HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

Frühe Beschleunigungsversuche in der Wissenschaft mit GPT-5

Zu einer objektiven und systematischen Bewertung von Verzerrungen in der künstlichen Intelligenz für die medizinische Bildgebung
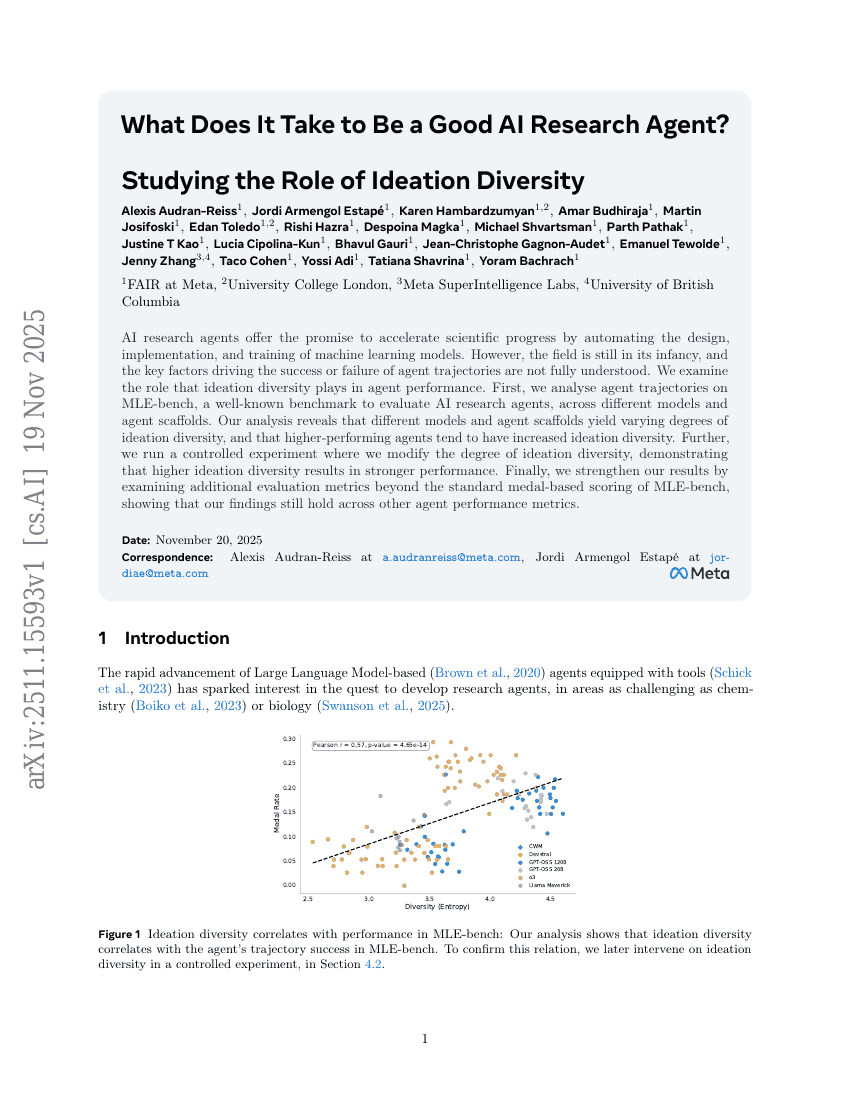
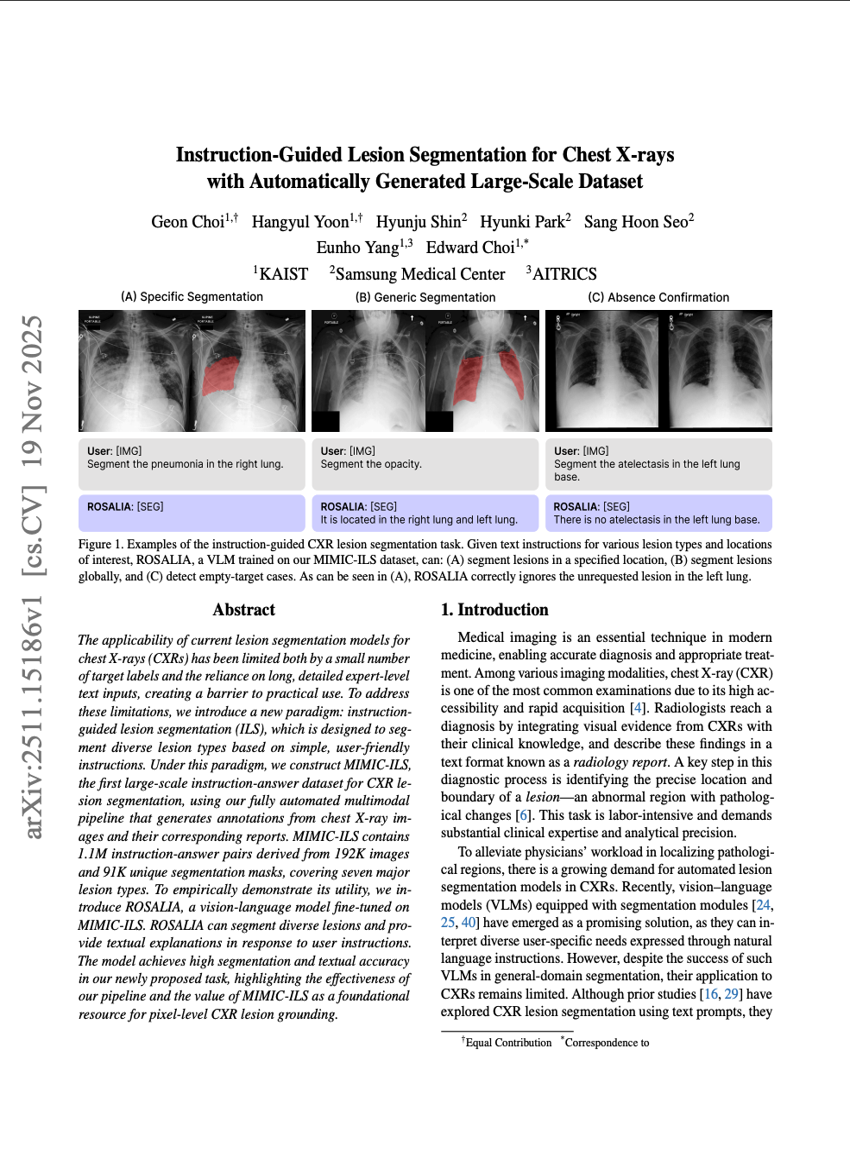
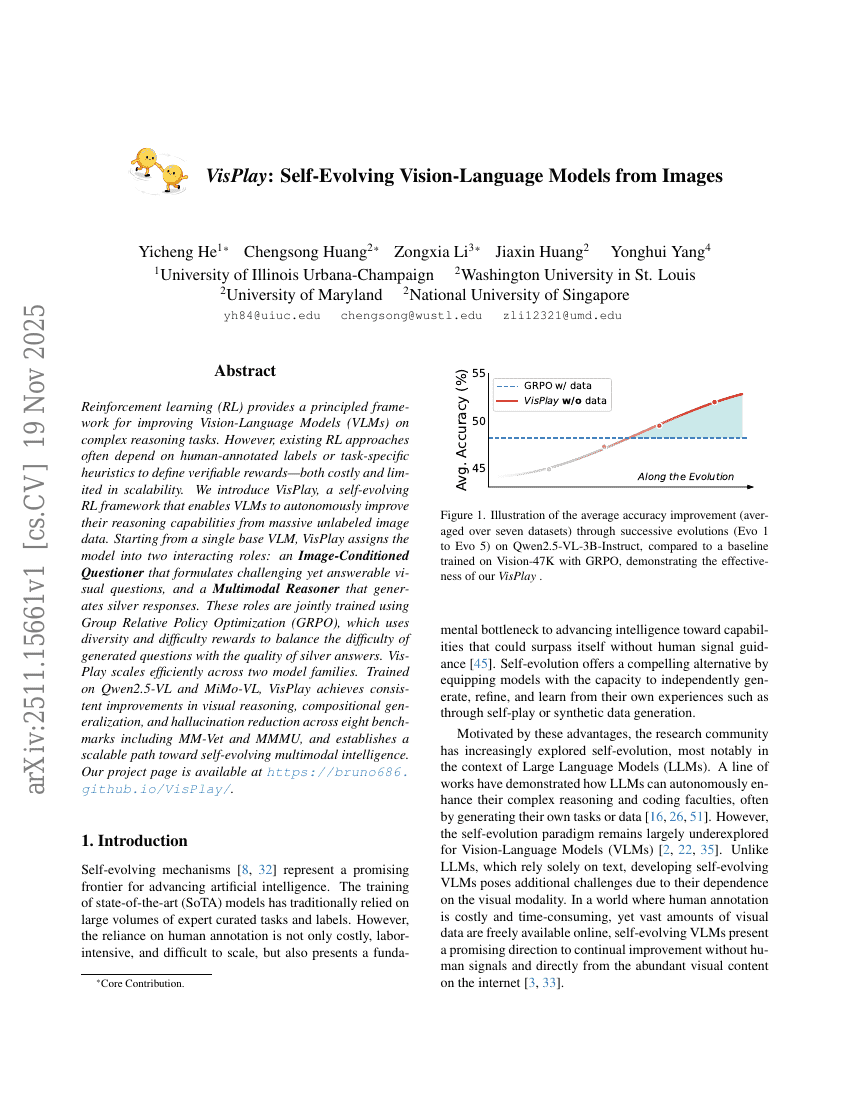






















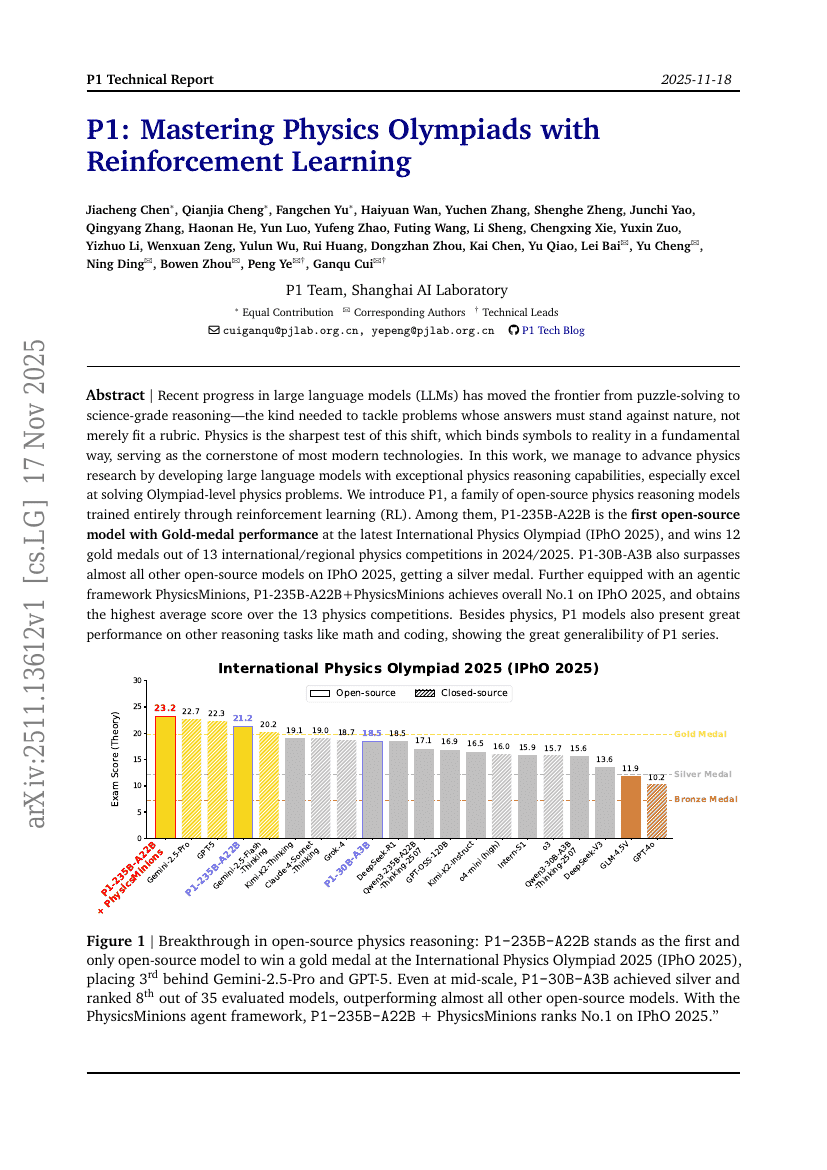



Frühe Beschleunigungsversuche in der Wissenschaft mit GPT-5
Zu einer objektiven und systematischen Bewertung von Verzerrungen in der künstlichen Intelligenz für die medizinische Bildgebung
Was macht einen guten AI-Forschungs-Agenten aus? Eine Untersuchung zur Rolle der Ideen-Diversität
Anweisungsgeleitete Läsionssegmentierung für Brust-Röntgenaufnahmen mit automatisch generiertem, großskaligem Datensatz
VisPlay: Selbstentwickelnde Vision-Sprache-Modelle aus Bildern
Reasoning via Video: Die erste Evaluation der Reasoning-Fähigkeiten von Video-Modellen anhand von Labyrinth-Lösungsaufgaben
VIDEOP2R: Videoverstehen von Wahrnehmung bis Schlussfolgerung
Kandinsky 5.0: Eine Familie von Foundation Models für die Bild- und Videogenerierung
JAM-2: Vollständig rechnerisch gestaltetes, arzneimittelähnliches Antikörper mit hoher Erfolgsquote
PathMind: Ein Retrieve-Prioritize-Reason-Rahmenwerk für die Wissensgraphen-Reasoning mit großen Sprachmodellen
REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video Understanding
MVI-Bench: Ein umfassender Benchmark zur Bewertung der Robustheit gegenüber irreführenden visuellen Eingaben in LVLMs
Können Welten-Simulatoren reasoning? Gen-ViRe: Eine generative visuelle Reasoning-Benchmark
Ein Style ist wert ein Code: Code-zu-Style-Bildgenerierung mit diskretem Style-Raum freischalten
AraLingBench: Ein menschlich annotiertes Benchmark zur Bewertung der arabischen sprachlichen Fähigkeiten von Large Language Models
Think-at-Hard: Selektive latente Iterationen zur Verbesserung von Reasoning-LLMs
HumanSense: Von multimodaler Wahrnehmung zu empathischen, kontextbewussten Antworten durch Schlussfolgerung mit MLLMs
CamCloneMaster: Referenzbasierte Kamerasteuerung für die Videogenerierung ermöglichen
EditScore: Freigabe von Online-RL für die Bildbearbeitung durch belastbare Belohnungsmodellierung
InteractMove: Textgesteuerte Generierung menschlicher Objektinteraktionen in 3D-Szenen mit beweglichen Objekten
WebCoach: Selbstentwickelnde Web-Agenten mit Richtlinien für kontinuierliches Gedächtnis über Sitzungen hinweg
Vertrauen lernen: Bayessche Anpassung an wechselnde Zuverlässigkeit von Vorschlaggebern bei sequenziellen Entscheidungsprozessen
GroupRank: Ein gruppenweiser Neuordnungsansatz, getrieben durch Verstärkungslernen
MMaDA-Parallel: Multimodale große Diffusions-Sprachmodelle für den denkbewussten Editier- und Generierungsprozess
TiViBench: Benchmarking Think-in-Video Reasoning für Video-Generative Models
Part-X-MLLM: partenbewusstes 3D-multimodales Großsprachmodell
Uni-MoE-2.0-Omni: Skalierung sprachzentrierter omnimodaler großer Modelle mit fortgeschrittenem MoE, Training und Daten
P1: Physik-Olympiaden mit Reinforcement Learning meistern
Lancelot: Hin zu effizienten und Datenschutz-freundlichen byzantinisch-resilienten verteilten Lernverfahren innerhalb der vollständig homomorphen Verschlüsselung
Latentes Diffusionsmodell ohne Variationalen Autoencoder
RewardMap: Bewältigung spärlicher Belohnungen bei feinabgestufter visueller Schlussfolgerung mittels mehrstufiger Verstärkungslernverfahren
ReinFlow: Feinabstimmung der Flussübereinstimmungspolitik mit Online-Verstärkungslernen
Was macht einen guten AI-Forschungs-Agenten aus? Eine Untersuchung zur Rolle der Ideen-Diversität
Anweisungsgeleitete Läsionssegmentierung für Brust-Röntgenaufnahmen mit automatisch generiertem, großskaligem Datensatz
VisPlay: Selbstentwickelnde Vision-Sprache-Modelle aus Bildern
Reasoning via Video: Die erste Evaluation der Reasoning-Fähigkeiten von Video-Modellen anhand von Labyrinth-Lösungsaufgaben
VIDEOP2R: Videoverstehen von Wahrnehmung bis Schlussfolgerung
Kandinsky 5.0: Eine Familie von Foundation Models für die Bild- und Videogenerierung
JAM-2: Vollständig rechnerisch gestaltetes, arzneimittelähnliches Antikörper mit hoher Erfolgsquote
PathMind: Ein Retrieve-Prioritize-Reason-Rahmenwerk für die Wissensgraphen-Reasoning mit großen Sprachmodellen
REVISOR: Beyond Textual Reflection, Towards Multimodal Introspective Reasoning in Long-Form Video Understanding
MVI-Bench: Ein umfassender Benchmark zur Bewertung der Robustheit gegenüber irreführenden visuellen Eingaben in LVLMs
Können Welten-Simulatoren reasoning? Gen-ViRe: Eine generative visuelle Reasoning-Benchmark
Ein Style ist wert ein Code: Code-zu-Style-Bildgenerierung mit diskretem Style-Raum freischalten
AraLingBench: Ein menschlich annotiertes Benchmark zur Bewertung der arabischen sprachlichen Fähigkeiten von Large Language Models
Think-at-Hard: Selektive latente Iterationen zur Verbesserung von Reasoning-LLMs
HumanSense: Von multimodaler Wahrnehmung zu empathischen, kontextbewussten Antworten durch Schlussfolgerung mit MLLMs
CamCloneMaster: Referenzbasierte Kamerasteuerung für die Videogenerierung ermöglichen
EditScore: Freigabe von Online-RL für die Bildbearbeitung durch belastbare Belohnungsmodellierung
InteractMove: Textgesteuerte Generierung menschlicher Objektinteraktionen in 3D-Szenen mit beweglichen Objekten
WebCoach: Selbstentwickelnde Web-Agenten mit Richtlinien für kontinuierliches Gedächtnis über Sitzungen hinweg
Vertrauen lernen: Bayessche Anpassung an wechselnde Zuverlässigkeit von Vorschlaggebern bei sequenziellen Entscheidungsprozessen
GroupRank: Ein gruppenweiser Neuordnungsansatz, getrieben durch Verstärkungslernen
MMaDA-Parallel: Multimodale große Diffusions-Sprachmodelle für den denkbewussten Editier- und Generierungsprozess
TiViBench: Benchmarking Think-in-Video Reasoning für Video-Generative Models
Part-X-MLLM: partenbewusstes 3D-multimodales Großsprachmodell
Uni-MoE-2.0-Omni: Skalierung sprachzentrierter omnimodaler großer Modelle mit fortgeschrittenem MoE, Training und Daten
P1: Physik-Olympiaden mit Reinforcement Learning meistern
Lancelot: Hin zu effizienten und Datenschutz-freundlichen byzantinisch-resilienten verteilten Lernverfahren innerhalb der vollständig homomorphen Verschlüsselung
Latentes Diffusionsmodell ohne Variationalen Autoencoder
RewardMap: Bewältigung spärlicher Belohnungen bei feinabgestufter visueller Schlussfolgerung mittels mehrstufiger Verstärkungslernverfahren
ReinFlow: Feinabstimmung der Flussübereinstimmungspolitik mit Online-Verstärkungslernen