Command Palette
Search for a command to run...
Das Tsinghua-Forschungsteam Sammelte Mehr Als 20 Räumlich-zeitliche Datensätze Und Über 130 Millionen Stichprobenpunkte Und Schlug Drei Methoden Zur Modellierung Komplexer Städtischer Systeme Vor, Die Auf Generativer KI Basieren

Michael Batty, bekannt als einer der Pioniere der Erforschung urbaner komplexer Systeme, sagte einmal in seinem Buch:„Städte sind im Wesentlichen komplexe adaptive Systeme, deren Strukturen und Funktionen sich ständig weiterentwickeln und ein hohes Maß an Nichtlinearität und selbstorganisierenden Eigenschaften aufweisen.“Mit der kontinuierlichen Entwicklung moderner Städte nimmt die Komplexität städtischer Systeme von Tag zu Tag zu.
Diese Komplexität macht den Umgang mit herkömmlichen Modellierungsmethoden schwierig. Mit der Entwicklung der generativen KI-Technologie wird die generative Modellierung als aufstrebendes technisches Mittel allmählich zu einem wichtigen Werkzeug für die Untersuchung und das Verständnis städtischer Systeme. Generative Modelle komplexer Stadtsysteme können nicht nur die Entwicklung städtischer Strukturen simulieren, sondern auch innovative Stadtplanungslösungen generieren und neue Ideen für intelligente Städte und nachhaltige Entwicklung liefern.
Mit Schwerpunkt auf China hat die Forschung zu generativen Modellen urbaner komplexer Systeme in den letzten Jahren erhebliche Fortschritte gemacht, und viele Universitäten und Forschungsinstitute haben fruchtbare Forschungsergebnisse vorgelegt.
Kürzlich wurde im COSCon'24 AI for Science-Forum, das gemeinsam von HyperAI und HyperAI veranstaltet wurde,Ding Jingtao, Postdoktorand am Urban Science and Computing Research Center der Abteilung für Elektrotechnik der Tsinghua-Universität, hielt eine Rede mit dem Titel „KI-gesteuerte Modellierung urbaner komplexer Systeme und Gesetzesentdeckung“.Er erläuterte allen ausführlich die räumlich-zeitliche generative Modellierungsmethode komplexer Stadtsysteme und die neuesten Forschungsfortschritte des Teams.
HyperAI Super Neural hat diesen ausführlichen Bericht von Dr. Ding Jingtao zusammengestellt und zusammengefasst, ohne die ursprüngliche Absicht zu verletzen. Das Folgende ist eine Abschrift der Rede.
Konzentrieren Sie sich auf die generative Modellierung komplexer städtischer Systeme und entdecken Sie Datenverteilungsmuster
Die Forschung unseres Teams in den Bereichen Smart Cities und Urban Computing konzentriert sich auf die Modellierung komplexer urbaner Systeme.Als komplexes System ähnelt die Stadt der Funktionsweise der Natur in einem Ökosystem. Menschen leben in ihr und interagieren in mehreren Dimensionen mit dem städtischen System, wodurch komplexe Interaktionen entstehen. Beispielsweise wurden im Zuge des Städtebaus verschiedene Netzwerksysteme wie Transportnetze, Kommunikationsnetze und Stromversorgungsnetze gebildet. Netzwerkelemente auf der physischen Ebene sind mit sozialen Elementen des menschlichen Lebens verflochten, was die Komplexität städtischer Systeme weiter verschärft.

Als Reaktion darauf konzentriert sich die Forschung unseres Teams hauptsächlich auf die folgenden drei Arten von Problemen:
(1) Das Problem der Vorhersage der Stadtstaatsentwicklung,Das heißt, wir achten auf die Richtung und den Prozess der zukünftigen Stadtentwicklung, da die Stadtentwicklung im Wesentlichen ein Prozess dynamischer Veränderungen in Raum und Zeit ist, was ein typisches Raum-Zeit-Vorhersageproblem darstellt.
(2) Das Problem der Simulation und Ableitung urbaner Elemente,Ähnlich wie beim Konzept des digitalen Zwillings oder Metaversums wird eine digitale Umgebung anhand realer Daten erstellt und auf dieser Grundlage Schlussfolgerungen gezogen, um das „Was wäre wenn“-Problem in hypothetischen Szenarien zu lösen;
(3) Problem der Optimierung der Entscheidungsfindung in der Stadtverwaltung,Basierend auf der oben erwähnten Vorhersage der städtischen Entwicklung und der Simulationsableitung können städtische Governance-Entscheidungen optimiert werden, um spezifische städtische Probleme wie Verkehrsstaus und Naturkatastrophen zu lösen.
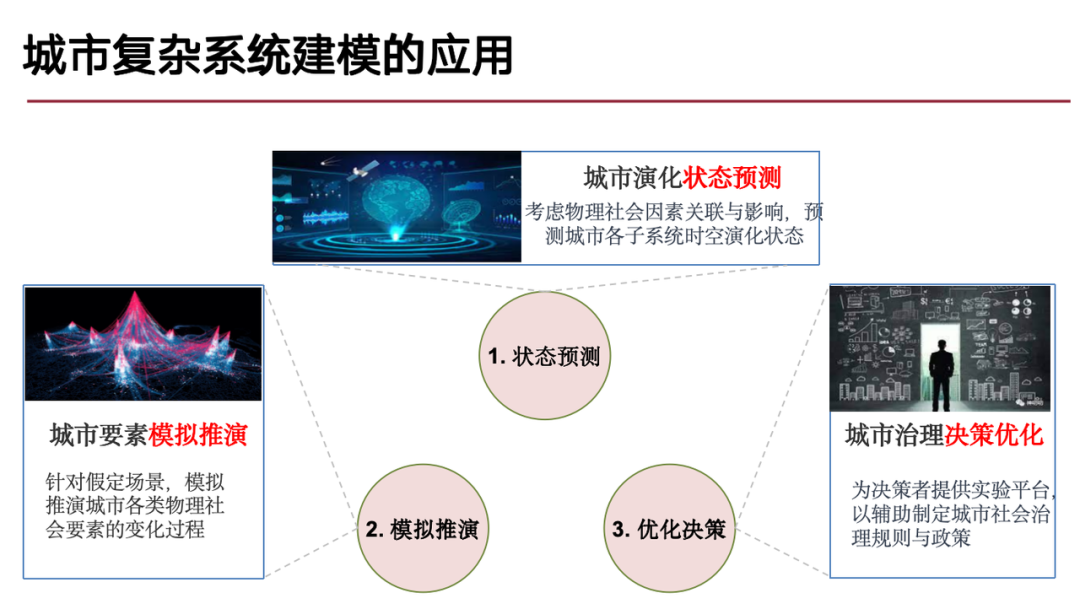
Der aktuelle Forschungsschwerpunkt unseres Teams liegt auf der generativen Modellierung komplexer urbaner Systeme.Der Kern des generativen Modells besteht darin, die Wahrscheinlichkeitsverteilung hinter den Daten zu lernen, dh die Wahrscheinlichkeitsverteilung basierend auf den Beobachtungsdaten zu modellieren und den Datengenerierungsprozess zu erfassen.Wenn das Modell über diese Fähigkeit verfügt, kann es die oben genannten drei Arten von Problemen effektiv lösen.
Einführung generativer KI-Methoden zur Lösung von Modellierungsproblemen
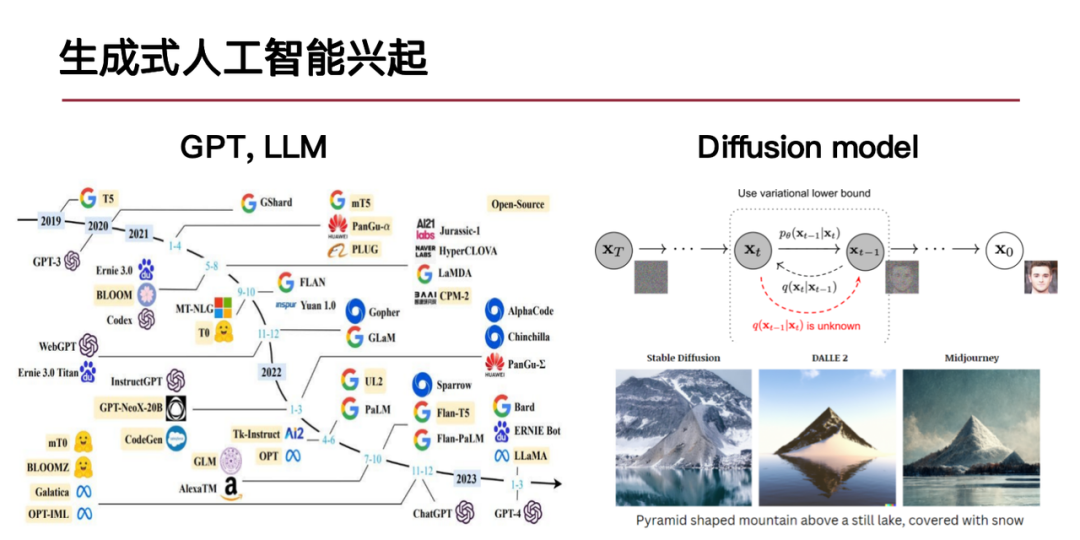
Die derzeitige rasante Entwicklung der generativen KI spiegelt sich hauptsächlich in zwei Aspekten wider: Zum einen in der Entwicklung der Sprachgenerierungstechnologie, dargestellt durch große Sprachmodelle, und zum anderen im Fortschritt der Technologie zur Generierung visueller Inhalte, dargestellt durch Diffusionsmodelle.Für die Modellierung komplexer urbaner Systeme ist die Eignung der generativen KI-Methode zum Schlüssel unserer Forschung geworden.
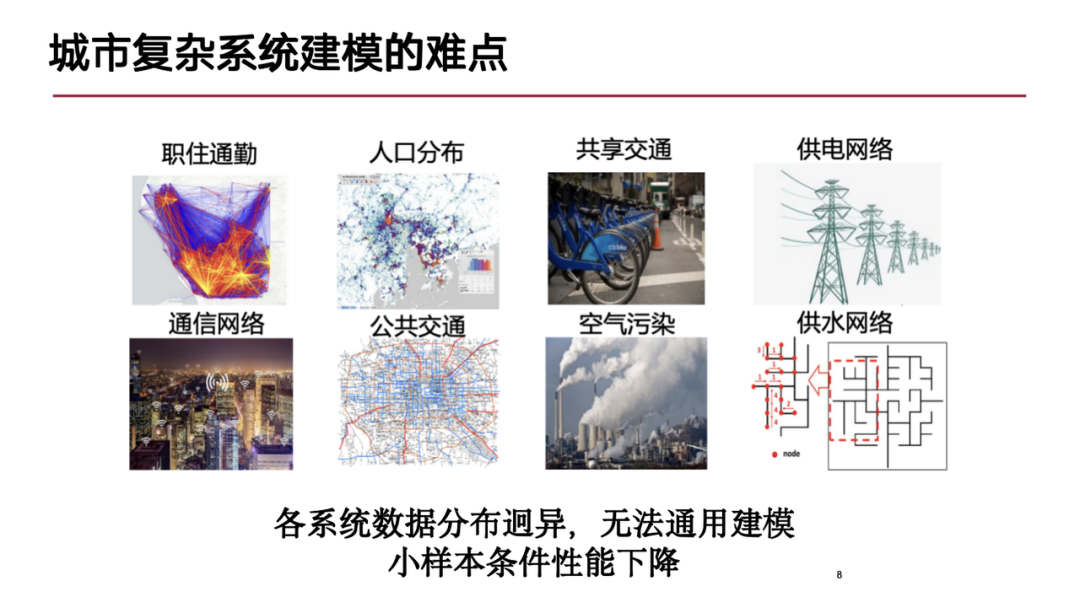
In städtischen komplexen Systemen spiegeln sich Modellierungsschwierigkeiten hauptsächlich in folgenden Aspekten wider:Nudel:Erstens weisen städtische komplexe Systeme erhebliche raumzeitliche Merkmale auf, und die Datenmodalitäten sind sehr umfangreich, einschließlich einer Vielzahl raumzeitlicher Datenformen, wie z. B. Flugbahndaten von Menschen, die sich in der Stadt bewegen. Diese Datenform ähnelt den Sequenzdaten natürlicher Daten Darüber hinaus gibt es räumlich-zeitliche Gitterdaten zur Verhinderung von Massenunfällen und topologischen Strukturen in Städten (z. B. die durch Straßen und Geschwindigkeitsspulen gebildete Diagrammstruktur) usw. Die Mischung raumzeitlicher Daten aus diesen verschiedenen Modalitäten bringt Herausforderungen bei der Modellierung mit sich.

Zweitens ist eine Stadt aus der Perspektive urbaner komplexer Systeme ein riesiges System, das aus mehreren Subsystemen besteht. Innerhalb dieser Subsysteme bestehen komplexe interaktive Beziehungen und es gibt bestimmte Kopplungen zwischen verschiedenen Subsystemen (z. B. Energiesystemen und Kommunikationsnetzwerksystemen). Die gegenseitige Abhängigkeit und die komplexen Wechselwirkungen dieser Teilsysteme stellen höhere Anforderungen an die Modellierung.

Schließlich ist das Innere des städtischen Systems ein dynamischer Prozess, der eine Vielzahl von Daten erfassen kann, und diese Daten haben unterschiedliche Formen, Modi und Verteilungen, was es derzeit schwierig macht, sie universell zu modellieren Forschungsphase.
Basierend auf den oben genannten Herausforderungen werde ich heute unsere Forschungsfortschritte in den folgenden drei Aspekten vorstellen:Die erste ist die Simulation des menschlichen Flusses,Wir schlagen ein Diffusionsmodell vor, das auf physikalischem Wissen basiert, um die Bewegung von Menschen in Städten genauer abzuleiten.Das zweite ist die Vorhersage der Widerstandsfähigkeit komplexer Systeme; das letzte ist das allgemeine räumlich-zeitliche Vorhersagemodell.
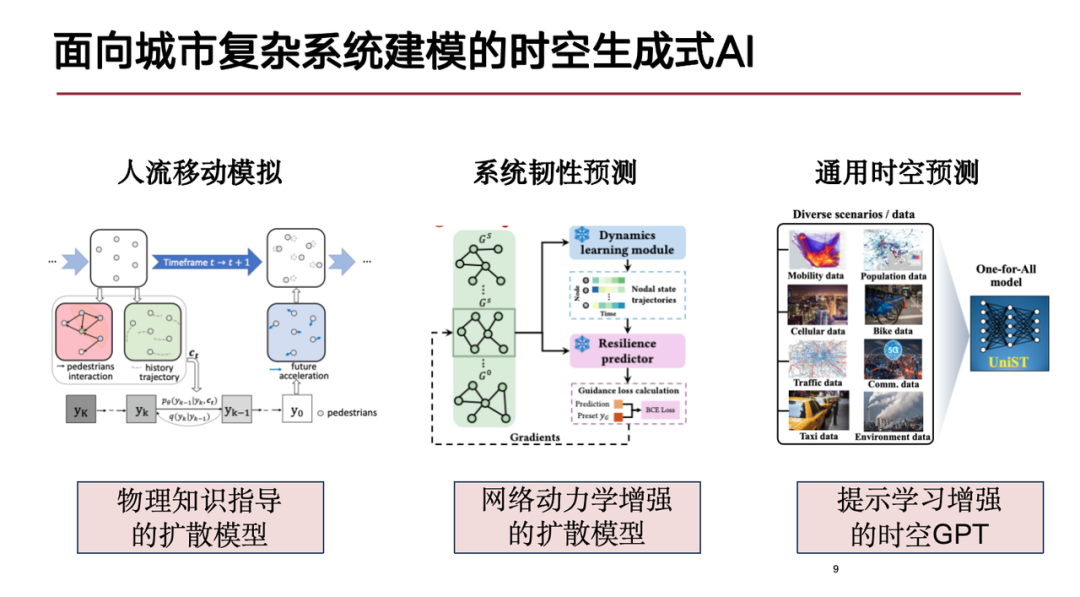
Simulation menschlicher Strömungen – Diffusionsmodell basierend auf physikalischem Wissen
Die Fußgängerbewegungssimulation zielt darauf ab, den dynamischen Bewegungs- und Interaktionsprozess einer großen Anzahl von Fußgängern im Raum zu reproduzieren. Ihr Kernproblem besteht darin, anhand des Start- und Endpunkts eines Fußgängers oder einer Person dessen Flugbahn während der Bewegung zu generieren.Diese Simulation ist in vielen Anwendungsszenarien von großem Wert, beispielsweise bei der Pfadplanung für virtuelle Charaktere (NPCs) in Spielen und der Machbarkeitsanalyse von Gebäudeentwürfen im realen Leben. Um die Leistungsfähigkeit des Architekturentwurfs in bestimmten Szenarien zu testen, ist es in der Regel notwendig, Simulationen großräumiger Fußgängerströme durchzuführen.

Die größte Herausforderung bei der Simulation menschlicher Strömungen besteht jedoch darin, dass das Simulationsobjekt kein molekulares System mit klaren physikalischen Gesetzen ist, sondern ein Individuum mit der Fähigkeit, unabhängige Entscheidungen zu treffen – ein Mensch.Menschliche Entscheidungsmechanismen sind komplex und veränderlich: Einerseits werden individuelle Vorlieben von der Umgebung beeinflusst, was zu kontinuierlichen Anpassungen bei der Entscheidungsfindung führt, andererseits ist menschliches Verhalten von Natur aus unsicher. Wenn beispielsweise verschiedene Personen mit Hindernissen konfrontiert werden, wählen sie unterschiedliche Bewältigungsstrategien (einige entscheiden sich für den Weg nach links, andere für den Weg nach rechts). Diese Unsicherheit lässt sich nur schwer mit einer deterministischen Formel beschreiben.
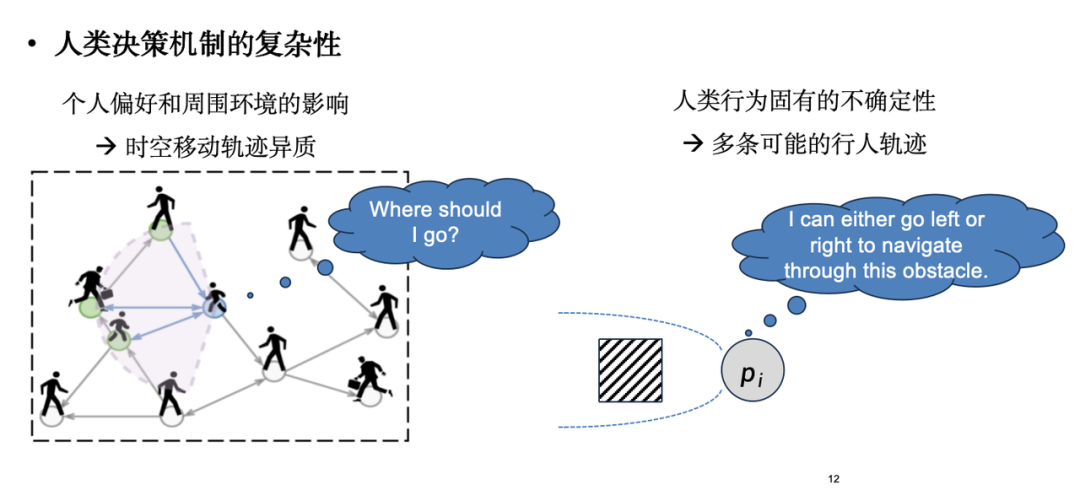
In praktischen Anwendungen ist das am weitesten verbreitete Modell zur Simulation menschlicher Strömungen das „Modell sozialer Kräfte“, das aus Ideen der Newtonschen Mechanik abgeleitet ist und eine der klassischen Methoden auf Basis von ABM (Agent-Based Modeling) darstellt.Das Modell der sozialen Kraft betrachtet die menschliche Mobilität als einen kraftgetriebenen Prozess. Wie in der folgenden Abbildung dargestellt, werden Personen, die sich bewegen, nicht nur vom Ziel angezogen, sondern auch von Hindernissen und umliegenden Fußgängern abgestoßen. Bei näherer Betrachtung zeigt sich jedoch, dass soziale Kraftmodelle nicht in der Lage sind, subtile Merkmale in realen Daten zu erfassen.

Daher untersuchen wir, wie generative KI-Technologie kombiniert werden kann.Einbringen physikalischen Wissens in Diffusionsmodelle.Der Grund für die Wahl des Diffusionsmodells liegt darin, dass der menschliche Entscheidungsmechanismus von Natur aus unsicher ist und ein probabilistischer Generierungsprozess ist. Das Diffusionsmodell eignet sich gut für die hochdimensionale Datenverteilungsmodellierung und eignet sich für die Simulation solcher unsicherer Probleme.
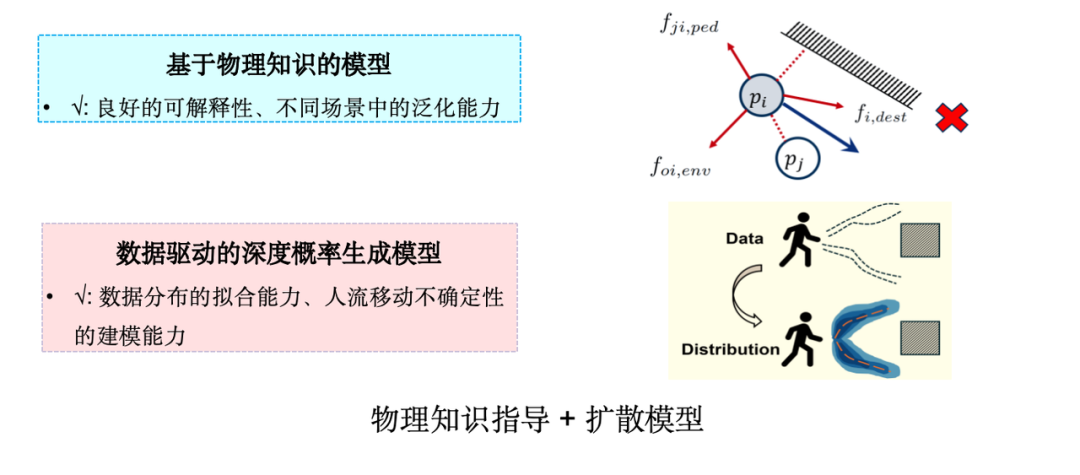
Wir haben ein graphisches neuronales Netzwerk basierend auf dem Modell der sozialen Kraft entworfen, die Anziehungs- und Abstoßungsterme der sozialen Kraft in das Modell integriert und das Simulationsmodell für menschliche Flussbewegungen SPDiff vorgeschlagen.
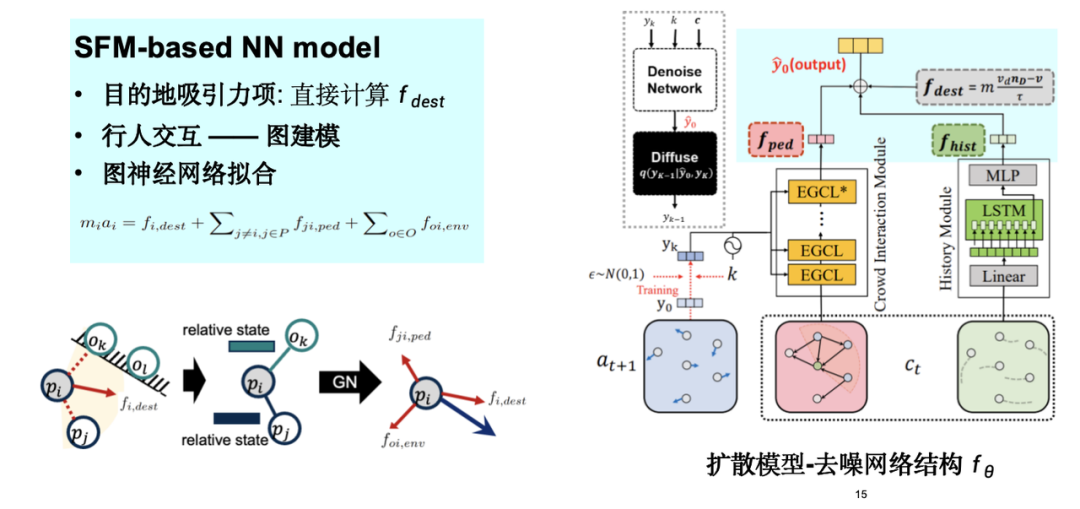
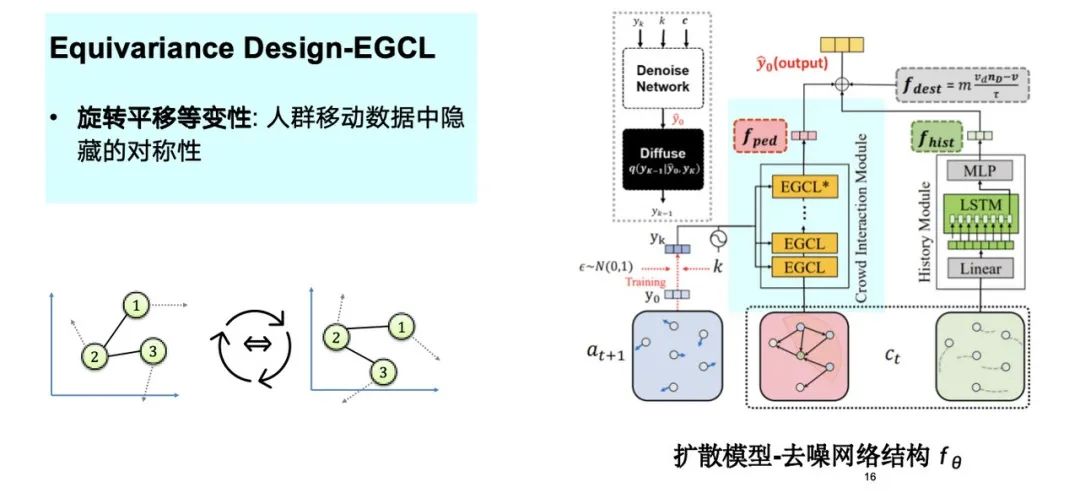
Wie in der Abbildung unten gezeigt, haben wir die verborgenen Symmetrien in den Massenbewegungsdaten – Rotation und Translation usw. – berücksichtigt und sie in den Modellentwurfsprozess integriert. Diese Injektion von induktiver Vorspannung hilft, den gesamten Simulationsprozess zu optimieren.
Wir haben einen Datensatz realer Fußgängerbewegungen ausgewählt, um die Modellleistung zu bewerten. Zu den Datenquellen gehören Überwachungsdaten von Fußgängerbewegungen auf Bahnhofsplätzen und -straßen.
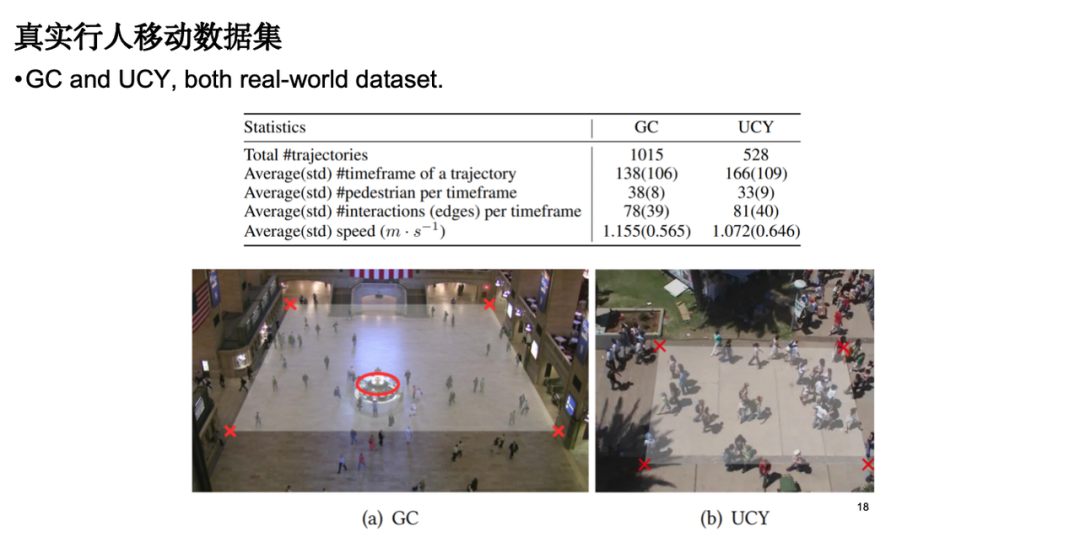
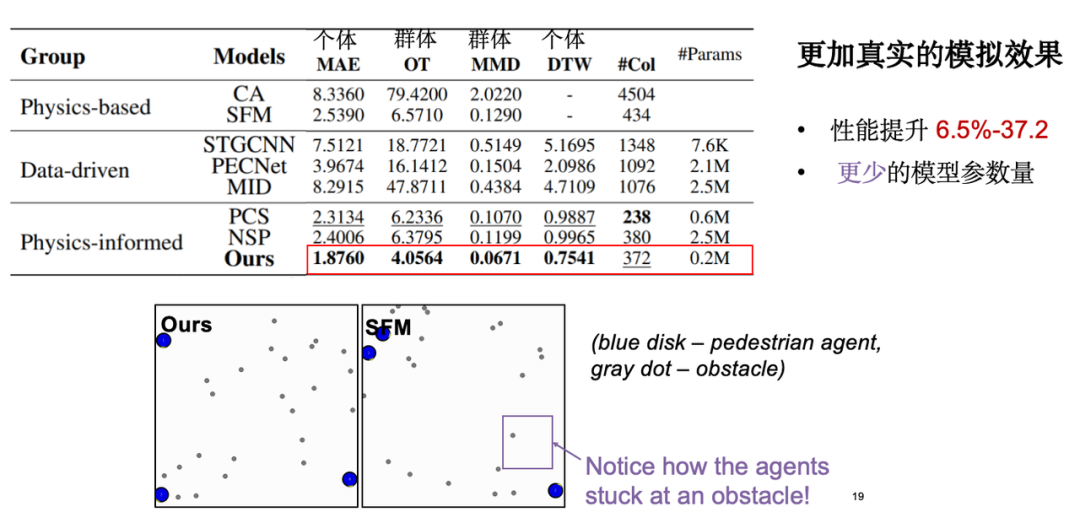
Bei der Modellbewertung konzentrieren wir uns hauptsächlich auf die folgenden Arten von Indikatoren:Der erste ist der individuelle Bewegungsfehler, also der absolute Fehler zwischen der simulierten Flugbahn und der real beobachteten Flugbahn; der zweite ist der Gruppenverteilungsindex, was bedeutet, dass man hofft, dass die simulierte Flugbahn nahe an den realen Daten liegt die Verteilungsebene. Darüber hinaus führten wir auch eine visuelle Analyse durch und die Ergebnisse zeigten, dass unser Modell im Vergleich zum klassischen Modell sozialer Kräfte eine bessere Leistung beim Hindernisvermeidungseffekt erzielte. Erwähnenswert ist, dass durch die Einführung physikalischen Wissens die Anzahl der Modellparameter erheblich reduziert und die Modelleffizienz optimiert wird.
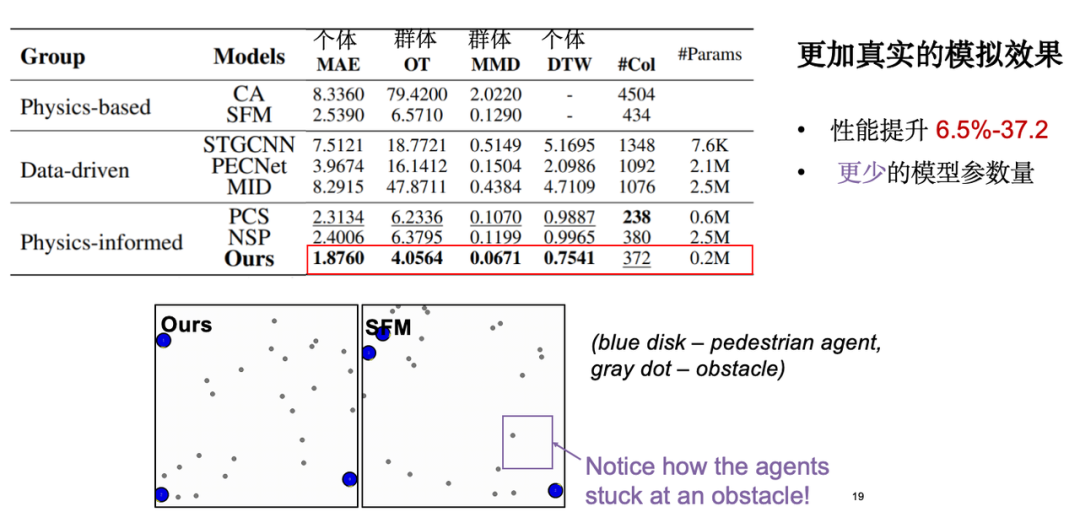
Als wir die Einführung physikalischen Wissens weiter untersuchten, stellten wir fest, dass Äquivarianz dem Modell Vorteile beim Lernen kleiner Stichproben verschafft. Wie bereits erwähnt, ist die Bewegungsbahn nach Rotation und Translation im Wesentlichen symmetrisch.Daher benötigt das Modell nur eine kleine Anzahl von Datenproben, um ein effektives Lernen durchzuführen.Experimente zeigen, dass der Modelleffekt bei einer Reduzierung der Trainingsdatenmenge auf 5% immer noch nahe an der Leistung des gesamten Datensatzes liegt.
Relevante Forschungsarbeiten mit den Titeln „Social Physics Informed Diffusion Model for Crowd Simulation“ und „Understanding and Modeling Collision Vermeidungsverhalten für realistische Crowd Simulation“ wurden in AAAI 2024 bzw. CIKM 2023 veröffentlicht, und der Code und die Daten waren Open Source.
Papieradresse:https://arxiv.org/abs/2402.06680
Adresse des Open-Source-Projekts:https://github.com/tsinghua-fib-lab/SPDiff
Papieradresse:https://dl.acm.org/doi/10.1145/3583780.3615098
Adresse des Open-Source-Projekts:https://github.com/tsinghua-fib-lab/TECRL
Vorhersage der Systemresilienz – durch Netzwerkdynamik verbessertes Diffusionsmodell
Unter Resilienz versteht man die Fähigkeit eines Systems, seine grundlegenden Systemfunktionen aufrechtzuerhalten, wenn es internen Ausfällen oder externen Störungen ausgesetzt ist.Beispielsweise bezieht sich Resilienz bei Ökosystemen auf die Fähigkeit, die biologische Vielfalt unter dem Einfluss von Umweltveränderungen aufrechtzuerhalten. In menschlichen Sozialsystemen hoffen wir, dass viele technische Systeme, wie z. B. Lieferkettennetzwerke, über eine solche Widerstandsfähigkeit verfügen, dass sie unter besonderen Umständen die normale Produktions- und Verkaufsbeziehung zwischen Produzenten und Verbrauchern gewährleisten und so den normalen Betrieb der Wirtschaft aufrechterhalten können.

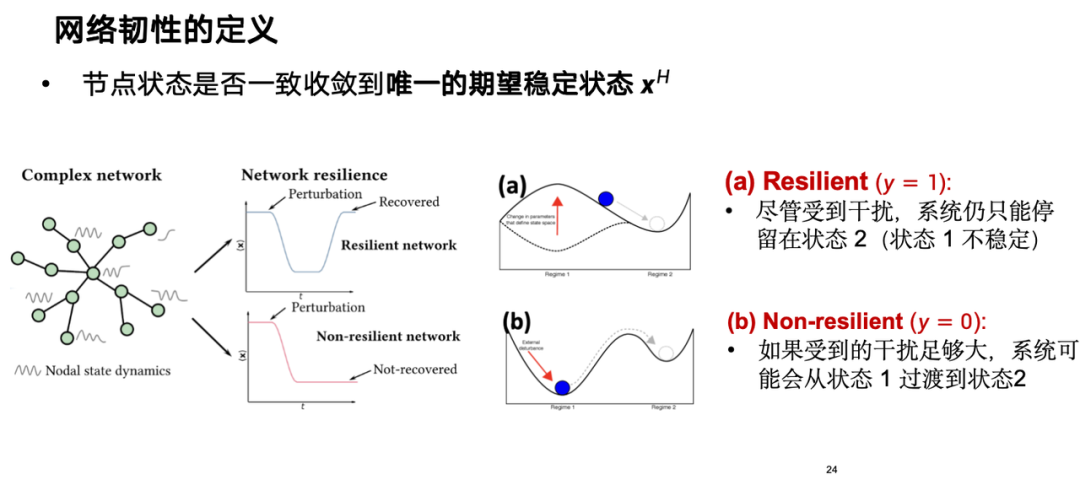
Aus theoretischer Sicht gibt es für Cyber-Resilienz einige klassische Definitionen. Resilienz kann als Knotenzustand betrachtet werden, dargestellt durch x, der widerspiegelt, ob das System nach einer Störung auf einen Knoten in den einzigen erwarteten stabilen Zustand konvergieren kann.Wenn das System belastbar ist, kann es sich innerhalb einer bestimmten Zeitspanne wieder in den erwarteten Zustand erholen, selbst wenn es gestört ist. Wie in der folgenden Abbildung dargestellt, können belastbare Systeme nach einer Störung in einen stabilen Zustand zurückkehren, während sich nicht belastbare Systeme möglicherweise nicht erholen.
Bereits 2017 schlug ein Artikel in Nature eine theoretische Modellierungsmethode vor, die im Wesentlichen ein n-dimensionales hochdimensionales System untersucht. Die Anzahl der Knoten in solchen Systemen kann Zehntausende oder sogar Millionen erreichen.Theoretisch vereinfacht diese Methode das hochdimensionale System durch Dimensionsreduktion in eine Dimension, um den Ausdruck der Systemresilienz zu erhalten.
Dieses theoretische Werkzeug weist jedoch in realen Systemen Einschränkungen auf und ist nur für Systeme geeignet, in denen Abschlüsse weniger relevant sind. In realen Systemen kommt es jedoch häufig zu einem Iso-Sortiment-Effekt, d .
Papieradresse:https://www.nature.com/articles/nature16948
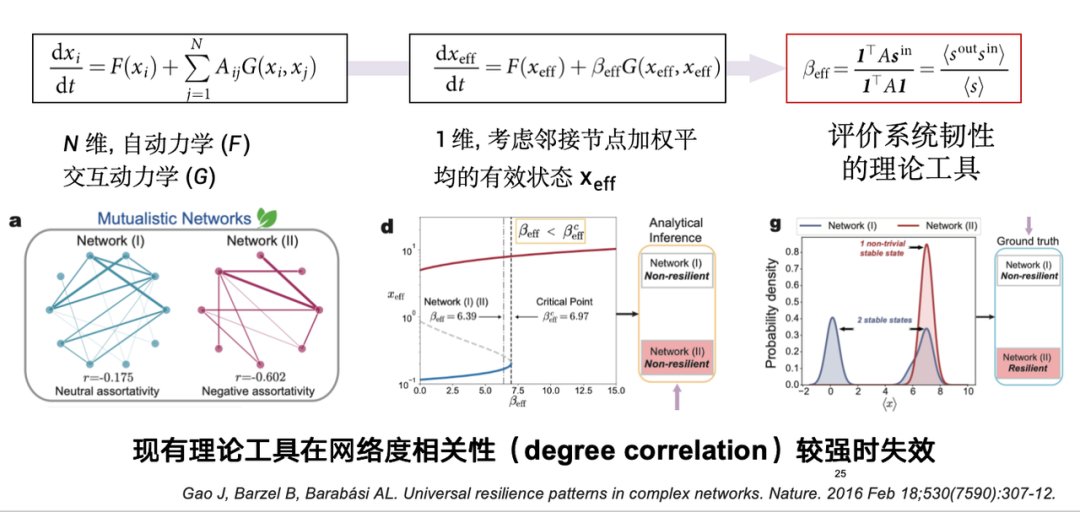
Auf dieser Grundlage schlug unser Team eine datengesteuerte Modellierungsmethode für die Widerstandsfähigkeit von Netzwerksystemen vor.Wie bereits erwähnt, wird die Ausfallsicherheit durch den kombinierten Einfluss der Entwicklung des Knotenzustands und der Netzwerktopologie beeinflusst. Durch die Modellierung aus der Perspektive des datengesteuerten oder maschinellen Lernens unterteilen wir das Problem in zwei Dimensionen. Einerseits wird der dynamische Änderungsprozess des Knotenzustands durch die Zustandsentwicklungsbahn charakterisiert; Auch die Netzwerktopologie muss berücksichtigt werden. Die Rolle schafft die Widerstandsfähigkeit komplexer Systeme, und wir entwerfen entsprechend datengesteuerte Widerstandsfähigkeitsvorhersagemodelle.
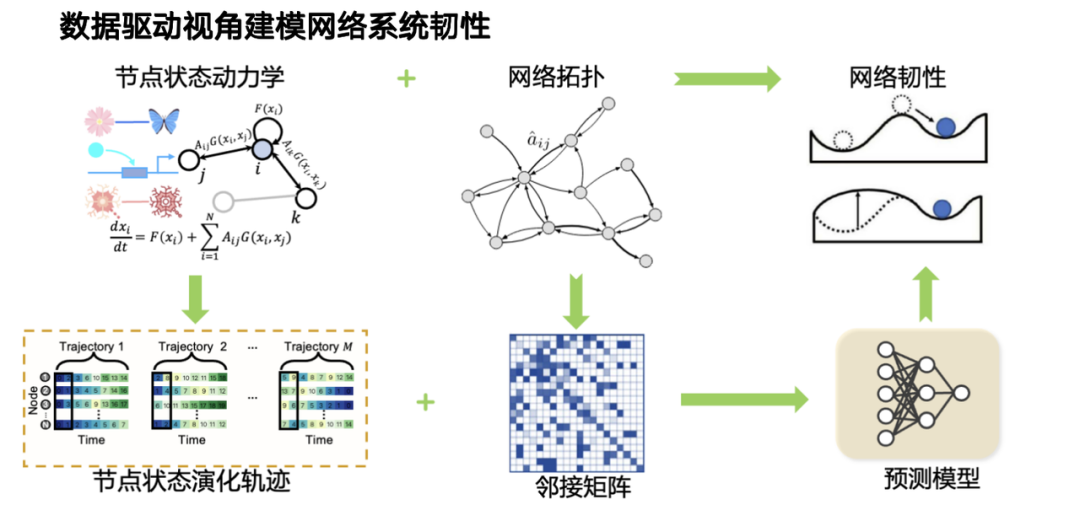
In Bezug auf die Modellarchitektur haben wir eine Struktur entworfen, die ein graphisches neuronales Netzwerk und einen Transformator kombiniert:Für den dynamischen Evolutionsteil verwenden wir Transformer, um Zeitbeziehungen zu modellieren; für komplexe topologische Beziehungen führen wir graphische neuronale Netze ein, um Interaktionen höherer Ordnung zwischen Systemen zu modellieren. Die beiden arbeiten zusammen, um unsere Beobachtung der Systemresilienz zu formen.
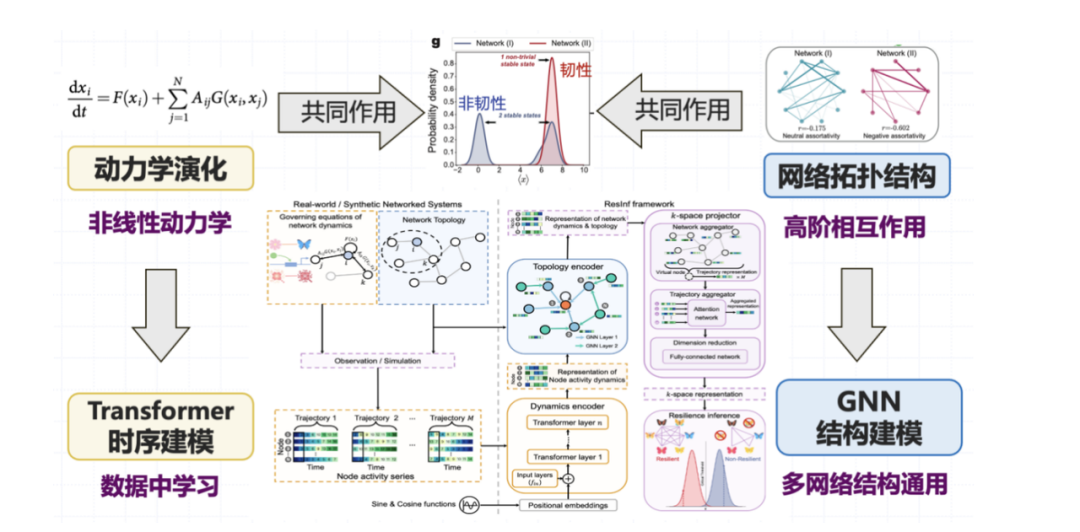
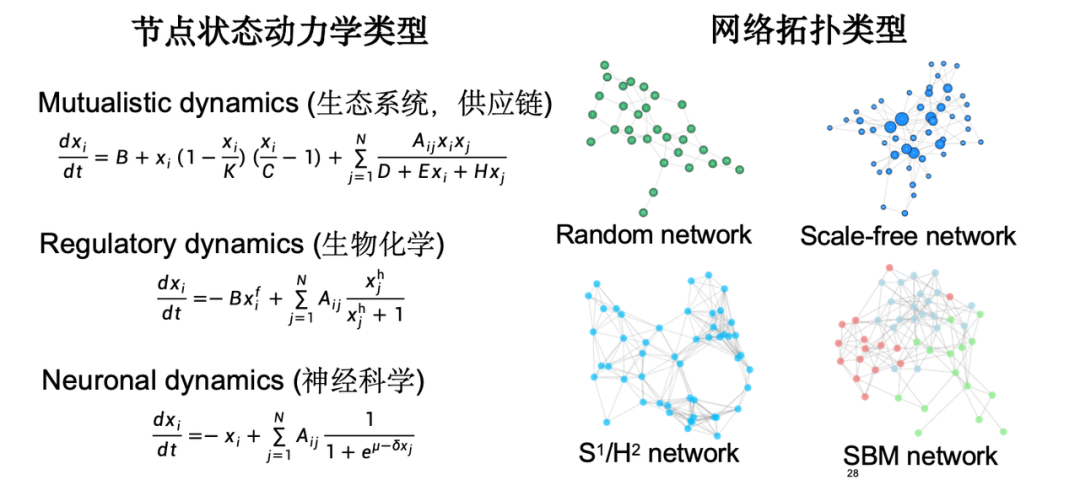
Im Experiment haben wir eine Vielzahl von Knotenzustandsdynamiktypen berücksichtigt, wie z. B. Ökosystem-Lieferketten, Genregulationsdynamik in der Biochemie, neuronale Signalübertragungsdynamik in den Neurowissenschaften usw. Für die Topologie haben wir den klassischen Netzwerktopologietyp ausgewählt.
Experimentelle Ergebnisse zeigen, dass unser Modell die Vorhersagegenauigkeit deutlich verbessert hat, einen hohen F1-Score aufweist, eine gewisse Interpretierbarkeit aufweist und eine Visualisierung der Entscheidungsebene zur Dimensionsreduzierung erreicht.
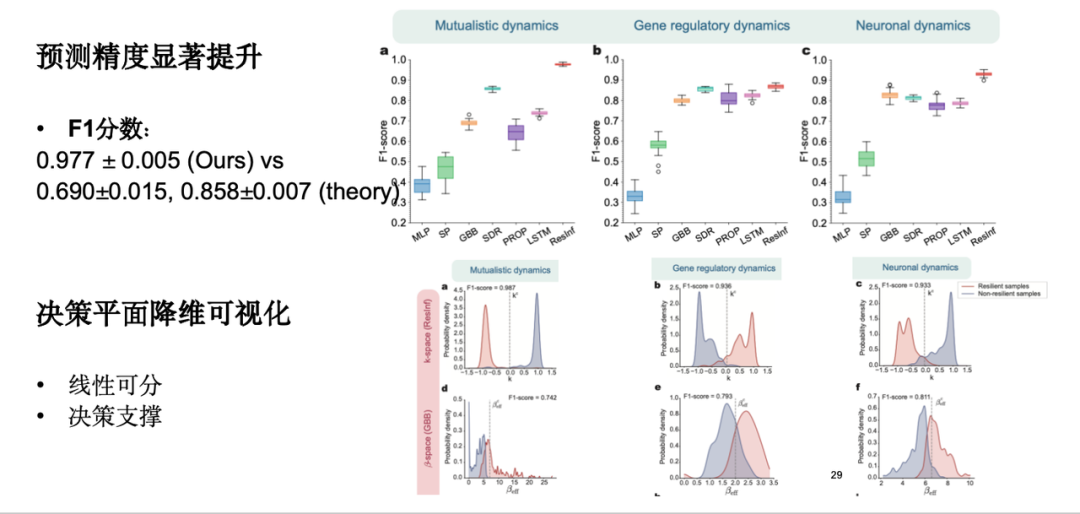
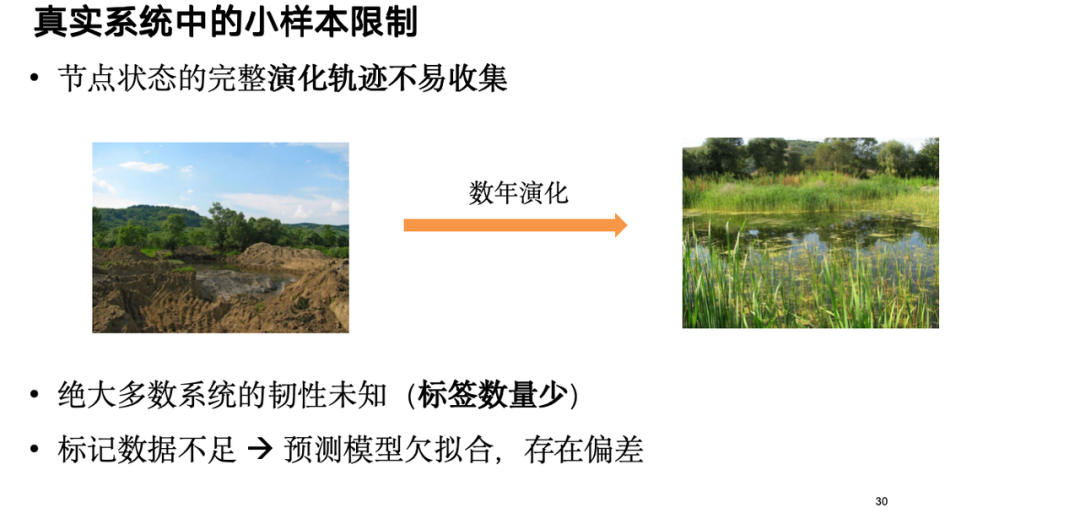
In praktischen Anwendungen haben wir jedoch festgestellt, dass die Widerstandsfähigkeit der meisten Systeme unbekannt ist und es schwierig ist, zu beurteilen, ob sie widerstandsfähig sind, was zu unzureichenden Daten zu den Widerstandsmarkern und einer Verzerrung der Modellvorhersagen führt. Zu diesem Zweck erweitern wir das Modell auf Stichprobenebene, um es in Situationen mit kleinen Stichproben robuster zu machen.
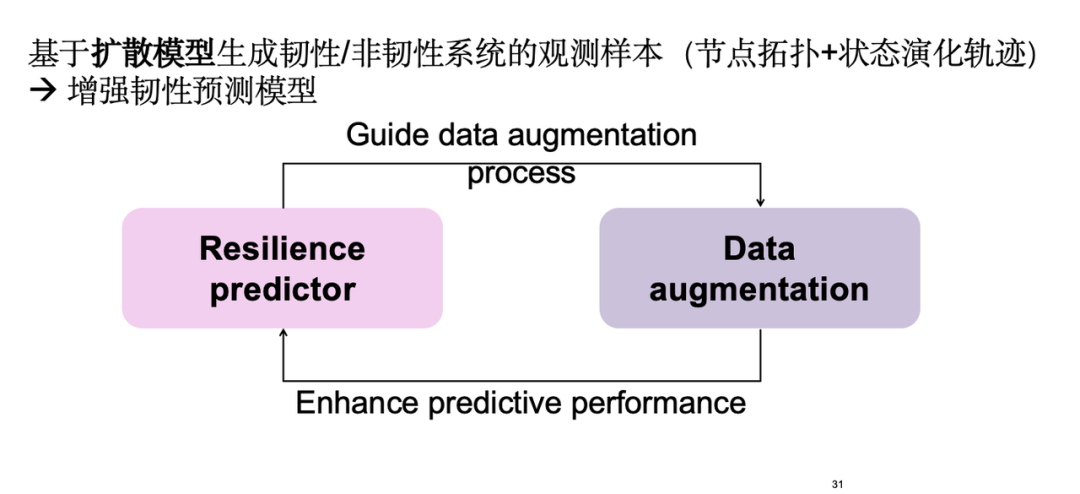
Die spezifische Strategie besteht darin, Beobachtungsstichproben von resilienten und nicht-resilienten Systemen auf der Grundlage von Diffusionsmodellen zu generieren, um die Vorhersagemodelle zu verbessern. Diese Beispiele decken Knotentopologien und ihre Zustandsentwicklungsverläufe ab. Erstens wird die Datenverbesserung durchgeführt, um das Resilienzvorhersagemodul besser zu trainieren, und die Vorhersageergebnisse führen das Datenverbesserungsmodul umgekehrt dazu, wertvollere Proben zu generieren, wodurch eine positive Rückkopplungsschleife entsteht.
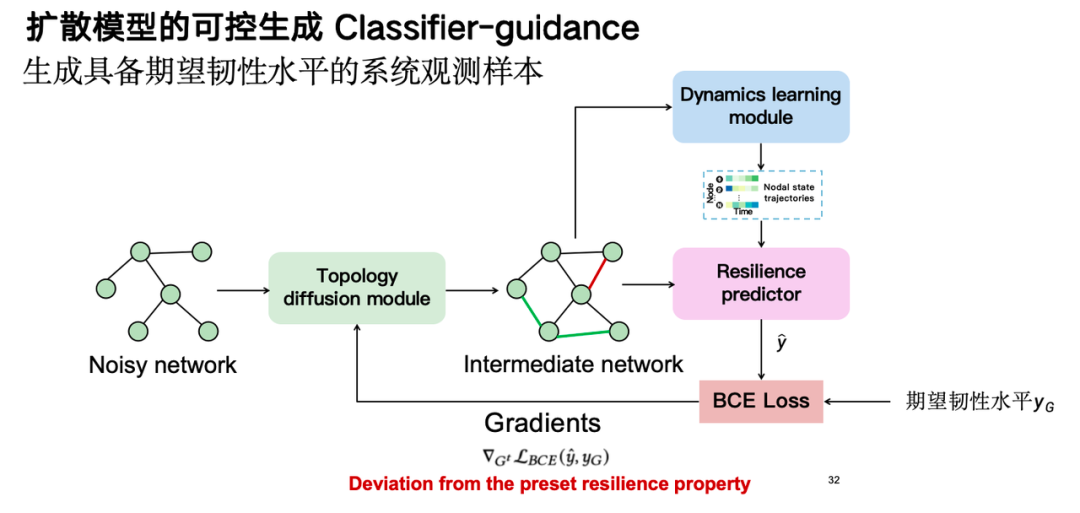
Durch die steuerbare Generierungsfähigkeit des Diffusionsmodells, also der Klassifikator-Führungstechnologie, generieren wir Proben mit dem gewünschten Grad an Belastbarkeit und erreichen so eine Datenverbesserung.
Die Testergebnisse für kleine Stichproben zeigen, dass nach der Verbesserung des Diffusionsmodells mit nur 20 Stichproben die Modellvorhersagegenauigkeit 87% erreichen kann;Ohne Datenerweiterung beträgt die Modellvorhersagegenauigkeit nur 62%. Es ist erwähnenswert, dass wir auch bei einer kürzeren Beobachtungsdauer der Zustandsentwicklungs-Trajektorien eine ähnliche Vorhersagegenauigkeit erreichen können, was für Systeme, die bei tatsächlichen Beobachtungen nicht über längere Zeiträume beobachtet werden können, von großer Bedeutung ist.

Relevante Studien mit den Titeln „Deep Learning Resilience Inference for Complex Networked Systems“ und „TDNetGen: Empowering Complex Network Resilience Prediction with Generative Augmentation of Topology and Dynamics“ wurden in Nature Communications bzw. KDD 2024 veröffentlicht, und der Code und die Daten waren Open Source.
Papieradresse:
https://www.nature.com/articles/s41467-024-53303-4
Adresse des Open-Source-Projekts:
https://github.com/tsinghua-fib-lab/ResInf
Papieradresse:
https://arxiv.org/abs/2408.09825
Adresse des Open-Source-Projekts:
https://github.com/tsinghua-fib-lab/TDNetGen
Universelle raumzeitliche Vorhersage – Tipp zum Lernen erweiterter raumzeitlicher GPT
Seit 2017 hat das Problem der raumzeitlichen Vorhersage im Bereich des Deep Learning allmählich an Aufmerksamkeit gewonnen. Aktuelle Forschungsmethoden sind hauptsächlich in zwei Kategorien unterteilt: Die eine besteht darin, entsprechende Deep-Learning-Modelle auf der Grundlage der räumlich-zeitlichen Eigenschaften bestimmter Datentypen oder -quellen zu entwerfen. Die andere besteht darin, dynamische Systemmethoden wie Reservepoolberechnungen aus der Perspektive komplexer Systeme zu verwenden Angewandte Mathematik. Gemeinsam ist diesen beiden Methodentypen, dass sie beide ein einzelnes Subsystem modellieren.
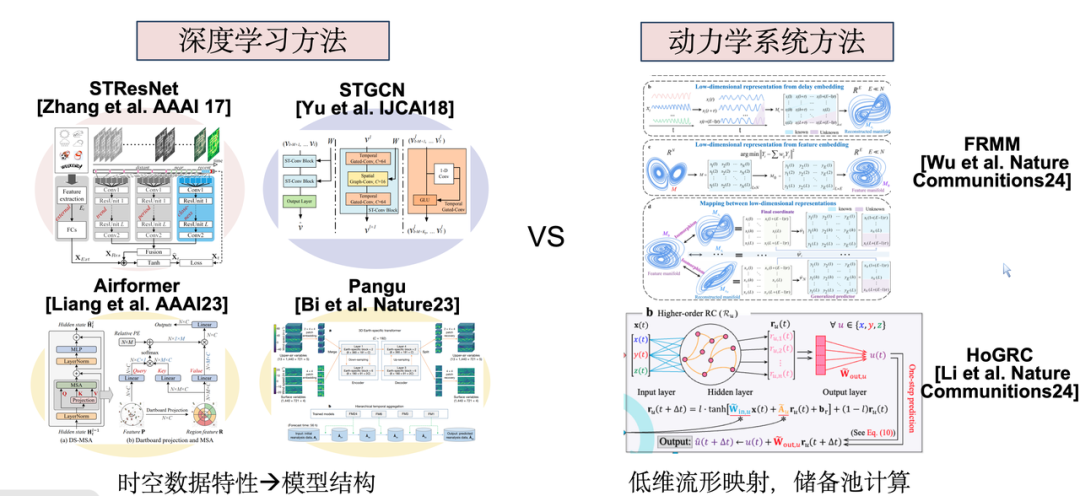
Für städtische Systeme hoffen wir jedoch aufgrund der hohen Korrelation zwischen tatsächlichen Teilsystemen, eine gemeinsame Modellierung zu erreichen, um einen Synergieeffekt von 1 + 1 > 2 zu erzielen. Dies ist auch das Kernziel unserer Forschungsarbeit.
In diesem Rahmen basiert unsere Idee auf der Machbarkeit, dass verschiedene Arten von raumzeitlichen Daten zwar unterschiedliche Organisationsformen und Verteilungen aufweisen, im Wesentlichen jedoch alle aus der menschlichen Produktion und dem Leben in Städten stammen und einige zugrunde liegende universelle Mechanismen sind, die in unterschiedlichen Dimensionen verkörpert sind. Sofern daher eine geeignete Methode gefunden werden kann, können diese heterogenen Daten fusioniert werden, um einen synergistischen Effekt von 1 + 1 > 2 zu erzielen.
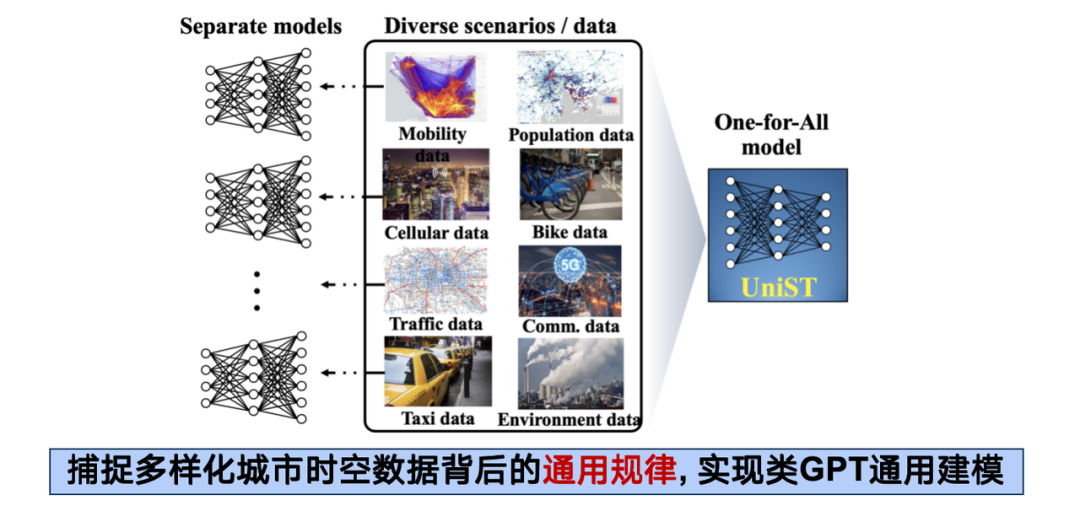
Im tatsächlichen Betrieb haben wir mehr als 20 räumlich-zeitliche Datensätze mit mehr als 130 Millionen Stichprobenpunkten gesammelt, die 5 Subsysteme wie Transport, Mobilfunknetz und Luftverschmutzung abdecken und 14 in- und ausländische Städte abdecken.
Beim Modelldesign haben wir die Transformer-Architektur weitergeführt, verschiedene Formen raumzeitlicher Daten in hochdimensionale Tensoren modelliert und diese auf ähnliche Weise wie ViT (Vision Transformer) verarbeitet.Schließlich wurde das universelle raumzeitliche Vorhersagemodell UniST entwickelt.
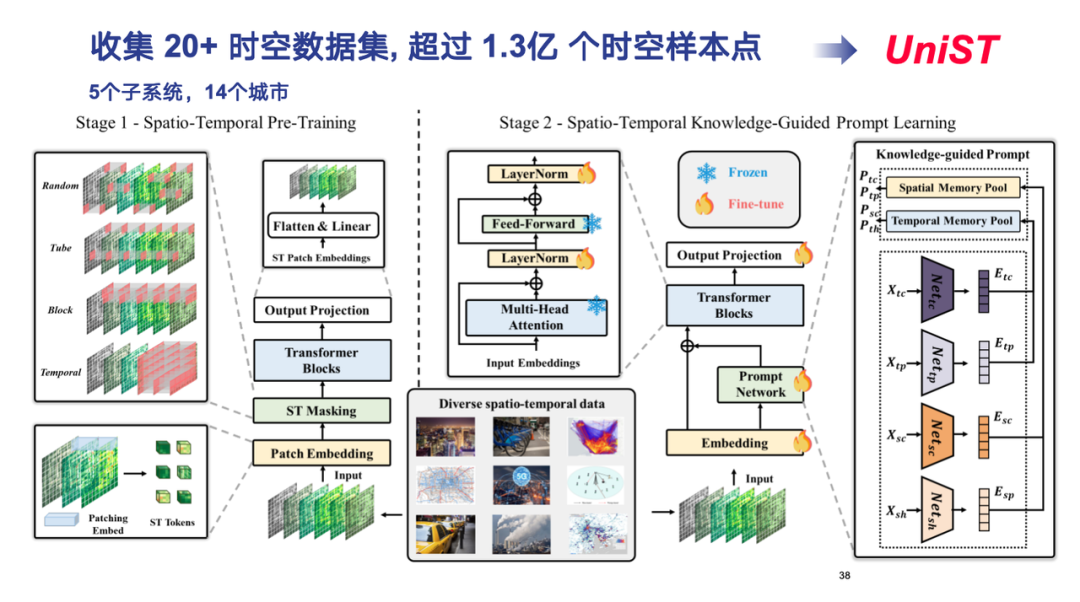
In der ersten Phase des ModelltrainingsWir tokenisieren verschiedene raumzeitliche Daten, zerlegen hochdimensionale Tensoren in kleine Quadrate, wobei jedes Quadrat einem Token entspricht, und verwenden unterschiedliche Maskenstrategien, um verschiedene raumzeitliche Korrelationsmerkmale zu erfassen.
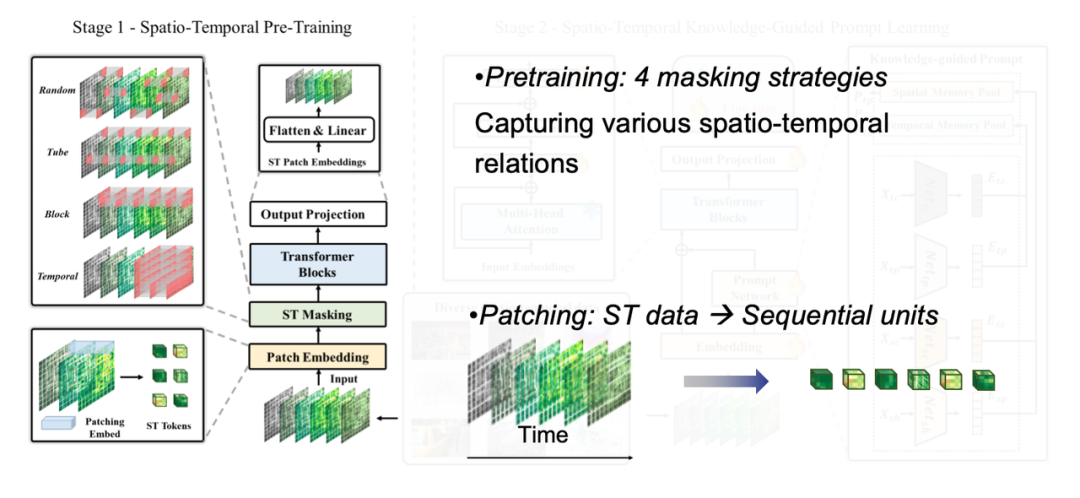
In der zweiten Stufe des ModelltrainingsWir müssen die universellen Gesetze hinter verschiedenen Formen raumzeitlicher Daten entdecken. „Wissen“ bezieht sich hier auf die klassischen Evolutionsmuster, die häufig in räumlich-zeitlichen Daten zu finden sind, wie etwa zeitliche Nähe, Periodizität und Trend sowie räumliche Nähe und Hierarchie. Indem wir dieses raumzeitliche Domänenwissen extrahieren und entsprechende Muster definieren, reduzieren wir die Dimensionalität realer Daten auf mehrere Musterräume und führen ein Vortraining für umfangreiche Daten durch. Auf diese Weise kann das Modell bei der Verarbeitung neuer Daten schnell mit dem entsprechenden Muster übereinstimmen und mithilfe einer RAG-ähnlichen Methode genaue Vorhersagen mit kleinen Stichproben oder sogar Nullstichproben erzielen.

Bei der Bewertung der Wirksamkeit des Modells konzentrieren wir uns hauptsächlich auf zwei Aufgaben: erstens auf die langfristige und kurzfristige Vorhersagefähigkeit, zweitens auf die kritischste Null-Schuss-Fähigkeit, d spezifische Aufgaben oder Datenfähigkeit für die Aufgabe.Wenn das Modell beispielsweise auf der Grundlage des Peking-Datensatzes trainiert wird, kann das Modell für die Shanghai-Daten, die nicht im Training enthalten sind, dennoch genaue Vorhersagen basierend auf der raumzeitlichen Sequenz von Shanghai erzielen.
Wie in der Abbildung unten dargestellt, stellt die rote gepunktete Linie den Vorhersageeffekt unserer Methode unter Null-Probenbedingungen dar. Das rote Rechteck ganz links zeigt die Vorhersageergebnisse unserer Methode unter 1%/5%-Probenbedingungen. Es ist ersichtlich, dass unsere Methode die Basismethode mit 1%/5%-Proben hinsichtlich der Nullprobenmigration deutlich übertrifft.
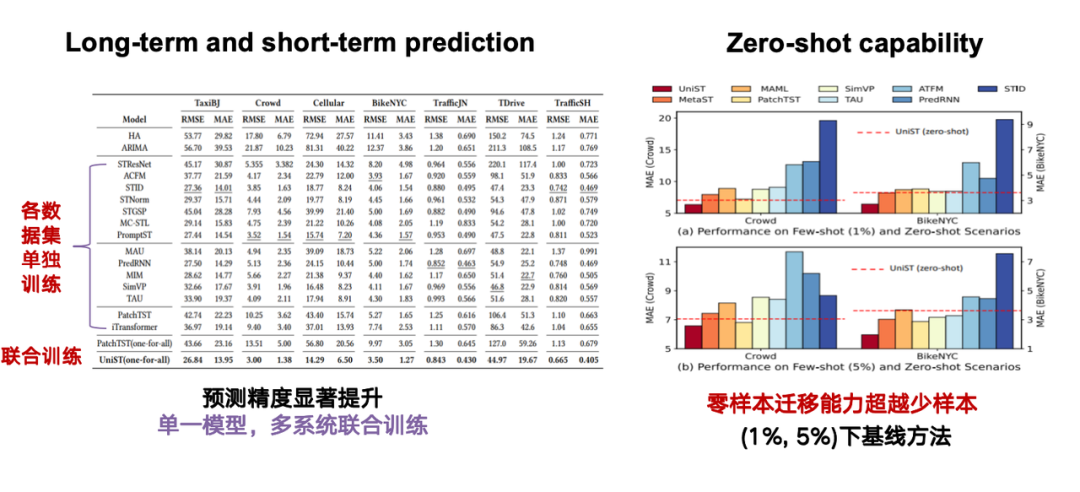
Warum tritt dieser Effekt auf? Durch den Vergleich der Ähnlichkeit zwischen den Daten von Peking und Shanghai in der Abbildung können wir feststellen, dass die Daten zwischen der Beijing Chang'an Street und dem Shanghai Jing'an District nach der Prompt-Berechnung sehr ähnlich sind. Diese hohe Ähnlichkeit erklärt, dass das Modell immer noch ähnliche Vorhersagemuster basierend auf dem Training auf Peking-Daten bilden kann, ohne auf Shanghai-Daten trainiert zu werden.

Wir haben auch die Leistung raumzeitlicher Daten im Hinblick auf das Skalierungsgesetz untersucht, das heißt, ob eine Erhöhung der Datenmenge die Modellfähigkeiten erheblich verbessern wird. Aufgrund der Einschränkungen des vorhandenen Datenvolumens und Datentyps haben wir jedoch noch keinen offensichtlichen Skalierungseffekt beobachtet. In dieser Hinsicht müssen die Datentypen weiter angereichert werden.

Relevante Forschung mit dem Titel „UniST: A Prompt-Empowered Universal Model for Urban Spatio-Temporal Prediction“ wurde für KDD 2024 ausgewählt.
Papieradresse:
https://arxiv.org/abs/2402.11838
Adresse des Open-Source-Projekts:
https://github.com/tsinghua-fib-lab/UniST
Gestützt auf physikalisches Wissen liefert es neue Ideen für die Modellierung komplexer urbaner Systeme.
Abschließend möchte ich die zukünftige Ausrichtung der Modellierung städtischer komplexer Systeme und die neuesten Fortschritte meines Teams (Urban Science and Computing Research Center, Abteilung für Elektronik, Tsinghua-Universität) diskutieren.
Wir glauben, dass physikalisches Wissen weiter kombiniert werden kann, um die Robustheit und Generalisierungsfähigkeit des Modells zu verbessern.Für Systeme in Städten, in denen die Erforschung vieler Mechanismen nicht ausreicht, können Methoden wie symbolische Regression und Netzwerkdynamik-Inferenz umfassend eingesetzt werden, um zu versuchen, symbolische Formeln, die Systementwicklungsregeln beschreiben, aus realen Daten zu extrahieren.

Relevante Forschungsergebnisse wurden auf der ICLR 2023 unter dem Titel „Learning Symbolic Models for Graph-structured Physical Mechanism“ veröffentlicht.
Papieradresse:https://openreview.net/pdf?id=f2wN4v_2__W
Im Bereich großer komplexer Netzwerke gibt es in der statistischen Physik bereits theoriebasierte Tools zur Dimensionsreduktion, wie z. B. Renormierungsgruppen, die auf reale Netzwerkvorhersagen im großen Maßstab angewendet werden können, um dabei zu helfen, das niedrigdimensionale „Skelett“ von zu identifizieren Evolutionsdynamik und langfristige Entwicklungszeitvorhersage. Dies ist auch der Schwerpunkt unserer aktuellen Forschung.

Die entsprechende Forschung trug den Titel „Predicting Long-term Dynamics of Complex Networks via Identifying Skeleton in Hyperbolic Space“ und wurde in KDD 2024 veröffentlicht.
Papieradresse:https://arxiv.org/abs/2408.09845
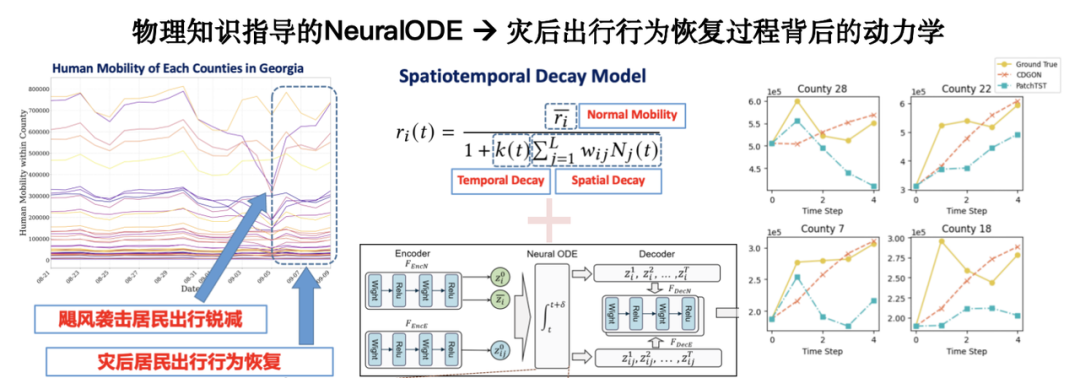
Darüber hinaus wird die Einführung physikalischen Wissens zur Unterstützung des Lernens kleiner Stichproben die Generalisierungsfähigkeit des Modells erheblich verbessern.Am Beispiel eines Notfalls nach einer Katastrophe fehlen historische Daten für dieses Szenario, aber einige Wissenschaftler haben dynamische Gleichungen für das menschliche Verhalten nach einer Katastrophe aus der Perspektive der Mechanismen aufgestellt. Die Kombination dieser Gleichungen mit realen Datenmodellen ermöglicht robustere Vorhersagen mit begrenzten Stichproben.
Relevante Forschungsergebnisse wurden auf KDD 2024 unter dem Titel „Physics-informed Neural ODE for Post-disaster Mobility Recovery“ veröffentlicht.
Papieradresse:https://dl.acm.org/doi/10.1145/3637528.3672027
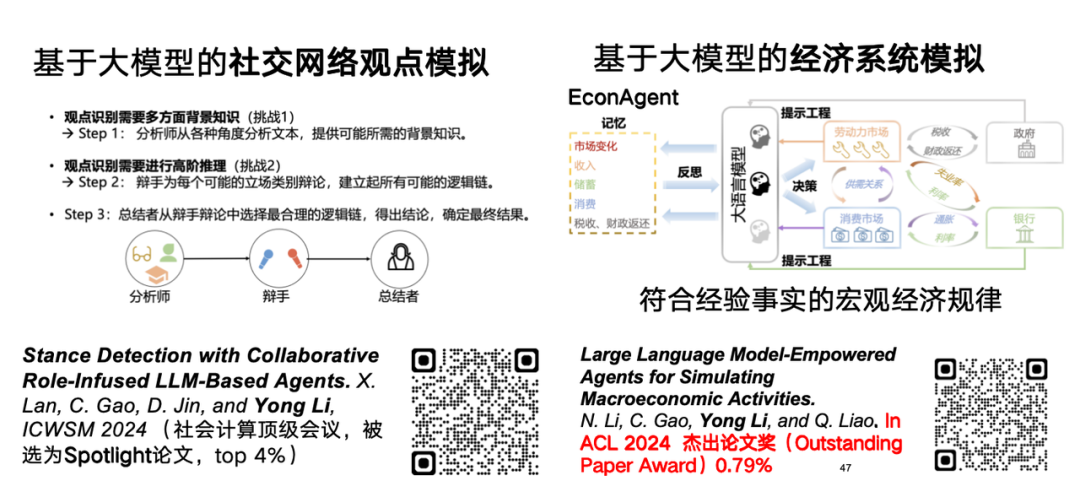
Wir glauben auch, dass große Sprachmodelle Potenzial für Argumentation und Simulation im Bereich raumzeitlicher Daten haben.Mit großen Sprachmodellen lassen sich beispielsweise Netzwerkkonzepte oder Wirtschaftssysteme simulieren. Zur Erforschung der Perspektive großer Sprachmodell-Simulationsnetzwerke wurde auf der ICWSM 2024 ein verwandter Artikel mit dem Titel „Stance Detection with Collaborative Role-Infused LLM-Based Agents“ veröffentlicht.
Papieradresse:https://arxiv.org/abs/2310.10467
Für die Untersuchung großer Sprachmodellsimulationen von Wirtschaftssystemen verwenden wir den Agenten großer Sprachmodelle, um makroökonomische Modelle effektiv zu simulieren, die empirischen Gesetzen entsprechen.Die entsprechende Forschung trug den Titel „EconAgent: Large Language Model-Empowered Agents for Simulated Macroeconomic Activities“ und wurde mit dem ACL 2024 Outstanding Paper Award ausgezeichnet.
Papieradresse:https://arxiv.org/abs/2310.10436
Da große Sprachmodelle auf der Grundlage großer Mengen menschengenerierter Sprachdaten trainiert werden und über menschenähnliche Denk- und Entscheidungsfähigkeiten verfügen, untersucht unser Team ihre Anwendung bei der Generierung oder Simulation menschlichen Verhaltens. Im Vergleich zur herkömmlichen Methode, die auf generativen Modellen basiert, haben wir mithilfe umfangreicher Kenntnisse vor dem Training von Modellen festgestellt, dass nur 200 Stichproben verwendet werden können, um ähnliche Effekte wie 100.000 Trainingsstichproben zu erzielen und so eine schnelle Verallgemeinerung in bestimmten Szenarien zu erreichen.
Die entsprechende Forschungsarbeit „Chain-of-Planned-Behaviour Workflow Elicits Few-Shot Mobility Generation in LLMs“ wurde auf die Preprint-Website arXiv hochgeladen.
Papieradresse:https://arxiv.org/abs/2402.09836
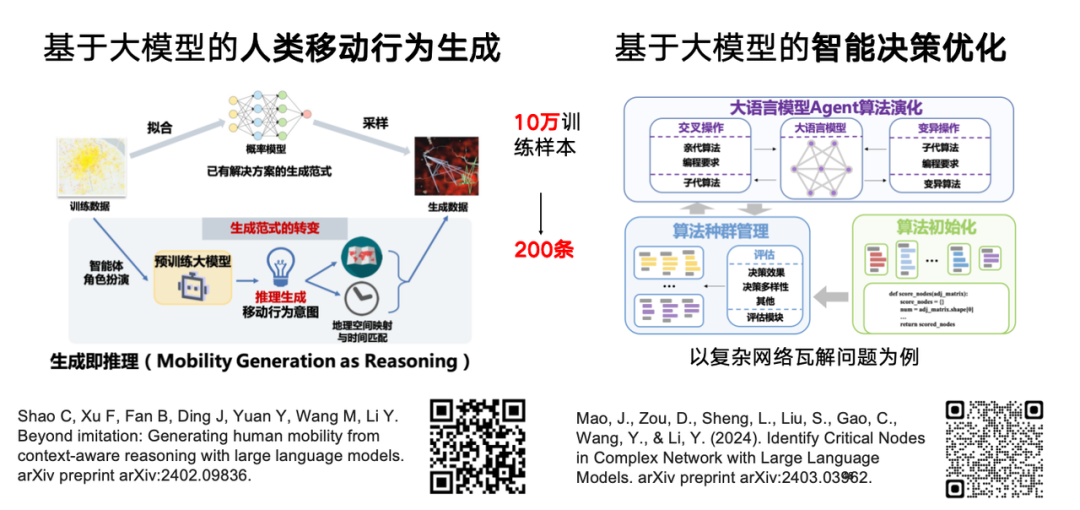
Unser Team untersucht außerdem, ob große Sprachmodelle weiterhin zur intelligenten Entscheidungsoptimierung genutzt werden können.Die verwandte Forschung „Identify Critical Nodes in Complex Network with Large Language Models“ wurde auf die Preprint-Website arXiv hochgeladen.
Papieradresse:https://arxiv.org/abs/2403.03962
Über FIB LAB
Der gemeinsame Gast ist dieses Mal Dr. Ding Jingtao vom Urban Science and Computing Research Center (FIB LAB) der Fakultät für Elektrotechnik der Tsinghua-Universität.Das Forschungszentrum konzentriert sich auf die Richtung der Stadtwissenschaft und Computerforschung. Es nimmt die Stadtwissenschaft als grundlegendes Forschungsproblem, betreibt Forschung auf der Grundlage von Theorien wie komplexen Systemen und Computersoziologie und kombiniert die neue Generation der „kognitiven künstlichen Intelligenz“ mit Daten Wissenschaft und maschinelles Lernen als Kerntechnologie für urbane Zwillinge, städtische Governance, drahtlose Netzwerkzwillinge und andere Anwendungsbereiche mit großem nationalen Bedarf. Das Team besteht derzeit aus 6 Lehrern und mehr als 60 Schülern.

Das Team hat mehr als 150 wissenschaftliche Arbeiten in führenden internationalen Fachzeitschriften wie Nature-Unterjournalen und führenden internationalen Konferenzen wie KDD, NeurIPS, WWW und UbiComp veröffentlicht (7 Beiträge in Unterzeitschriften und mehr als 100 Beiträge in der CCF-Kategorie A). . Die Artikel wurden mehr als 25.000 Mal zitiert und mit 7 Preisen für den besten Beitrag der Internationalen Konferenz ausgezeichnet.Das Team war Gastgeber oder Teilnehmer an mehr als 15 Projekten, darunter den wichtigsten Forschungs- und Entwicklungsplänen des Ministeriums für Wissenschaft und Technologie und der National Natural Science Foundation of China, und die entsprechenden Ergebnisse gewannen den zweiten Preis des National Science and Technology Progress Award.
Das Forschungszentrum hat stets an der Integration von Industrie und Wissenschaft festgehalten. In den letzten Jahren hat es gute Kooperationsbeziehungen mit Huawei, Tencent, Alibaba, Microsoft Research Asia, Meituan, Kuaishou, AutoNavi, SenseTime, Toyota und Mobilfunkbetreibern aufgebaut. Es gibt zahlreiche Möglichkeiten für Unternehmenskooperationen und Praktika.
Homepage des Labors:https://fi.ee.tsinghua.edu.cn/
Persönliche Homepage:https://fi.ee.tsinghua.edu.cn/~dingjingtao/









