Command Palette
Search for a command to run...
Die Hong Kong University of Science and Technology Schlägt Ein Fusion-Neural-Network-Framework Vor, Um Multimetall-Bindungsstellen in Proteinsequenzen Effizient Vorherzusagen
Metallionen spielen eine unverzichtbare Rolle im Leben. Zink wirkt als Lewis-Säure in der Hydrolasekatalyse, Eisen ist ein wichtiger Träger des Elektronentransports in der Atmungskette und Magnesium ist für die Faltung der RNA in eine stabile Tertiärstruktur unerlässlich. Trotz der großen Anzahl hochauflösender Metalloproteinstrukturen in der Proteindatenbank bleibt die experimentelle Identifizierung von Metall-Protein-Wechselwirkungen zeitaufwändig, mühsam und kostspielig.Daher ist die rechnerische Vorhersage von Metallbindungsstellen auf der Grundlage des Rückstandsniveaus zu einer effektiven alternativen Strategie geworden.
Bestehende Methoden zur Vorhersage multimetallischer Verbindungen sind durch ihre Architektur stark eingeschränkt. Strukturbasierte Prädiktoren sind auf rechenintensive Programme angewiesen, was ihre praktische Anwendung erschwert. Proteinsprachmodelle haben sich zwar als vielversprechende Vorhersagemethode erwiesen, doch ihr erheblicher Rechenaufwand und die langen Inferenzzeiten schränken ihre praktische Anwendung ein.
Um dieses Problem zu lösen, schlug ein Forschungsteam der Hong Kong University of Science and Technology ein Fusion-Neural-Network-Framework vor, um Multimetall-Bindungsstellen in Proteinsequenzen vorherzusagen.Dieses Framework verwendet eine zweistufige Architektur, die ein Convolutional Neural Network (CNN) mit einem Fusionsnetzwerk kombiniert. Durch die Einführung einer ungleichgewichtsbewussten Verlustfunktion, integrierter Auswertung und einer modularen Architektur behebt es effektiv das Klassenungleichgewicht zwischen positiven und negativen Proben verschiedener Metalle und die komplexen Wechselwirkungen zwischen ihnen. Sein strukturunabhängiges Design ermöglicht schnelle, robuste und qualitativ hochwertige ganzheitliche Vorhersagen für große Datensätze ohne strukturelle Eingaben und erweitert so das Potenzial des Metall-Protein-Interaktions-Mining erheblich.
Die entsprechende Forschungsarbeit wurde auf bioRxiv unter dem Titel „A Modular Fusion Neural Network Approach to Efficiently Predict Multi-Metal Binding Sites in Protein Sequences“ veröffentlicht.
Forschungshighlights:
* Ein zweistufiges Fusion-Neural-Network-Framework, das CNN und Fusion-Netzwerk kombiniert;
* Durch die Einführung einer gewichteten binären Kreuzentropieverlustfunktion wird das Problem des Klassenungleichgewichts bei der Vorhersage von Metallbindungsstellen effektiv gelöst.
Papieradresse:
Folgen Sie dem offiziellen Konto und antworten Sie mit „Multi-Metal-Bindungsstellen“, um das vollständige PDF zu erhalten
Weitere Artikel zu den Grenzen der KI:
Aufbau eines stabilen und repräsentativen Datensatzes
Um einen hochwertigen Datensatz zu erstellen, der für Training und Evaluierung geeignet ist, führte das Forschungsteam eine Sekundärverarbeitung auf Grundlage der vorhandenen MbPA-Datenbank durch.Zunächst wurde ein umfassender Datensatz metallbindender Proteine aus der MbPA-Datenbank abgerufen. Insgesamt wurden 91.593 Proteine, die Zink (Zn), Eisen (Fe) und Magnesium (Mg) binden können, gescreent, wobei ihre verifizierten Bindungsstelleninformationen und die entsprechenden Metallionen erhalten blieben. Auf dieser Grundlage schloss das Forschungsteam die Sequenznormalisierung und Ganzzahlkodierung (einheitliche Länge von 500 Aminosäuren), die Multilabel-Annotation der Bindungsstellen, die stratifizierte Stichprobenziehung (15%-Testsatz, 85%-Entwicklungssatz) und die Behandlung des Klassenungleichgewichts ab. Die Behandlung des Klassenungleichgewichts umfasste eine dreistufige Vorverarbeitung und einen unabhängigen Trainingsprozess, um das Klassenungleichgewicht zu beheben und gleichzeitig metallspezifische Prädiktoren zu implementieren. Der Implementierungsprozess lief wie folgt ab: Generierung metallspezifischer Labels, positive Probenzählung und gewichteter binärer Kreuzentropieverlust.
* MbPA (Metal Binding Protein Atlas) ist eine Ressourcenbibliothek für metallbindende Proteine. Derzeit enthält die Datenbank 106.373 Einträge und 440.187 Standorte, darunter 54 Metallionen und 8.169 Arten.

Zweistufiges Deep-Learning-Framework und modulare Fusion
Das Forschungsteam schlug ein sequenzbasiertes zweistufiges Deep-Learning-Framework zur effizienten Vorhersage von Multimetall-Bindungsstellen in Proteinsequenzen vor.Die Grundidee besteht darin, zunächst unabhängige Vorhersagemodelle für einzelne Metallionen zu trainieren, um Wahrscheinlichkeitskarten für einzelne Rückstände zu erstellen. Diese Karten werden dann über ein leichtes Fusionsnetzwerk integriert, um intermetallische Abhängigkeiten zu modellieren und letztendlich die Vorhersageleistung zu optimieren.
Im ersten Schritt wurde für jedes einzelne Metall (Zn, Fe und Mg) ein eindimensionales Convolutional Neural Network (Single-Metal CNN) verwendet, um die Positionsassoziationswahrscheinlichkeit eines bestimmten Metallions vorherzusagen. Nach der oben beschriebenen Verarbeitung wurde jede Proteinsequenz einheitlich als 500-dimensionale Darstellung dargestellt. Ganzzahlig kodierte Reste wurden auf eine Einbettungsschicht eines 64-dimensionalen trainierbaren Vektors abgebildet. Die Sequenz wurde dann unter Verwendung einer einheitlichen Rectangular Unit (ReLU)-Aktivierungsfunktion durch vier Conv1D-Schichten geleitet (Anzahl der Convolution-Kernel: 512, 256, 128, 64, Kernelgrößen: 15, 7, 5, 3). Nach den Convolutional-Schichten wurde eine Dropout-Schicht mit einer Dropout-Rate von 0,3 hinzugefügt. Nach der Extraktion und Regularisierung der Convolutional-Funktionen wurden die Sequenzfunktionen in eine zeitverteilte, vollständig verbundene Schicht eingegeben, die die vorhergesagte Bindungswahrscheinlichkeit unter Verwendung einer sigmoiden Aktivierungsfunktion bitweise ausgibt.
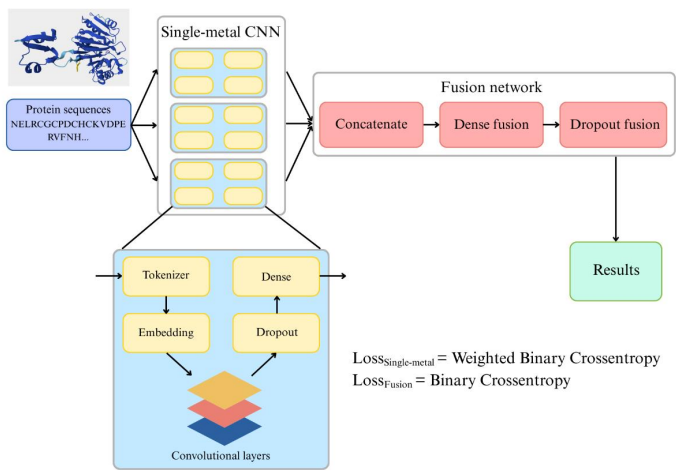
Phase II,Das Forschungsteam entwarf ein integriertes Multimetall-Fusionsnetzwerk (Fusionsnetzwerk).Die Vorhersagen für die drei Metalle werden zu einem Tensor der Form (Lmax, M) verkettet, wobei Lmax = 500 Aminosäuren und M = 3 Metallkanäle. Dieser Tensor wird in eine vollständig verbundene Schicht mit 256 verborgenen Einheiten und ReLU-Aktivierungen eingespeist, wodurch die nichtlinearen Wechselwirkungen zwischen metallspezifischen Merkmalen auf jeder Restebene erlernt werden. Anschließend wird eine Dropout-Schicht mit einer Dropout-Rate von 0,2 eingeführt, um die Fusionsgewichte zu regulieren und Überanpassung zu vermeiden. Schließlich werden M Sigmoid-Ausgaben in der dichten Schicht verwendet, um genaue Bindungswahrscheinlichkeiten für Zn, Fe und Mg für jeden Rest bereitzustellen. Das Fusionsnetzwerk verwendet die standardmäßige binäre Kreuzentropie als Verlustfunktion und wird mit dem Adam-Optimierer trainiert. Dadurch lernt es, Korrelationsfehler zu korrigieren und die Gesamtgenauigkeit zu verbessern.
Darüber hinaus besteht das einzigartige Merkmal des Frameworks darin, dass es vollständig auf Proteinsequenzdaten basiert und somit die Abhängigkeit von der Struktur eliminiert.Dadurch kann der gesamte Prozess in weniger als einer Stunde auf einer einzigen NVIDIA A800-GPU abgeschlossen werden, und seine Effizienz trägt dazu bei, den experimentellen Prozess und die Parameteranpassung in Echtzeit zu beschleunigen.
Mehrdimensionale umfassende experimentelle Auswertung
Das Forschungsteam verwendete mehrdimensionale Indikatoren, um eine experimentelle Auswertung durchzuführen.Diese kombinierte Metrik umfasst Präzision, Recall, F1-Score und Matthews-Korrelationskoeffizient (MCC). Auf die vorhergesagte Bindungswahrscheinlichkeit wird eine Entscheidungsschwelle τ angewendet: Übersteigt die vorhergesagte Wahrscheinlichkeit eines Restes τ, wird er als Metallbindungsstelle klassifiziert; andernfalls wird er als Nichtmetallbindungsstelle klassifiziert. Im Vergleich zu Bewertungsmethoden, die nur einen einzelnen Wert berücksichtigen, spiegelt dieses kombinierte Metriksystem die tatsächliche Leistung des Frameworks in Szenarien mit Klassenungleichgewicht besser wider.
Abbildung (a) unten zeigt die Beziehung zwischen jedem Metall und dem makro-durchschnittlichen F1-Score sowie der Entscheidungsschwelle τ. Die Ergebnisse zeigen, dass Fe bei Vorhersagen gut abschneidet, mit F1-Scores über 0,81 bei τ-Werten zwischen 0,25 und 0,60. Die Einzelmetallmodelle für Zn und Mg erreichen ebenfalls F1-Scores über 0,79 in den Bereichen τ = 0,25–0,50 und 0,25–0,60. Insgesamt erreicht der makro-durchschnittliche F1-Score einen Spitzenwert von 0,855, wenn die Schwelle zwischen 0,40 und 0,45 festgelegt wird. Dies ist die optimale Wahl für die Balance zwischen Präzision und Rückruf für alle Metalle. Abbildung (b) zeigt die Beziehung zwischen MCC und Schwelle und verdeutlicht, dass das Framework selbst bei starkem Klassenungleichgewicht noch eine gute Balance erreichen kann.
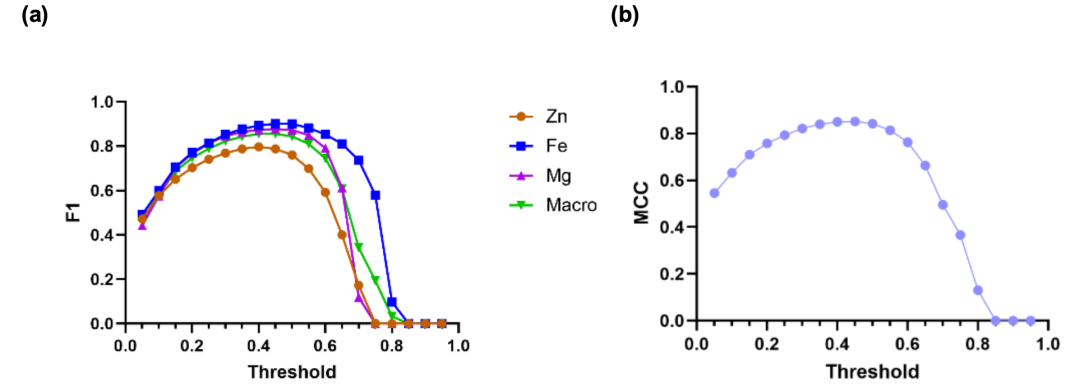
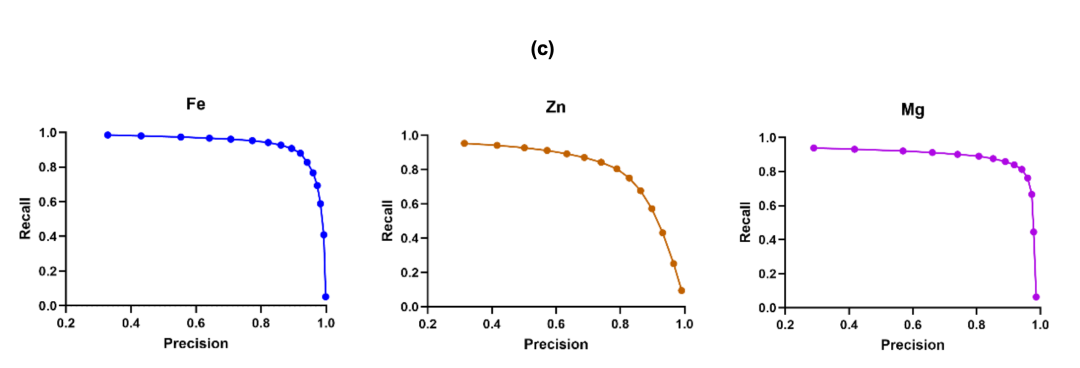
Abbildung (c) zeigt die Präzisions-Recall-Kurven für die drei Metalle. Die Vorhersage von Fe weist bei hohen Recall-Werten eine hohe Präzision auf und zeigt damit ihre Eignung für ein umfassendes Site-Screening. Auch die Vorhersageindizes für Zn und Mg schneiden gut ab und verdeutlichen die Robustheit des Frameworks für Anwendungen, die einen mäßig hohen Recall und anhaltende Präzision erfordern.
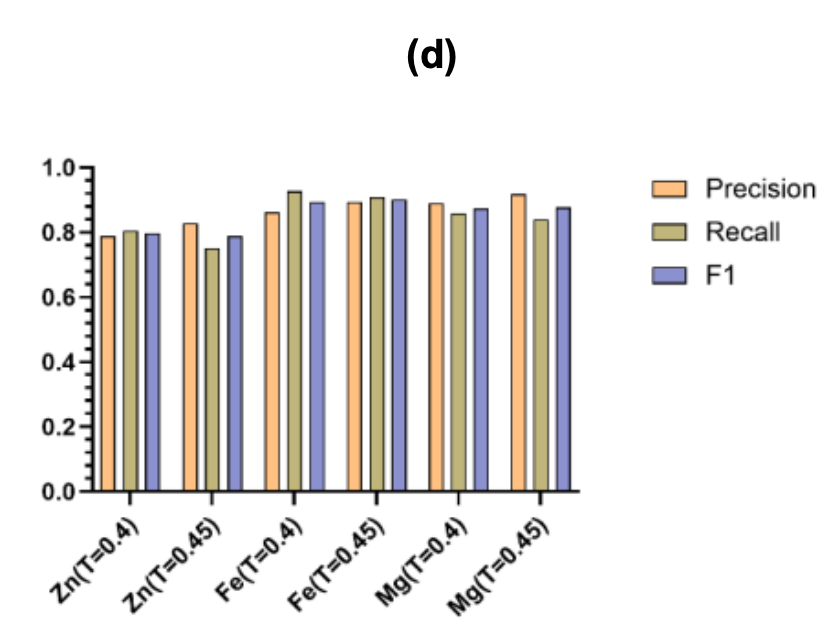
Schließlich zeigt Abbildung (d) die Präzision, den Rückruf und den F1-Score verschiedener Metallvorhersagen bei den beiden optimalen Schwellenwerten von τ = 0,40 und 0,45.Die Ergebnisse zeigen, dass das Framework flexibel an die Eigenschaften verschiedener Metalle angepasst werden kann. Es kann in Screening-Szenarien mit Abdeckungspriorität verwendet werden und erfüllt auch die Anforderungen hochpräziser experimenteller Verifizierungen.
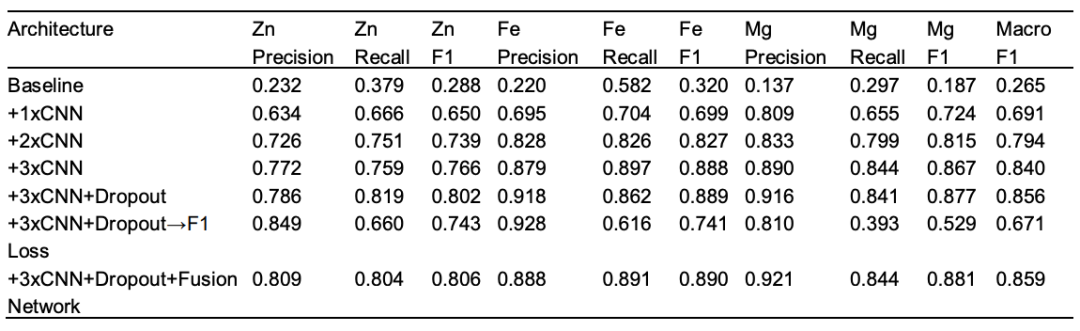
Um den Beitrag jeder einzelnen Architekturkomponente zu bewerten, führte das Forschungsteam auch systematische Ablationsexperimente durch, um zwei zentrale Designprinzipien zu überprüfen:(1) Die gewichtete binäre Kreuzentropie-Verlustfunktion ist entscheidend für die Handhabung des Klassenungleichgewichtsproblems bei der Vorhersage von Metallbindungsstellen. (2) Die Fusionsnetzwerkarchitektur verbessert die Vorhersagekonsistenz und erfasst Kreuzmetallbeziehungen, die von einzelnen Modellen nicht unabhängig voneinander genutzt werden können.
Ausgehend von der einfachsten einzelnen CNN-Schicht betrug der durchschnittliche F1-Wert lediglich 0,265. Mit zunehmender Anzahl an Faltungsschichten verbesserte sich die Leistung deutlich. Ein dreischichtiges CNN steigerte den durchschnittlichen F1-Wert auf 0,840, was die entscheidende Rolle der hierarchischen Merkmalsextraktion verdeutlicht. Durch die Einführung von Dropout erhöhte sich der F1-Wert auf 0,856, wodurch Überanpassung verhindert und die Generalisierung verbessert wurde. Um das Klassenungleichgewicht zu beheben, entwickelte das Forschungsteam eine gewichtete binäre Kreuzentropie-Verlustfunktion, die die Trefferquote deutlich verbesserte, ohne die Gesamtgenauigkeit zu beeinträchtigen. Schließlich verbesserte das Hinzufügen einer Fusionsschicht den durchschnittlichen F1-Wert weiter auf 0,859. Diese Fusionsschicht modelliert effektiv intermetallische Abhängigkeiten und erhöht so die Genauigkeit und Robustheit von Vorhersagen auf Rückstandsebene.
Eine neue Engine zur Beschleunigung der Metall-Protein-Interaktionsanalyse
Dieses neuartige Framework ermöglicht eine erweiterte Metalloprotein-Annotation und entwickelt sich zu einem entscheidenden Motor für die beschleunigte Analyse von Metall-Protein-Interaktionen. Die Bedeutung der Erforschung von Metall-Protein-Interaktionen in der Biologie ist unbestreitbar, und diese Forschungsrichtung hat erhebliche Aufmerksamkeit erregt. Wissenschaftler verschiedener Forschungsteams erforschen aktiv neue Ansätze und Werkzeuge aus unterschiedlichen Perspektiven. Zwei herausragende Erfolge sind nachfolgend aufgeführt:
Zwei von der Eidgenössischen Technischen Hochschule Lausanne (EPFL) entwickelte Tools – Metal3D und Metal1D – verbessern die Vorhersage der Zinkionenposition in Proteinstrukturen. Das Metal3D-Framework kann durch Anpassung der Trainingsdaten auf andere Metalle erweitert werden. Die zugehörige Forschung mit dem Titel „Metal3D: Ein allgemeines Deep-Learning-Framework zur genauen Vorhersage der Metallionenposition in Proteinen“ wurde in Nature Communications veröffentlicht.
Papieradresse:
https://www.nature.com/articles/s41467-023-37870-6
Eine auf arXiv veröffentlichte Studie mit dem Titel „Interpretable Multimodal Learning for Tumor Protein-Metal Binding: Progress, Challenges, and Perspectives“ fasst systematisch die neuesten Fortschritte und aktuellen Herausforderungen bei der Anwendung von maschinellem Lernen zur Vorhersage der Tumorprotein-Metall-Bindung zusammen. Sie schlägt außerdem zwei vielversprechende Ansätze für die Entwicklung effizienter Metallmedikamente vor: die Integration von Daten zur Protein-Protein-Interaktion, um strukturelle Einblicke in die Metallbindung zu gewinnen, und die Vorhersage struktureller Veränderungen in Tumorproteinen nach der Metallbindung.
Papieradresse:
https://arxiv.org/abs/2504.03847
Referenzlinks:
1.https://pubs.acs.org/doi/10.1021/cr300014x








