HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

Jenseits der Transkription: Mechanistische Interpretierbarkeit in der Spracherkennung

CODA: Koordination von Großhirn und Kleinhirn für einen Dual-Brain-Computer-Nutzungs-Agenten mit entkoppelter Verstärkungslernung






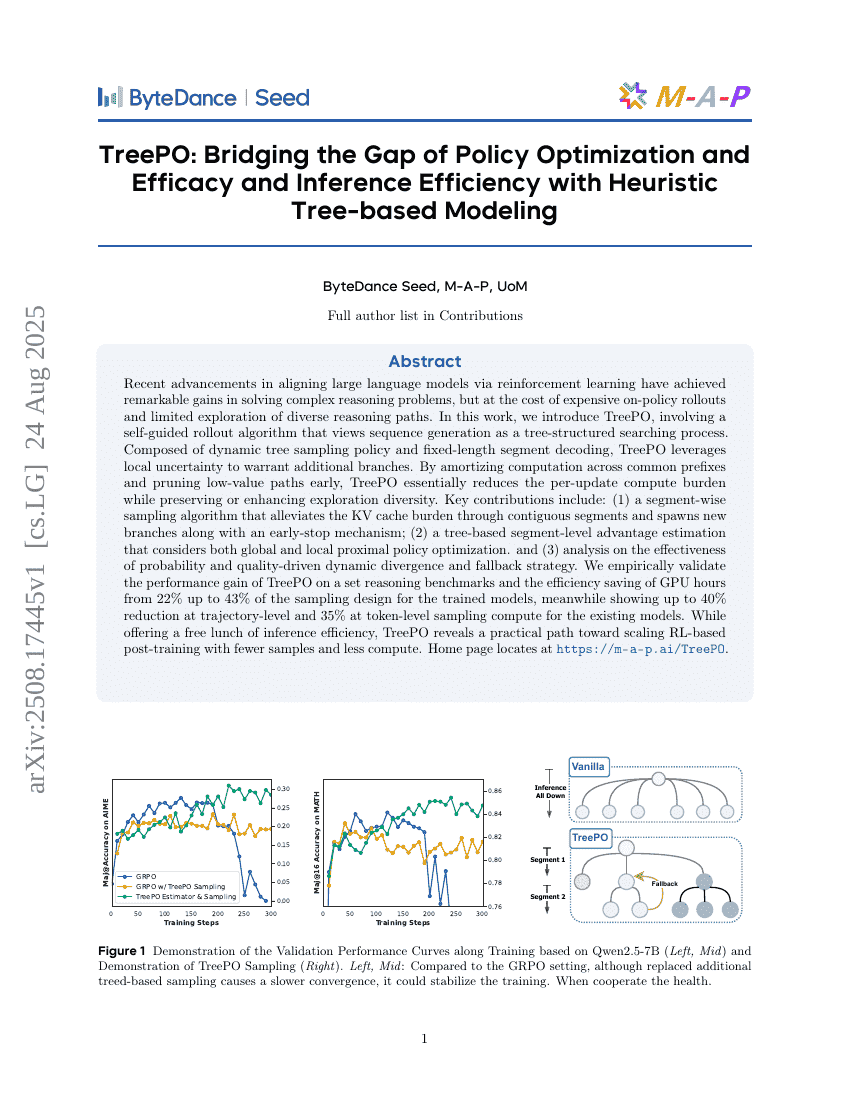





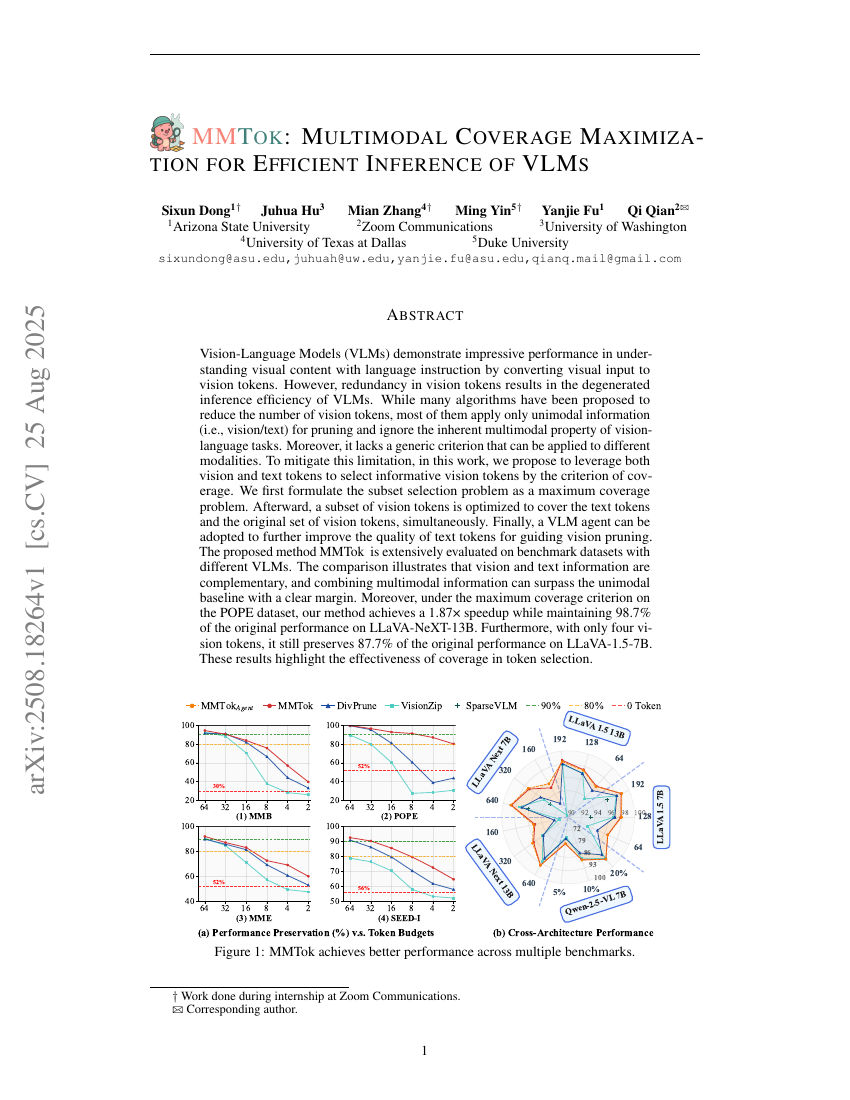




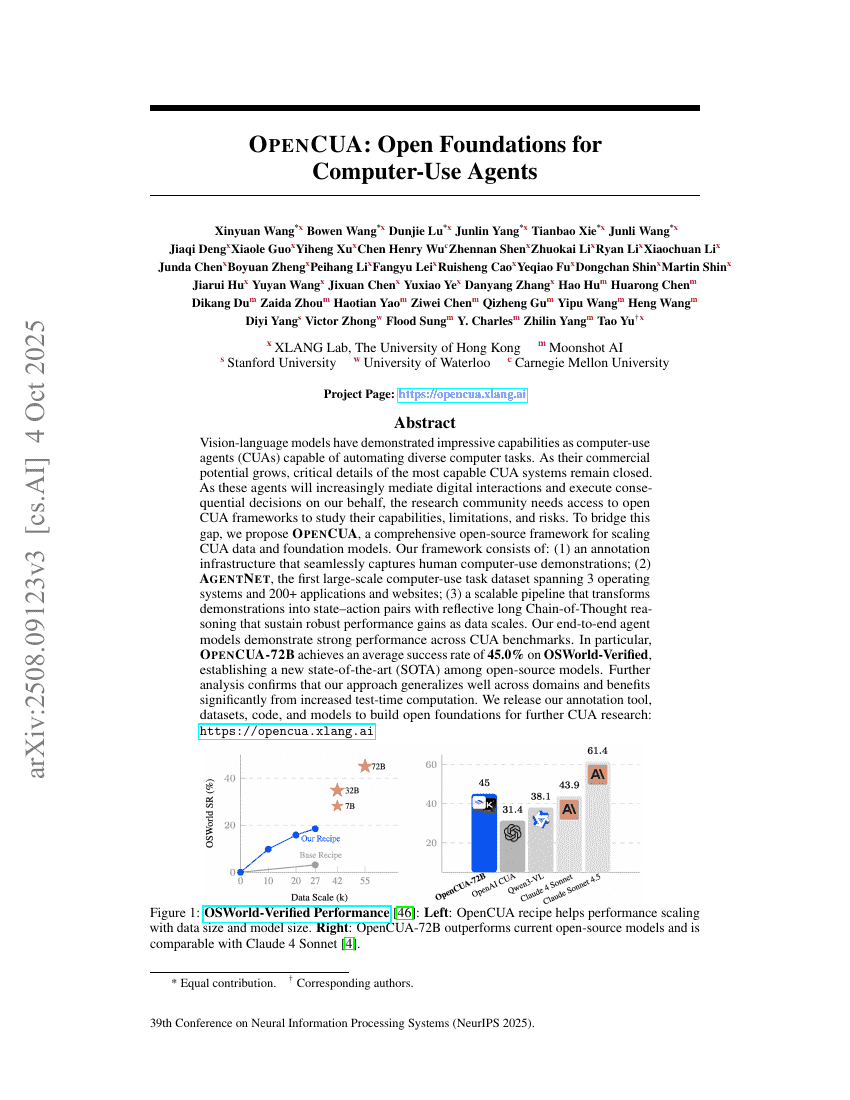

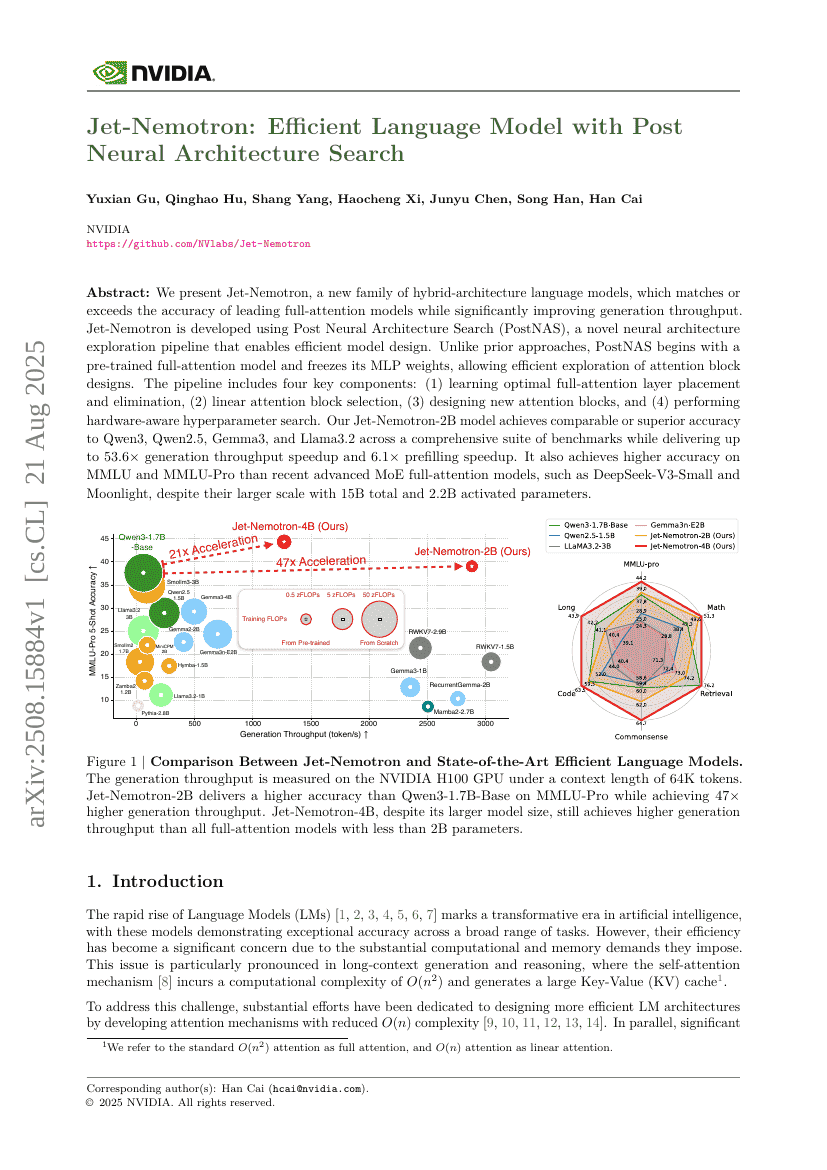







Jenseits der Transkription: Mechanistische Interpretierbarkeit in der Spracherkennung
CODA: Koordination von Großhirn und Kleinhirn für einen Dual-Brain-Computer-Nutzungs-Agenten mit entkoppelter Verstärkungslernung
WebSight: Eine vision-first-Architektur für robuste Web-Agenten
UltraMemV2: Speicher-Netzwerke mit Skalierung auf 120B Parameter und überlegener Lernleistung für lange Kontexte
Technischer Bericht von Hermes 4
OmniHuman-1.5: Verleihen eines aktiven Geistes an Avatare durch kognitive Simulation
VoxHammer: trainingsfreie präzise und kohärente 3D-Editierung im nativen 3D-Raum
CMPhysBench: Ein Benchmark zur Bewertung großer Sprachmodelle in der Festkörperphysik
TreePO: Brücke zwischen Policy-Optimierung und Wirksamkeit sowie Inferenzeffizienz durch heuristische baumbasierte Modellierung
Nemotron-CC-Math: Ein hochwertiger Vortrainingsdatensatz für Mathematik mit Skalierung auf 133 Milliarden Token
Verständniswerkzeug-integriertes Schließen
Spacer: Hin zu künstlich gestalteter wissenschaftlicher Inspiration
Jenseits der Wiederholung: Verlängerung der Rekursionstiefe durch Rekurrenz, Gedächtnis und Skalierung der Rechenleistung zur Prüfungszeit
VibeVoice Technischer Bericht
MMTok: Multimodale Abdeckungsoptimierung für eine effiziente Inferenz von VLMs
MV-RAG: Retrievalgestützte multiview-Diffusionsmethode
Verbindung der Synthese von metallorganischen Gerüsten mit Anwendungen mittels multimodaler maschineller Lernverfahren
Modellkontext-Protokolle in adaptiven Transportsystemen: Eine Übersicht
Algorithmenbasierte kollektive Aktion mit mehreren Kollektiven
OpenCUA: Offene Grundlagen für Computer-Use-Agenten
Raumpolitik: Steuerung visuomotorischer robotischer Manipulation mittels raumbewusster Modellierung und Schlussfolgerung
Jet-Nemotron: Effizientes Sprachmodell mit nachgeschalteter neuronaler Architektursuche
CRISP: Persistente Konzeptvergessen durch sparse Autoencoder
Selektives kontrastives Lernen für schwach überwachtes Affordance-Grundlegen
EgoTwin: Träumender Körper und Perspektive aus erster Person
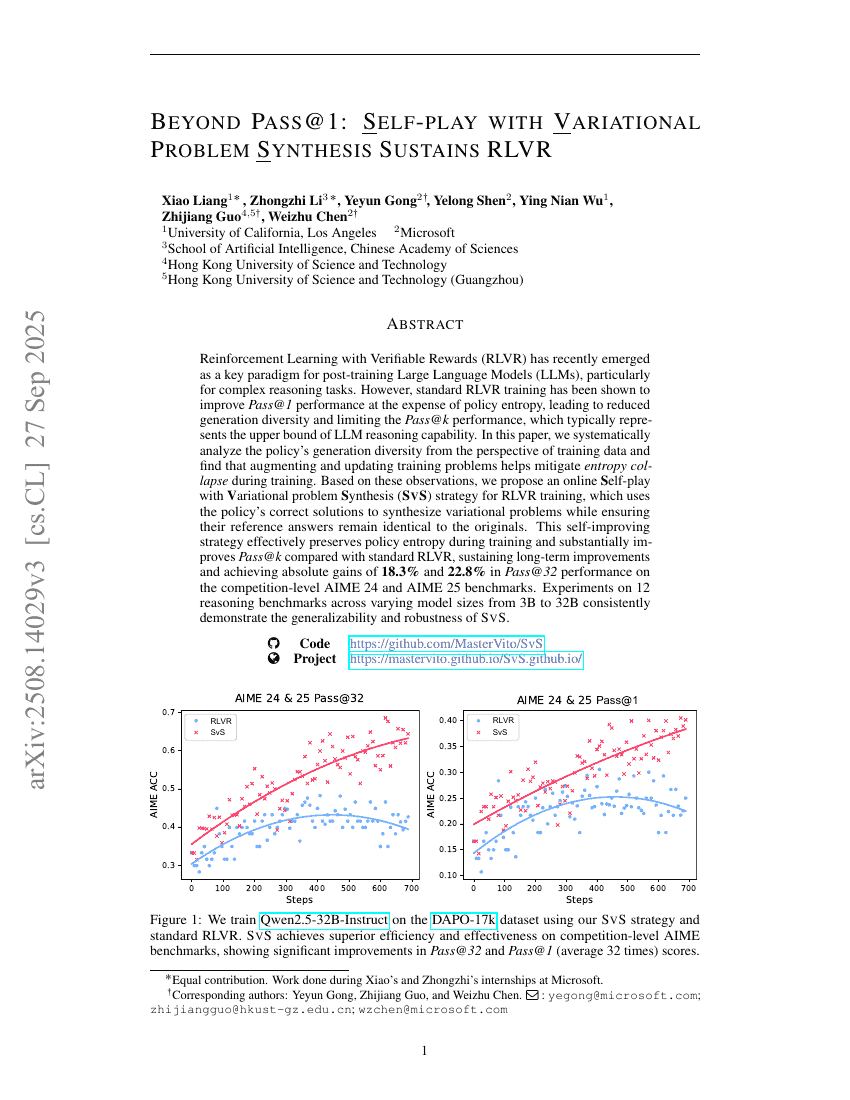
Jenseits von Pass@1: Selbstspiel mit variationaler Problemgenerierung erhält RLVR aufrechterhalten
ODYSSEY: Offene Welt Erkundung und Manipulation von Viertelfüßlern für langfristige Aufgaben
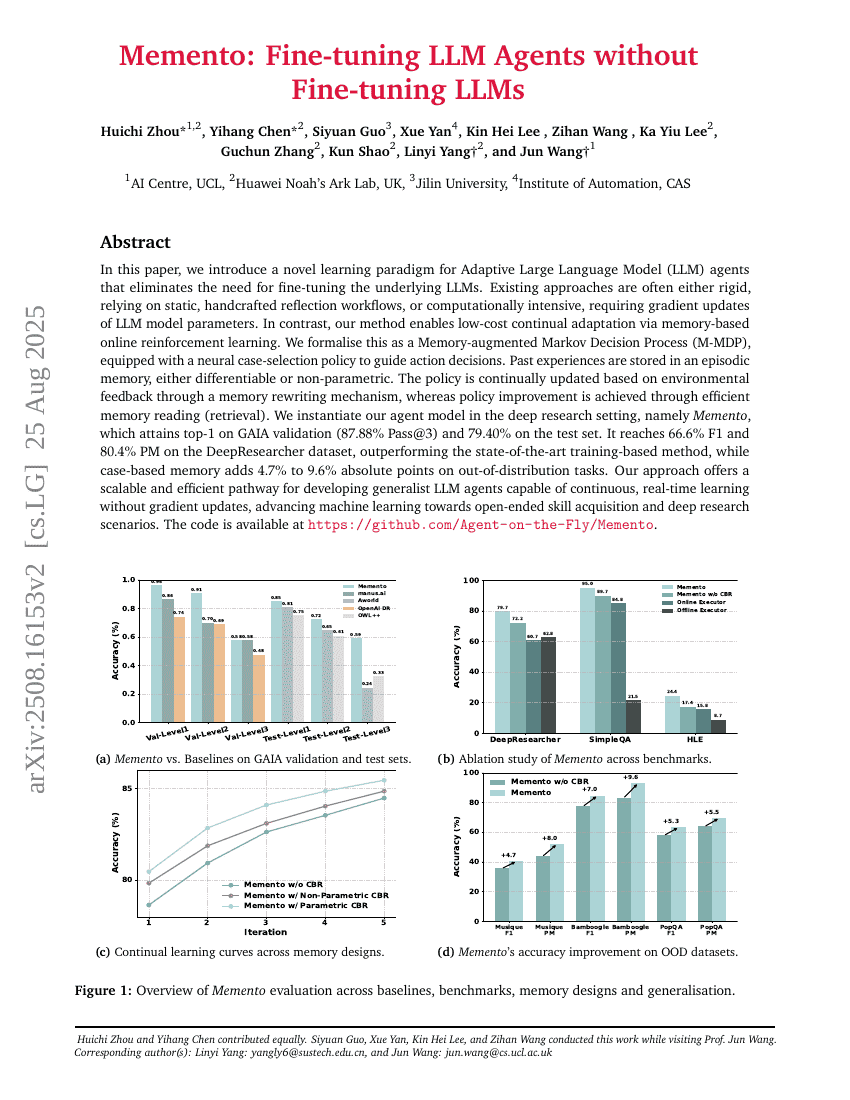
AgentFly: Feinabstimmen von LLM-Agenten ohne Feinabstimmen von LLMs
Constraints-Guided Diffusion Reasoner für neuro-symbolisches Lernen
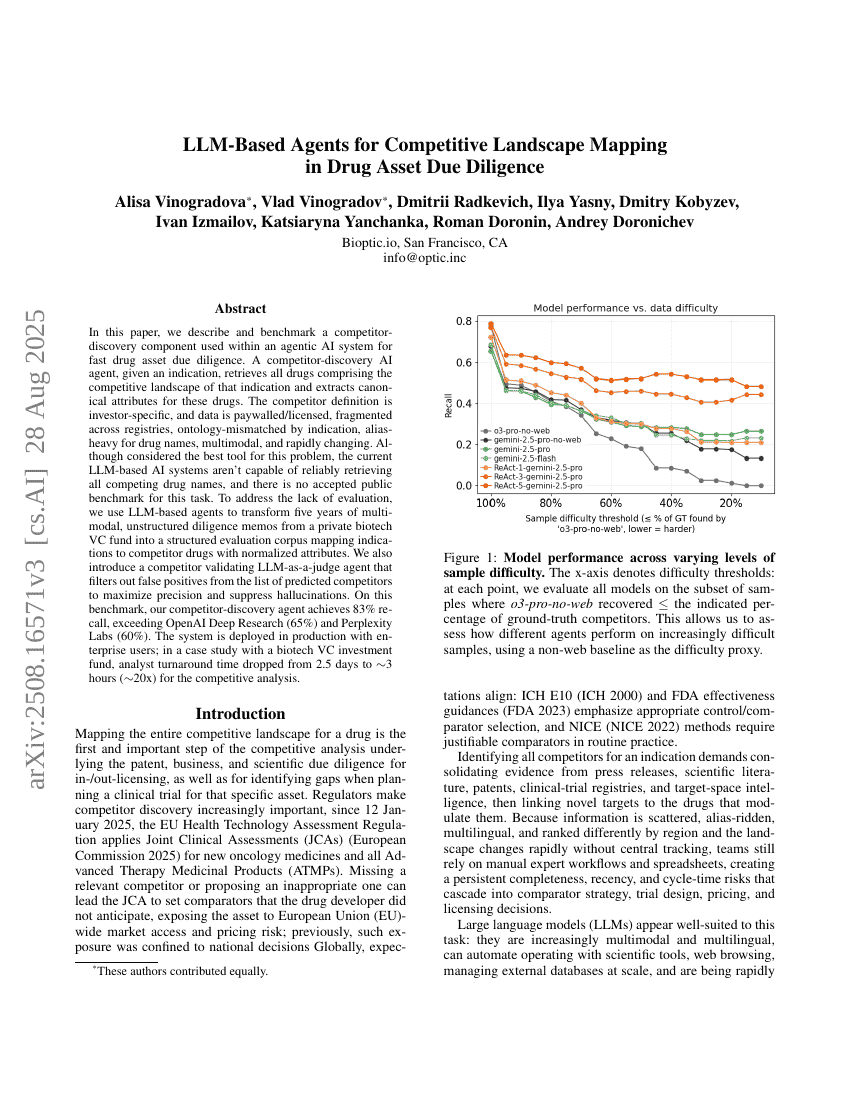
LLM-basierte Agenten zur Erkundung des Wettbewerbslandschafts bei der Due-Diligence von Arzneimittelressourcen
SceneGen: Einzelbild-3D-Szenenerzeugung in einem Feedforward-Schritt
Eine Übersicht über Benchmark-Tests für große Sprachmodelle
WebSight: Eine vision-first-Architektur für robuste Web-Agenten
UltraMemV2: Speicher-Netzwerke mit Skalierung auf 120B Parameter und überlegener Lernleistung für lange Kontexte
Technischer Bericht von Hermes 4
OmniHuman-1.5: Verleihen eines aktiven Geistes an Avatare durch kognitive Simulation
VoxHammer: trainingsfreie präzise und kohärente 3D-Editierung im nativen 3D-Raum
CMPhysBench: Ein Benchmark zur Bewertung großer Sprachmodelle in der Festkörperphysik
TreePO: Brücke zwischen Policy-Optimierung und Wirksamkeit sowie Inferenzeffizienz durch heuristische baumbasierte Modellierung
Nemotron-CC-Math: Ein hochwertiger Vortrainingsdatensatz für Mathematik mit Skalierung auf 133 Milliarden Token
Verständniswerkzeug-integriertes Schließen
Spacer: Hin zu künstlich gestalteter wissenschaftlicher Inspiration
Jenseits der Wiederholung: Verlängerung der Rekursionstiefe durch Rekurrenz, Gedächtnis und Skalierung der Rechenleistung zur Prüfungszeit
VibeVoice Technischer Bericht
MMTok: Multimodale Abdeckungsoptimierung für eine effiziente Inferenz von VLMs
MV-RAG: Retrievalgestützte multiview-Diffusionsmethode
Verbindung der Synthese von metallorganischen Gerüsten mit Anwendungen mittels multimodaler maschineller Lernverfahren
Modellkontext-Protokolle in adaptiven Transportsystemen: Eine Übersicht
Algorithmenbasierte kollektive Aktion mit mehreren Kollektiven
OpenCUA: Offene Grundlagen für Computer-Use-Agenten
Raumpolitik: Steuerung visuomotorischer robotischer Manipulation mittels raumbewusster Modellierung und Schlussfolgerung
Jet-Nemotron: Effizientes Sprachmodell mit nachgeschalteter neuronaler Architektursuche
CRISP: Persistente Konzeptvergessen durch sparse Autoencoder
Selektives kontrastives Lernen für schwach überwachtes Affordance-Grundlegen
EgoTwin: Träumender Körper und Perspektive aus erster Person
Jenseits von Pass@1: Selbstspiel mit variationaler Problemgenerierung erhält RLVR aufrechterhalten
ODYSSEY: Offene Welt Erkundung und Manipulation von Viertelfüßlern für langfristige Aufgaben
AgentFly: Feinabstimmen von LLM-Agenten ohne Feinabstimmen von LLMs
Constraints-Guided Diffusion Reasoner für neuro-symbolisches Lernen
LLM-basierte Agenten zur Erkundung des Wettbewerbslandschafts bei der Due-Diligence von Arzneimittelressourcen
SceneGen: Einzelbild-3D-Szenenerzeugung in einem Feedforward-Schritt
Eine Übersicht über Benchmark-Tests für große Sprachmodelle