Command Palette
Search for a command to run...
Wöchentlicher KI-Bericht: Rekursive Inferenzmethoden, Leichte Decoderarchitekturen, Architekturen Tiefer Convolutional Neural Networks Und Mehr – Ein Blick Auf Die Neuesten Entwicklungen in Mehreren Bereichen

Das langfristige Ziel sprachbasierter Agenten ist es, durch Erfahrung kontinuierlich zu lernen und sich zu optimieren, um letztendlich die menschliche Leistung bei komplexen realen Aufgaben zu übertreffen. Das Training von Agenten mithilfe von Reinforcement Learning, das ausschließlich auf empirischen Daten basiert, bleibt jedoch in vielen Umgebungen eine Herausforderung, in denen überprüfbare Belohnungssignale fehlen (z. B. bei Webseiteninteraktionen) oder eine ineffiziente langfristige Trajektorienwiedergabe erforderlich ist (z. B. bei mehreren Runden der Tool-Nutzung). Daher verlassen sich die meisten aktuellen Agenten immer noch auf überwachte Feinabstimmung mithilfe von Expertendaten, ein Ansatz, der schwer skalierbar ist und unter mangelnder Generalisierung leidet.
Um diese Einschränkung zu überwinden, schlugen das Meta Superintelligence Lab, Meta FAIR und die Ohio State University gemeinsam ein Kompromissparadigma namens „Early Experience“ vor. Dieses Paradigma nutzt Interaktionsdaten, die durch das eigene Verhalten des Agenten generiert werden, wobei zukünftige Zustände als Überwachungssignale dienen, anstatt sich auf Belohnungssignale zu verlassen. Dieses Paradigma legte eine solide Grundlage für nachfolgendes Verstärkungslernen und machte es zu einer praktikablen Brücke zwischen Imitationslernen und vollständig erfahrungsgesteuerten Agenten.
Link zum Artikel:https://go.hyper.ai/a8Zkn
Neueste KI-Artikel:https://go.hyper.ai/hzChC
Um mehr Benutzer über die neuesten Entwicklungen im Bereich der künstlichen Intelligenz in der Wissenschaft zu informieren, wurde auf der offiziellen Website von HyperAI (hyper.ai) jetzt der Bereich „Neueste Artikel“ eingerichtet, in dem täglich hochmoderne KI-Forschungsartikel aktualisiert werden.Hier sind 5 beliebte KI-Artikel, die wir empfehlen, werfen wir einen kurzen Blick auf die bahnbrechenden KI-Errungenschaften dieser Woche ⬇️
Die Zeitungsempfehlung dieser Woche
1. Weniger ist mehr: Rekursives Denken mit winzigen Netzwerken
In diesem Artikel wird das Tiny Recursive Model (TRM) vorgestellt, eine einfachere rekursive Inferenzmethode, die HRM in der Generalisierung deutlich übertrifft und ausschließlich auf einem winzigen zweischichtigen neuronalen Netzwerk basiert. Mit nur 7 Millionen Parametern erreicht TRM eine Testgenauigkeit von 451 TP3T bei der ARC-AGI-1-Aufgabe und 81 TP3T bei der ARC-AGI-2-Aufgabe. Damit übertrifft TRM die Leistung der meisten großen Sprachmodelle (wie Deepseek R1 und o3-mini), während weniger als 0,011 TP3T der Parameter dieser Modelle verwendet werden.
Link zum Artikel:https://go.hyper.ai/bUZ6M
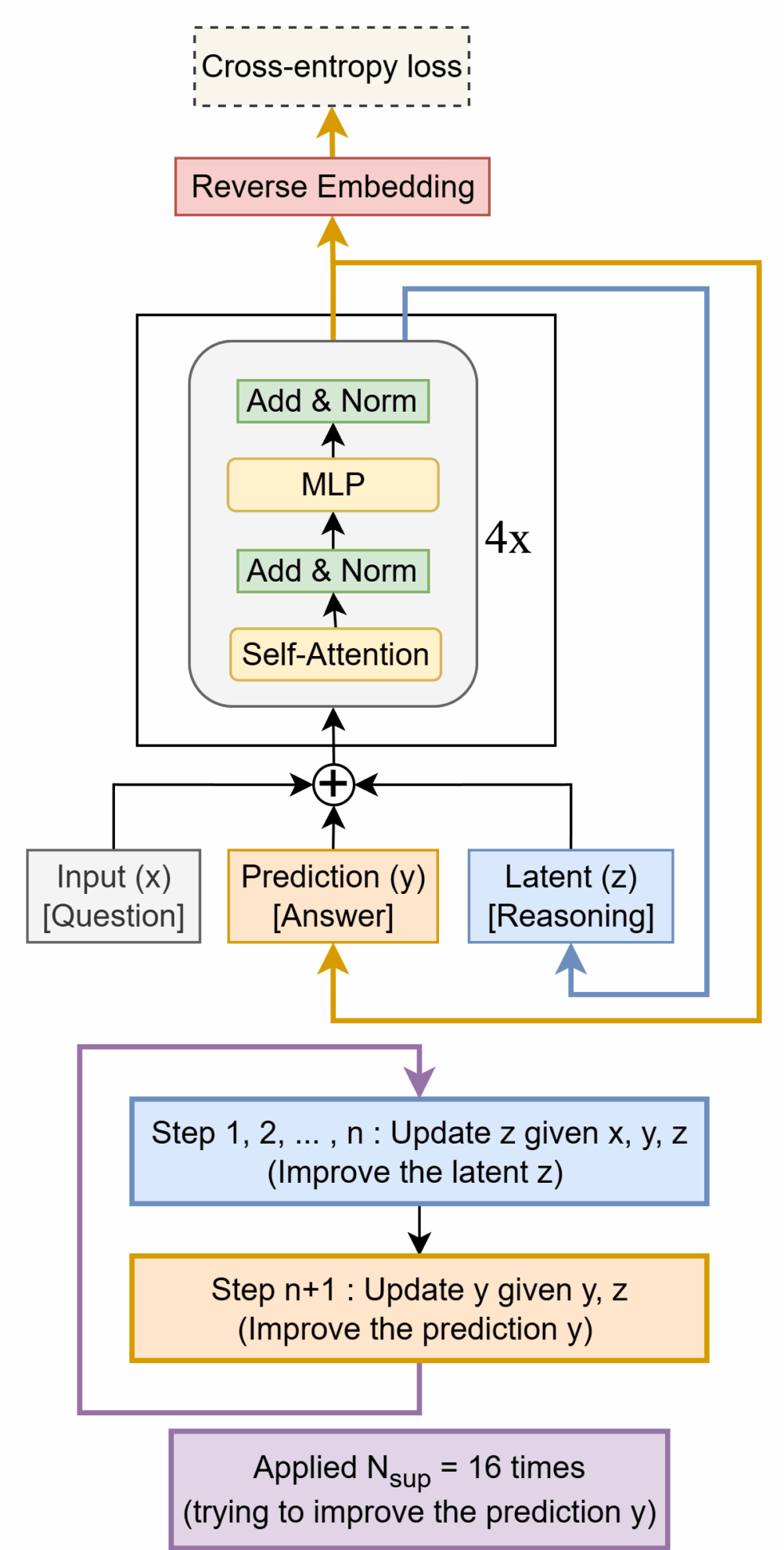
2. PromptCoT 2.0: Skalierung der Promptsynthese für LLM-Argumentation
Dieses Papier stellt PromptCoT 2.0 vor, ein skalierbares Framework, das handgefertigte heuristische Regeln durch eine iterative Erwartungs-Maximierungs-Schleife (EM) ersetzt, um die Prompt-Konstruktion durch iterative Optimierung des Inferenzprozesses zu steuern. Dieser Ansatz generiert Fragen, die nicht nur anspruchsvoller, sondern auch vielfältiger sind als bisherige Korpora.
Link zum Artikel:https://go.hyper.ai/jKAmy
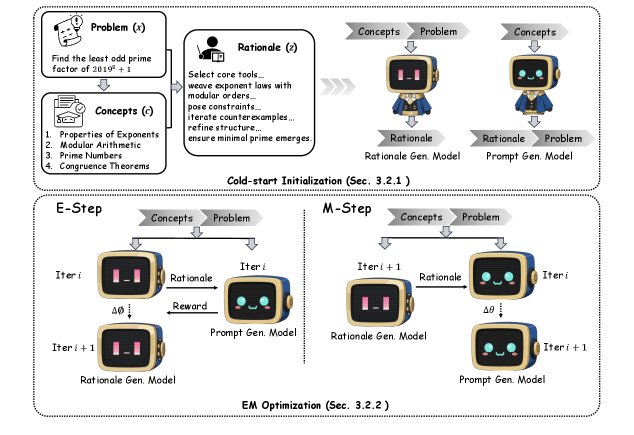
3. Auf der Suche nach Lerninhalten: Token-weises dynamisches Gating für die ressourcenarme Vision-Language-Modellierung
In diesem Artikel wird eine leichtgewichtige Decoderarchitektur mit drei Hauptdesigns vorgeschlagen: (1) ein dynamischer Gating-Mechanismus auf Token-Ebene, um eine adaptive Fusion von Sprache und visuellen Hinweisen zu erreichen; (2) ein Merkmalsmodulations- und Kanalaufmerksamkeitsmechanismus, um die Nutzungseffizienz begrenzter visueller Informationen zu maximieren; und (3) ein zusätzliches Kontrastlernziel, um die visuellen Lokalisierungsfähigkeiten zu verbessern.
Link zum Artikel:https://go.hyper.ai/D178P
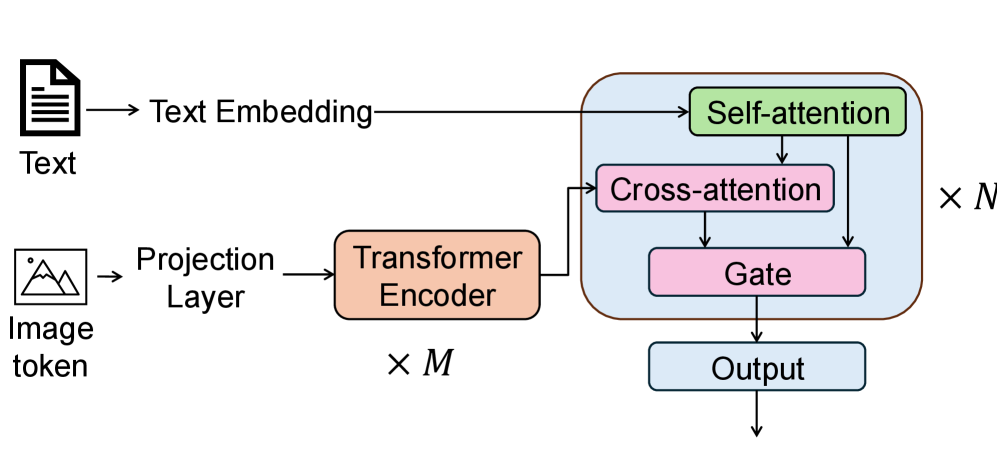
4. Agentenlernen durch frühe Erfahrungen
Die meisten aktuellen intelligenten Agenten basieren noch immer auf überwachter Feinabstimmung mithilfe von Expertendaten. Dieser Ansatz ist jedoch schwer skalierbar und weist eine unzureichende Generalisierung auf. Diese Einschränkung liegt in der Natur von Expertendemonstrationen: Sie decken nur eine begrenzte Anzahl von Szenarien ab, was zu einer unzureichenden Vielfalt der dem Agenten ausgesetzten Umgebungen führt. Um diese Einschränkung zu überwinden, schlägt dieses Papier ein Kompromissparadigma vor: „Early Experience“. Dabei werden Interaktionsdaten verwendet, die der Agent durch sein eigenes Verhalten generiert, wobei zukünftige Zustände als Überwachungssignale dienen, ohne dass auf Belohnungssignale zurückgegriffen wird.
Link zum Artikel:https://go.hyper.ai/a8Zkn
5. Xception: Deep Learning mit tiefenweise trennbaren Faltungen
Dieses Papier stellt Xception vor, eine neuartige Architektur für tiefe Convolutional-Neural-Networks, die von Inception inspiriert ist und bei der das Inception-Modul durch tiefenseparierbare Convolutions ersetzt wurde. Da die Xception-Architektur die gleiche Anzahl an Parametern wie Inception V3 aufweist, ist die Leistungsverbesserung nicht auf eine Erhöhung der Modellkapazität zurückzuführen, sondern auf eine effizientere Nutzung der Modellparameter.
Link zum Artikel:https://go.hyper.ai/0BUt5
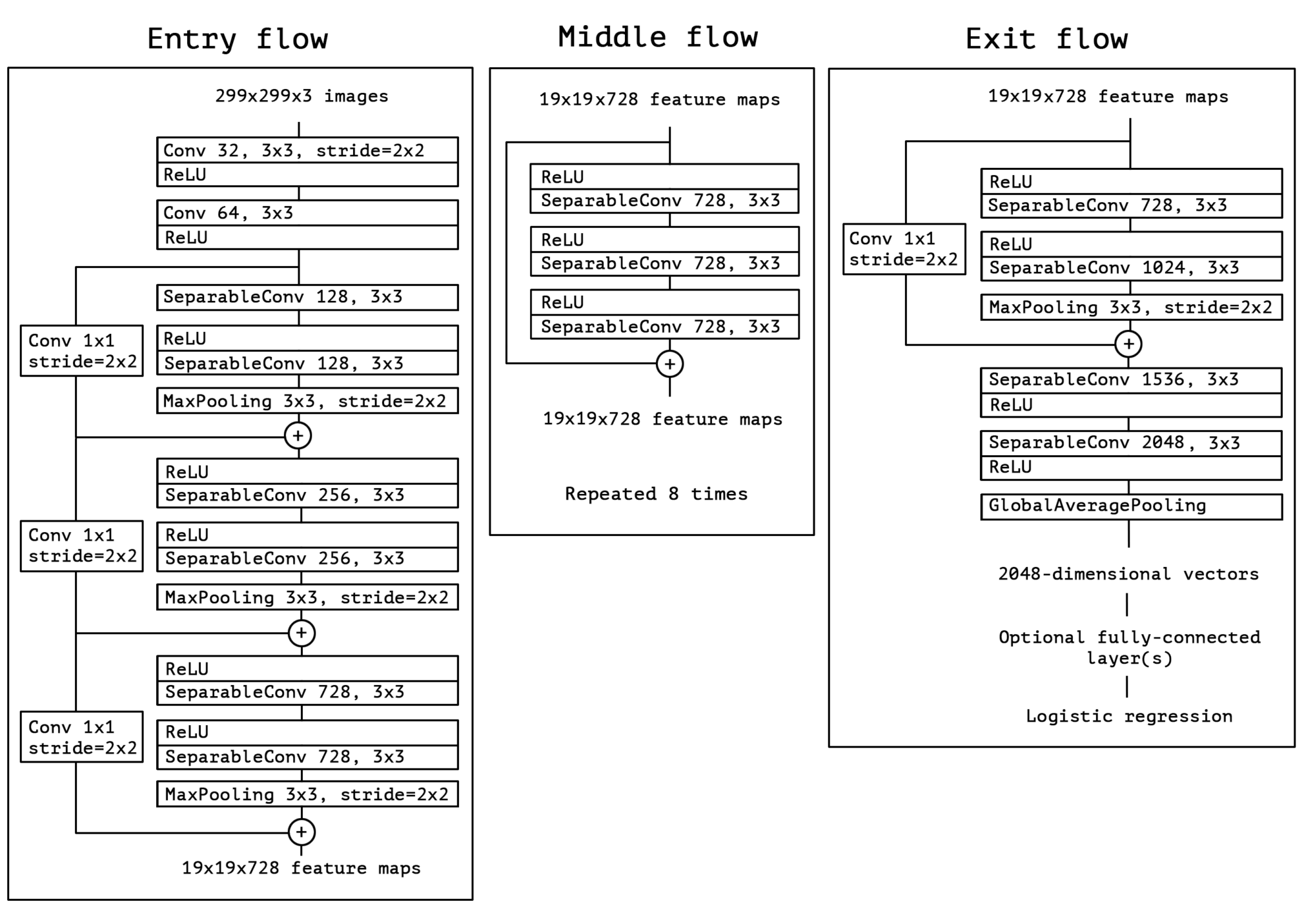
Dies ist der gesamte Inhalt der Papierempfehlung dieser Woche. Weitere aktuelle KI-Forschungsarbeiten finden Sie im Bereich „Neueste Arbeiten“ auf der offiziellen Website von hyper.ai.
Wir freuen uns auch über die Einreichung hochwertiger Ergebnisse und Veröffentlichungen durch Forschungsteams. Interessierte können sich im NeuroStar WeChat anmelden (WeChat-ID: Hyperai01).
Bis nächste Woche!








