Die Version ltxv-13b-0.9.7-distilled von LTX-Video ist das neueste Destillationsmodell, das von Lightricks am 14. Mai 2025 veröffentlicht wurde. Dieses Modell nutzt Transformer- und Video-VAE-Technologie zur effizienten Generierung hochauflösender Videos. Auf einer Nvidia H100 GPU erzeugte es ein 5 Sekunden langes Video mit 24 Bildern pro Sekunde und einer Auflösung von 768 × 512 Pixeln in nur 2 Sekunden und übertraf damit alle bisherigen Modelle vergleichbarer Größenordnung. Darüber hinaus unterstützt LTX-Video verschiedene Videogenerierungsmethoden, darunter Text-zu-Video, Bild-zu-Video, erweiterte Videos und Videogenerierung unter verschiedenen Bedingungen. Die zugehörigen Forschungsergebnisse sind… LTX-Video: Echtzeit-Video-Latentdiffusion .
Dieses Tutorial verwendet eine einzelne A6000-Rechenressource und bietet zum Testen zwei Beispiele für die Text-zu-Video- und Bild-zu-Video-Generierung.
2. Effektanzeige
Text zu Video:
Bild zu Video:
3. Bedienungsschritte
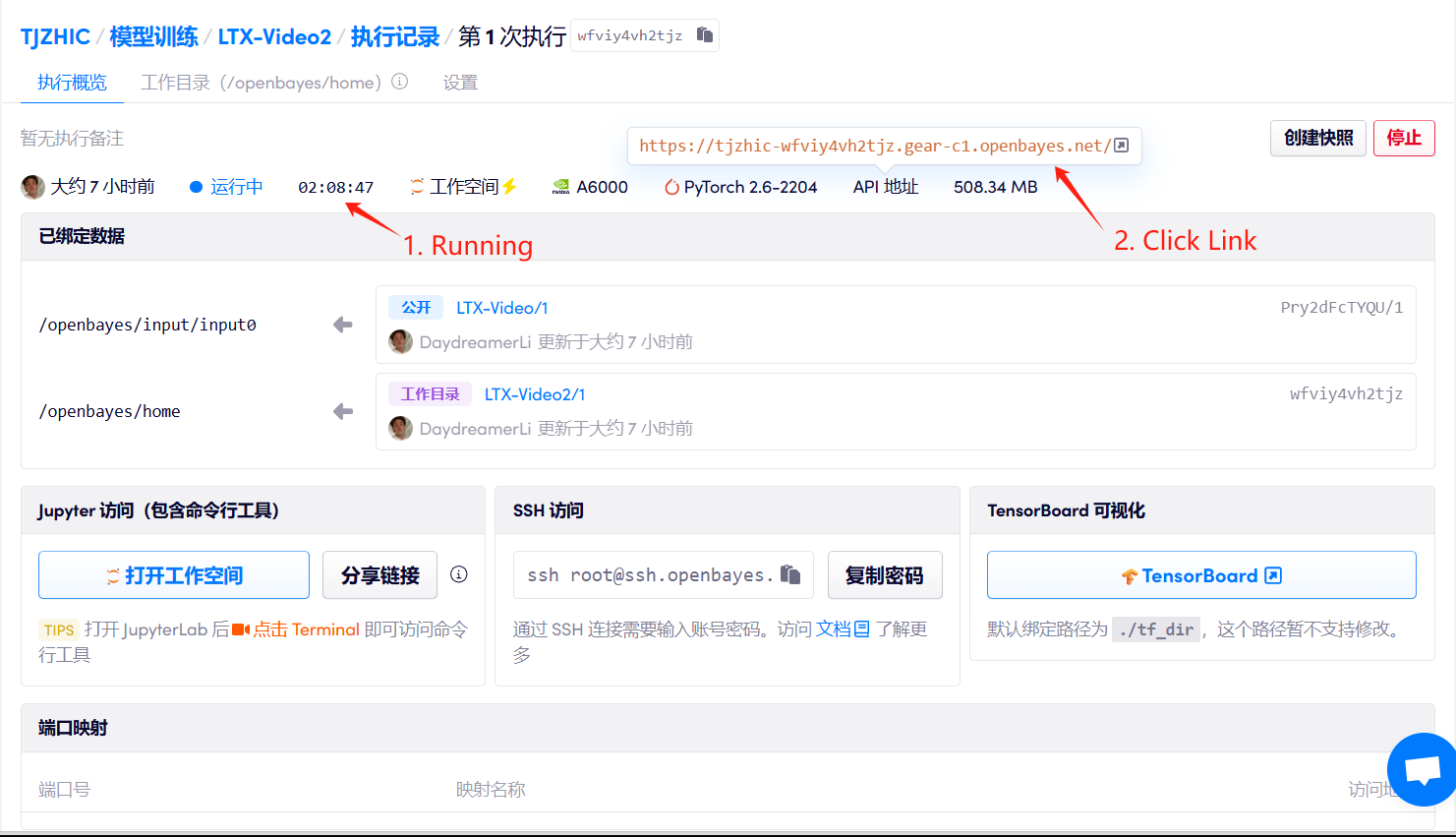
1. Starten Sie den Container
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
2. Anwendungsbeispiele
Prompt unterstützt nur Englisch.
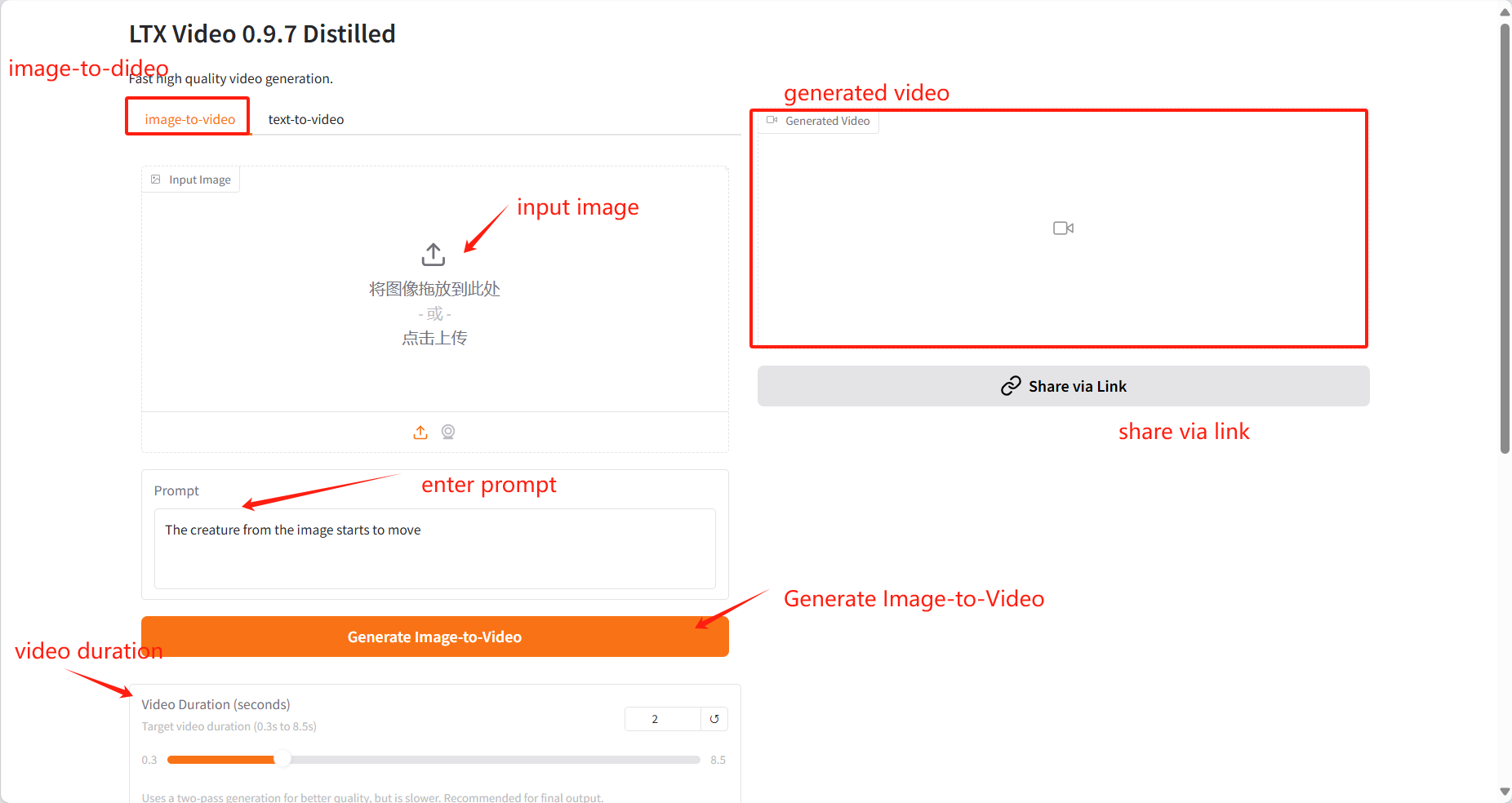
1. Bild-zu-Video
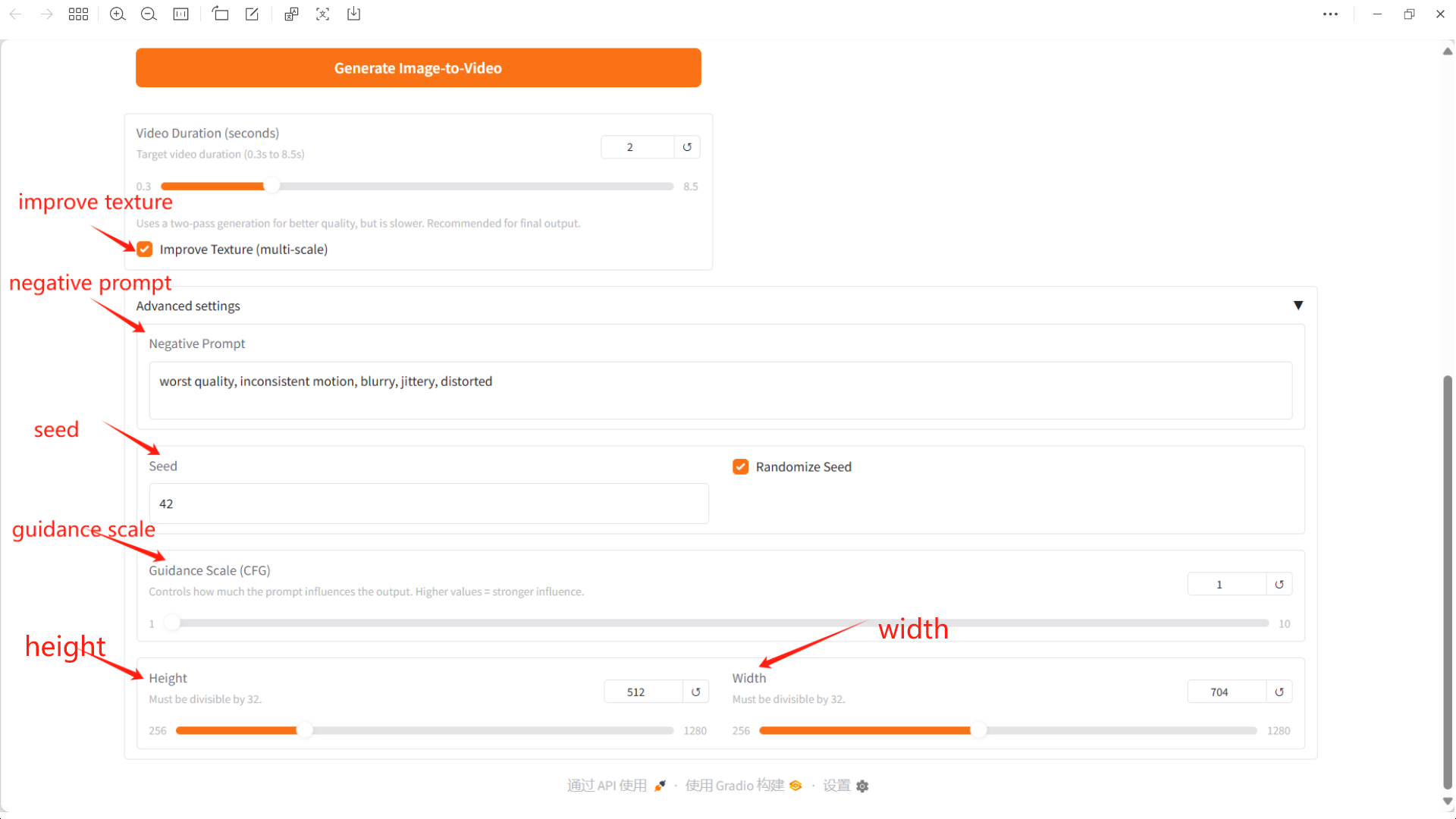
Spezifische Parameter:
Bild hochladen: Hier können Sie ein Bild als Ausgangspunkt für die Videoerstellung hochladen.
Eingabeaufforderung: Sie können hier Text zur Beschreibung des Videoinhalts eingeben und das Modell generiert basierend auf diesem Text ein Video.
Videodauer: Wählen Sie die Länge des generierten Videos.
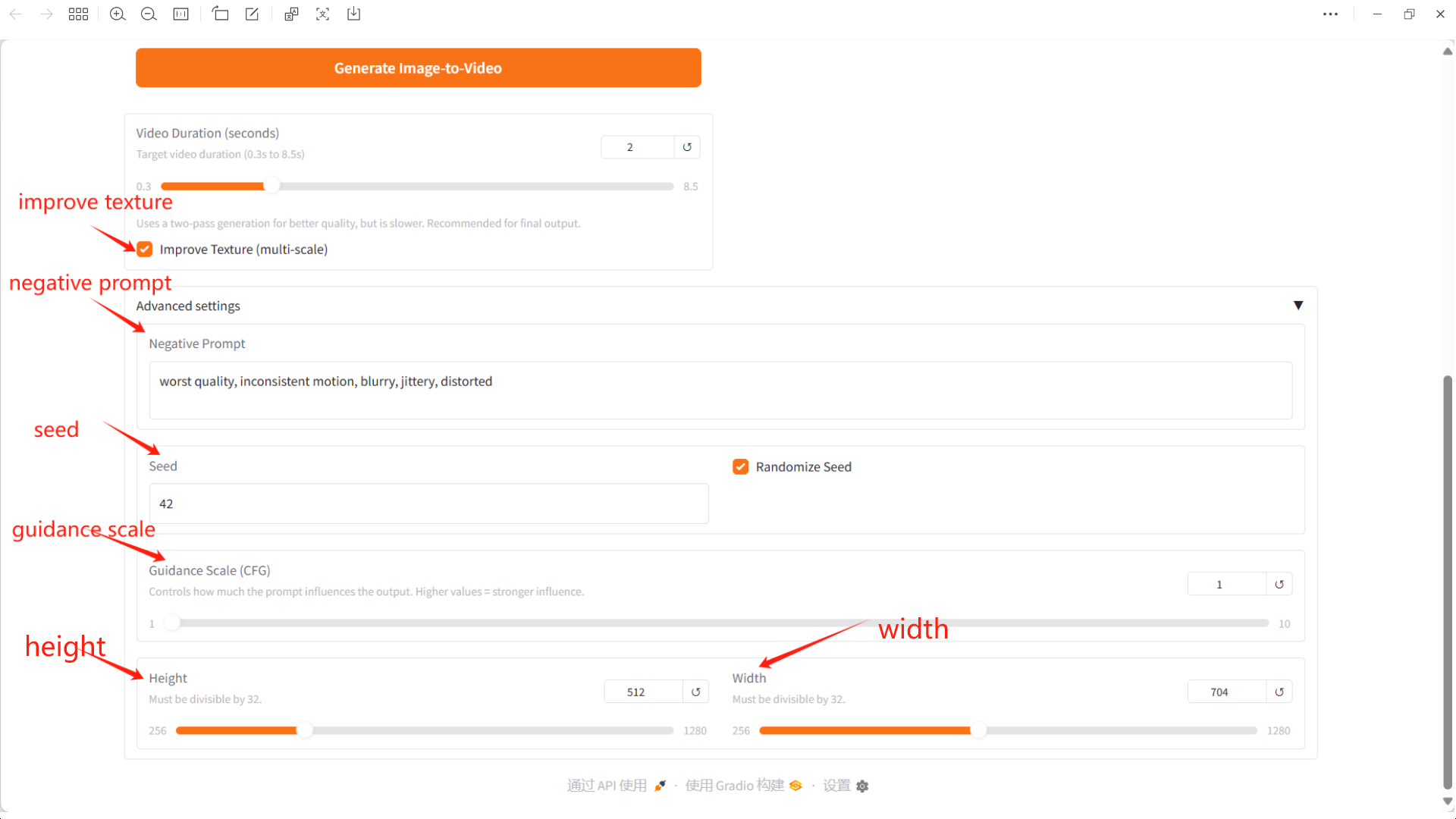
Negative Eingabeaufforderung: Hier können Sie Elemente oder Funktionen eingeben, die nicht im Video erscheinen sollen. So vermeiden Sie unerwünschte Effekte.
Seed: Diese Zahl bestimmt die Zufälligkeit der Videogenerierung.
Guidance Scale (CFG): Steuert, wie viel Einfluss die Eingabeaufforderungen auf die Ausgabe haben. Höhere Werte haben eine größere Wirkung.
Höhe: Höhe, muss durch 32 teilbar sein.
Breite: Breite, muss durch 32 teilbar sein.
Ergebnis
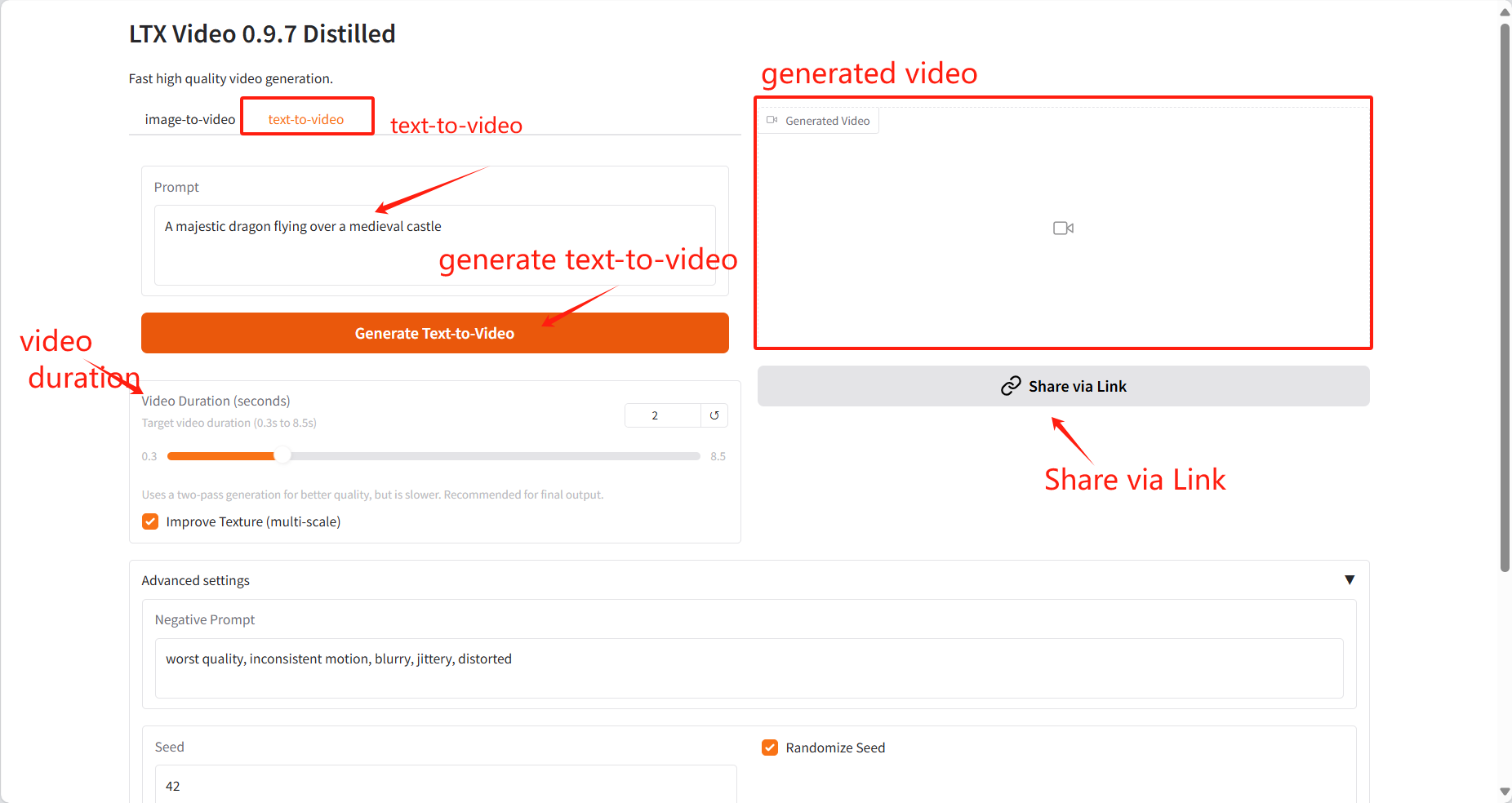
2. Text-zu-Video
Spezifische Parameter:
Eingabeaufforderung: Sie können hier Text zur Beschreibung des Videoinhalts eingeben und das Modell generiert basierend auf diesem Text ein Video.
Videodauer: Wählen Sie die Länge des generierten Videos.
Negative Eingabeaufforderung: Hier können Sie Elemente oder Funktionen eingeben, die nicht im Video erscheinen sollen. So vermeiden Sie unerwünschte Effekte.
Seed: Diese Zahl bestimmt die Zufälligkeit der Videogenerierung.
Guidance Scale (CFG): Steuert, wie viel Einfluss die Eingabeaufforderungen auf die Ausgabe haben. Höhere Werte haben eine größere Wirkung.
Höhe: Höhe, muss durch 32 teilbar sein.
Breite: Breite, muss durch 32 teilbar sein.
Ergebnisausgabe
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{HaCohen2024LTXVideo,
title={LTX-Video: Realtime Video Latent Diffusion},
author={HaCohen, Yoav and Chiprut, Nisan and Brazowski, Benny and Shalem, Daniel and Moshe, Dudu and Richardson, Eitan and Levin, Eran and Shiran, Guy and Zabari, Nir and Gordon, Ori and Panet, Poriya and Weissbuch, Sapir and Kulikov, Victor and Bitterman, Yaki and Melumian, Zeev and Bibi, Ofir},
journal={arXiv preprint arXiv:2501.00103},
year={2024}
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.
Die Version ltxv-13b-0.9.7-distilled von LTX-Video ist das neueste Destillationsmodell, das von Lightricks am 14. Mai 2025 veröffentlicht wurde. Dieses Modell nutzt Transformer- und Video-VAE-Technologie zur effizienten Generierung hochauflösender Videos. Auf einer Nvidia H100 GPU erzeugte es ein 5 Sekunden langes Video mit 24 Bildern pro Sekunde und einer Auflösung von 768 × 512 Pixeln in nur 2 Sekunden und übertraf damit alle bisherigen Modelle vergleichbarer Größenordnung. Darüber hinaus unterstützt LTX-Video verschiedene Videogenerierungsmethoden, darunter Text-zu-Video, Bild-zu-Video, erweiterte Videos und Videogenerierung unter verschiedenen Bedingungen. Die zugehörigen Forschungsergebnisse sind… LTX-Video: Echtzeit-Video-Latentdiffusion .
Dieses Tutorial verwendet eine einzelne A6000-Rechenressource und bietet zum Testen zwei Beispiele für die Text-zu-Video- und Bild-zu-Video-Generierung.
2. Effektanzeige
Text zu Video:
Bild zu Video:
3. Bedienungsschritte
1. Starten Sie den Container
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
2. Anwendungsbeispiele
Prompt unterstützt nur Englisch.
1. Bild-zu-Video
Spezifische Parameter:
Bild hochladen: Hier können Sie ein Bild als Ausgangspunkt für die Videoerstellung hochladen.
Eingabeaufforderung: Sie können hier Text zur Beschreibung des Videoinhalts eingeben und das Modell generiert basierend auf diesem Text ein Video.
Videodauer: Wählen Sie die Länge des generierten Videos.
Negative Eingabeaufforderung: Hier können Sie Elemente oder Funktionen eingeben, die nicht im Video erscheinen sollen. So vermeiden Sie unerwünschte Effekte.
Seed: Diese Zahl bestimmt die Zufälligkeit der Videogenerierung.
Guidance Scale (CFG): Steuert, wie viel Einfluss die Eingabeaufforderungen auf die Ausgabe haben. Höhere Werte haben eine größere Wirkung.
Höhe: Höhe, muss durch 32 teilbar sein.
Breite: Breite, muss durch 32 teilbar sein.
Ergebnis
2. Text-zu-Video
Spezifische Parameter:
Eingabeaufforderung: Sie können hier Text zur Beschreibung des Videoinhalts eingeben und das Modell generiert basierend auf diesem Text ein Video.
Videodauer: Wählen Sie die Länge des generierten Videos.
Negative Eingabeaufforderung: Hier können Sie Elemente oder Funktionen eingeben, die nicht im Video erscheinen sollen. So vermeiden Sie unerwünschte Effekte.
Seed: Diese Zahl bestimmt die Zufälligkeit der Videogenerierung.
Guidance Scale (CFG): Steuert, wie viel Einfluss die Eingabeaufforderungen auf die Ausgabe haben. Höhere Werte haben eine größere Wirkung.
Höhe: Höhe, muss durch 32 teilbar sein.
Breite: Breite, muss durch 32 teilbar sein.
Ergebnisausgabe
4. Diskussion
🖌️ Wenn Sie ein hochwertiges Projekt sehen, hinterlassen Sie bitte im Hintergrund eine Nachricht, um es weiterzuempfehlen! Darüber hinaus haben wir auch eine Tutorien-Austauschgruppe ins Leben gerufen. Willkommen, Freunde, scannen Sie den QR-Code und kommentieren Sie [SD-Tutorial], um der Gruppe beizutreten, verschiedene technische Probleme zu besprechen und Anwendungsergebnisse auszutauschen ↓
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{HaCohen2024LTXVideo,
title={LTX-Video: Realtime Video Latent Diffusion},
author={HaCohen, Yoav and Chiprut, Nisan and Brazowski, Benny and Shalem, Daniel and Moshe, Dudu and Richardson, Eitan and Levin, Eran and Shiran, Guy and Zabari, Nir and Gordon, Ori and Panet, Poriya and Weissbuch, Sapir and Kulikov, Victor and Bitterman, Yaki and Melumian, Zeev and Bibi, Ofir},
journal={arXiv preprint arXiv:2501.00103},
year={2024}
}
Dieses Notebook wurde von Community-Nutzern beigesteuert und dient ausschließlich Bildungs- und Informationszwecken. Bei urheberrechtlichen Bedenken kontaktieren Sie uns bitte unter [email protected] zur umgehenden Prüfung und Entfernung.
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.