Command Palette
Search for a command to run...
Wöchentlicher Bericht Von AI Paper | Red Team-Tests Von Sprachmodellen / Multi-View-3D-Punktverfolgungsmethoden / Framework Für Das Lernen Von Proteindarstellungen / Neues Framework Zur Erkennung Von Kryptografie-Schwachstellen …

In den letzten Jahren wurden verschiedene Methoden eingesetzt, um 3D-Punktverfolgung aus monokularen Videos zu erreichen. Da es jedoch schwierig ist, 3D-Informationen in anspruchsvollen Szenarien wie Okklusion und komplexen Bewegungen genau abzuschätzen, kann die Leistung dieser Methoden den hohen Anforderungen an Präzision und Robustheit praktischer Anwendungen noch immer nicht gerecht werden.
Auf dieser Grundlage haben die ETH Zürich und die Carnegie Mellon University gemeinsam die erste datengesteuerte Multi-View-3D-Punktverfolgungsmethode vorgeschlagen, die darauf abzielt, beliebige Punkte in dynamischen Szenen mithilfe mehrerer Kameraperspektiven zu verfolgen. Das Feedforward-Modell dieser Methode prognostiziert entsprechende 3D-Punkte direkt mit nur einer kleinen Anzahl von Kameras und ermöglicht so ein robustes und genaues Online-Tracking.
Link zum Artikel:https://go.hyper.ai/2BSGR
Neueste KI-Artikel:https://go.hyper.ai/hzChC
Um mehr Benutzer über die neuesten Entwicklungen im Bereich der künstlichen Intelligenz in der Wissenschaft zu informieren, wurde auf der offiziellen Website von HyperAI (hyper.ai) jetzt der Bereich „Neueste Artikel“ eingerichtet, in dem täglich hochmoderne KI-Forschungsartikel aktualisiert werden.Hier sind 5 beliebte KI-Artikel, die wir empfehlenGleichzeitig haben wir auch die Mindmap der Papierstruktur für alle zusammengefasst. Werfen wir einen kurzen Blick auf die KI-Spitzenleistungen dieser Woche ⬇️
Die Zeitungsempfehlung dieser Woche
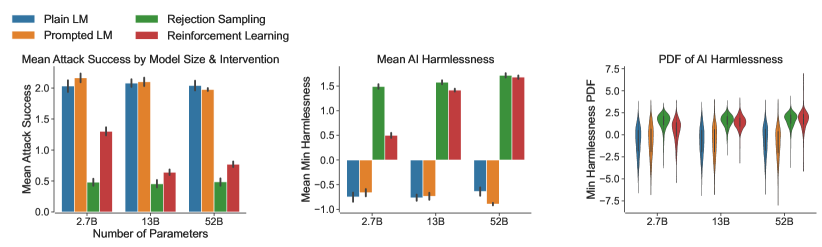
1. Red Teaming-Sprachmodelle zur Schadensminderung: Methoden, Skalierungsverhalten und gewonnene Erkenntnisse
Dieses Dokument beschreibt erste Arbeiten zum Red-Team-Testen von Sprachmodellen mit dem Ziel, potenziell schädliche Modellausgaben gleichzeitig zu identifizieren, zu messen und zu minimieren. Die Studie ergab, dass der Schwierigkeitsgrad von Red-Team-Tests für RLHF-Modelle mit zunehmender Skalierung deutlich zunimmt, während andere Modelltypen keine signifikanten Skalierungstrends aufweisen. Das Dokument veröffentlicht außerdem einen Datensatz mit 38.961 Red-Team-Angriffsbeispielen und beschreibt das Anweisungsdesign, den Ausführungsprozess, die statistischen Methoden und die damit verbundenen Unsicherheitsfaktoren, die bei Red-Team-Tests verwendet werden.
Link zum Artikel:https://go.hyper.ai/j2U2u
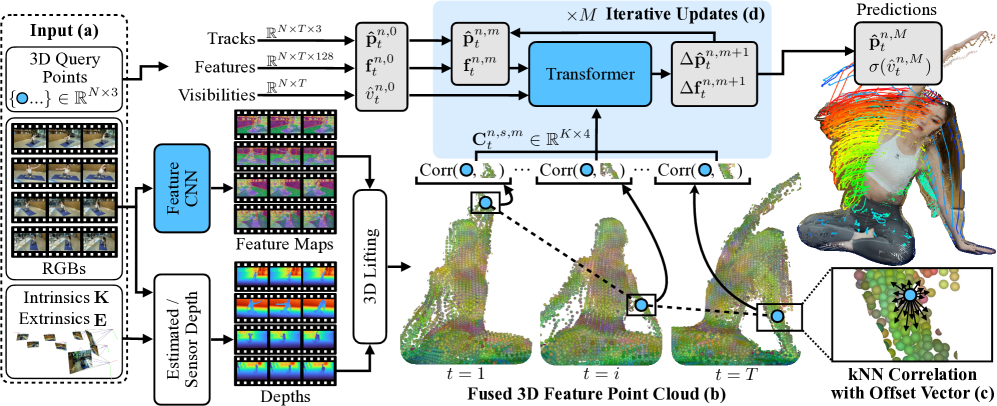
2. Multi-View 3D-Punktverfolgung
Dieses Dokument stellt die erste datengesteuerte 3D-Punktverfolgungsmethode mit mehreren Ansichten vor, die für die Verfolgung beliebiger Punkte in dynamischen Szenen mithilfe mehrerer Kameraansichten entwickelt wurde. Die Methode zeigt eine gute Generalisierung für eine Vielzahl von Videoszenarien, von 1 bis 8 Ansichten, aus unterschiedlichen Beobachtungswinkeln und mit Bildlängen von 24 bis 150.
Link zum Artikel:https://go.hyper.ai/2BSGR
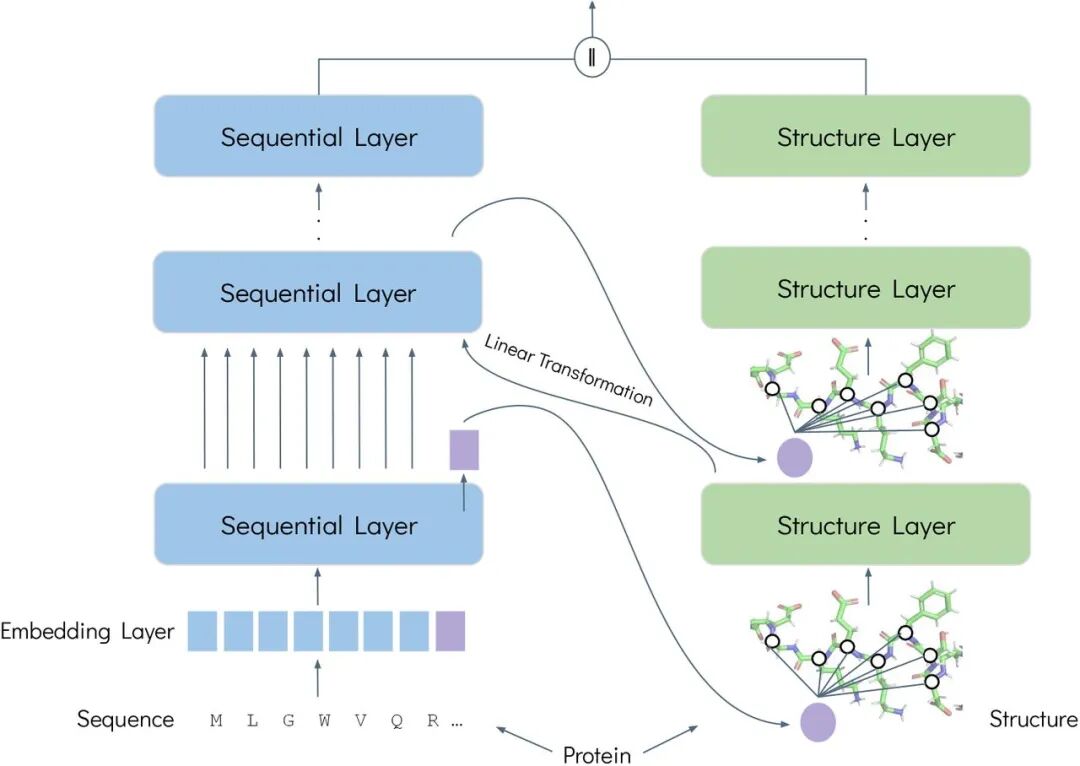
3. FusionProt: Fusion von Sequenz- und Strukturinformationen für das einheitliche Lernen von Proteindarstellungen
Dieser Artikel stellt ein neuartiges Framework zum Erlernen der Proteinrepräsentation vor: FusionProt. Ziel ist es, gleichzeitig eine einheitliche Darstellung der eindimensionalen Sequenz und der dreidimensionalen Struktur eines Proteins zu erlernen. FusionProt führt einen innovativen lernbaren Fusionstag als adaptive Brücke ein und ermöglicht so den iterativen Informationsaustausch zwischen Proteinsprachenmodellen und dreidimensionalen Proteinstrukturgraphen.
Link zum Artikel:https://go.hyper.ai/rjbaU
4. Warum Sprachmodelle halluzinieren
Dieser Artikel geht davon aus, dass der grundlegende Grund für Halluzinationen bei Sprachmodellen darin liegt, dass ihre Trainings- und Evaluierungsmechanismen eher Raten belohnen als Unsicherheiten berücksichtigen. Darüber hinaus werden die statistischen Ursachen von Halluzinationen in modernen Trainingsprozessen analysiert. Halluzinationen bleiben bestehen, da Sprachmodelle in den meisten Evaluierungsmethoden auf „hervorragende Testergebnisse“ optimiert werden und Raten unter Unsicherheit die Testleistung tatsächlich verbessert. Diese systematische Bestrafung unsicherer Antworten legt nahe, dass die aktuellen, verzerrten Benchmark-Bewertungsmethoden überarbeitet werden sollten, anstatt zusätzliche Metriken zur Bewertung von Halluzinationen einzuführen.
Link zum Artikel:https://go.hyper.ai/7TIjt

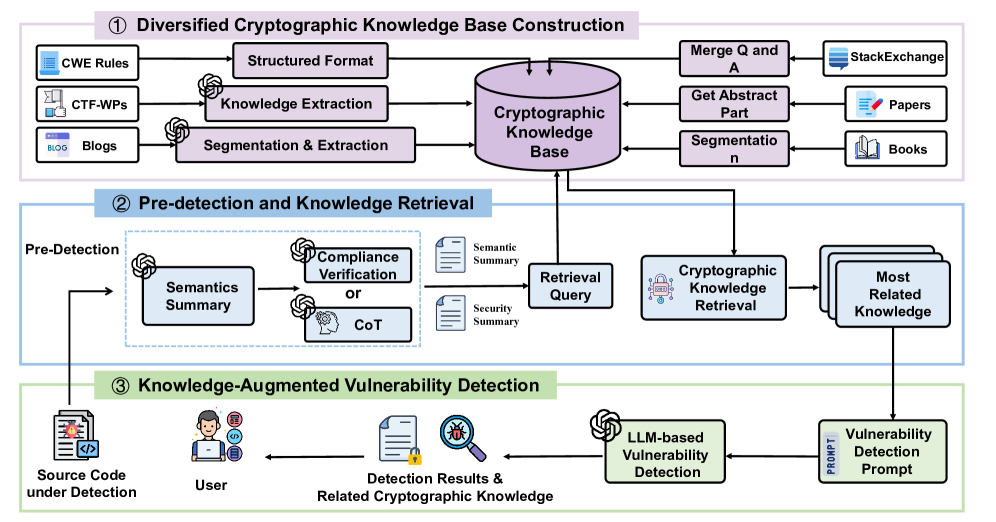
5. CryptoScope: Nutzung großer Sprachmodelle zur automatisierten Erkennung von Schwachstellen in der kryptografischen Logik
In diesem Dokument wird ein neues LLM-basiertes Framework zur automatischen Erkennung von Kryptografie-Schwachstellen namens CryptoScope vorgeschlagen, das die Chain of Thought (CoT)-Hinweistechnik mit Retrieval-Augmented Generation (RAG) kombiniert und auf einer sorgfältig kuratierten Kryptografie-Wissensdatenbank mit mehr als 12.000 Einträgen basiert.
Link zum Artikel:https://go.hyper.ai/qkboy
Dies ist der gesamte Inhalt der Papierempfehlung dieser Woche. Weitere aktuelle KI-Forschungsarbeiten finden Sie im Bereich „Neueste Arbeiten“ auf der offiziellen Website von hyper.ai.
Wir freuen uns auch über die Einreichung hochwertiger Ergebnisse und Veröffentlichungen durch Forschungsteams. Interessierte können sich im NeuroStar WeChat anmelden (WeChat-ID: Hyperai01).
Bis nächste Woche!








