Command Palette
Search for a command to run...
SAM3: Visuelles Segmentierungsmodell
Datum
Paper-URL
Lizenz
其他
GitHub
1. Einführung in das Tutorial

SAM3 ist ein fortschrittliches Computer-Vision-Modell, das von Meta AI im November 2025 veröffentlicht wurde. Es kann Objekte in Bildern und Videos mithilfe von Text, Beispielen und visuellen Hinweisen erkennen, segmentieren und verfolgen. SAM3 unterstützt die Eingabe von Phrasen mit offenem Vokabular, verfügt über leistungsstarke multimodale Interaktionsfunktionen und kann Segmentierungsergebnisse in Echtzeit korrigieren. SAM3 erzielt überragende Ergebnisse bei der Bild- und Videosegmentierung, übertrifft bestehende Systeme um das Doppelte und unterstützt Zero-Shot-Learning. Das Modell lässt sich auf die 3D-Rekonstruktion erweitern und unterstützt Anwendungen in verschiedenen Bereichen wie Hausvorschau, kreative Videobearbeitung und wissenschaftliche Forschung. Es setzt damit einen wichtigen Impuls für die zukünftige Entwicklung der Computer Vision. Zugehörige Forschungsarbeiten sind verfügbar. SAM 3: Segmentieren Sie alles mit Konzepten .
Dieses Tutorial verwendet standardmäßig eine einzelne RTX 5090-Grafikkarte, kann aber auch mit mindestens einer einzelnen RTX 4090 gestartet werden. Drei Beispiele stehen zum Testen zur Verfügung: Bildsegmentierung, Videotext-Eingabeaufforderung und Videopunkt-/Feld-Eingabeaufforderung. Das Modell unterstützt nur englische Eingaben.
2. Effektanzeige


3. Bedienungsschritte
1. Starten Sie den Container
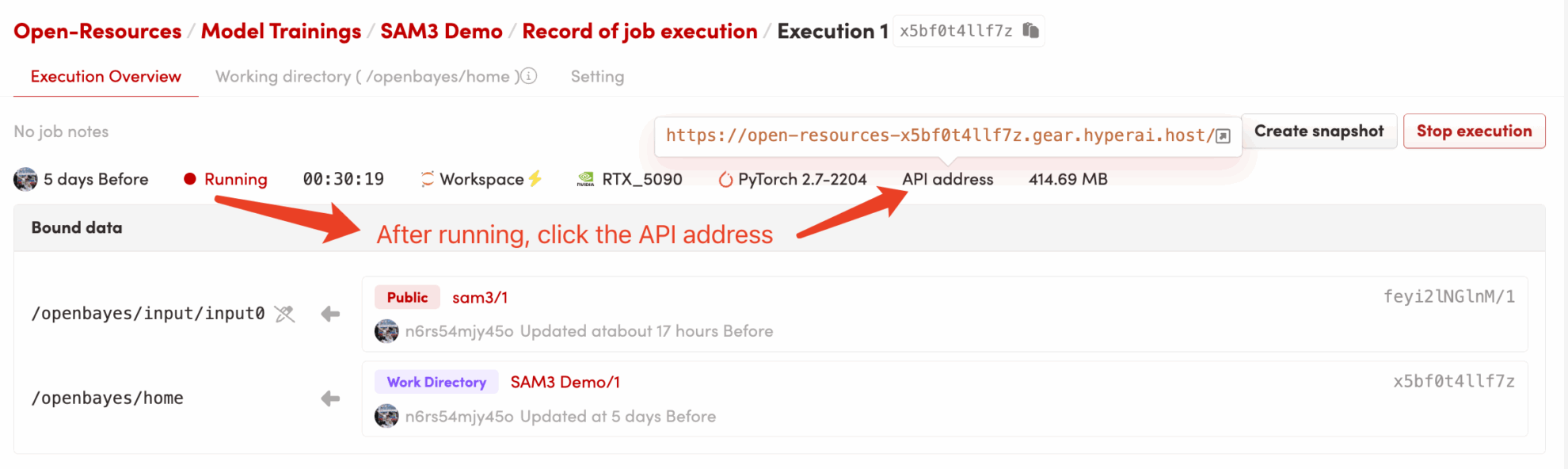
2. Anwendungsschritte
Wenn „Bad Gateway“ angezeigt wird, bedeutet dies, dass das Modell initialisiert wird. Da das Modell groß ist, warten Sie bitte etwa 2–3 Minuten und aktualisieren Sie die Seite.
1. Bildsegmentierung
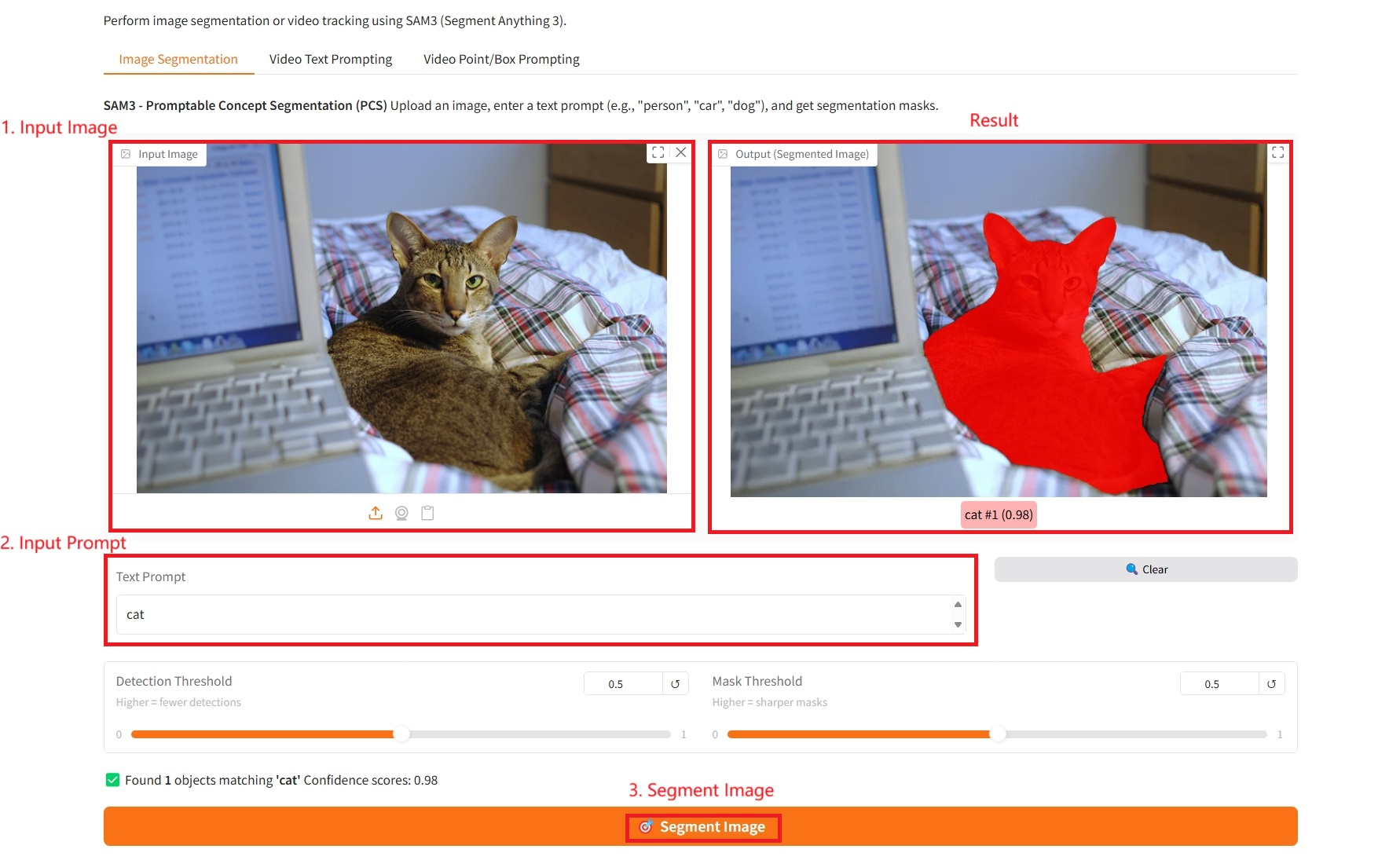
Spezifische Parameter:
- Texteingabeaufforderung: Hier können Sie Text eingeben.
- Erkennungsschwelle: Je höher die Schwelle, desto weniger Ziele werden erkannt.
- Maskenschwelle: Je höher die Schwelle, desto klarer und schärfer die erzeugten Maskengrenzen.
2. Video-Text-Eingabe
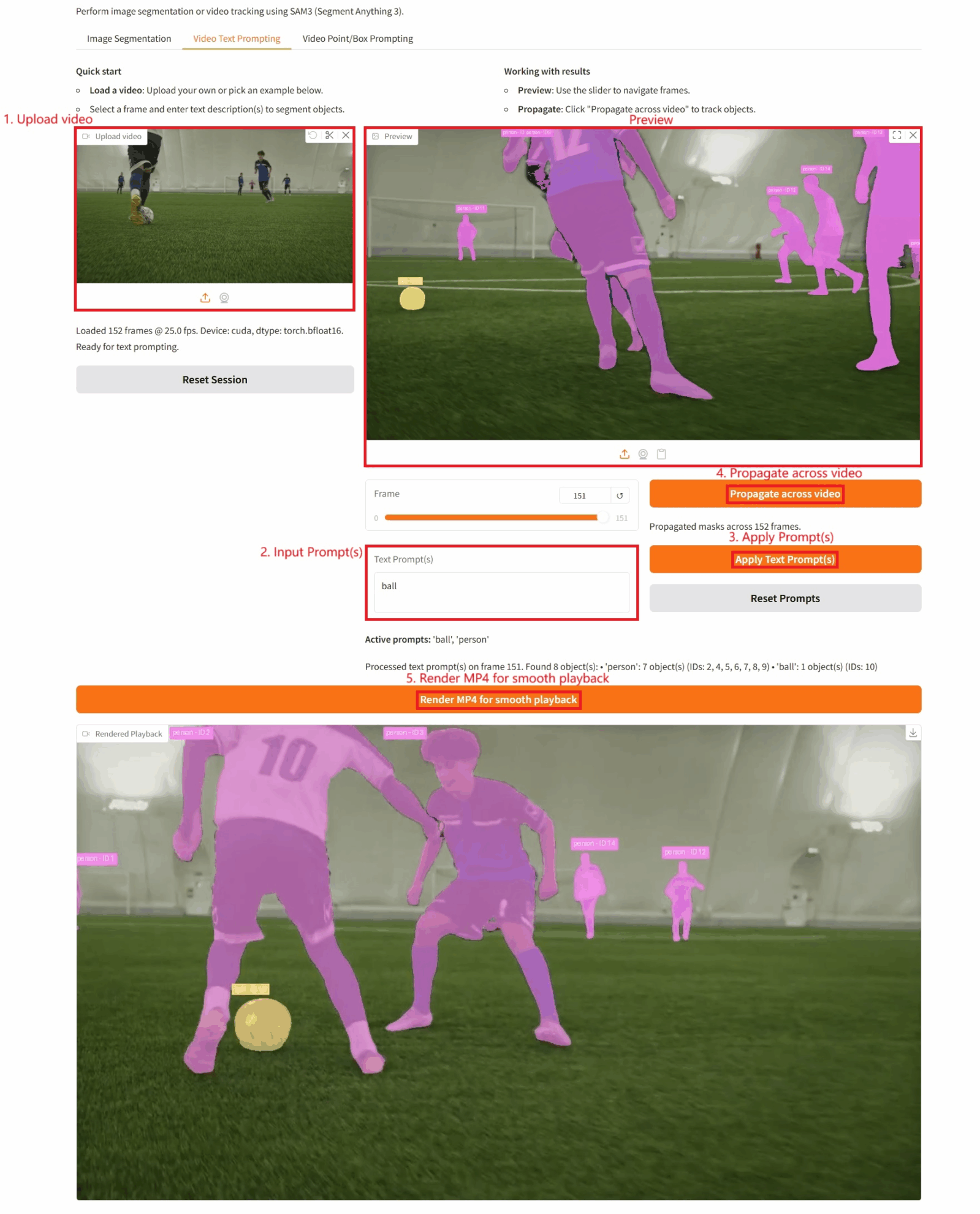
Spezifische Parameter:
- Texteingabeaufforderung(en): Hier können Sie Text eingeben.
- Videoverfolgung: Klicken Sie auf diese Schaltfläche, um die Videoverfolgung des Ziels durchzuführen.
3. Video-Punkt-/Box-Eingabe
Spezifische Parameter:
- Objekt-ID: Die erkannte Ziel-ID.
- Punktbezeichnung:
- positiv: Wenn Sie auf eine Stelle im Bild klicken und diese positiv ist, bedeutet dies, dass dieser Punkt zu dem Zielobjekt gehört, das Sie segmentieren möchten. Bitte beziehen Sie ihn daher in die Berechnung mit ein.
- Negativ: Wenn Sie auf eine Stelle im Bild klicken und diese negativ ist, bedeutet dies, dass dieser Punkt nicht zum Zielobjekt gehört (es handelt sich um den Hintergrund oder etwas anderes), bitte entfernen Sie ihn.
- Alte Eingaben für dieses Objekt löschen: Gibt an, ob zuvor erkannte Ziele gelöscht werden sollen.
- Eingabeaufforderungstyp:
- Hinweise: Visuelle Hinweise anklicken.
- Kästchen: Visuelle Hinweise zur Auswahl von Artikeln.

Zitationsinformationen
Die Zitationsinformationen für dieses Projekt lauten wie folgt:
@misc{carion2025sam3segmentconcepts,
title={SAM 3: Segment Anything with Concepts},
author={Nicolas Carion and Laura Gustafson and Yuan-Ting Hu and Shoubhik Debnath and Ronghang Hu and Didac Suris and Chaitanya Ryali and Kalyan Vasudev Alwala and Haitham Khedr and Andrew Huang and Jie Lei and Tengyu Ma and Baishan Guo and Arpit Kalla and Markus Marks and Joseph Greer and Meng Wang and Peize Sun and Roman Rädle and Triantafyllos Afouras and Effrosyni Mavroudi and Katherine Xu and Tsung-Han Wu and Yu Zhou and Liliane Momeni and Rishi Hazra and Shuangrui Ding and Sagar Vaze and Francois Porcher and Feng Li and Siyuan Li and Aishwarya Kamath and Ho Kei Cheng and Piotr Dollár and Nikhila Ravi and Kate Saenko and Pengchuan Zhang and Christoph Feichtenhofer},
year={2025},
eprint={2511.16719},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2511.16719},
}Notebook-Übersicht
Stufe
KI mit KI entwickeln
Von der Idee bis zum Launch – beschleunigen Sie Ihre KI-Entwicklung mit kostenlosem KI-Co-Coding, sofort einsatzbereiter Umgebung und bestem GPU-Preis.