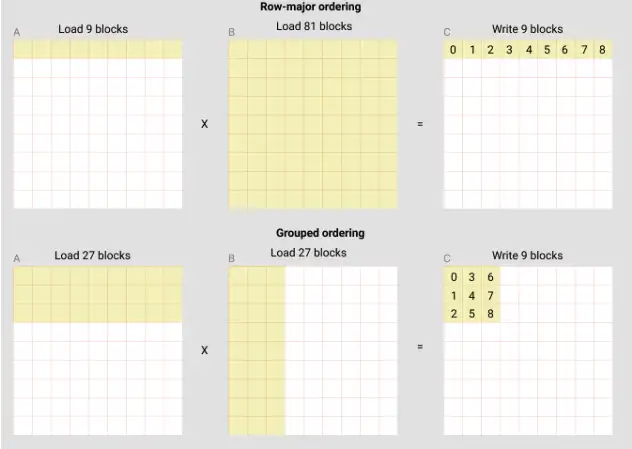
3. Triton Tutorial: Matrix Multiplication
In this tutorial, you will write a very short, high-performance FP16 matrix multiplication kernel that is comparable to cuBLAS or rocBLAS in performance. You will learn about: 1-level matrix multiplication; multidimensional pointer arithmetic; program reordering to improve L2 cache hit rate; automatic performance tuning.
Run online:https://go.hyper.ai/riM7b
Community Articles
HyperAI has selected and classified 26 cutting-edge papers interpreted during 2023-2024. This article focuses on the research of AI in the field of materials chemistry. It is a comprehensive review, so click to read it quickly.
View the full report:https://go.hyper.ai/XnzcN
As a British high-tech chemical company, Chemify has developed the world's first "chemical Turing machine" and the world's first chemical compiler. It is committed to integrating chemical computing, artificial intelligence, robotics, automation, etc. into drug research and development to promote the digital development of chemistry. This article is a detailed report on the company. Click to read it quickly.
View the full report:https://go.hyper.ai/V5VWB
Professor Tu Wei and Professor Lu Feng from Huazhong University of Science and Technology proposed a medical image segmentation model that can accurately identify lymphocyte clusters in pathological images of patients with Sjögren's syndrome, helping doctors make faster and more accurate diagnoses. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/EetpB
Zhang Shixin's team at China University of Geosciences (Beijing) has been conducting research on visual tactile sensors since 2014, exploring and developing multiple generations of sensor technology, and calling it a cutting-edge tactile technology, TactEdge. This article is a detailed introduction to the relevant research results, click here to take a quick look.
View the full report:https://go.hyper.ai/nOE2a
5. A review of medical AI breakthroughs in 2024, 35 cutting-edge papers you can’t miss
This article focuses on the research of AI in the field of healthcare. We have selected 35 cutting-edge papers interpreted from 2023 to 2024 for you to share super dry goods. Click to read quickly.
View the full report:https://go.hyper.ai/CZdYT
The University of California, Berkeley, Microsoft Research, and others proposed a multimodal protein generation method called PLAID, which can generate scarcer modalities from richer data modalities to achieve multimodal generation. This article is a detailed interpretation and sharing of the paper.
View the full report:https://go.hyper.ai/nwnDy
Popular Encyclopedia Articles
1. Sigmoid function
2. Reciprocal sorting fusion RRF
3. Nuclear Norm
4. Large Language Model
5. Long Short-Term Memory
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:

One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!








