Command Palette
Search for a command to run...
Depth-Anything-3: Wiederherstellung Des Visuellen Raums Aus Jeder Perspektive
Datum
Organisation
Paper-URL
Lizenz
Apache 2.0
1. Einführung in das Tutorial

Depth-Anything-3 (DA3) ist ein bahnbrechendes visuelles Geometriemodell, das vom ByteDance-Seed-Team im November 2025 veröffentlicht wurde. Die zugehörige Veröffentlichung lautet wie folgt: Depth Anything 3: Die Wiederherstellung des visuellen Raums aus beliebigen Ansichten .
Dieses Modell revolutioniert Aufgaben der visuellen Geometrie durch sein minimalistisches Modellierungskonzept: Es verwendet lediglich einen einzigen, herkömmlichen Transformer (wie den DINO-Encoder) als Basisnetzwerk und ersetzt komplexes Multitasking-Lernen durch Tiefenstrahldarstellung. Dadurch kann es räumlich konsistente geometrische Strukturen aus beliebigen visuellen Eingaben (bekannte und unbekannte Kamerapositionen) vorhersagen. Seine Leistung übertrifft deutlich frühere Modelle wie DA2 (monokulare Tiefenschätzung) und ähnliche Lösungen wie VGGT (Mehransicht-Tiefen-/Positionsschätzung). Alle Modelle wurden mit öffentlich verfügbaren akademischen Datensätzen trainiert, wobei Genauigkeit und Reproduzierbarkeit optimal aufeinander abgestimmt wurden.
Kernfunktionen:
- Integration mehrerer Aufgaben: Ein einziges Modell unterstützt Aufgaben wie die monokulare Tiefenschätzung, die Tiefenfusion aus mehreren Ansichten, die Schätzung der Kameraposition und die 3D-Gauß-Generierung.
- Hochpräzise Ausgabe: Erreichte eine monokulare Tiefengenauigkeit von 94,6% auf dem HiRoom-Datensatz; die Genauigkeit der ETH3D-Rekonstruktion übertrifft Modelle wie VGGT.
- Anpassung an verschiedene Modelle: Bietet Modelle der Serien Main (Allrounder), Metric (Tiefenmessung), Monocular (nur monokular) und Nested (verschachtelte Fusion).
- Flexibler Export: Unterstützt Formate wie GLB, NPZ, PLY und 3DGS-Video und lässt sich nahtlos in nachgelagerte 3D-Tools (wie Blender) integrieren.
In diesem Tutorial wird Grado verwendet, um das DA3-Kernmodell mit "RTX_5090"-Rechenressourcen bereitzustellen, die rechenintensive Aufgaben wie die 3D-Gauß-Generierung (hohe Auflösung) und die 3D-Rekonstruktion aus mehreren Ansichten ohne Engpässe im Videospeicher/Speicher ausführen können.
2. Effektanzeige
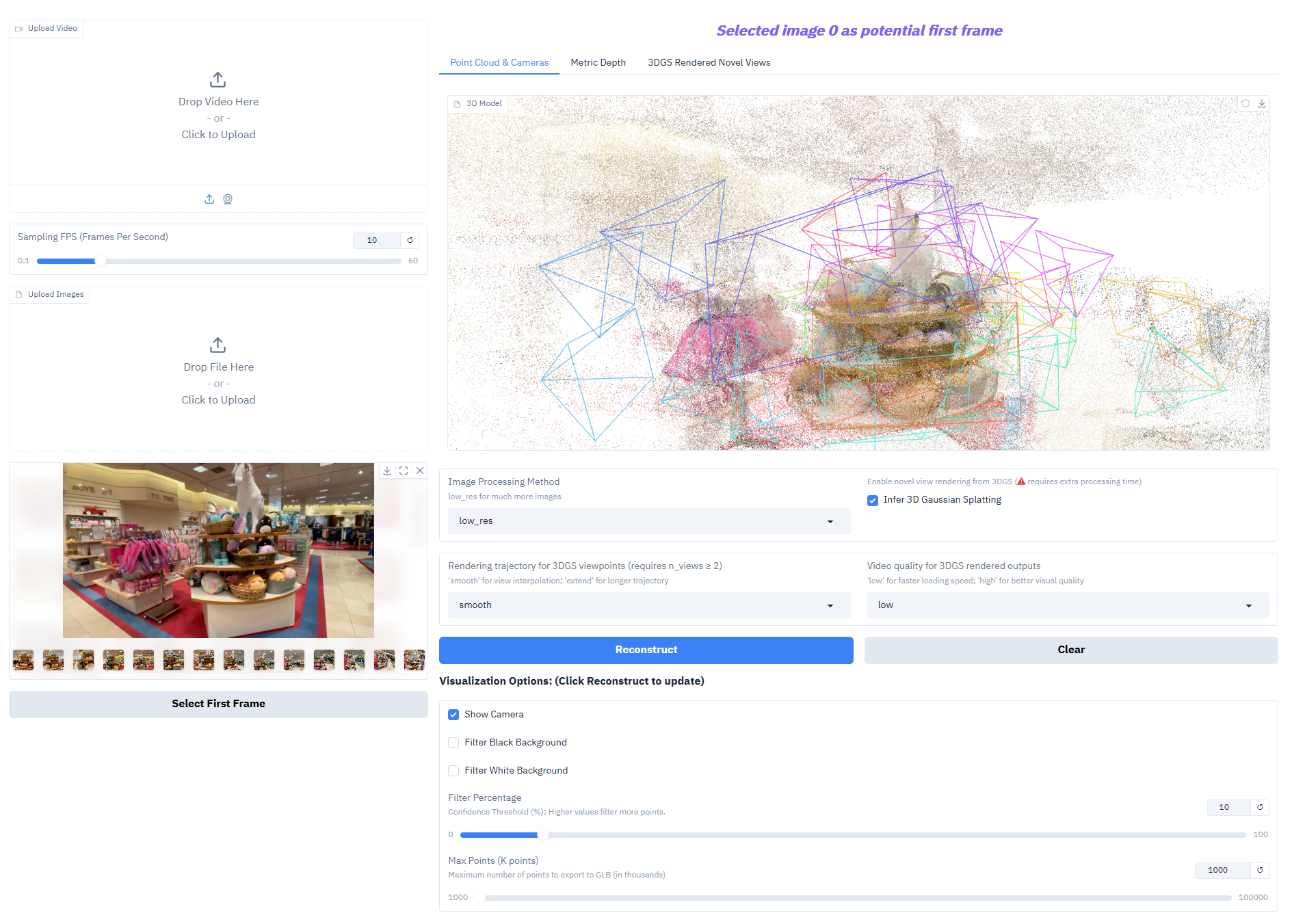
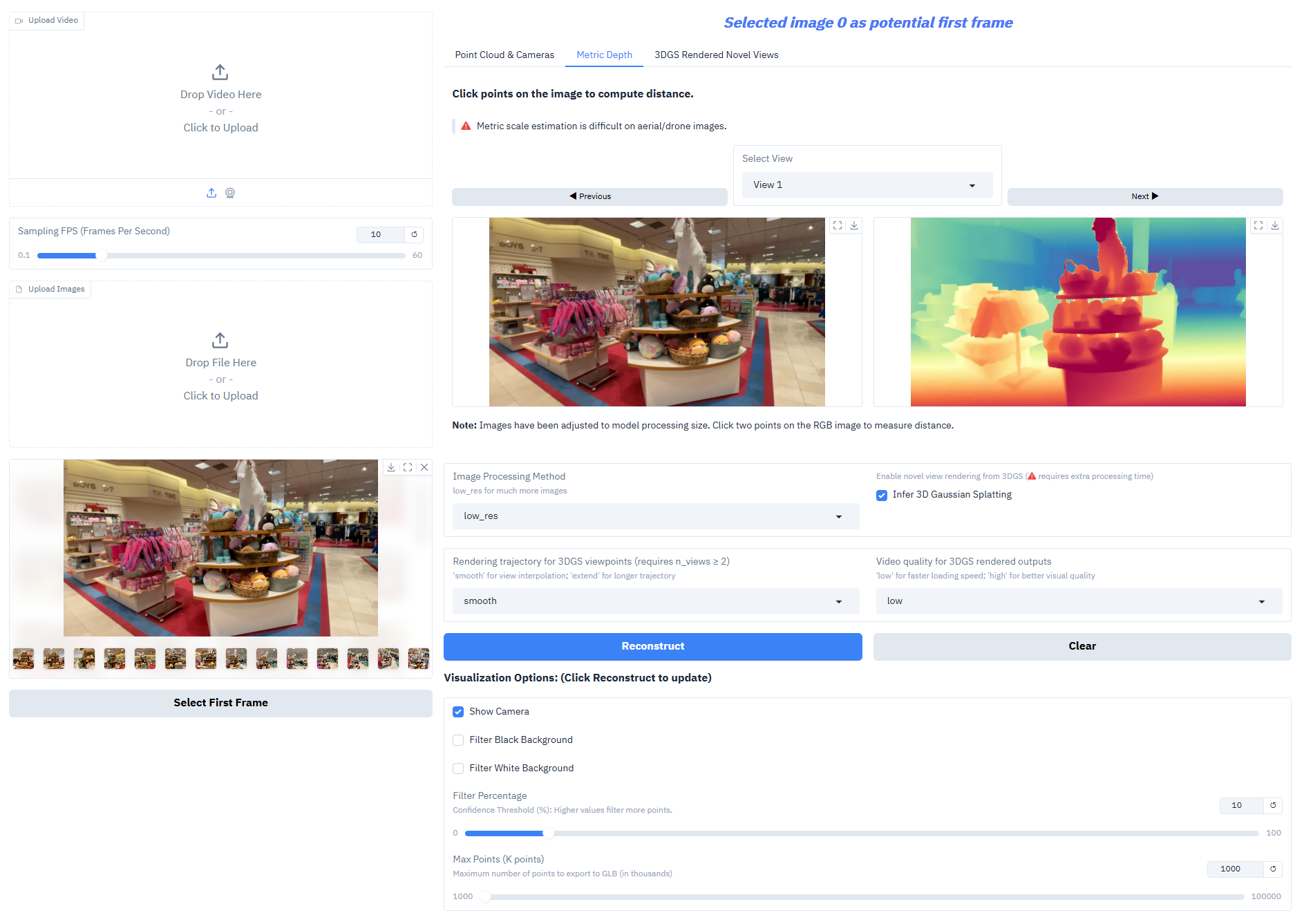
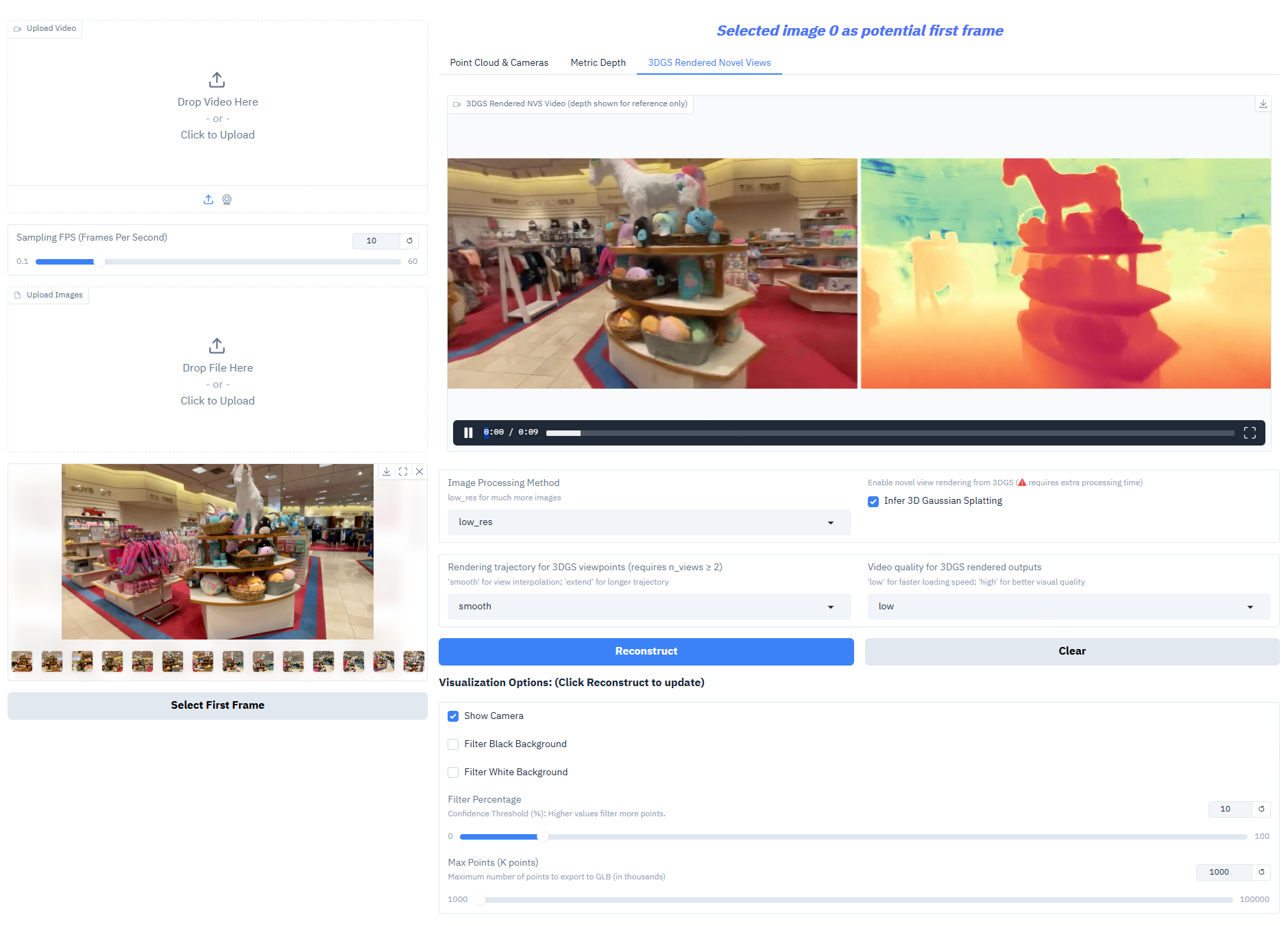
Depth-Anything-3 schneidet bei Kernaufgaben außergewöhnlich gut ab:
- Monokulare Tiefenschätzung: Erzeugung hochpräziser Tiefenkarten aus einem einzelnen RGB-Bild zur Rekonstruktion der räumlichen Hierarchie einer Szene.
- Multi-View-Tiefenfusion: Erzeugt ein konsistentes Tiefenfeld auf Basis mehrerer Bilder derselben Szene und unterstützt so eine hochwertige 3D-Rekonstruktion.
- Schätzung der Kameraposition: Genaue Vorhersage der intrinsischen und extrinsischen Kameraparameter (extrinsische Parameter [N,3,4], intrinsische Parameter [N,3,3]), angepasst an kollaborative Aufgaben mit mehreren Ansichten.
- 3D-Gauß-Generierung: Gibt direkt hochpräzise 3D-Gauß-Modelle aus und unterstützt neuartige Ansichtskompositionen (Bildrate ≥ 30 fps).
- Ausgabe der Messtiefe: Verschachtelte Serienmodelle können Tiefen im realistischen Maßstab erzeugen und so den Anforderungen von Vermessungsarbeiten, Innenarchitektur und anderen Anwendungsbereichen gerecht werden.
3. Bedienungsschritte
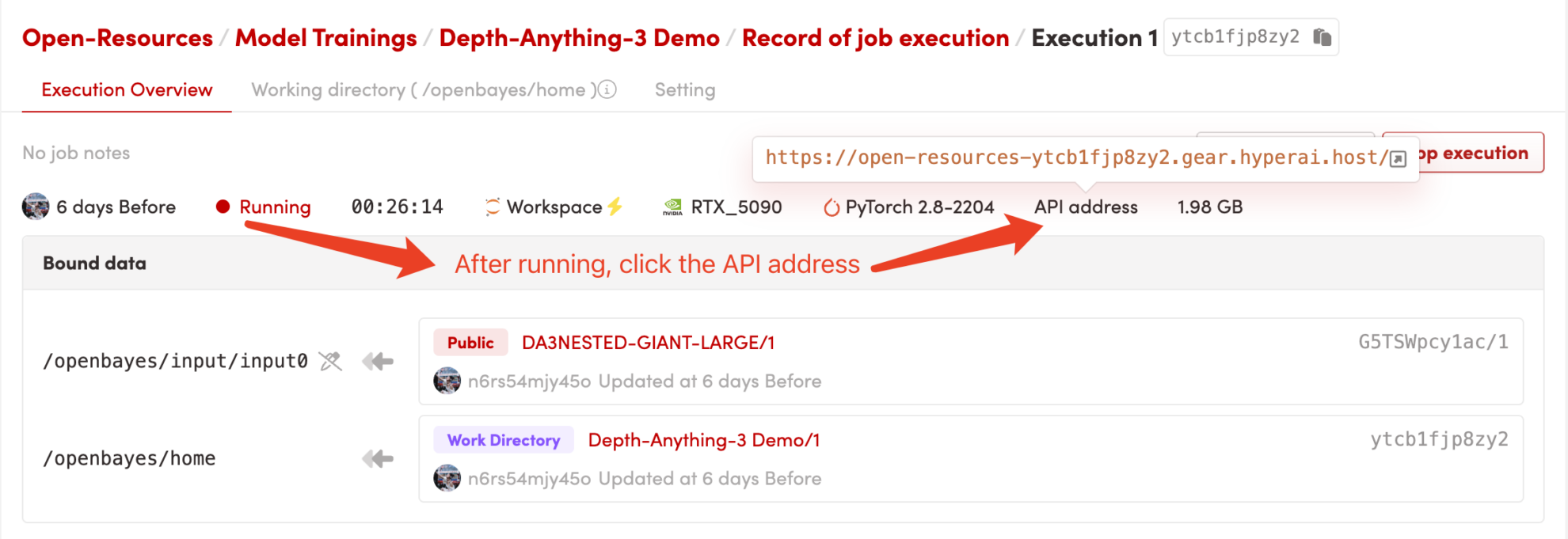
1. Starten Sie den Container
Klicken Sie nach dem Starten des Containers auf die API-Adresse, um zur Weboberfläche zu gelangen
2. Erste Schritte
Wird „Bad Gateway“ angezeigt, bedeutet dies, dass das Modell initialisiert wird. Da das Modell umfangreich ist, warten Sie bitte 2–3 Minuten und aktualisieren Sie die Seite.
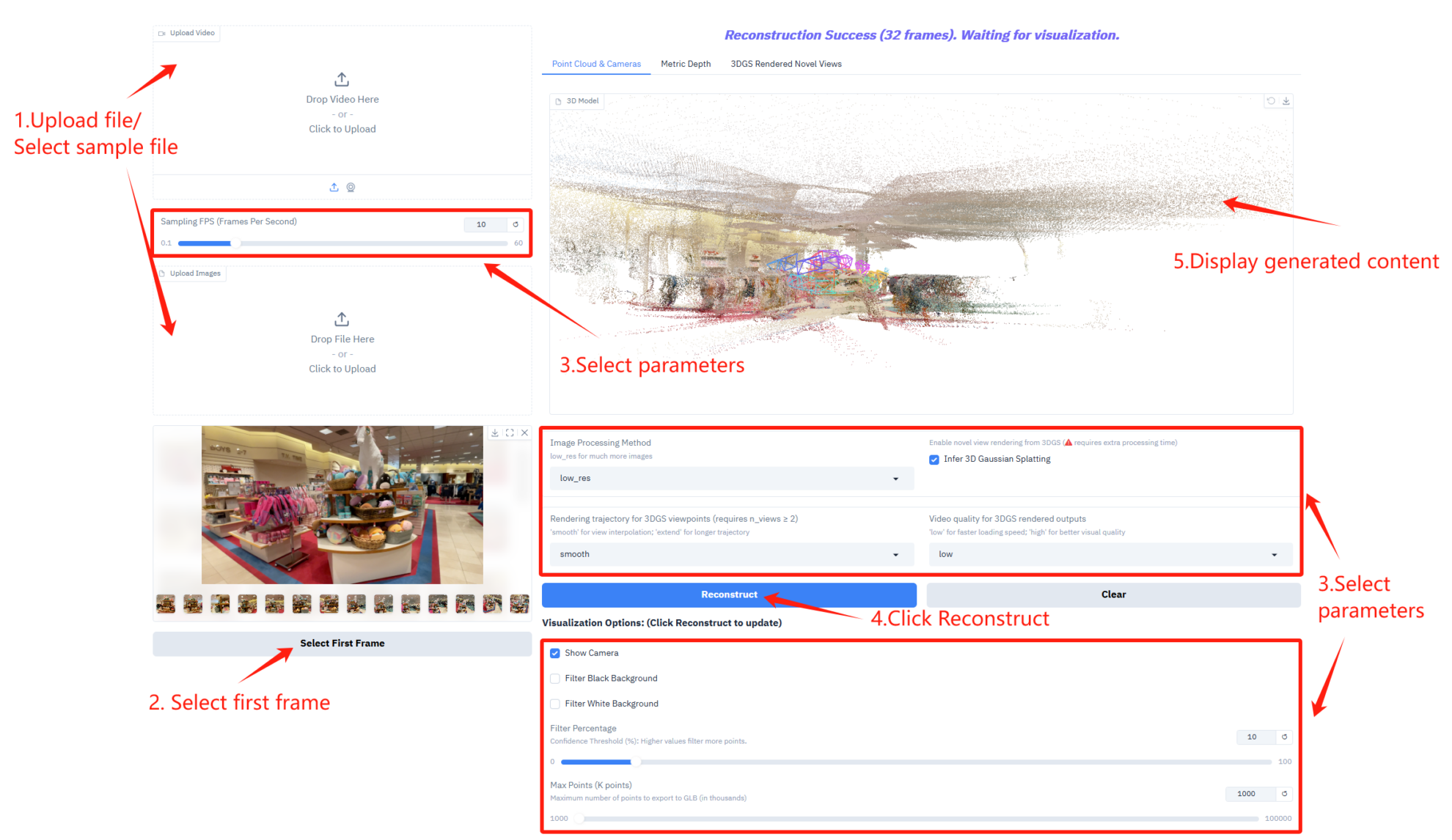
Parameterbeschreibung
- Einstellungen für die Abtastrate
- Abtastrate (Frames Per Second): Steuert die Anzahl der Bilder pro Sekunde, die für die Videoabtastung verwendet werden.
- Einrichtung für Bildverarbeitung und 3D-Inferenz
- Bildverarbeitungsmethode: Wählen Sie den Bildverarbeitungsmodus, der eine größere Anzahl von Bildern verarbeiten kann.
- Inferenz von 3D-Gaussian-Splatting: Die Aktivierung der 3D-Gaussian-Sputtering-Inferenz erfordert zusätzliche Verarbeitungszeit zur Generierung von 3D-Modellen.
- Einstellungen für Rendering-Trajektorie und Videoqualität
- Rendering-Trajektorie für 3DGS-Ansichten: Wählen Sie den Typ der Rendering-Trajektorie für die 3DGS-Ansicht.
- Videoqualität für 3DGS-gerenderte Ausgaben: Steuert die Videoqualität der 3DGS-gerenderten Ausgaben.
- Visualisierungsoptionen
- Kamera anzeigen: Zeigt die Kamerabewegung in einer 3D-Ansicht an.
- Schwarzer Hintergrundfilter: Filtert den schwarzen Hintergrundbereich in der Punktwolke heraus.
- Filter Weißer Hintergrund: Filtert weiße Hintergrundbereiche in der Punktwolke heraus.
- Filterprozentsatz: Steuert die Filterintensität der Punktwolke.
- Max. Punkte (K Punkte): Legt die maximale Anzahl von Punkten für den Export eines 3D-Modells im GLB-Format fest.
Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@article{depthanything3,
title={Depth Anything 3: Recovering the visual space from any views},
author={Haotong Lin and Sili Chen and Jun Hao Liew and Donny Y. Chen and Zhenyu Li and Guang Shi and Jiashi Feng and Bingyi Kang},
journal={arXiv preprint arXiv:2511.10647},
year={2025}
}Notebook-Übersicht
Stufe
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.