Command Palette
Search for a command to run...
Overcoming the Difficulties of OCR Handwriting Recognition! InkSight Tutorial Is Online to Achieve high-precision Transcription; iNatSounds Dataset Is Released, Including 230,000 Natural Species Audio

Handwritten notes are a way for many people to record inspiration in their daily lives, but how to efficiently convert handwritten content into electronic text has always been a major challenge. Traditional OCR (optical character recognition) technology often has limited accuracy when dealing with complex backgrounds or irregular handwriting.
To solve this problem, Google Research recently launched the InkSight technology, which simulates the human reading process through deep learning, accurately recognizes handwritten text and perfectly restores its style. Unlike traditional OCR, InkSight can still maintain high accuracy in low light or complex backgrounds, supports word-level and full-page transcription, and the effect is almost the same as the original handwriting. This technology has shown great potential in the fields of document digitization and cultural heritage protection.
In order to help many handwriting enthusiasts easily digitize their inspiration and facilitate the high-precision transcription of precious documents,The InkSight tutorial is now available on the hyper.ai official website. You can experience it by cloning it with one click~
Run online:https://go.hyper.ai/gVh8a

From November 11th to November 15th, hyper.ai official website updates:
* High-quality public datasets: 10
* High-quality tutorial selection: 6
* Community article selection: 4 articles
* Popular encyclopedia entries: 5
* Top conferences with deadline in November: 2
Visit the official website: hyper.ai
Selected public datasets
1. DrivingDojo Autonomous Driving Dataset
The DrivingDojo autonomous driving dataset contains about 18k video clips, specifically simulating real-world visual interactions, covering rich driving actions, multi-agent interactions, and open-world driving knowledge. This dataset aims to advance the development of interactive and knowledge-rich driving world models.
Direct use:https://go.hyper.ai/Y86yY

2. TuSimple US highway road image dataset
The TuSimple dataset contains 6,408 images of US highways, including 3,626 for training, 358 for validation, and 2,782 for testing. The image resolution is 1280×720, and all images are taken under different weather conditions.
Direct use:https://go.hyper.ai/Mo6bt

3. Sport Classification 100 sports image dataset
The dataset covers a set of motion images of 100 different sports, and all images are in 224x224x3 jpg format. The data is divided into training images, test images, and validation images. In addition, the dataset also comes with a CSV file to facilitate researchers to load and process these image data.
Direct use:https://go.hyper.ai/715At

4. House Plant Species 47 indoor plant species dataset
The dataset was collected from Bing Images and contains 14,790 images classified into 47 different plant species categories.
Direct use:https://go.hyper.ai/v7wTX

5.BIOSCAN-5M Multimodal Insect Biodiversity Dataset
BIOSCAN-5M is a comprehensive multimodal insect biodiversity dataset designed to understand and monitor global insect biodiversity. The dataset contains detailed information on more than 5 million insect specimens, significantly expanding existing image-based biological datasets.
Direct use:https://go.hyper.ai/YDeuN

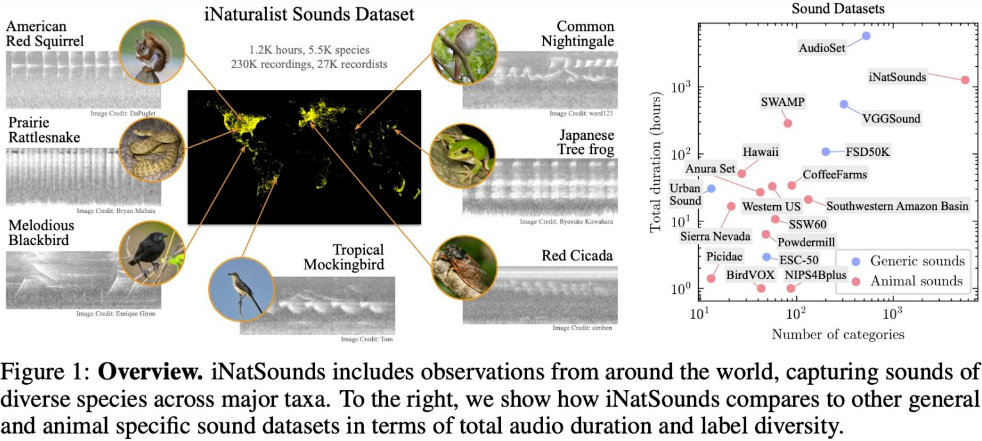
6. iNaturalist Sounds Dataset Natural Species Sound Dataset
The dataset is a collection of natural species audio files, which collects 230k audio files, capturing sounds from more than 5.5k species, contributed by more than 27k recorders worldwide.
Direct use:https://go.hyper.ai/S0lg6
7. OpenSatMap High-resolution Satellite Dataset
OpenSatMap is a high-resolution satellite dataset designed for large-scale map building, which includes images of not only many cities in China, but also more than 50 cities and 18 countries around the world. These images have reached a resolution of 20 levels, the highest among existing satellite datasets.
Direct use:https://go.hyper.ai/PtbCB
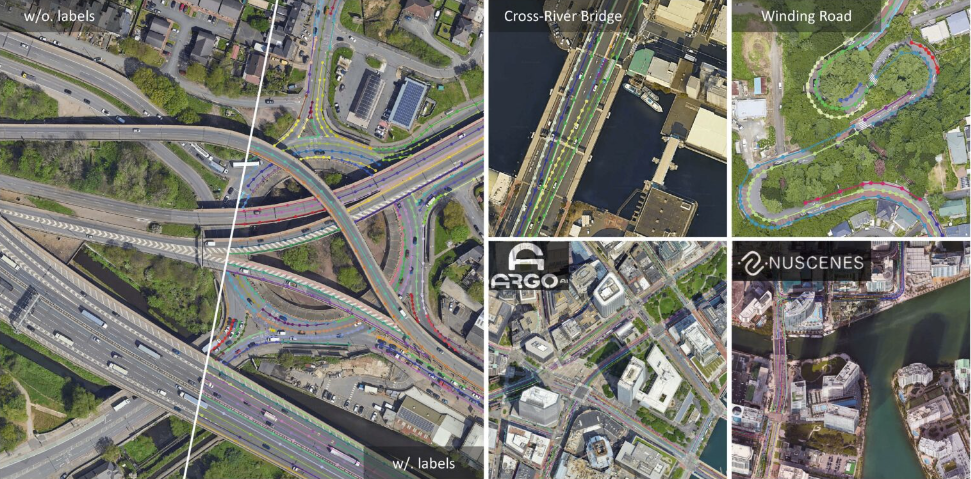
8. Cards Image Card Image Dataset
Cards Image is a playing card image dataset. The dataset contains 7,624 training images, 265 test images, and 265 validation images, all of which are in 224x224x3 jpg format. Each image is carefully cropped to ensure that only one playing card is shown, and the card occupies more than 50% of the pixel area of the image.
Direct use:https://go.hyper.ai/DuOJb
9. PD12M Large-Scale Image-Text Pair Dataset
PD12M is the largest public domain image-text pair dataset, containing 12.4 million high-quality public domain and CCO licensed images with synthetic captions, mainly used for training text-to-image models.
Direct use:https://go.hyper.ai/xyjrD

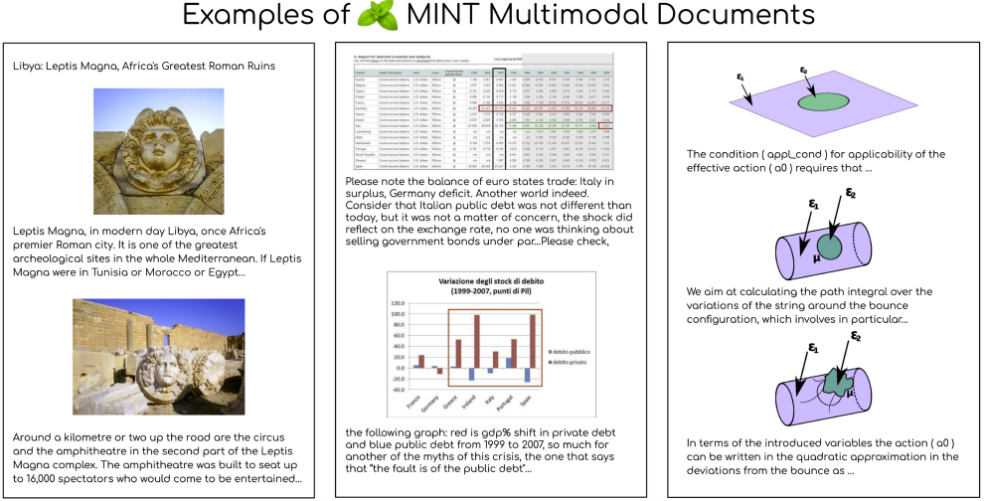
10. MINT-1T Text-Image Multimodal Dataset
The MINT-1T dataset is a multimodal dataset that contains one trillion text tags and 3.4 billion images, which is 10 times the size of the previous largest open source dataset. The dataset includes not only HTML documents, but also PDF documents and ArXiv papers, significantly improving the coverage of scientific documents.
Direct use:https://go.hyper.ai/Vf3mq
Selected Public Tutorials
1. InkSight Demo to digitize handwritten text
InkSight is a technology for handwritten text recognition and digitization. This technology mimics the human reading and learning process, constantly rewriting and learning handwritten text, thereby accumulating an understanding of the text's appearance and meaning. Compared with traditional optical character recognition (OCR) technology, InkSight has demonstrated higher recognition accuracy when dealing with handwritten text in complex backgrounds, blurry or low-light conditions.
This project can generate a front-end interactive interface through the Gradio interface. The relevant models and dependencies have been deployed. You can experience handwriting conversion with one-click startup.
Run online:https://go.hyper.ai/gVh8a

2. CharacterGen generates high-quality 3D characters from a single image
CharacterGen takes a single input image and generates a 3D posed unified character mesh with high quality and consistent appearance, ready for use in downstream rigging and animation workflows.
This tutorial is a one-click run demo of CharacterGen. The relevant environment and dependencies have been installed. You can experience generating high-quality 3D characters by cloning and starting.
Run online:https://go.hyper.ai/jtVAF

3. One-click deployment of Ministral-8B-Instruct-2410
Ministral-8B is a language model developed by the Mistral AI team specifically designed for edge devices and edge computing scenarios. It can perform multiple tasks, including answering questions, translating texts in different languages, making document summaries, helping to write articles and reports, etc. It uses an interleaved sliding window attention model, which not only improves the model's reasoning speed, but also significantly reduces memory usage, making it very suitable for running on resource-constrained edge devices.
Go to the official website to clone and start the container, directly copy the API address, and you can communicate with the model.
Run online:https://go.hyper.ai/wMQWN
4. VASP Tutorial: 1-1. DFT Calculation of Isolated Oxygen Atoms
VASP is a software package for electronic structure calculations and quantum mechanics-molecular dynamics simulations. It is one of the most popular commercial software for material simulation and computational material science research. Its high accuracy and powerful functions make it an important tool for researchers to predict and design material properties. It is widely used in solid physics, materials science, chemistry, molecular dynamics and other fields.
This tutorial is the first part of the VASP official tutorial: DFT calculation of isolated oxygen atoms. Click the link below and follow the tutorial instructions to start DFT high-performance calculations from scratch.
Run online:https://go.hyper.ai/pa2NX
💡We have also established a Stable Diffusion tutorial exchange group. Welcome friends to scan the QR code and remark [SD tutorial] to join the group to discuss various technical issues and share application results~

Community Articles
Since drug development lacks a unified standard paradigm, the development process is complex and requires accurate data annotation, which limits the application of large language models in the field of drug development. In response to this, research teams from four major universities jointly proposed a large language model Y-Mol guided by multi-scale biomedical knowledge. It can be fine-tuned on different text corpora and instructions, enhancing the performance and potential of the model in drug development. This article is a detailed interpretation and sharing of the research paper.
View the full report:https://go.hyper.ai/14X5I
As a world-class master in the field of protein design, David Baker has open-sourced many deep learning tools. He is also the "academic king", having published more than 700 research papers on proteins, with a total of 177,000 citations. As a founder, David Baker has directly participated in the development of 21 companies, covering areas including disease treatment, food production, and materials science. Click to read to learn about David Baker's legendary experience.
View the full report:https://go.hyper.ai/ItxvG
At the COSCon'24 AI for Science forum co-produced by HyperAI, Jingtao Ding, a postdoctoral researcher from the Center for Urban Science and Computational Research, Department of Electronic Engineering, Tsinghua University, gave a speech titled "AI-driven modeling and pattern discovery of urban complex systems" and gave an in-depth explanation of the spatiotemporal generative modeling method for urban complex systems and the team's latest research progress. It's full of useful information, click to read.
View the full report:https://go.hyper.ai/qaDYE
On November 13, Huang Renxun and Son Masayoshi had an offline conversation in Japan, reviewing the latter's past investment in Nvidia and discussing the development of AI in Japan. Huang Renxun bluntly said that Son Masayoshi is "the only entrepreneur and innovator in the world who has chosen winners and worked with winners in every generation of technological change." This article sorts out the past disputes between the two and the current development direction. Click to read for details.
View the full report:https://go.hyper.ai/hLKbG
Popular Encyclopedia Articles
1. UNA Alignment Framework
2. Digital Cousin
3. Model Collapse
4. Gradient Boosting
5. Frequency Principle
Here are hundreds of AI-related terms compiled to help you understand "artificial intelligence" here:
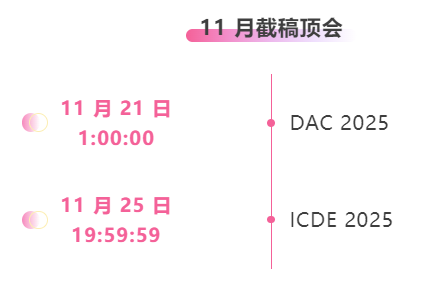
One-stop tracking of top AI academic conferences:https://go.hyper.ai/event
The above is all the content of this week’s editor’s selection. If you have resources that you want to include on the hyper.ai official website, you are also welcome to leave a message or submit an article to tell us!
See you next week!
About HyperAI
HyperAI (hyper.ai) is the leading artificial intelligence and high-performance computing community in China.We are committed to becoming the infrastructure in the field of data science in China and providing rich and high-quality public resources for domestic developers. So far, we have:
* Provide domestic accelerated download nodes for 1300+ public data sets
* Includes 400+ classic and popular online tutorials
* Interpretation of 100+ AI4Science paper cases
* Support 500+ related terms search
* Hosting the first complete Apache TVM Chinese documentation in China
Visit the official website to start your learning journey:
Finally, I recommend a "Creator Incentive Program". Interested friends can scan the QR code to participate!









