Command Palette
Search for a command to run...
VibeVoice-Realtime TTS: Echtzeit-Sprachsynthesedienst
1. Einführung in das Tutorial

VibeVoice-Realtime TTS ist ein hochwertiges Echtzeit-Text-to-Speech-System (TTS), das auf dem Streaming-Sprachsynthesemodell VibeVoice-Realtime-0.5B basiert, welches vom Microsoft Research Team im Dezember 2025 veröffentlicht wurde. Das System verwendet eine neuartige Next-Token-Diffusionsmethode zur Modellierung kontinuierlicher Daten in der langen Sprachsynthese mit mehreren Sprechern und führt einen effizienten Segmentierer für kontinuierliche Sprache ein. Dadurch kann das Modell bis zu 90 Minuten Sprache innerhalb eines 64-KB-Kontextfensters generieren und bis zu vier Sprecher unterstützen. Es verbessert die Recheneffizienz deutlich, während gleichzeitig die Audioqualität erhalten bleibt und die Atmosphäre realistischer Gespräche eingefangen wird. Zugehörige Forschungsarbeiten sind verfügbar. VibeVoice: Hochwertige Text-zu-Sprache-Streaming-Funktion für mehrere Sprecher Das System unterstützt die Sprachgenerierung mit mehreren Sprechern, Echtzeit-Inferenz mit geringer Latenz und visuelle Interaktion über die Grado-Weboberfläche.
Kernfunktionen:
- Echtzeit-Sprachsynthese mit mehreren Sprechern
- Streaming-Inferenz, Ausgabe mit geringer Latenz
- Hochpräzise Sprachabtastrate von 24000 Hz
- Unterstützt skalierbare, steuerbare Erzeugung nach CFG-Standard
- GPU-beschleunigte Inferenz
- Vollständige lokale Offline-Bereitstellung, ohne auf ein externes Netzwerk angewiesen zu sein.
Dieses Tutorial verwendet Grado, um das VibeVoice-Realtime-0.5B-Kernmodell mithilfe einer „RTX_5090“-Rechenressource bereitzustellen, die den stabilen Betrieb von Echtzeit-Sprachsynthesediensten ermöglicht. Dieses Modell unterstützt ausschließlich englische Texteingabe.
2. Effektanzeige
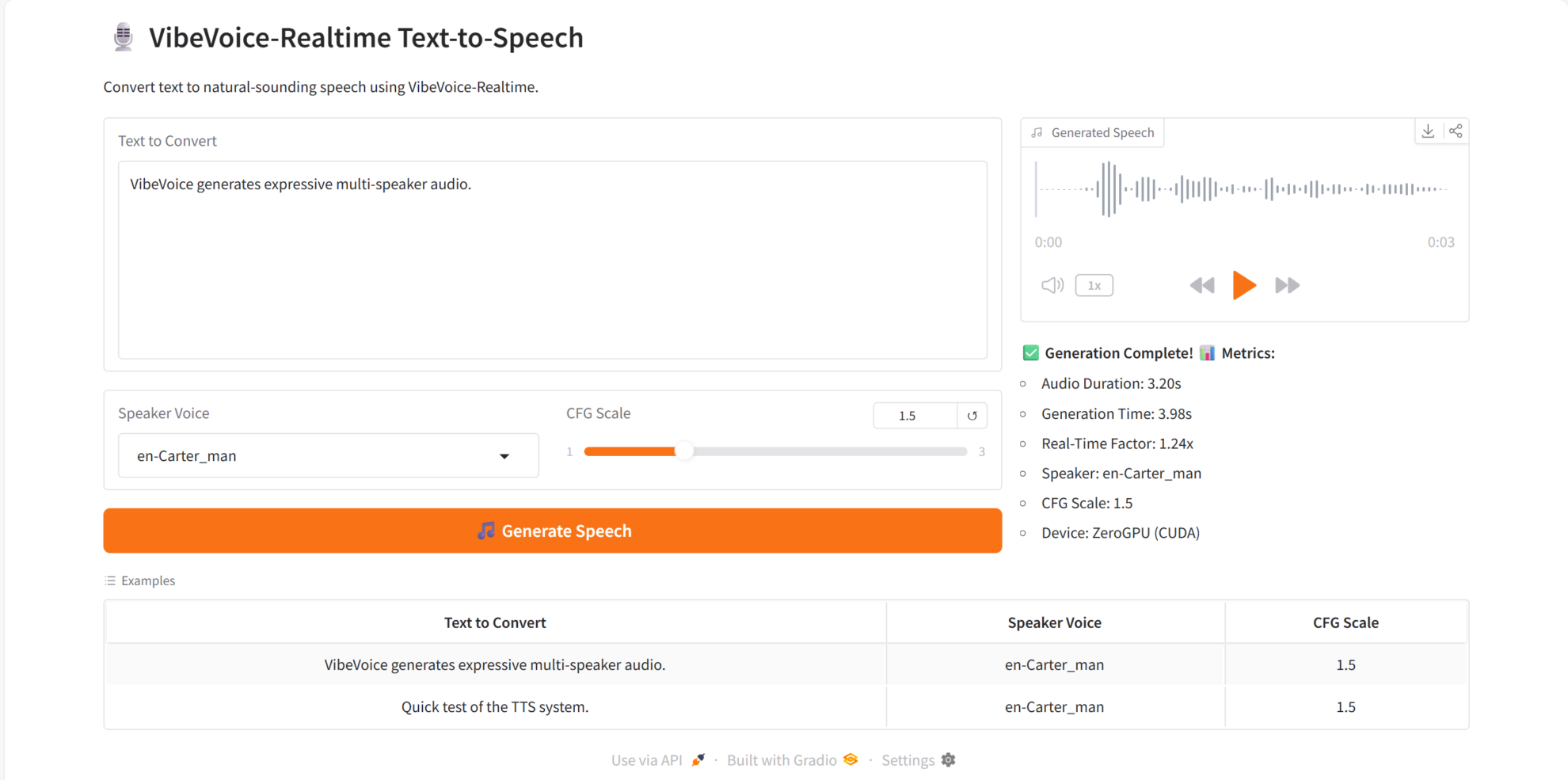
VibeVoice-Realtime zeichnet sich durch seine Kernkompetenzen aus:
- Echtzeit-TTS: Erzeugt nach der Texteingabe schnell eine Sprachausgabe.
- Unterstützung mehrerer Sprecher: Für denselben Text können verschiedene Sprachstile ausgewählt werden.
- Sehr natürliche Sprachqualität: klarer Klang und natürliche Intonation.
- Stabile Synthese langer Texte: Keine offensichtlichen Interpunktions- oder Verzerrungsprobleme.
- Es verfügt über starke Echtzeit-Interaktionsfunktionen und eignet sich für Szenarien wie Dialogsysteme und Sprachassistenten.
3. Bedienungsschritte
1. Starten Sie den Container
Klicken Sie nach dem Starten des Containers auf die API-Adresse, um zur Weboberfläche zu gelangen
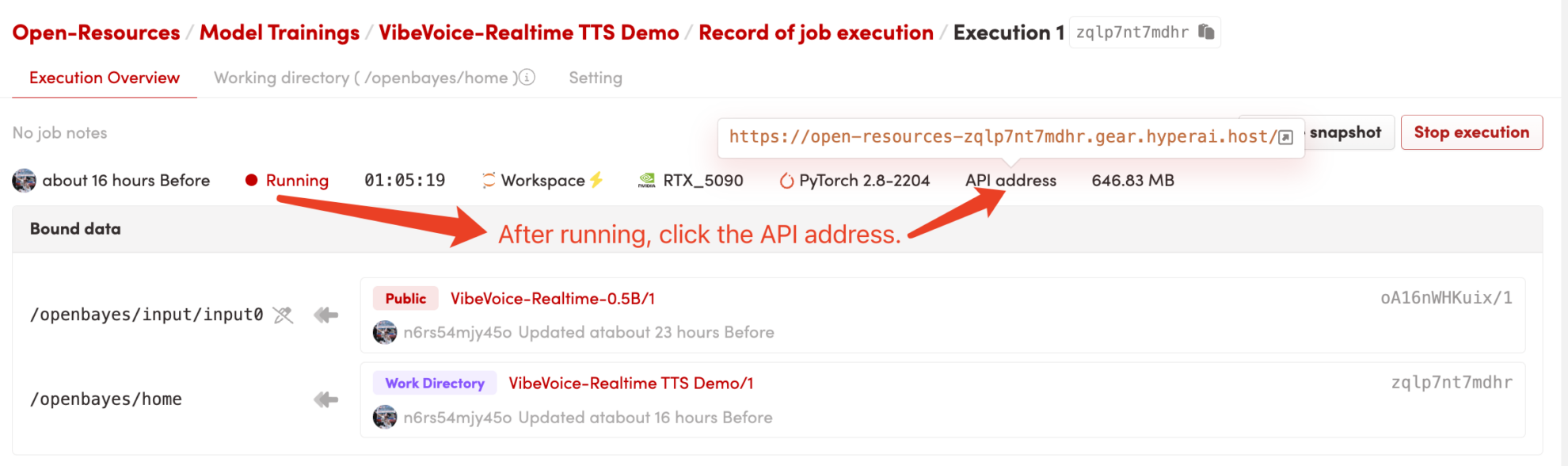
2. Erste Schritte
Wird „Bad Gateway“ angezeigt, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte 1–2 Minuten und aktualisieren Sie dann die Seite.
Bei Verwendung des Safari-Browsers wird der Ton möglicherweise nicht direkt abgespielt und muss vor der Wiedergabe heruntergeladen werden.
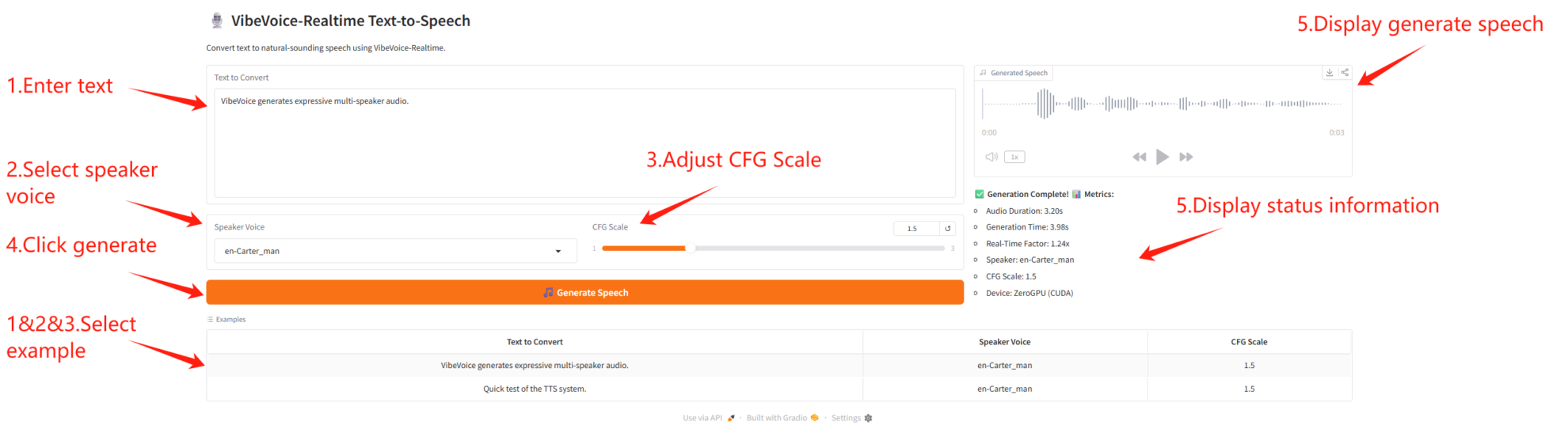
Parameterbeschreibung
- Sprachgenerierungsparameter
- CFG-Skala: Steuert die Intensität des Sprachstils; je höher der Wert, desto stärker die Emotion.
- Lautsprecherparameter
- Sprecherstimme: Wählen Sie verschiedene Sprecherstimmen.

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{vibevoice2024,
title={VibeVoice: Real-Time Streaming Text-to-Speech with Multi-Speaker Support},
author={Zhiliang Peng and Jianwei Yu and Wenhui Wang and Yaoyao Chang and Yutao Sun and Li Dong and Yi Zhu and Weijiang Xu and Hangbo Bao and Zehua Wang and Shaohan Huang and Yan Xia and Furu Wei},
journal={arXiv preprint arXiv:2412.08635},
year={2024}
}
@article{vibevoice2025,
title={VibeVoice: High-Fidelity Multi-Speaker Streaming Text-to-Speech},
author={Zhiliang Peng and Jianwei Yu and Wenhui Wang and Yaoyao Chang and Yutao Sun and Li Dong and Yi Zhu and Weijiang Xu and Hangbo Bao and Zehua Wang and Shaohan Huang and Yan Xia and Furu Wei},
journal={arXiv preprint arXiv:2508.19205},
year={2025}
}Notebook-Übersicht
Stufe
Thema
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.