HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

Automatisierte Erkennung klinischer Probleme aus SOAP-Notizen mithilfe einer kooperativen Mehr-Agenten-LLM-Architektur

olmOCR: Trillionen von Tokens in PDFs mit Vision-Language-Modellen entschlüsseln


























Automatisierte Erkennung klinischer Probleme aus SOAP-Notizen mithilfe einer kooperativen Mehr-Agenten-LLM-Architektur
olmOCR: Trillionen von Tokens in PDFs mit Vision-Language-Modellen entschlüsseln
VA-MoE: Variables-Adaptive Mixture of Experts für inkrementelle Wettervorhersage
Wie kann eine Eingabereformulierung die Genauigkeit der Werkzeugnutzung in einer komplexen dynamischen Umgebung verbessern? Eine Studie zu τ-bench
Evaluierung auf UI-Ebene von ALLaM 34B: Messung eines arabisch-zentrierten LLM mittels HUMAIN Chat
Von reaktiv zu kognitiv: gehirngestützte räumliche Intelligenz für körperhafte Agenten
Kein Label zurückgelassen: Ein vereinheitlichtes Modell zur Oberflächenfehlererkennung für alle Überwachungsregime
T2R-bench: Ein Benchmark zur Generierung von artikelbasierten Berichten aus realen industriellen Tabellen
PVPO: Vorabgeschätzte wertbasierte Politikoptimierung für agenteles Denken
Das Training eines hilfreichen und harmlosen Assistenten mit dem Verstärkungslernen aus menschlicher Rückmeldung
UQ: Beurteilung von Sprachmodellen auf ungelösten Fragen
CARJAN: agentenbasierte Generierung und Simulation von Verkehrszenarien mit AJAN
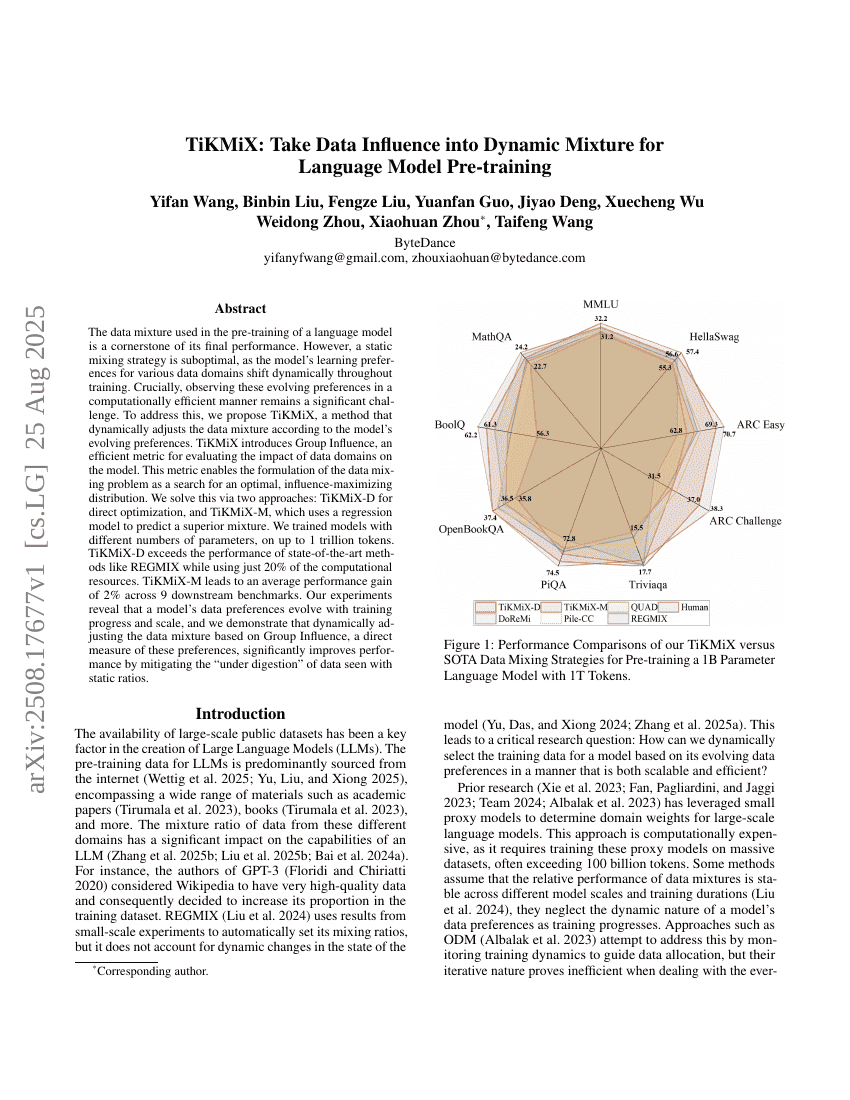
TiKMiX: Datenbeeinflussung in dynamische Mischung für die Sprachmodell-Vortrainierung einbeziehen
TalkVid: Ein großskaliges und vielfältiges Datensatz für audiogetriebene Synthese von sprechenden Köpfen
Droplet3D: Alltagswissen aus Videos unterstützt die 3D-Generierung
A.S.E.: Ein benchmark auf Repository-Ebene zur Bewertung der Sicherheit in künstlich generiertem Code
EmbodiedOneVision: Durchmischtes Vortrainieren von Vision-Text-Action für allgemeine Robotersteuerung
R-4B: Anreizung einer allgemeinen Auto-Denkfähigkeit in MLLMs durch zweistufige Annealing- und Verstärkungslernverfahren
Anfachen kreativen Schreibens in kleinen Sprachmodellen: LLM-as-a-Judge im Vergleich zu mehragentenbasierten verfeinerten Belohnungen
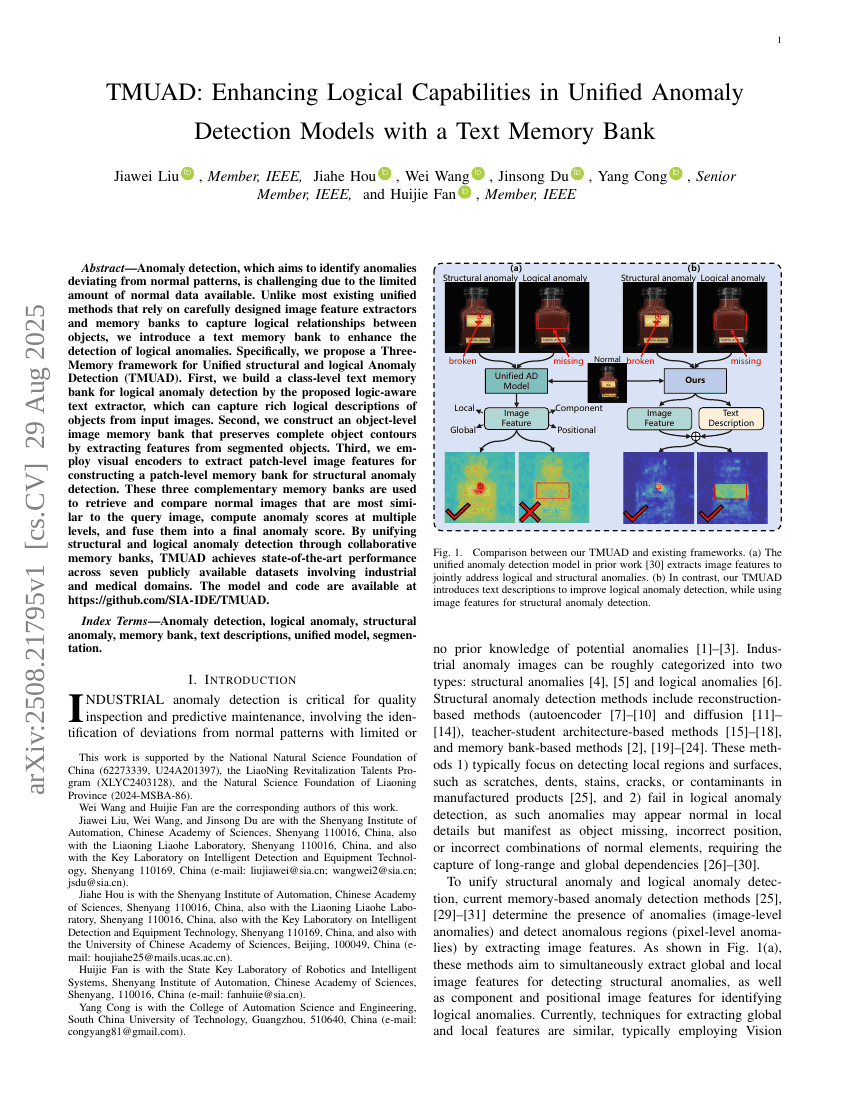
TMUAD: Verbesserung logischer Fähigkeiten in einheitlichen Anomalieerkennungsmodellen mit einem Text-Speicherbank
Analyse der Denkketten-Dynamik: Aktive Steuerung oder untreue nachträgliche Rationalisierung?
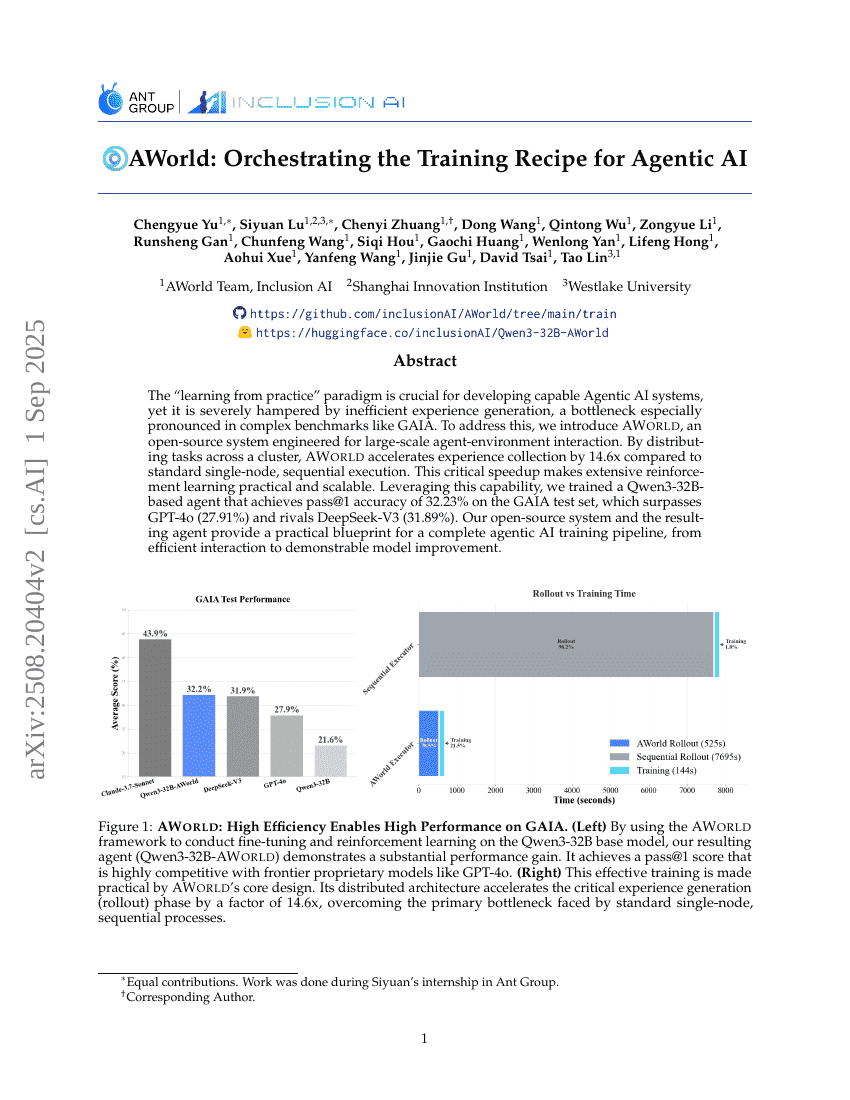
AWorld: Die Koordination des Trainingsrezepts für agente AI
MCP-Bench: Benchmark-Tool für das Verwenden von LLM-Agenten mit komplexen Aufgaben aus der realen Welt über MCP-Server
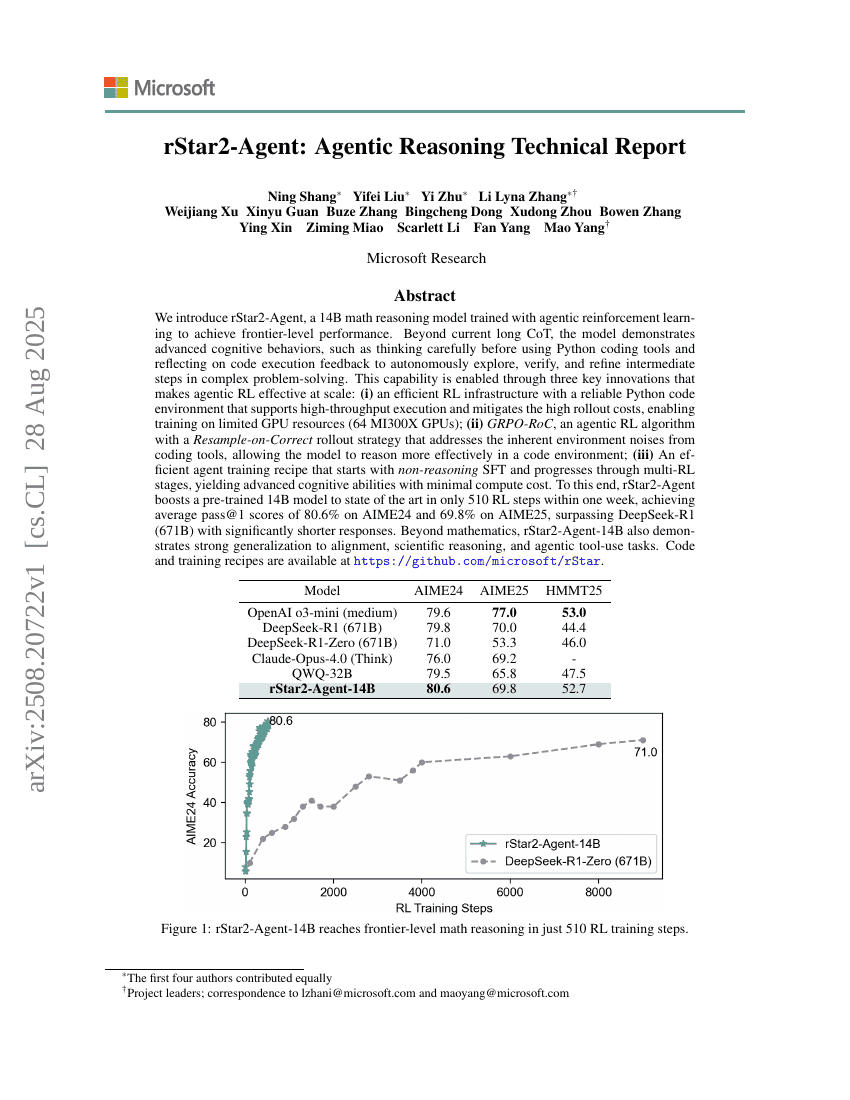
rStar2-Agent: Technischer Bericht zur agentenbasierten Schlussfolgerung
Pref-GRPO: Paarweiser Präferenz-Reward-basierter GRPO für stabiles Text-zu-Bild-Reinforcement-Learning
MobileCLIP2: Verbesserung des multimodalen verstärkten Trainings
KI-KI-Ästhetische Zusammenarbeit mit expliziter semiotischer Bewusstheit und emergenter Grammatikentwicklung
In das Herz blicken: Ein Multiview-Video-Datensatz für die rPPG- und Gesundheitsbiomarker-Schätzung
Die Vorhersage der Reihenfolge kommender Tokens verbessert die Sprachmodellierung
MIDAS: Multimodale interaktive digitale Mensch-Synthese durch Echtzeit-Autoregressive Videogenerierung
Diskrete Diffusions-VLA: Einbringen diskreter Diffusion in die Aktionstdekodierung von visuell-sprachlich-handelnden Politiken
Selbstbelohnender visuell-sprachlicher Modellierungsansatz durch Reasoning-Dekomposition
VA-MoE: Variables-Adaptive Mixture of Experts für inkrementelle Wettervorhersage
Wie kann eine Eingabereformulierung die Genauigkeit der Werkzeugnutzung in einer komplexen dynamischen Umgebung verbessern? Eine Studie zu τ-bench
Evaluierung auf UI-Ebene von ALLaM 34B: Messung eines arabisch-zentrierten LLM mittels HUMAIN Chat
Von reaktiv zu kognitiv: gehirngestützte räumliche Intelligenz für körperhafte Agenten
Kein Label zurückgelassen: Ein vereinheitlichtes Modell zur Oberflächenfehlererkennung für alle Überwachungsregime
T2R-bench: Ein Benchmark zur Generierung von artikelbasierten Berichten aus realen industriellen Tabellen
PVPO: Vorabgeschätzte wertbasierte Politikoptimierung für agenteles Denken
Das Training eines hilfreichen und harmlosen Assistenten mit dem Verstärkungslernen aus menschlicher Rückmeldung
UQ: Beurteilung von Sprachmodellen auf ungelösten Fragen
CARJAN: agentenbasierte Generierung und Simulation von Verkehrszenarien mit AJAN
TiKMiX: Datenbeeinflussung in dynamische Mischung für die Sprachmodell-Vortrainierung einbeziehen
TalkVid: Ein großskaliges und vielfältiges Datensatz für audiogetriebene Synthese von sprechenden Köpfen
Droplet3D: Alltagswissen aus Videos unterstützt die 3D-Generierung
A.S.E.: Ein benchmark auf Repository-Ebene zur Bewertung der Sicherheit in künstlich generiertem Code
EmbodiedOneVision: Durchmischtes Vortrainieren von Vision-Text-Action für allgemeine Robotersteuerung
R-4B: Anreizung einer allgemeinen Auto-Denkfähigkeit in MLLMs durch zweistufige Annealing- und Verstärkungslernverfahren
Anfachen kreativen Schreibens in kleinen Sprachmodellen: LLM-as-a-Judge im Vergleich zu mehragentenbasierten verfeinerten Belohnungen
TMUAD: Verbesserung logischer Fähigkeiten in einheitlichen Anomalieerkennungsmodellen mit einem Text-Speicherbank
Analyse der Denkketten-Dynamik: Aktive Steuerung oder untreue nachträgliche Rationalisierung?
AWorld: Die Koordination des Trainingsrezepts für agente AI
MCP-Bench: Benchmark-Tool für das Verwenden von LLM-Agenten mit komplexen Aufgaben aus der realen Welt über MCP-Server
rStar2-Agent: Technischer Bericht zur agentenbasierten Schlussfolgerung
Pref-GRPO: Paarweiser Präferenz-Reward-basierter GRPO für stabiles Text-zu-Bild-Reinforcement-Learning
MobileCLIP2: Verbesserung des multimodalen verstärkten Trainings
KI-KI-Ästhetische Zusammenarbeit mit expliziter semiotischer Bewusstheit und emergenter Grammatikentwicklung
In das Herz blicken: Ein Multiview-Video-Datensatz für die rPPG- und Gesundheitsbiomarker-Schätzung
Die Vorhersage der Reihenfolge kommender Tokens verbessert die Sprachmodellierung
MIDAS: Multimodale interaktive digitale Mensch-Synthese durch Echtzeit-Autoregressive Videogenerierung
Diskrete Diffusions-VLA: Einbringen diskreter Diffusion in die Aktionstdekodierung von visuell-sprachlich-handelnden Politiken
Selbstbelohnender visuell-sprachlicher Modellierungsansatz durch Reasoning-Dekomposition