Command Palette
Search for a command to run...
Auf Basis Von Gemini, Das Nachrichten Aus 150 Ländern Verarbeitet, Hat Google Den Open-Source-Datensatz Groundsource Zu Überschwemmungen Veröffentlicht, Der Über 2,6 Millionen Historische Datensätze umfasst.
Unter den zahlreichen Naturkatastrophen weltweit zählen Überschwemmungen zu den wenigen, die häufig auftreten und gleichzeitig immense Zerstörungskraft besitzen. Daher sind sie seit Langem ein zentrales Thema in den Bereichen Hydrologie, Klimaforschung und Katastrophenmanagement. Die Forschung befasst sich mit der Verbesserung hydrologischer Vorhersagemodelle, der Analyse der Auswirkungen des Klimawandels auf die Entwicklung von Überschwemmungen, der Bewertung zukünftiger Überschwemmungsrisiken und der Optimierung von Katastrophenschutz- und -minderungssystemen.Nahezu alle einschlägigen Studien setzen die gleiche Grundvoraussetzung voraus – qualitativ hochwertige historische Hochwasserdaten.Diese Daten dienen als wichtige Referenz zur Überprüfung der Zuverlässigkeit des Modells und als wichtige Grundlage für die Risikobewertung und politische Entscheidungen.
Traditionelle hydrologische und meteorologische Messstationen sind weit verstreut, und die Datenqualität variiert, was die Erfassung großflächiger, hochpräziser Hochwasserdaten erschwert. Derzeit sind wirklich umfassende Hochwasserdatensätze rar gesät. Die vom US-amerikanischen National Center for Environmental Information (NCEI) geführte Storm Events Database ist zwar ein typisches Beispiel, doch systematische Aufzeichnungen dieser Art sind weltweit selten, und viele Länder haben noch keine langfristigen Hochwasserdatenbanken eingerichtet. Daher weisen bestehende globale Hochwasserdatensätze im Allgemeinen Lücken in Abdeckung und Vollständigkeit auf.
Es ist bemerkenswert, dass viele Informationen über Hochwasserereignisse lange Zeit in unstrukturierten Texten wie Nachrichtenberichten und Regierungsdokumenten verstreut waren. Bisherige Forschungsarbeiten versuchten zwar, Daten aus diesen Quellen zu extrahieren, doch Einschränkungen bei der Textstandardisierung und hohe Kosten der manuellen Bearbeitung behinderten eine großflächige Umsetzung. Jüngste Fortschritte im Bereich der generativen künstlichen Intelligenz eröffnen nun einen vielversprechenden neuen Ansatz zur Lösung dieses Problems.
Kürzlich hat Google Research den Groundsource-Überschwemmungsdatensatz als Open Source veröffentlicht. Dieser extrahiert validierte Bodeninformationen aus unstrukturierten Daten und ermöglicht so die Kartierung historischer Katastrophenspuren mit beispielloser Genauigkeit.Forscher automatisierten die Verarbeitung von über 5 Millionen Nachrichtenberichten aus mehr als 150 Ländern und trugen so letztendlich über 2,6 Millionen Datensätze zu historischen Überschwemmungsereignissen zusammen.Es bietet einen beispiellosen Umfang und eine beispiellose Abdeckung von Daten für die globale Hochwasserforschung.
derzeit,「Der Groundsource Global Flood Events Dataset ist jetzt auf der HyperAI-Website (hyper.ai) im Bereich „Datensätze“ verfügbar.Online-Nutzung:

Papieradresse:
https://eartharxiv.org/repository/view/12083/
Folgen Sie unserem offiziellen WeChat-Konto und antworten Sie im Hintergrund mit „Groundsource“, um das vollständige PDF zu erhalten.
Aus 5 Millionen Nachrichtenartikeln wurden mehr als 2,6 Millionen Hochwasserberichte ausgewertet.
Der Groundsource-Datensatz wurde mithilfe eines standardisierten, automatisierten Prozesses erstellt. Während der globalen Datenerfassung und der Entitätserkennung nutzte das Forschungsteam Teile der Google-Infrastruktur, darunter das Named-Entity-Recognition-System WebRef und das Read-Aloud-Tool. Die Logik der Datenextraktion, das Framework zur Generierung von Sprachmodellvorschlägen und die Regeln zur raumzeitlichen Aggregation sind jedoch öffentlich dokumentiert. Daher lässt sich dieser Prozess auch in anderen technischen Umgebungen reproduzieren, indem Open-Source-Algorithmen oder andere Sprachmodelle verwendet werden.
Die Datenkonstruktion beginnt mit der Sammlung von Nachrichteninformationen.Das Forschungsteam nutzte Webcrawler, um öffentlich zugängliche Nachrichtenberichte zu sammeln, die seit dem Jahr 2000 veröffentlicht wurden, und verwendete WebRef, um für jeden Artikel einen Relevanzwert im Zusammenhang mit Überschwemmungen zu berechnen.Die Forscher setzten den Schwellenwert auf 0,6 fest.VorprüfungUngefähr 9,5 Millionen WebseitenEine manuelle Stichprobe ergab jedoch, dass nur etwa die Hälfte von ihnen tatsächlich über die Überschwemmungsereignisse berichtete, während der Rest lediglich am Rande erwähnt wurde.
Dann folgt die Textextraktionsphase.Das System entfernt automatisch Werbung und Navigationselemente von Webseiten, behält nur den Artikeltext und das Veröffentlichungsdatum bei und filtert nicht erkannte Sprachen oder nicht zugängliche Webseiten heraus.Die endgültige Anzahl verwendbarer Artikel betrug ungefähr 7,5 Millionen.Alle nicht-englischen Texte werden ins Englische übersetzt, und die geografischen Ortsnamen werden mittels Entitätserkennung extrahiert, um eine Kandidatenstandortdatenbank zu erstellen.
Die Identifizierung konkreter Überschwemmungsereignisse anhand von Nachrichtentexten ist der komplexeste Teil des gesamten Prozesses. Berichte enthalten oft mehrere Ortsangaben und ungenaue Zeitangaben wie „gestern“ oder „letzte Woche“. DaherDas Forschungsteam entwarf ein strukturiertes Vorschlagsframework für das große Sprachmodell Gemini und testete es anhand von 250 manuell annotierten Artikeln.Das Modell nutzte Google Read Aloud, um Rohdaten aus 80 Sprachen zu extrahieren und diese anschließend mithilfe der Cloud Translation API ins Englische zu normalisieren. Danach führte das Modell nacheinander vier Aufgaben aus: die Bestimmung, ob der Artikel ein reales Hochwasserereignis beschrieb, die Extraktion und Normalisierung des Ereigniszeitpunkts, die Identifizierung der vom Hochwasser betroffenen Orte und die Zuordnung der Ortsnamen zu standardisierten geografischen Kennungen.
Im Rahmen dieses ProzessesVon den 7,5 Millionen Artikeln wurden etwa 5 Millionen als solche identifiziert, die reale Überschwemmungsereignisse thematisierten.Basierend auf manuell annotierten Beispielen beträgt die Präzision der Ereigniserkennung etwa 751 TP³T und der Recall etwa 901 TP³T. Die Genauigkeit der Datums- und Ortsbestimmung ist etwas geringer, liefert aber dennoch aussagekräftige raumzeitliche Hinweise.
Um diese Ereignisse auf der Karte zu lokalisieren, geokodiert das System auch die Standorte: Wenn eine bestehende geografische Einheit gefunden werden kann, wird deren räumliche Grenze direkt verwendet; wenn keine Übereinstimmung gefunden werden kann, wird der Ortsname über einen Geokodierungsdienst in Koordinaten umgewandelt, und gegebenenfalls wird eine kleine Pufferzone für die räumliche Analyse generiert.
Schließlich fasste das Forschungsteam anhand geografischer Kennungen und zeitlicher Informationen die nacheinander gemeldeten Datensätze zu einzelnen Hochwasserereignissen zusammen und führte eine Qualitätskontrolle durch, wobei Datensätze mit zu weitem Umfang oder ungewöhnlichem Zeitpunkt entfernt wurden. Nach dieser Abfolge von ProzessenDie Ergebnisse lieferten über 2,64 Millionen eindeutige Datensätze, die jeweils einer in Nachrichtenberichten festgehaltenen Hochwasserbeobachtung zu einem bestimmten Zeitpunkt und an einem bestimmten Ort entsprechen.
Evaluierung des Datensatzes: Das Ereignis 82% hat analytischen Wert; seine Genauigkeit auf Straßenebene schließt eine Lücke in den Aufzeichnungen über kleinere Katastrophen.
Um die Zuverlässigkeit des Groundsource-Datensatzes zu beurteilen,Die Studie analysiert die Daten unter drei Gesichtspunkten: Genauigkeit, räumlich-zeitliche Verteilung und Übereinstimmung mit externen Datenbanken.Es wurde mit zwei großen Datenbanken verglichen: dem Global Disaster Alerts and Coordination System (GDACS) und dem Dartmouth Flood Observatory (DFO).
Zur Genauigkeitsprüfung wählten die Forscher zufällig 400 Datensätze aus und überprüften die Angaben zu Zeit und Ort anhand der ursprünglichen Nachrichtenquellen. Die Ergebnisse zeigten, dass 601 Datensätze als absolut korrekt einzustufen waren (Konfidenzintervall: 951 Datensätze ± 51 Datensätze).Wenn Datensätze mit leichten Verzerrungen, die aber dennoch von analytischem Wert sind, mit einbezogen werden, können noch etwa 82% Ereignisse für die nachfolgende Analyse verwendet werden.Die verbleibenden rund 18% Fehler resultieren hauptsächlich aus Fehlern bei der räumlichen Positionierung, die durch Mehrdeutigkeiten in Ortsnamen sowie durch Fehlinterpretationen von relativen Zeitangaben wie „gestern“ und „letzte Woche“ verursacht werden.
Hinsichtlich der räumlich-zeitlichen Verteilung weist der Datensatz eine deutliche „Neuzeit-Tendenz“ auf.Wie die Abbildung unten zeigt, konzentrieren sich etwa 641 TP3T-Datensätze auf den Zeitraum zwischen 2020 und 2025, wobei allein im Jahr 2025 151 TP3T verzeichnet wurden. Dieser Trend dürfte eher das rasante Wachstum digitaler Nachrichtenmedien als eine Zunahme von Überschwemmungsereignissen selbst widerspiegeln.
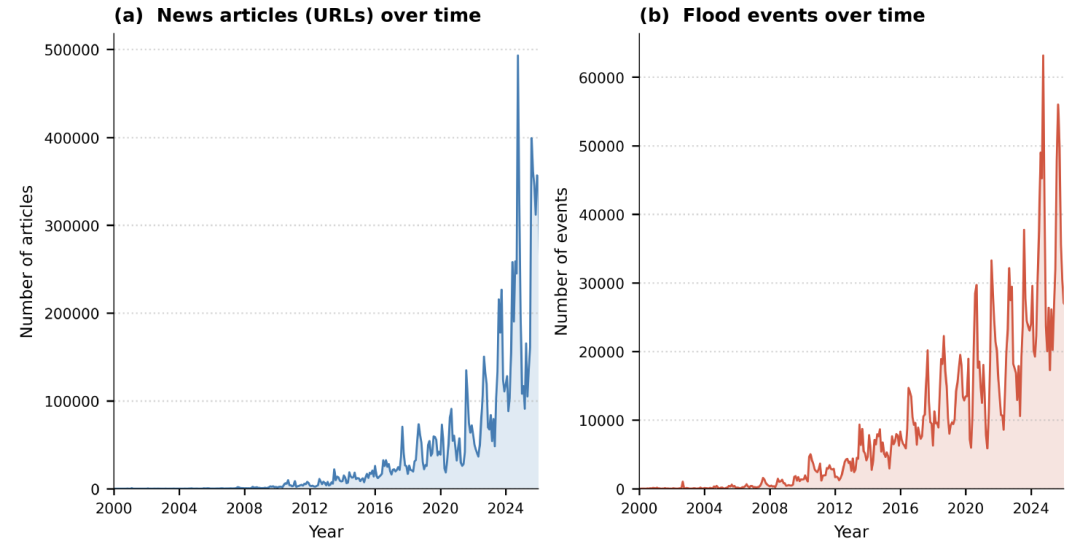
Die räumliche Verteilung wird auch vom Medienökosystem beeinflusst: In Gebieten mit intensiver Medienberichterstattung werden mehr Ereignisse erfasst, während Gebiete mit wenigen digitalen Nachrichten oder unzureichender Sprachunterstützung weniger repräsentativ sind. Dennoch zeigen die Daten deutlich, dass Regionen wie Europa, Südasien und Südostasien stark von Überschwemmungen bedroht sind.Die räumliche Verteilung stimmt weitgehend mit den vom GDACS erfassten Orten großer Überschwemmungen überein.
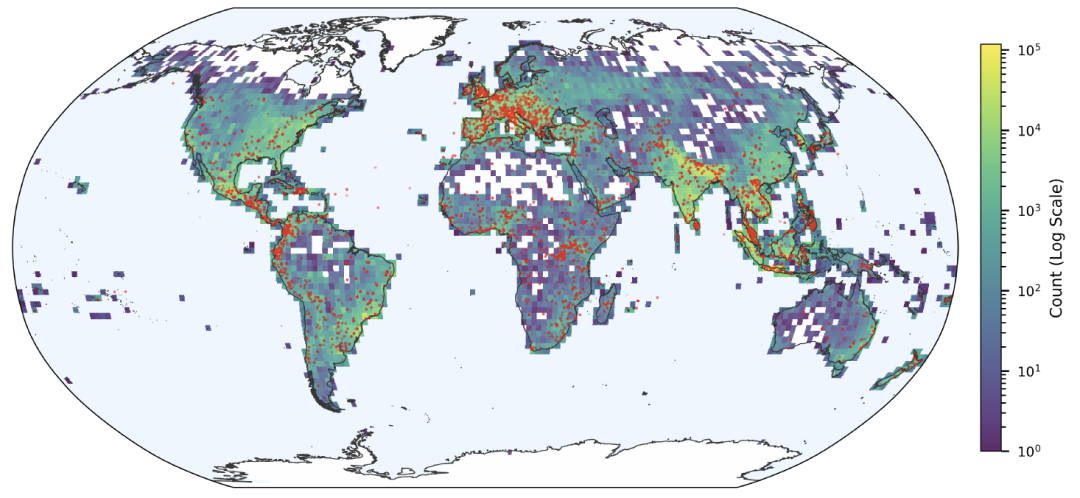
Trotz möglicher Verzerrungen in der Berichterstattung erzielt Groundsource eine außergewöhnlich gute Leistung hinsichtlich der räumlichen Auflösung.Statistiken zeigen, dass die durchschnittliche Abdeckung der erfassten Ereignisse 142 Quadratkilometer beträgt, wobei die Datensätze des 82%-Projekts weniger als 50 Quadratkilometer umfassen. Viele Ereignisse lassen sich bis auf die Ebene einzelner Häuserblöcke oder Gemeinden verfeinern und erfassen so lokale Überschwemmungen, die von herkömmlichen globalen Katastrophendatenbanken oft übersehen werden.
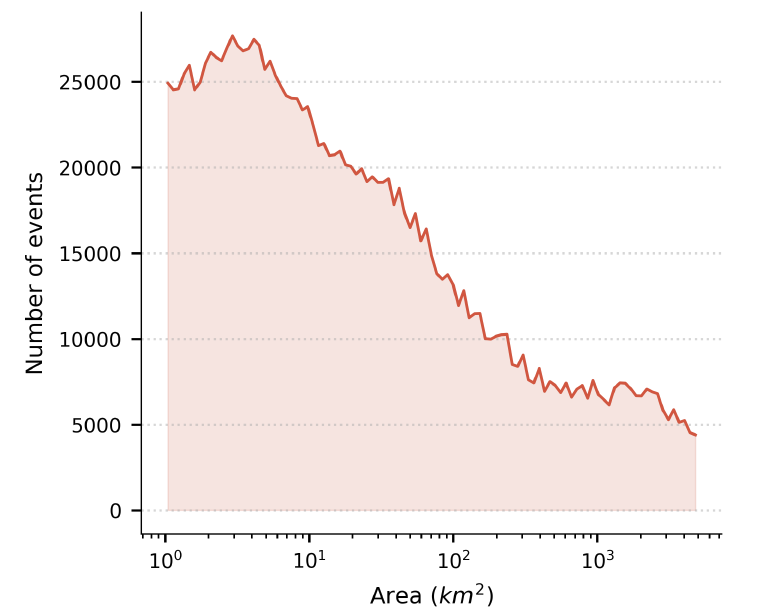
Im Rahmen der Integritätsbewertung verglich die Studie Groundsource mit dem Globalen Katastrophenwarn- und Koordinierungssystem (GDACS) und dem Dartmouth Flood Observatory (DFO) mittels raumzeitlichem Abgleich. Die Ergebnisse zeigten, dass die Trefferquote für GDACS-Ereignisse seit 2020 zwischen 851 TP3T und 1001 TP3T lag; in Regionen mit gut entwickelter Medieninfrastruktur, wie beispielsweise den Vereinigten Staaten, erreichten die Trefferquoten 961 TP3T (GDACS) bzw. 911 TP3T (DFO). Darüber hinausDie Rückrufquoten korrelieren signifikant mit der Schwere der Katastrophenauswirkungen: Die Rückrufquoten für große Überschwemmungsereignisse liegen nahe bei oder über dem Wert von 90%.
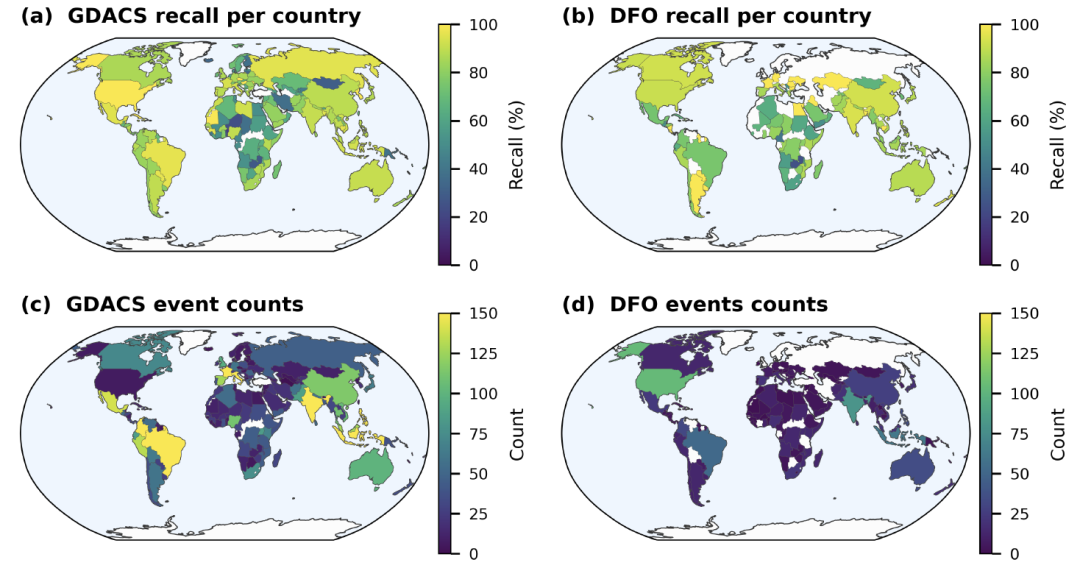
Insgesamt lässt sich sagen, dass Groundsource zwar keine perfekt ausgewogene globale Abdeckung bieten kann,Mit über 2,6 Millionen Datensätzen und einer hohen räumlichen Auflösung gleicht sie jedoch die Mängel herkömmlicher Katastrophendatenbanken bei der Erfassung kleinräumiger und lokaler Überschwemmungsereignisse aus.Dies stellt eine neue Datenquelle für die globale Hochwasserforschung dar.
KI-gestützte Hochwasserdatenforschung
Die Extraktion standardisierter Informationen über Hochwasserereignisse aus unstrukturierten Texten mithilfe großer Sprachmodelle entwickelt sich zunehmend zu einer wichtigen Methode im Bereich der Hochwasserforschung.
In der akademischen Forschung haben viele Teams diese Richtung kontinuierlich erforscht. Forscher am MIT haben eine verbesserte Strategie für Hinweiswörter und eine Methode zur Kontextassoziation vorgeschlagen, um die Probleme der zeitlichen und der Ortsnamen-Mehrdeutigkeit zu lösen, die bei großen Sprachmodellen bei der Extraktion von Hochwasserereignissen häufig auftreten.Durch die Feinabstimmung des Modells mithilfe historischer hydrologischer Beobachtungsdaten verbesserte das Team die Genauigkeit der Extraktion von Hochwasserereignisdaten auf über 80% und entwickelte ein mehrsprachiges Anpassungsmodul, das es dem Modell ermöglicht, Nachrichtentexte in verschiedenen Sprachen stabiler zu verarbeiten und so einen Hochwasserereignisdatensatz zu erstellen, der mehrere Regionen abdeckt.
Titel des Beitrags: Erzeugung physikalisch konsistenter Satellitenbilder für Klimavisualisierungen
Link zum Artikel:
https://ieeexplore.ieee.org/document/10758300
Das Forschungsteam der National University of Singapore hat die Anwendungsbereiche seiner Forschung weiter ausgedehnt.Das Team kombinierte historische Hochwasserereignisse, die mithilfe von KI aus Nachrichtenberichten extrahiert wurden, mit Daten des städtischen Entwässerungsnetzes und hochpräzisen topografischen Informationen, um ein Hochwasserrisikobewertungsmodell im urbanen Maßstab zu erstellen.Durch die Analyse des Zusammenhangs zwischen Häufigkeit und Ausmaß von Überschwemmungen in verschiedenen Regionen und der städtischen Infrastruktur können Forscher potenzielle Risikogebiete genauer identifizieren und gezieltere Empfehlungen für die städtische Hochwasserschutzplanung geben. Sie versuchen außerdem, die sich verändernden Trends zukünftiger Hochwasserrisiken unter extremen Klimabedingungen abzuschätzen.
Titel des Papers: Vorhersage heftiger Überschwemmungen mit übertragbarer KI in datenarmen Regionen
Link zum Artikel:
https://www.cell.com/the-innovation/fulltext/S2666-6758(24)00090-0
Die Fortschritte der zugehörigen Forschung haben sich auch auf die Industrie ausgeweitet.Microsoft Research hat sich mit der NASA zusammengetan, um Hydrology Copilot zu entwickeln, eine KI-gestützte Plattform zur Vorhersage von Hochwasserrisiken.Dieses System integriert Hochwasserereignisdaten aus Nachrichtenberichten, Satellitenfernerkundungsinformationen und hydrologischen Echtzeitdaten und nutzt maschinelle Lernmodelle, um die Wahrscheinlichkeit des Auftretens von Hochwasser und das potenzielle Ausmaß der Auswirkungen vorherzusagen. Die Plattform wird derzeit in den Vereinigten Staaten und mehreren anderen Ländern erprobt, um lokale Katastrophenschutzbehörden bei der Verbesserung ihrer Hochwasserwarn- und Reaktionsverfahren zu unterstützen.
Insgesamt entwickelt sich die automatische Extraktion von Hochwasserereignisinformationen aus Nachrichtentexten zunehmend zu einer wichtigen Ergänzung traditioneller Beobachtungsdaten. Mit der kontinuierlichen Verbesserung der Modellleistung und des Datenumfangs dürfte diese Methode eine umfassendere und höher aufgelöste Datengrundlage für die globale Hochwasserrisikoforschung liefern.
Referenzlinks:
1.https://www.geekwire.com/2025/microsoft-nasa-ai-hydrology-copilot-floods








