Command Palette
Search for a command to run...
Meta Proposes AI Data Scientists, and Autodata Builds high-quality training/evaluation datasets.

In recent years, the continuous improvement of large-scale model capabilities has been reshaping the development path of artificial intelligence. However, an increasingly clear consensus is that the boundary of model performance is gradually shifting from "algorithm innovation-driven" to "data quality-driven." Against the backdrop of increasingly scarce and costly high-quality human-annotated data, synthetic data is gradually becoming an important support method in the post-training stage. It can generate marginal cases and long-tail scenarios that are relatively scarce in real-world corpora; reduce the difficulty and latency of manual annotation; and in some cases, generate training samples with distributions more challenging than human data.
With the emergence of Large Language Models (LLMs), "Self-Instruction" was proposed as a method to generate synthetic data using zero-shot or few-shot prompts. Building on this, "Grounded Self-Instruction" further incorporates external sources such as documents as constraints to reduce illusions and enhance diversity. Additionally, "CoT Self-Instruction" introduces chain-like reasoning during the generation process to construct more complex and accurate tasks. Finally, a class of so-called "self-challenging" methods allows a challenger agent to interact with the tool before proposing the task and its evaluation function. However, none of these methods can directly control the difficulty and quality of the data, thus giving rise to improvement strategies such as filtering, evolution, and refinement.
In this context,The Meta Basic Artificial Intelligence Research Team (FAIR at Meta) proposed a general method called Autodata.All the methods described above have been unified and generalized. In this framework, an intelligent agent, acting as a "data scientist," is responsible for building and organizing data, mimicking the workflow of a human data scientist to generate high-quality data. This process includes not only the initial data generation but also the data analysis phase (similar to "human review"), evaluating its performance, summarizing experiences, and iteratively generating better data solutions based on these assessments.
Researchers conducted experiments on computer science research tasks, legal reasoning tasks, and mathematical object reasoning tasks, achieving better results compared to traditional synthetic data construction methods. Furthermore, meta-optimization of the data scientist agent itself resulted in even more significant performance improvements.
The related research findings, titled "Autodata: An agentic data scientist to create high-quality synthetic data," have been published as a preprint on arXiv.
Research highlights:
* The agent-based data generation method provides a path to transform inference computing resources into higher-quality model training data.
* The data scientist agent itself can also be meta-optimized, leading to significant performance improvements without the need for human prompts or engineering.
* This research has the potential to change how future tasks and benchmarks are built to drive the forefront of AI development.

Paper address:
https://hyper.ai/papers/2606.25996
Dataset: Covering three core task scenarios
The Autodata framework covered three core task scenarios in the experiments: computer science research problems, legal reasoning tasks, and scientific reasoning tasks based on mathematical objects.These tasks are built on different data source systems to test the framework's generalization ability under different cognitive structures.
In computer science tasks,Researchers processed over 10,000 computer science papers from the S2ORC corpus (2022 and later).2,800 accepted samples were generated using Agentic Self-Instruct.After the loop ends, these samples are further filtered using a Kimi-K2.6-based quality validator to remove those with issues such as leakage of paper-specific information, insufficient context, or incorrect scoring criteria format. Finally, 1,300 high-quality samples are retained as the Agentic Self-Instruct dataset for reinforcement learning (RL) training.
In legal reasoning tasks,The data comes from publicly available legal documents such as the Pile of Law, including court judgments and legal opinions, and is evaluated on PRBench-Legal and its difficult subset PRBench-Legal-Hard. Unlike scientific papers,Legal texts have stronger structured logical constraints and case law dependence, so the generation task places more emphasis on the ability to extract facts and apply rules.
In scientific reasoning tasksThe research is based on the Principia dataset. The Principia dataset was constructed using the CoT Self-Instruct method and covers a wide range of course content in the MSC2020 and PHYS taxonomy. The Principia benchmark consists of a subset of existing mathematical and physical benchmarks annotated by humans. These questions have been screened to ensure that the answers involve mathematical objects.
In all tasks, Autodata's goal is not simply to generate question-and-answer pairs, but to generate training data that can effectively distinguish between weak and strong models.
Autodata: Employing autonomous intelligent agents to simulate the role of data scientists.
The top-level design of Autodata is shown in the figure below.The framework employs an autonomous intelligent agent to simulate the role of a data scientist.By generating data iteratively, conducting qualitative checks and quantitative performance evaluations, comprehensively analyzing the insights gained, and updating the data generation method accordingly, various different implementation forms can be built on this template.
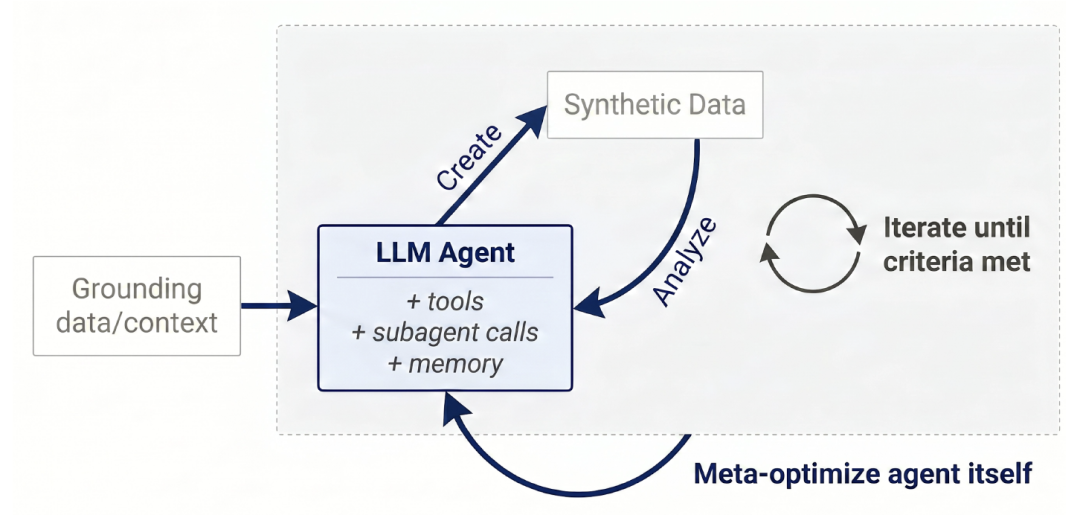
Autodata Workflow
The overall loop consists of the following components:
① Data Creation
The Autodata agent "grounds" provided data (e.g., specific documents in fields like mathematics, law, or programming, or other task-specific data sources) to aid in data generation. This agent can use tools or its existing skills and experience, and leverage computational resources from the inference phase, to generate training and benchmark data for model training or evaluation. This data generation step can be repeated after subsequent analysis and learning, continuously improving and enhancing data quality.
② Data Analysis
After obtaining the data generated by the agent, the system analyzes this data to summarize what it "did right" and "did wrong," and how to further improve it. This analysis can occur at different levels: it can be at the level of a single sample (e.g., judging whether an example is correct, of high quality, or sufficiently challenging), or at the level of the entire dataset (e.g., whether the samples are diverse, and whether they can improve model performance as training data). The conclusions from these analyses are fed back to the data generation stage, thereby generating better data in the next iteration, until the stopping condition is met.
③ Overall Data Scientist Loop
The agent continuously cycles between "data generation and data analysis" until it is satisfied with the data quality, ultimately generating a high-quality training dataset or benchmark. Specific safety or constraint mechanisms can be added to the outer loop to prevent the system from being hacked. This agent-based loop allows the model to continuously accumulate and utilize its learning outcomes throughout the process.
④ Meta-Optimization of the Data Scientist
The agent itself can also be further optimized to make it better suited to act as a data scientist. One approach is to optimize the agent framework using methods similar to autoresearch or meta-harness, and leverage the same inner-loop objective (i.e., "generating better data") to guide outer-loop optimization, thereby improving the entire agent system.
In its implementation, the paper proposes Agentic Self-Instruct as an instantiation method of Autodata, as shown in the figure below:
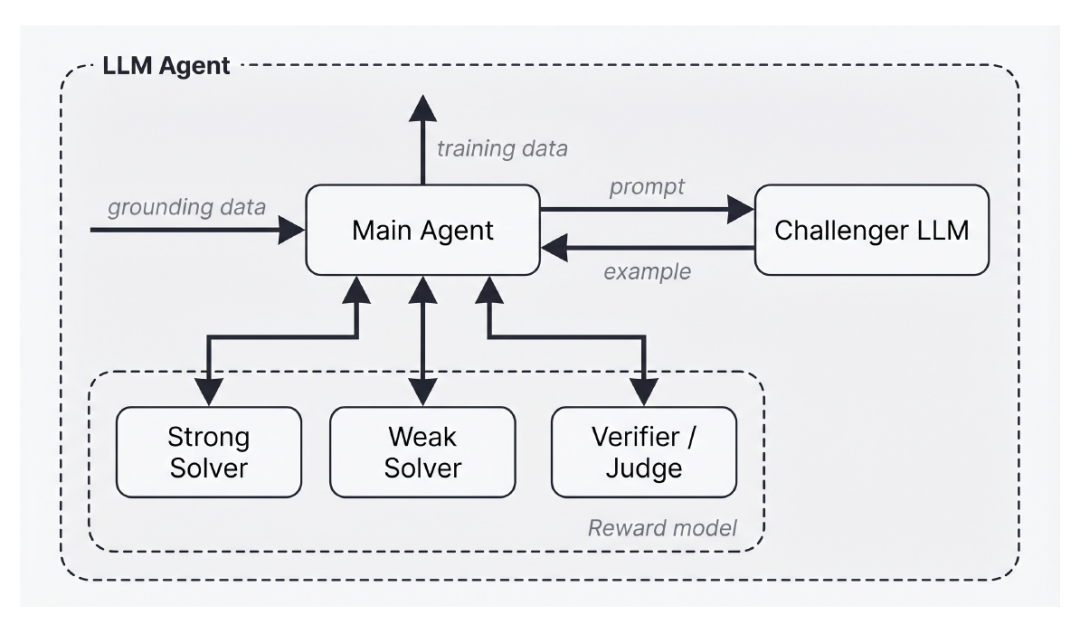
Weak-strong contrast Agentic Self-Instruct method
The main orchestrator agent in this method can access four sub-agents based on the Large Language Model (LLM):
* Challenger: Generates training samples based on detailed prompts provided by the main agent;
* Weak solver: A model that typically struggles to solve the generated training data;
* Strong solver: A model that can typically solve the generated training data successfully;
* Verifier/judge: After providing samples and model solutions, the verifier/judge checks the quality of the solutions and feeds back the learning results to the main agent.
The goal of this system is to generate training data that allows strong solvers to successfully complete tasks while weak solvers struggle. The master LLM analyzes feedback from reviewers and updates the hints sent to challengers accordingly. This cycle is repeated continuously to generate high-difficulty samples for training the weak solver.
Results Showcase: Achieved superior results compared to traditional synthetic data construction methods
The researchers' experiments covered three task domains, thus validating the effectiveness of the Autodata framework across multiple dimensions.
Computer Science Tasks
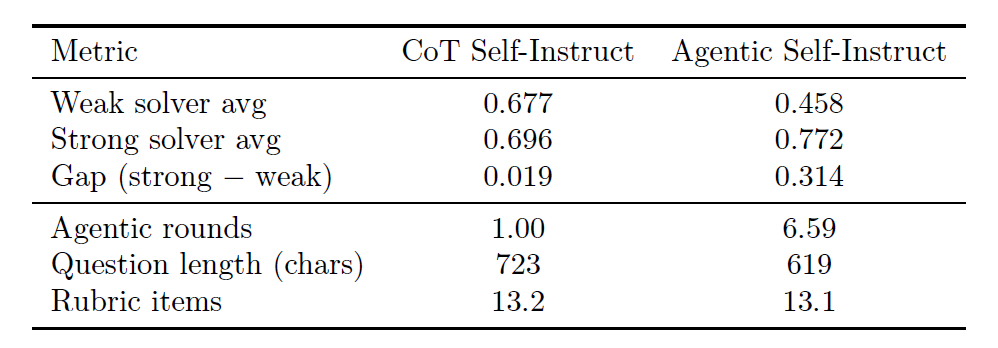
In computer science tasks, data generated by Agentic Self-Instruct significantly reduces the confusion rate between weak and strong models, making the training signal clearer.
On problems generated using the baseline CoT Self-Instruct method, the weak solver achieved an average score of 0.677. However, on the same source material (papers) problems generated using Agentic Self-Instruct, the weak solver score decreased by 22 percentage points (0.677 → 0.458), while the strong solver score increased by 8 percentage points (0.696 → 0.772), as shown in the table below.This indicates that the final accepted question has a greater incentive effect on the deep reasoning ability of the strong model.
In RL training, on the simpler CoT Self-Instruct test set (left side of the table below), training with CoT data improves the mean@3 of the basic 4B model from 0.630 to 0.727, while training with Agentic data further improves it to 0.774. On the more difficult Agentic test set (right side of the table below), the corresponding results are: 0.366 (basic model) → 0.500 (CoT training) → 0.632 (Agentic training). The difference between the two methods is significantly larger on this test set (more than twice that of the CoT test set), and the best@3 metric also shows the same ranking.
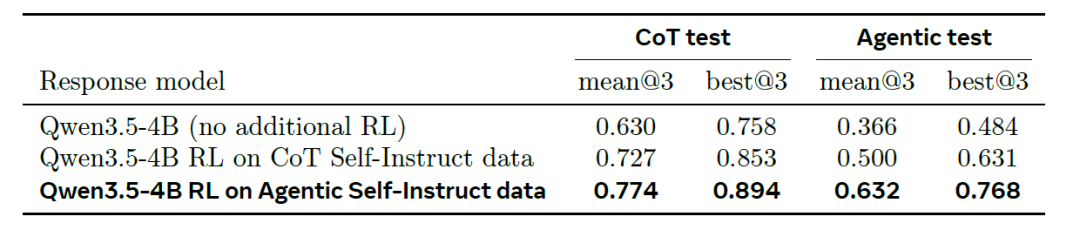
The Agentic-trained model demonstrated transferability in both directions (+0.05 on the CoT test set and +0.13 on the more difficult Agentic test set). This significant advantage suggests that the more discriminative training data generated by the Agentic pipeline can translate into stronger inference capabilities.
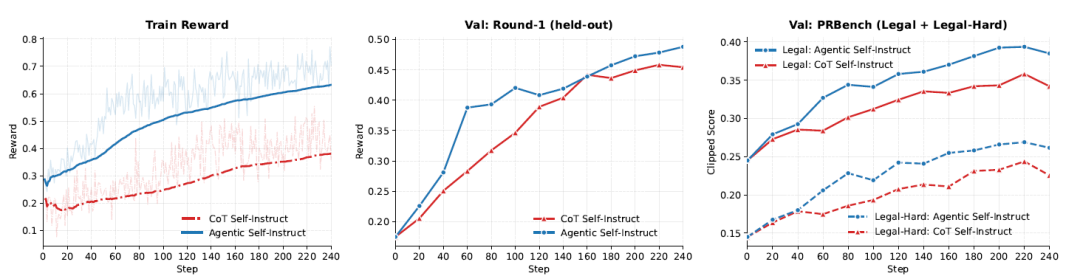
Legal reasoning task
In legal reasoning tasks, research has revealed a contrasting but equally important phenomenon: the data generated by traditional CoT is often too difficult, causing weak models to provide almost no effective gradient signals (resulting in a large number of zero-score outputs). Autodata, by introducing a more granular evaluation feedback mechanism, brings the data difficulty back to the "learnable range," significantly improving the stability and effectiveness of GRPO training.
Researchers used GRPO to train Qwen3.5-4B on two data sources: 2.8k legal question-rubric pairs (Agentic Self-Instruct and CoT Self-Instruct). During training, every 20 steps, the dataset was tested on two evaluation sets: a CoT holdout set containing 100 prompts and a PRBench Legal/Legal-Hard split. All rewards and scores were evaluated using Kimi-K2.6. The training curve in the figure below shows that at each evaluation checkpoint...Agentic methods consistently lead in training rewards, CoT validation sets, and PRBench-Legal.
Scientific reasoning task
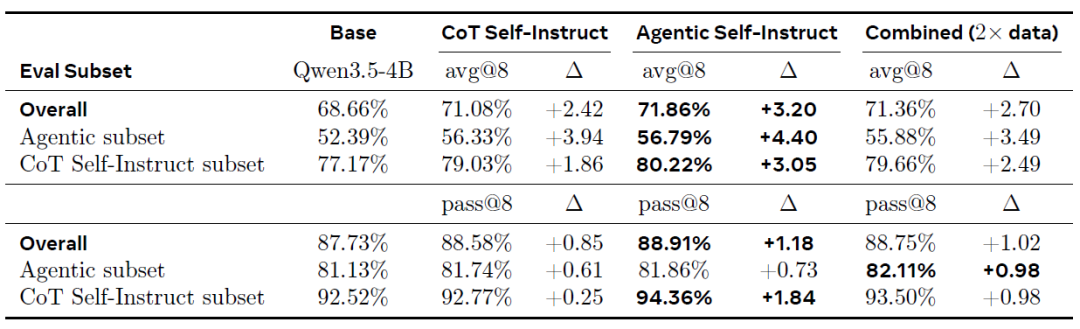
In scientific reasoning tasks, Agentic Self-Instruct also demonstrates a consistent advantage. On the combined validation set (as shown in the table below), training with Agentic Self-Instruct data achieved the largest overall improvement (+3.20% avg@8), outperforming direct use of CoT Self-Instruct (+2.42%) and Combined data (+2.70%).
Evaluation of reinforcement learning training results on scientific reasoning tasks
A key finding is that even on the unoptimized CoT validation subset, Agentic Self-Instruct still delivers a higher performance improvement (+3.05% vs. CoT's +1.86%). This suggests that...Training on more difficult tasks can be transferred to simpler tasks: by iterating over high-difficulty samples generated through an agentic process, generalizable reasoning abilities can be learned, rather than being limited to a specific difficulty distribution.
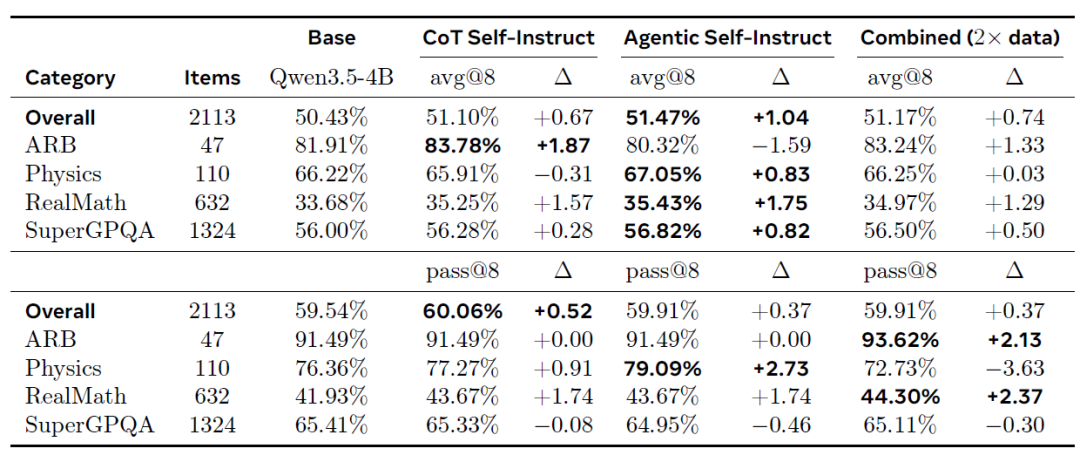
On the out-of-distribution Principia benchmark (as shown in the table below), Agentic Self-Instruct also achieved the best average improvement (+1.04% avg@8) and consistently led across multiple categories, particularly RealMath (+1.75%) and SuperGPQA (+0.82%). This transfer effect further demonstrates that the more difficult problems generated by Agentic Self-Instruct can improve robust reasoning capabilities.
Conclusion
In summary, Autodata proposes a novel data generation paradigm: modeling the data generation process as a data science loop driven by an intelligent agent. Within this framework, data generation, evaluation, failure analysis, and policy optimization are unified within a single closed-loop system. Further meta-optimization experiments demonstrate that the data science agent itself can also be optimized, thereby improving data quality without the need for human intervention.
Overall, the core contribution of this research lies in providing a mechanism to transform computational resources used in the inference phase into the ability to generate higher-quality training data. In the future, this direction still has significant room for expansion, including larger-scale task adaptation, more complex multi-turn agent collaboration, and global optimization at the dataset level. Furthermore, reintroducing human feedback into the loop to form a collaborative optimization mechanism with the agent is also considered an important direction for future development.








