Command Palette
Search for a command to run...
SEER Ist Nur Der Anfang? Das US-amerikanische NIH Hat Ein Dokument Herausgegeben, Das Chinesischen Nutzern Den Zugriff Auf Zentrale Biomedizinische Daten Verbietet, Und Es Gibt Inländische Datenbanken

Am 5. April verbreitete sich die Nachricht, dass „die SEER-Datenbank für chinesische Benutzer verboten ist“, wie ein Lauffeuer in der heimischen akademischen Welt.
Eine offizielle Antwort-E-Mail, die ein Doktorand der Universität Heidelberg erhielt, wurde von vielen Medien nachgedruckt. Darin hieß es eindeutig: „Ab dem 4. April 2025 werden die National Institutes of Health Forschern und Institutionen aus bestimmten Ländern den Zugriff auf alle laufenden Projekte untersagen, die das National Institutes of Health CADRS und damit verbundene Daten betreffen, und diese Projekte beenden.“Zu diesen konkreten Ländern zählen China (einschließlich Hongkong und Macau), Russland, Iran, Nordkorea, Kuba und Venezuela.“
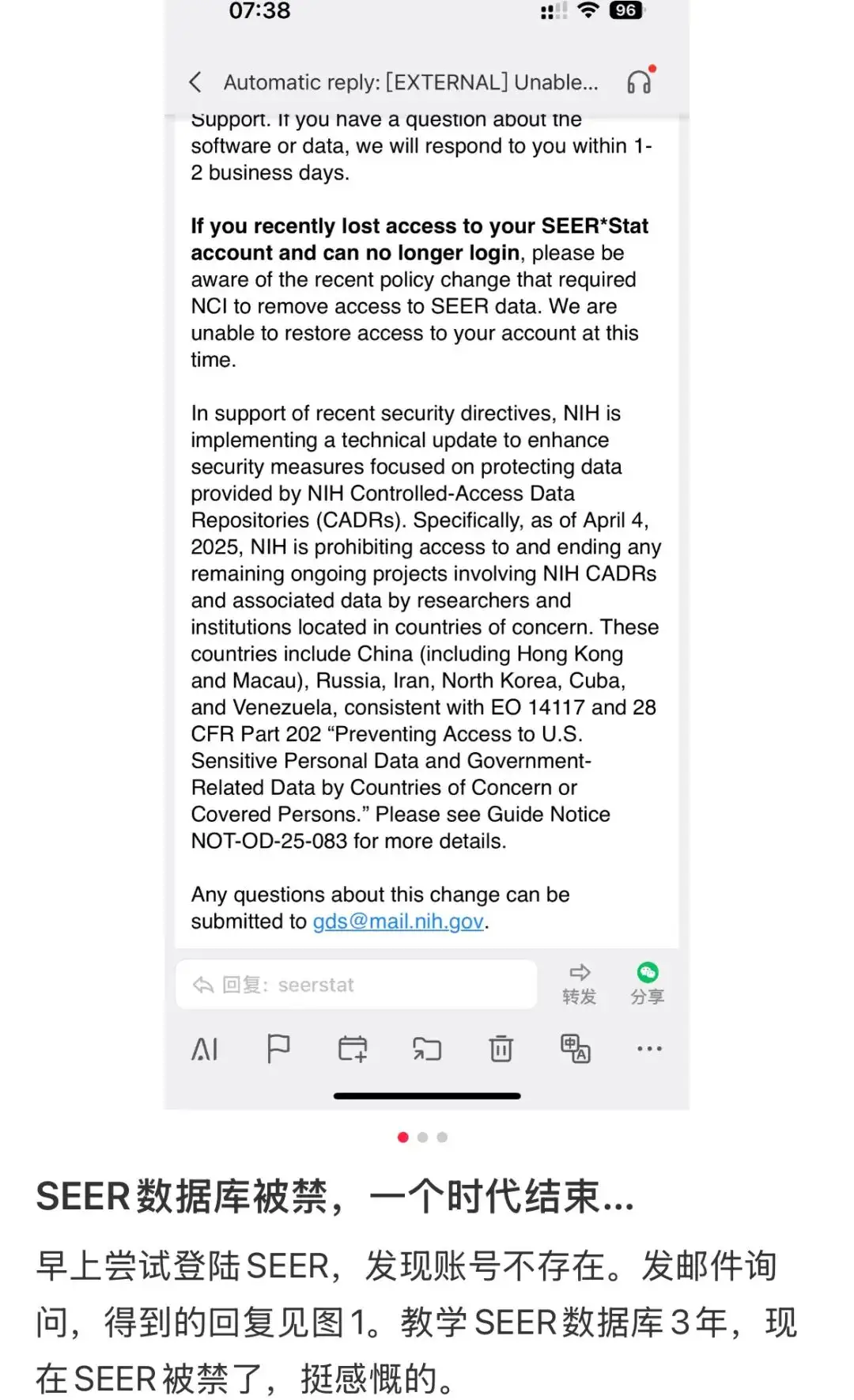
Tatsächlich haben die National Institutes of Health (NIH) der Vereinigten Staaten am 2. April Ortszeit eine Mitteilung herausgegeben.Es wurde angekündigt, dass Institutionen in betroffenen Ländern ab dem 4. April (Ortszeit) der Zugriff auf die NIH-Datenbank mit kontrolliertem Zugriff und die zugehörigen Daten untersagt sein wird.
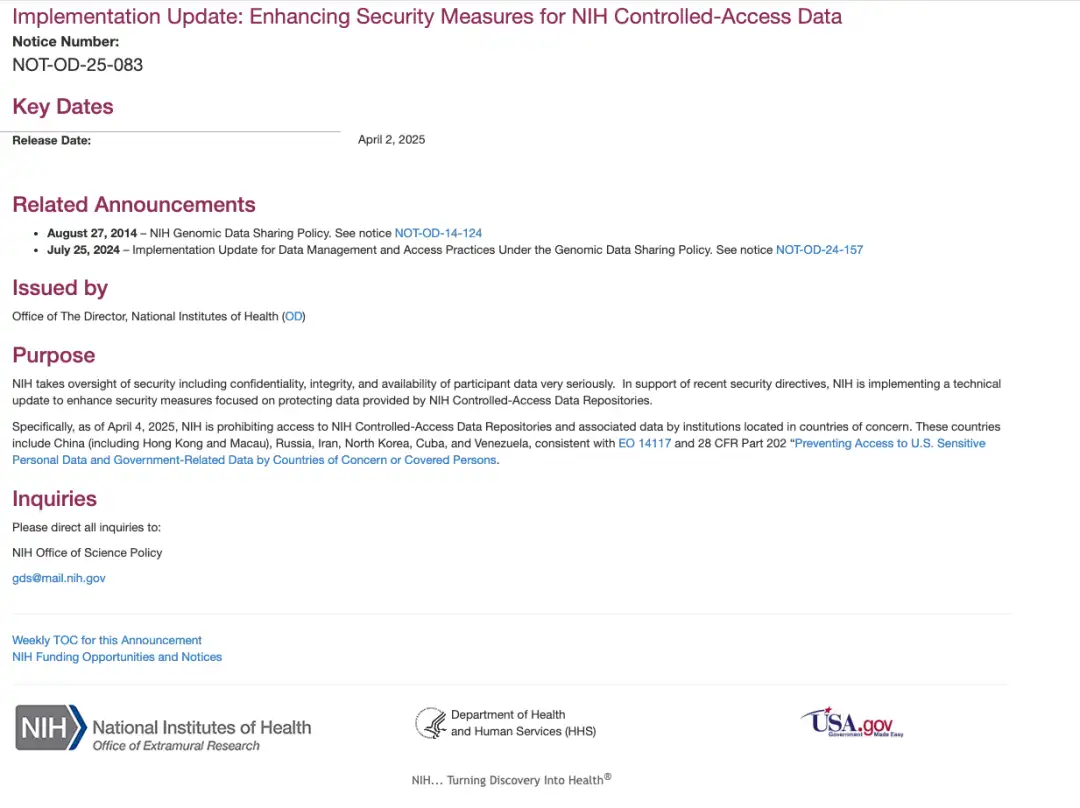
Die in der Mitteilung erwähnte Executive Order Nr. 14117 wurde im Februar 2024 erlassen. Die US-Regierung erließ eine „Executive Order zur Verhinderung des Zugriffs bestimmter Länder auf große Mengen sensibler personenbezogener Daten von US-Bürgern und auf Daten der US-Regierung“. Wie der Name schon sagt, wird sechs „bedenklichen Ländern“ wie China, Russland und dem Iran der Zugriff auf „große Mengen sensibler personenbezogener Daten und regierungsbezogener Daten“ von US-Bürgern untersagt.

Unter allen „sensiblen Daten“ sind bioinformatische Daten am stärksten betroffen.

Ein wissenschaftlicher Kalter Krieg könnte beginnen
Ein Jahr nach Erlass der Durchführungsverordnung hatte diese endlich Auswirkungen auf den akademischen Bereich, der sich für Offenheit und Grenzenlosigkeit einsetzt. Als erster Schuss des NIH ist der Einfluss von SEER offensichtlich.
SEER ist ein statistisches Krebsdatensystem, das vom National Cancer Institute (NCI) der Vereinigten Staaten entwickelt und gepflegt wird.Seit ihrer Inbetriebnahme im Jahr 1973 hat sie sich zu einer der maßgeblichsten und am häufigsten genutzten epidemiologischen Datenbanken für Krebs weltweit entwickelt und deckt etwa 481.000.000 Menschen der US-Bevölkerung ab. Die Daten umfassen grundlegende Informationen wie Alter, Geschlecht, Diagnosezeitpunkt, Diagnoseinformationen wie Krebsart, pathologische Klassifizierung und Stadieneinteilung, Behandlungsinformationen wie Operation, Strahlentherapie/Chemotherapie und Nachsorgeinformationen wie Überlebenszeit und Überlebensstatus. Es besteht kein Zweifel, dass diese Datenbank einen äußerst hohen Forschungswert in den Bereichen Tumorepidemiologie, öffentliche Gesundheit und Prognosemodelle hat.
Zwar ist mit dem Verbot der SEER-Datenbank bereits das letzte Wort gesprochen, dennoch sind viele namhafte Datenbanken weiterhin in Gefahr.
Als wichtigste medizinische Forschungseinrichtung in den Vereinigten Staaten verfügt das NIH über 27 Institute und Zentren, die sich auf verschiedene Krankheitsbereiche konzentrieren.Unter ihnen pflegt das NCI, das sich auf die Krebsforschung konzentriert, nicht nur die SEER-Datenbank, sondern verwaltet auch den Cancer Genome Atlas TCGA (The Cancer Genome Atlas). Das National Institute of General Medical Sciences (NIGMS), das sich auf die biologische Grundlagenforschung konzentriert, ist für die Pflege der Proteindatenbank Protein Data Bank verantwortlich. Die US-amerikanische National Library of Medicine (NLM) besitzt die weltweit führende medizinische Literaturdatenbank PubMed. Das US-amerikanische National Center for Biotechnology Information (NCBI) besitzt die Genotyp-Phänotyp-Datenbank dbGaP …
Die oben genannten, häufig verwendeten, hochwertigen Datenbanken gehören alle dem NIH. Mit anderen Worten: Der Zugriff auf sie alle ist chinesischen Benutzern untersagt. Vielleicht ist es nur eine Frage der Zeit. Datenbeschränkungen führen einerseits zu einseitigen Forschungsergebnissen und erhöhen andererseits den Schwierigkeitsgrad und die Dauer der Forschung. Dies war zweifellos ein Alarmsignal für die heimische wissenschaftliche Forschungsgemeinschaft. Neben der aktiven Förderung der Zusammenarbeit mit ausländischen Teams ist der Aufbau einer international repräsentativen „China-Datenbank“ von großer Bedeutung.
Aktiver Aufbau einer lokalen Datenbank
Es besteht keine Notwendigkeit, näher auf die Bedeutung von Daten für die wissenschaftliche Forschung einzugehen. Ob es sich um traditionelle wissenschaftliche Forschung oder um die heutige KI für die Wissenschaft handelt, es ist eine wichtige Unterstützung für Forschungsergebnisse. Insbesondere im biologischen und medizinischen Bereich ist die Datenerfassung schwieriger. Daher warnten einige Forscher bereits nach Erlass der Executive Order Nr. 14117, dass bei hochfrequenten Daten wie der Datenbank des National Center for Biotechnology Information (NCBI) und dem Cancer Genome Atlas (TCGA) die Gefahr einer Zugriffsbeschränkung bestehe.
Ein Branchenkenner erklärte in einem Interview mit DeepTech: „Um das Problem des eingeschränkten Zugriffs auf diese Datenbank zu lösen, gibt es meiner Meinung nach mehrere Ansätze, die einen Versuch wert sind. Erstens könnten chinesische Wissenschaftler einen gemeinsamen Appell starten und Konsultationen mit den USA abhalten, um mögliche Lösungen zu prüfen, wie beispielsweise die Umstellung der Datenbank auf ein kostenpflichtiges System. Zweitens könnten wir mit Drittländern zusammenarbeiten, für die der Zugriff nicht eingeschränkt ist. Und schließlich ist der wichtigste Punkt, dass China schnellstmöglich eine eigene Datenbank aufbauen muss.“Wenn wir erst einmal unsere eigene Datenbank aufgebaut haben, verfügen wir bei Verhandlungen mit den Amerikanern über ein besseres Verhandlungsinstrument. Wir können zum Beispiel darüber diskutieren, ob beide Seiten ihre Datenbanken füreinander öffnen und einen gegenseitigen Austausch erreichen sollten.“
Obwohl es kurzfristig immer noch schwierig ist, SEER vollständig zu ersetzen, wurden durch die Ansammlung inländischer biowissenschaftlicher und medizinischer Datenbanken über einen langen Zeitraum hinweg gewisse Ergebnisse erzielt, und einige Datenbanken können bis zu einem gewissen Grad als Ergänzung dienen.
Das National Genome Science Data Center konzentriert sich beispielsweise auf den Aufbau von Datenbanksystemen und Datenressourcen rund um Genomdaten von Menschen, Tieren, Pflanzen und Mikroorganismen.Derzeit haben wir die BioProject-Datenbank zum Austausch von Informationen zu biologischen Forschungsprojekten, das globale biologische Datenbankverzeichnis Database Commons, die Genomvariationsdatenbank Genome Variation Map (GVM), die Literaturbibliothek für Biowissenschaften OpenLB usw. erstellt.
* Offizielle Website:https://ngdc.cncb.ac.cn/
Das National Center for Bioinformatics hat derzeit 69,9 PB an inländischen Daten und 7,75 PB an internationalen Daten gesammelt.Seine bioinformatische Datenbankplattform umfasst Daten wie Genom, RNA-Sequenz, Epigenom usw. Zu den häufig verwendeten Datenbanken gehören die öffentliche Archivdatenbank für Gesamtgenomdaten mehrerer Arten (Genome Warehouse, GWH), die Ressourcenbibliothek zum Teilen von Informationen zu biologischen Proben_Biological Sample Database (BioSample) usw.
*Offizielle Website:https://www.cncb.ac.cn/
Die von der Shenzhen National GeneBank (CNGB) erstellte Plattform China National GeneBank DataBase (CNGBdb)Bereitstellung von Proben biologischer genetischer Ressourcen sowie Bereitstellung von Diensten zum Informationsaustausch und zur Anwendung,Unterstützen Sie die Datenübertragung und -archivierung, computergestützte Analyse, Wissensabfrage und Entwicklung wissenschaftlicher Datenbanken.
Gemeinsam mit dem Spatiotemporal Omics Consortium (STOC) hat es das räumlich-zeitliche Datenportal STOmicsDB (Spatial Transcript Omics DataBase) eingerichtet.Die Standards und Systeme zur räumlichen Archivierung von Transkriptomdaten wurden etabliert und unterstützen eine Reihe großer wissenschaftlicher Projekte, darunter den Mouse Embryonic Development Spatiotemporal Transcriptome Atlas (MOSTA). Über STOmicsD können Benutzer eine Vielzahl von Datentypen übermitteln, darunter Rohsequenzierungsdaten, räumliche Transkriptommatrizen, Anmerkungsdateien, Bildinformationen sowie Datenanalysen und Visualisierungen von nachgelagerten Analyseergebnissen.
Auch,Das von ihm erstellte Zellgruppen-Datenportal CDCP (Cell-omics Data Coordinate Platform),Es hat die Integration und Standardisierung mehrdimensionaler zytogenomischer Daten erreicht, eine Reihe großer wissenschaftlicher Projekte wie den Non-Human Primate Cell Atlas (NHPCA) unterstützt und Forschern auf der ganzen Welt eine hocheffiziente Plattform zur Zusammenarbeit bei zytogenomischen Daten bereitgestellt.
Das von ihm initiierte Genomics Data Portal widmet sich der Integration und dem Austausch globaler Biodiversitätsdaten.Durch die Einführung großer wissenschaftlicher Programme wie dem Earth BioGenome Project (EBP) und MEER (Mariana Trench Environmental and Ecological Research) stellen wir Forschern auf der ganzen Welt umfangreiche genomische Datenressourcen im Bereich der Biodiversität zur Verfügung.
Abschluss
Heute sind Wissenschaft und Technologie zum wichtigsten Schauplatz des Wettbewerbs zwischen den Großmächten geworden. Insbesondere angesichts der rasanten Entwicklung der KI scheint das Konzept der wissenschaftlichen Forschung ohne Grenzen nicht mehr praktikabel zu sein. In den letzten Jahren wurden jedoch in vielen Bereichen durch unabhängige Kontrolle und inländische Substitution Erfolge erzielt. Während Offenheit und Win-Win-Kooperationen gefordert und die internationale Zusammenarbeit gefördert werden, ist es noch dringlicher, den Aufbau lokaler Datenbanken zu stärken.
Quellen:








