Command Palette
Search for a command to run...
Wie Betreiben KI-Praktiker Wissenschaft? Tsinghua University AIR Zhou Hao: Grenzüberschreitende Erkundung Von Der Textgenerierung Bis Zum Proteindesign

Kürzlich fand auf dem Forum „AI for Science“ der Beijing Zhiyuan Conference statt:Zhou Hao, assoziierter Forscher am Institute of Intelligent Industries der Tsinghua-Universität, hielt eine Rede zum Thema „Generative künstliche Intelligenz für wissenschaftliche Entdeckungen“.HyperAI hat die ausführlichen Ausführungen von Professor Zhou Hao organisiert und zusammengefasst, ohne die ursprüngliche Absicht zu verletzen.

Grenzüberschreitende Erkundung von der Textgenerierung bis zum Moleküldesign
In seiner Rede ging Professor Zhou Hao vor allem auf drei Aspekte ein: Generative künstliche Intelligenz für komplexe Symbole, die Herausforderungen bei der Mikroprobengenerierung und aktuelle spezifische Forschungsinhalte.
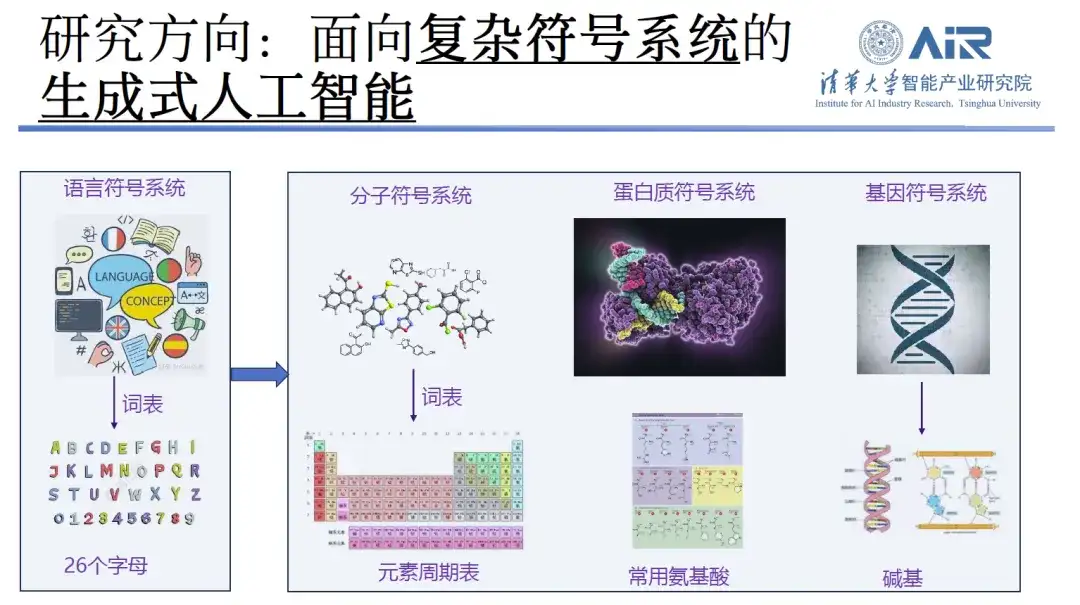
Bei der Vorstellung seiner entsprechenden Forschungsrichtungen sagte Professor Zhou Hao, dass er sich in den letzten zehn Jahren der natürlichen Sprachverarbeitung, einschließlich Textgenerierung und maschineller Übersetzung, verschrieben habe. In den letzten zwei JahrenDer Forschungsschwerpunkt verlagerte sich allmählich von der Inhaltserstellung auf die Molekülerzeugung und das Proteindesign.Seiner Ansicht nach ist die aktuelle Arbeit gleichbedeutend mit der Ausweitung dieser 26 Buchstaben auf ein breiteres Spektrum von Bereichen wie das Periodensystem, Aminosäuren, Basen usw., wenn man die Textverarbeitungsarbeit der Vergangenheit als komplexes Sprachsymbolsystem betrachtet, dessen Vokabular aus 26 Buchstaben besteht. Sein Forschungsteam verfügt über umfangreiche Erfahrungen mit diesen Technologien.

Von KI, die sich auf die Erstellung von Inhalten konzentriert, bis hin zu KI, die sich der wissenschaftlichen Entdeckung widmet,Was ist die Verbindung zwischen den beiden? Tatsächlich kann künstliche Intelligenz aus Rauschen vollständige Bilder erzeugen, und viele nordamerikanische Forschungsteams haben bereits ähnliche Methoden zum Design von Proteinen verwendet. Durch die zufällige Anordnung der Aminosäuren eines Proteins im Raum und das anschließende Durchlaufen einer Reihe generativer Designs von 0 bis 2.000 Schritten ist es möglich, eine Aminosäuresequenz zu entwerfen, die recht vernünftig aussieht.
Zwar bestehen hinsichtlich der Länge der in dieser Forschung verwendeten Proteine noch gewisse Beschränkungen, doch haben jüngste Forschungsergebnisse diese Beschränkungen deutlich erweitert und auch auf das enorme Potenzial dieser Technologie hingewiesen, was ein wichtiger Grund dafür sein könnte, warum sich Professor Zhou Hao für dieses Gebiet entschieden hat.
Zahlreiche Herausforderungen für KI-Praktiker bei der Durchführung wissenschaftlicher Forschung
Anschließend erläuterte Professor Zhou Hao allen die drei größten Herausforderungen, vor denen die künstliche Intelligenz (KI für die Wissenschaft) im wissenschaftlichen Bereich aus der Sicht von Praktikern auf dem Gebiet der Informatik bzw. KI steht.
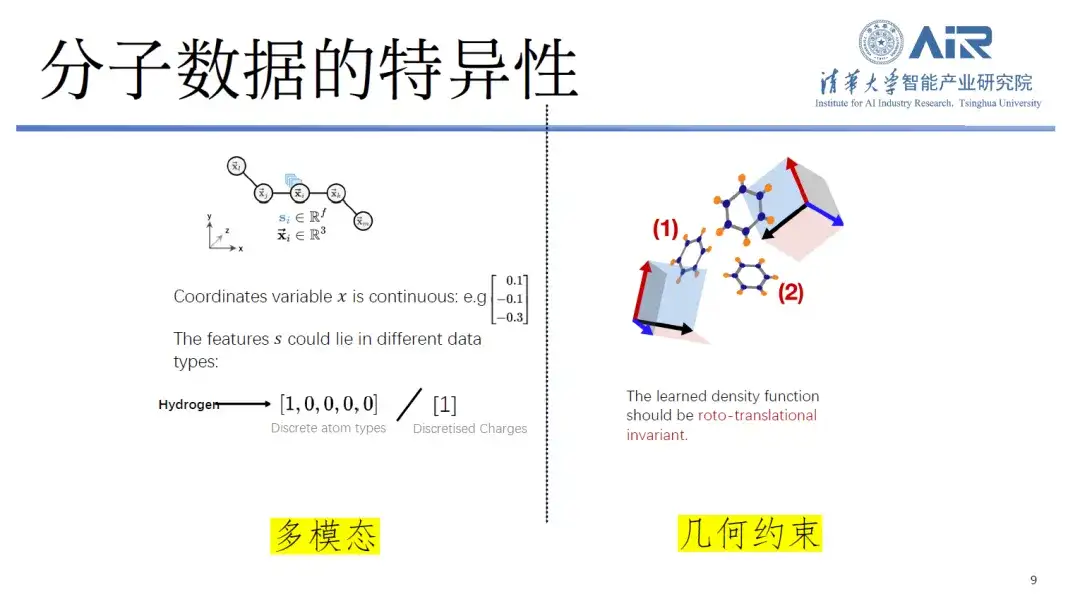
Erstens die Spezifität molekularer Daten.Im Allgemeinen werden Text und Symbole diskret verarbeitet und Bilder sind kontinuierliche Signale zwischen 0 und 1, aber molekulare Daten enthalten sowohl diskrete als auch kontinuierliche Elemente.
Wenn Forscher beispielsweise Moleküle in Computern speichern, stellen sie diese üblicherweise als Atomkoordinaten und Atomtypen dar, wobei Atomkoordinaten kontinuierlich und Atomtypen diskret sind, wodurch eine Art multimodaler Daten entsteht, die schwer zu verarbeiten sind. Darüber hinaus unterliegen Moleküle auch geometrischen Einschränkungen, wie etwa der Invarianz gegenüber Rotation und Translation, die bei der Text- oder Bildverarbeitung nicht üblich sind.
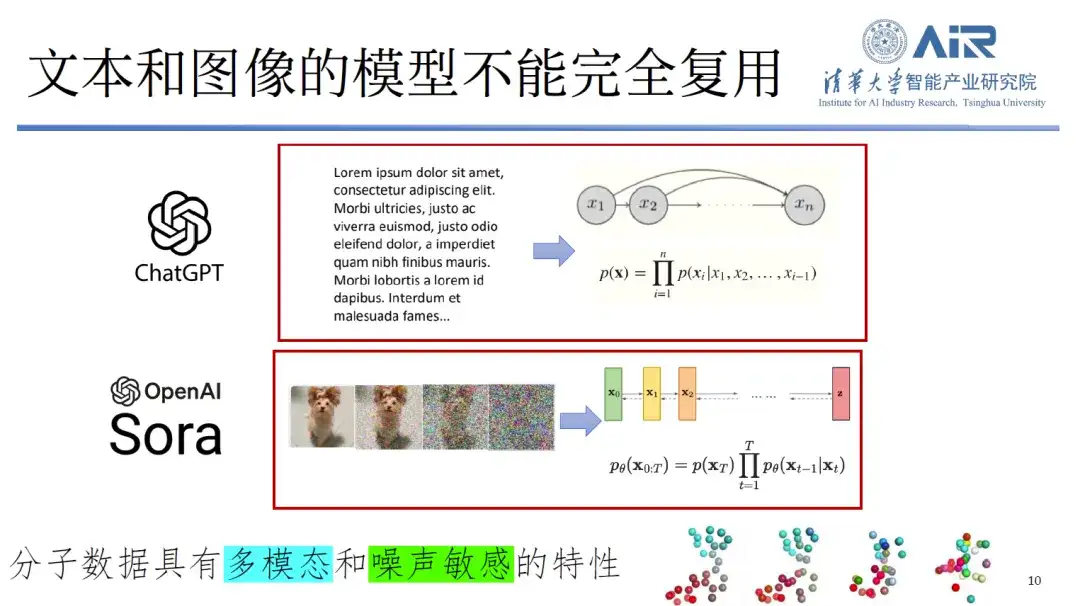
Zweitens können Text- und Bildmodelle im Proteinbereich nicht vollständig wiederverwendet werden.Molekulare Daten sind nicht nur multimodal, sondern auch äußerst empfindlich gegenüber Rauschen. Wenn beispielsweise einem Hundebild Rauschen hinzugefügt wird, können Menschen immer noch erkennen, dass es sich um ein Hundebild handelt. Wenn den molekularen Daten jedoch auch nur eine winzige Menge Rauschen hinzugefügt wird, kann es sein, dass die Identität des Moleküls nicht mehr erkannt werden kann, was zu einem großen Informationsverlust führt. Daher sind herkömmliche Verarbeitungsmethoden auf diesen neuen Datentyp nicht in vollem Umfang anwendbar.
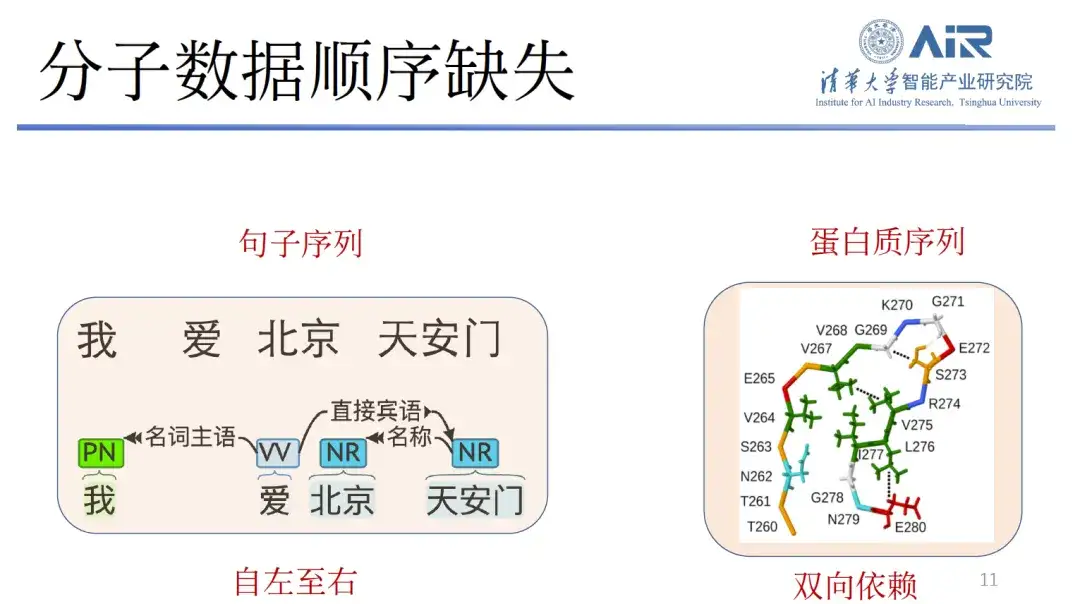
Drittens fehlen die molekularen Daten in der Sequenz.Der Text ist kaum von der Schreibrichtung von links nach rechts abhängig, sodass über GPT neuer Text von links nach rechts generiert werden kann. Allerdings weisen Proteine sehr starke bidirektionale Abhängigkeiten auf und ihre Reihenfolge von vorne nach hinten und von links nach rechts lässt sich nur schwer bestimmen. Die direkte Verwendung von Text- oder Bildmodellen zur Generierung molekularer Strukturen wird äußerst schwierig sein.
Um die oben genannten Herausforderungen zu meistern,Das Team von Professor Zhou Hao hat eingehende Untersuchungen zur Datenstruktur, zum Generierungsalgorithmus und zur Basiskonstruktion durchgeführt.
Ausgehend von der Datenstruktur den intrinsischen Datencharakterisierungsraum finden
Behalten Sie nur die Freiheitsgrade des Diederwinkels bei, um die 3D-Strukturdarstellung des Moleküls zu rekonstruieren
„Die Bestimmung des Eigenraums eines Moleküls oder einer Zieldatenstruktur ist ein Problem, das Informatiker lösen müssen.“Professor Zhou Hao sagte, dass die dreidimensionale Strukturdarstellung von Molekülen sehr wichtig sei und man sagen könne, dass Struktur Funktion sei. In der Vergangenheit erlangten Forscher die erforderlichen Informationen hauptsächlich durch die Aufzeichnung der Koordinaten und Arten von Atomen, um Molekülmodelle zu erstellen. Die Struktur eines Moleküls ist jedoch groß und enthält viele redundante Informationen. Wenn es auf die Art modelliert wird, wie es in der Vergangenheit getan wurde, handelt es sich aus Sicht der Informatik nicht um eine Beobachtung im Eigenraum des Moleküls.
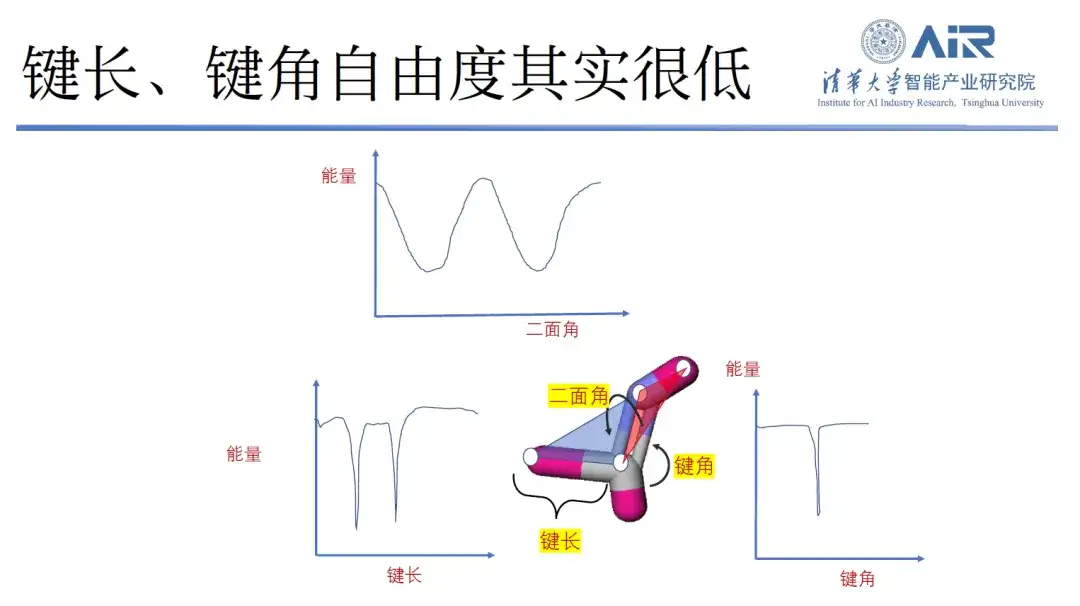
Tatsächlich lässt sich durch die Analyse der Bindungslänge, des Bindungswinkels und des Diederwinkels des Moleküls feststellen, dass die molekulare Bindungslänge und der Bindungswinkel weniger Spitzen und eingeschränkte Freiheitsgrade aufweisen, während der Diederwinkel mehr Freiheitsgrade aufweist. Aus diesem Grund hat das Team von Professor Zhou Hao eine neue Methode entwickelt.Das heißt, während der Freiheitsgrad des Flächenwinkels erhalten bleibt, werden andere redundante Freiheitsgrade entfernt.
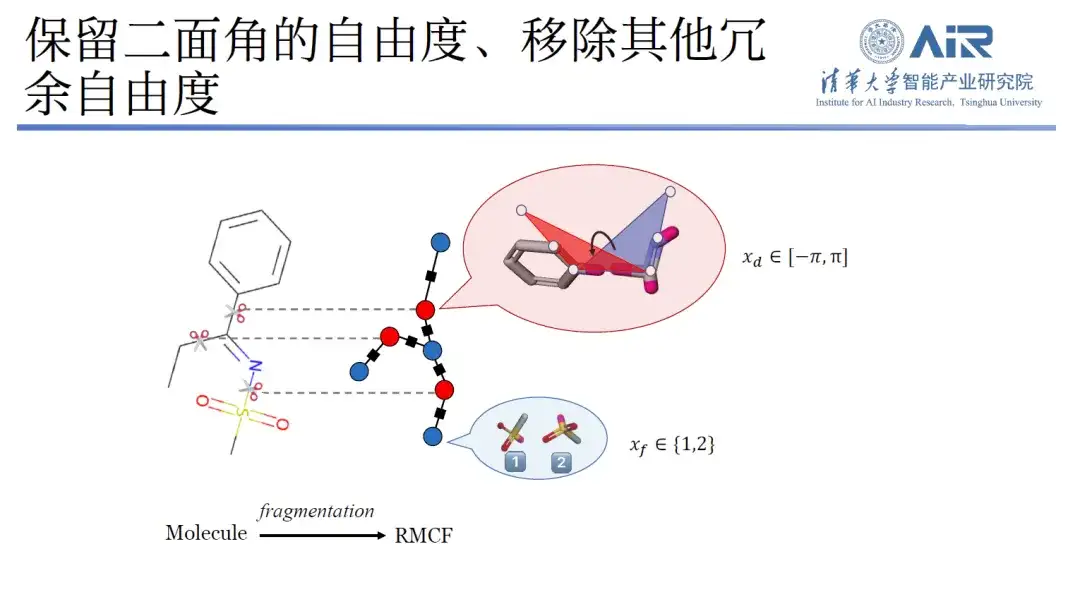
Insbesondere kann die Forschung die dreidimensionale Struktur in eine zweidimensionale Darstellung umwandeln und durch die Verarbeitung molekularer Fragmentierung die Freiheitsgrade innerhalb jedes Moleküls minimieren und die Freiheitsgrade zwischen den Fragmenten maximieren. Mithilfe der dynamischen Programmiertechnologie kann das Min-Max-Problem einfach gelöst werden, und anschließend können alle Moleküle mithilfe eines Algorithmus in die Zieldatenstruktur geschnitten werden.
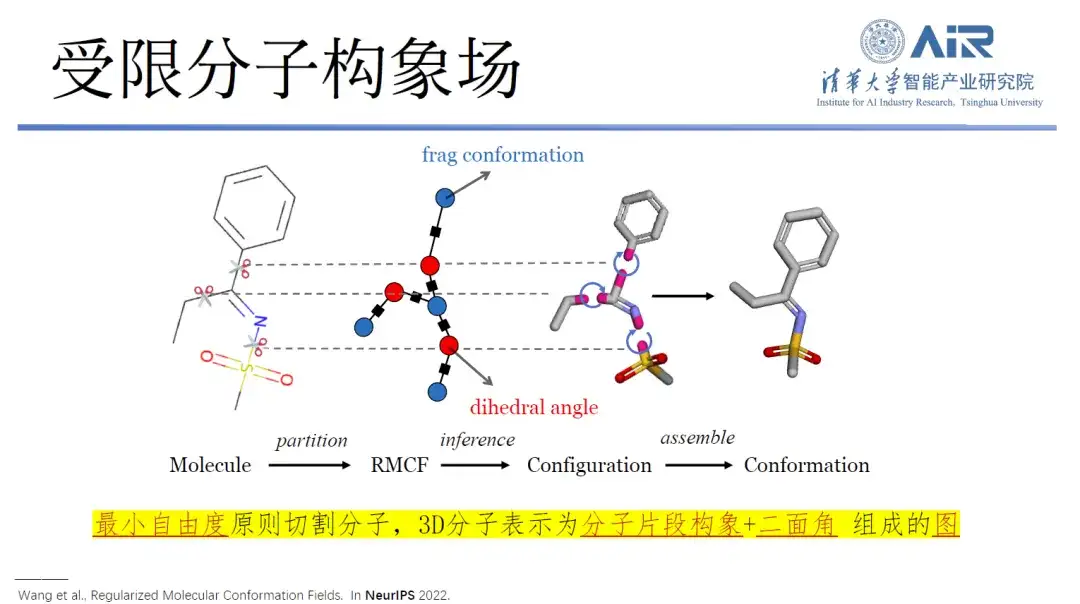
Titel des Artikels:Regularisierte molekulare Konformationsfelder
Link zum Artikel:https://neurips.cc/virtual/2022/poster/53277
„Mit dieser neuen Datenstruktur können in Zukunft relevante Forschungsarbeiten, wenn Moleküle erzeugt werden müssen, den molekularen Raum mit sehr wenigen Daten konstruieren. Diese Idee ist äußerst wichtig!“
Vom Realraum zum Spektralraum: Effiziente Erfassung der Proteingeometrie und chemischer Informationen
Neben der molekularen Forschung interessiert sich das Team von Professor Zhou Hao auch für die Untersuchung der Struktur und Funktion von Proteinen.
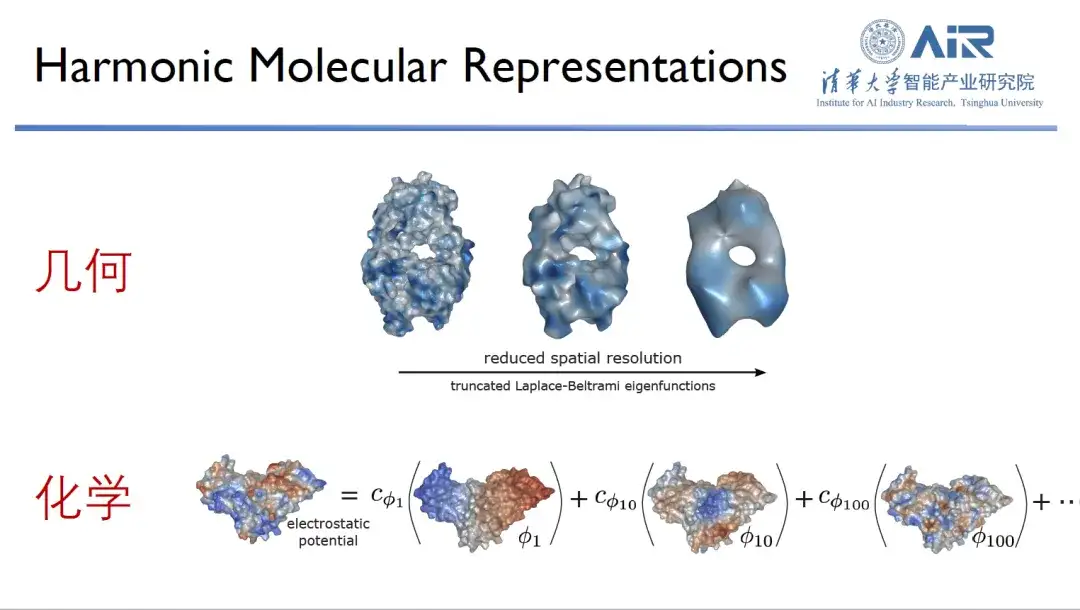
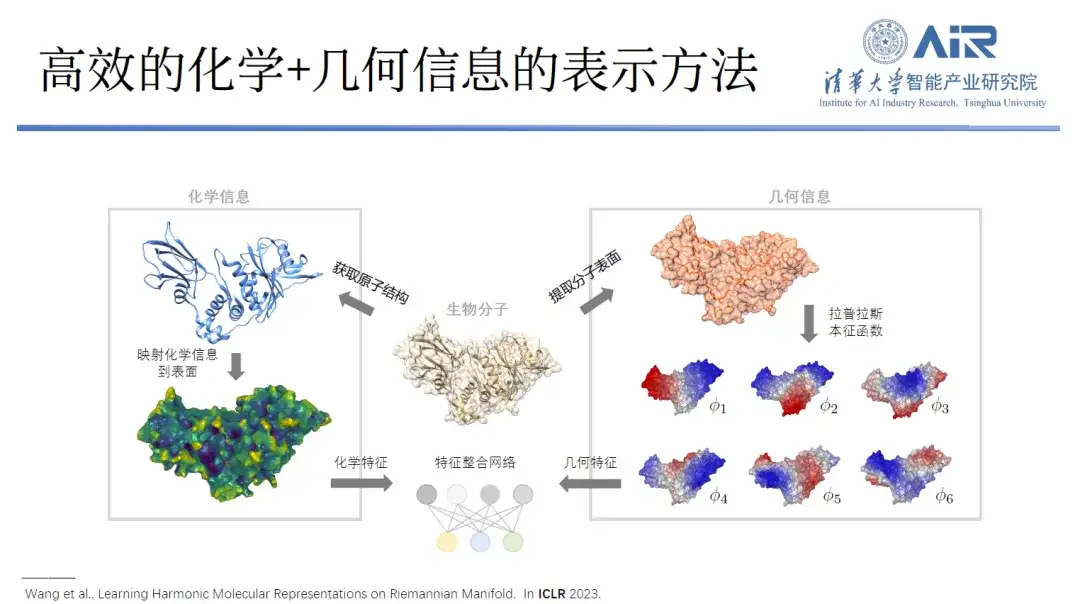
Bei der Untersuchung von Proteinen betrachten Forscher diese normalerweise aus zwei Dimensionen: geometrische Informationen und chemische Informationen. Es ist bekannt, dass die Form und die chemischen Informationen an der Oberfläche eines Proteins entscheidend für seine Funktion sind und dass es nur dann eine optimale Leistung erbringen kann, wenn sich beide ergänzen.
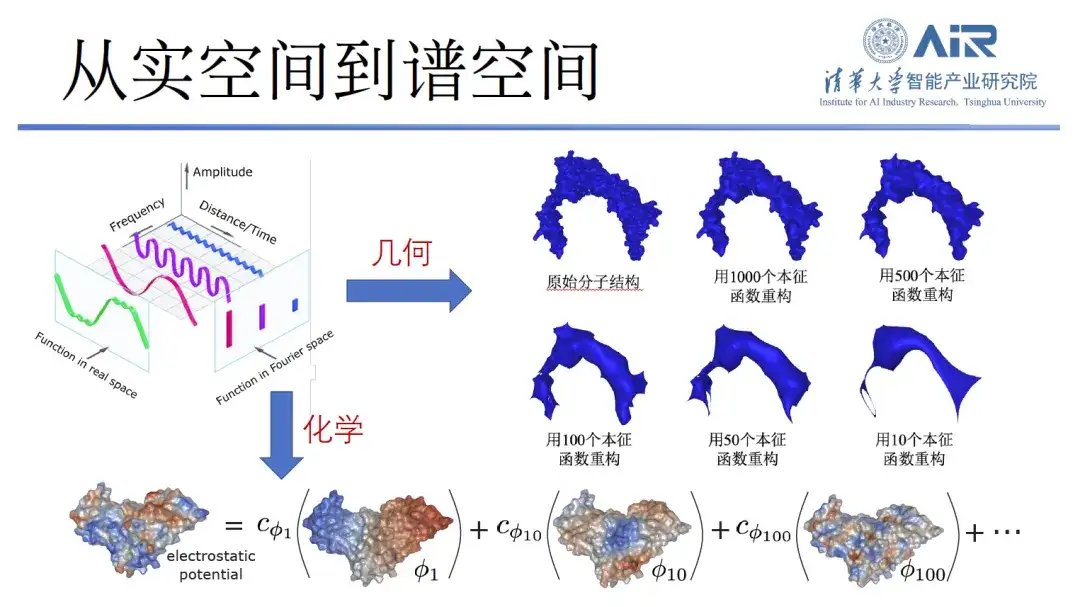
Um die chemischen und geometrischen Informationen von Proteinen effizient darzustellen,Das Team von Professor Zhou Hao transformierte Proteine vom Realraum in den Spektralraum und verwendete dann Eigenfunktionen zur Darstellung der Proteine. Beispielsweise werden 10 Eigenfunktionen verwendet, um die niederfrequenten Informationen eines Proteins zu erfassen und so seine allgemeine Struktur aufzulösen. Darüber hinaus können mehr Eigenfunktionen mehr hochfrequente Informationen erfassen, und durch die Verwendung von 1.000 Eigenfunktionen können fast alle Proteininformationen erfasst werden.
Titel des Artikels:Erlernen harmonischer molekularer Darstellungen auf der Riemannschen Mannigfaltigkeit
Link zum Artikel:https://iclr.cc/virtual/2023/poster/10900
„Der Vorteil dieses Ansatzes besteht darin, dass er nicht nur die geometrischen Informationen des Proteins replizieren kann, sondern auch seine chemischen Informationen.“Jede Eigenfunktion kann als neuer Raum betrachtet werden, und die chemischen Informationen auf der Proteinoberfläche können auf diesen Eigenraum abgebildet werden. Sowohl geometrische als auch chemische Informationen können im selben Raum ausgedrückt werden, und das komplexe Realraumproblem wird in ein einfaches Spektralraumproblem umgewandelt.
Entwurf eines generativen Modells für Aptamere basierend auf einem generativen Algorithmus
Obwohl die kompaktesten und intrinsischsten Molekül- und Proteinräume gefunden wurden, lautet die nächste Frage nach der erfolgreichen Identifizierung dieser Räume:So nutzen Sie generative künstliche Intelligenz, um Zielmoleküle effektiv zu erhalten.
Titel des Artikels:MARS: Markov Molecular Sampling für die multikriterielle Arzneimittelforschung
Link zum Artikel:https://iclr.cc/virtual/2021/poster/3352
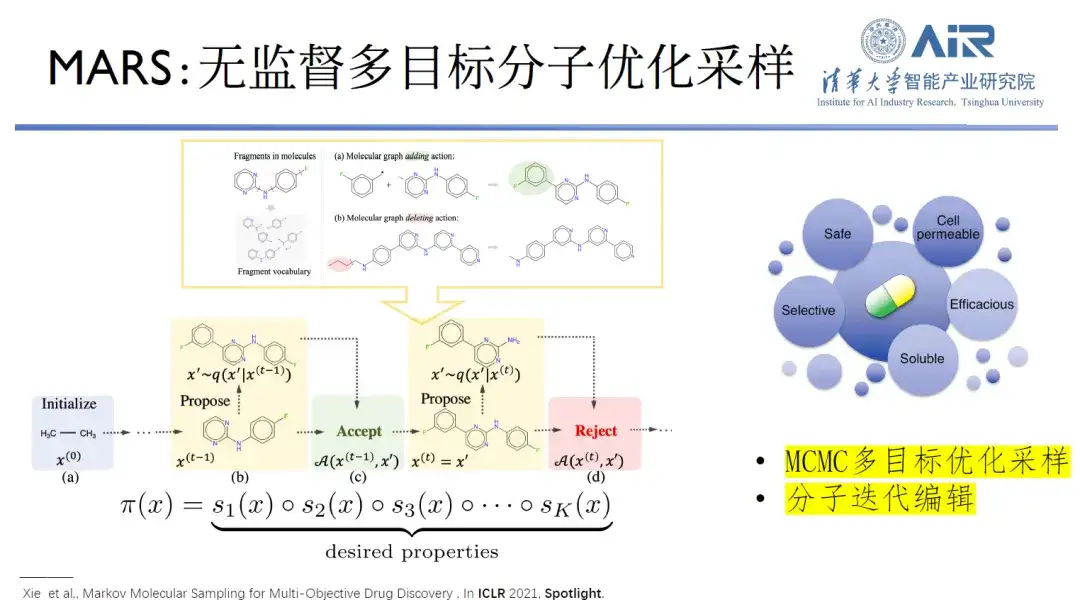
Um das am besten geeignete Molekülgenerationsmodell zu finden,Das Team von Professor Zhou Hao entwickelte ein Modell namens MARS, das unbeaufsichtigte multiobjektive molekulare Optimierungsstichproben verwendet, um ein zweidimensionales Moleküldesign durchzuführen. Der molekulare Designprozess muss mehrere Designziele erfüllen, was ein Stichprobenproblem in einem komplexen hochdimensionalen Raum darstellt. Das Markov-Chain-Monte-Carlo-Framework (MCMC) wird zum Bearbeiten von Molekülen verwendet und jedes Zielmolekül kann generiert werden, wenn sorgfältige Gleichgewichtsbedingungen eingehalten werden.
Titel des Artikels:Äquivariante Flussanpassung mit hybridem Wahrscheinlichkeitstransport
Link zum Artikel:https://neurips.cc/virtual/2023/poster/70795
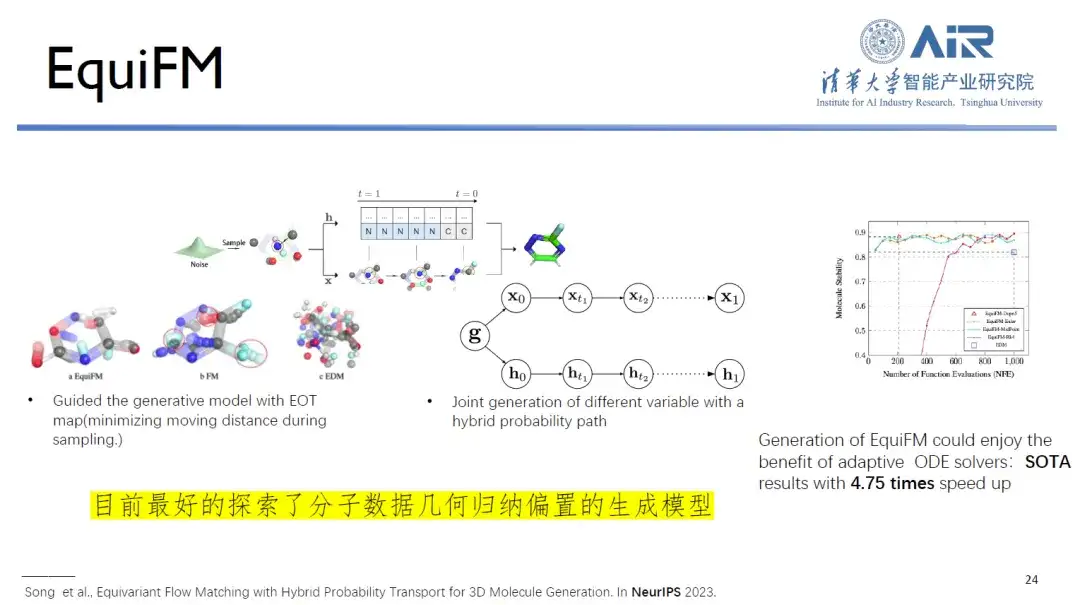
Gleichzeitig ist das von Professor Zhou Haos Team vorgeschlagene EquiFM derzeit das beste generative Modell zur Erforschung der geometrischen induktiven Verzerrung molekularer Daten. Es kann in mehreren Benchmarks zur Molekülgeneration eine gute Leistung erzielen und die durchschnittliche Abtastgeschwindigkeit wird um das 4,75-fache erhöht.
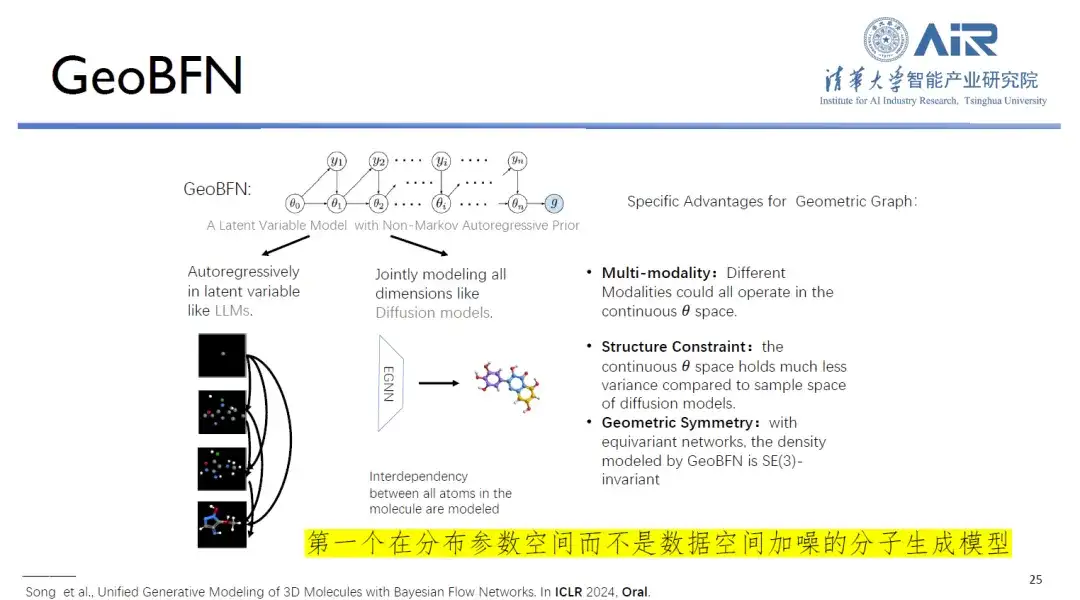
Titel des Artikels:Einheitliche generative Modellierung von 3D-Molekülen über Bayesianische Flussnetzwerke
Link zum Artikel:https://iclr.cc/virtual/2024/oral/19764
Darüber hinaus besteht der Kern des GeoBFN-Modells zur Molekülgenerierung darin, alle Moleküldaten im Datenraum in einen Gaußschen Mittelwert-Varianz-Raum zu transformieren und so Moleküle mit hoher Legitimität und nahe an der realen Verteilung zu generieren. In diesem Zusammenhang sagte Professor Zhou Hao:„Dies ist derzeit das am besten geeignete tiefe generative Modell für Moleküle und hat großes Entwicklungspotenzial.“
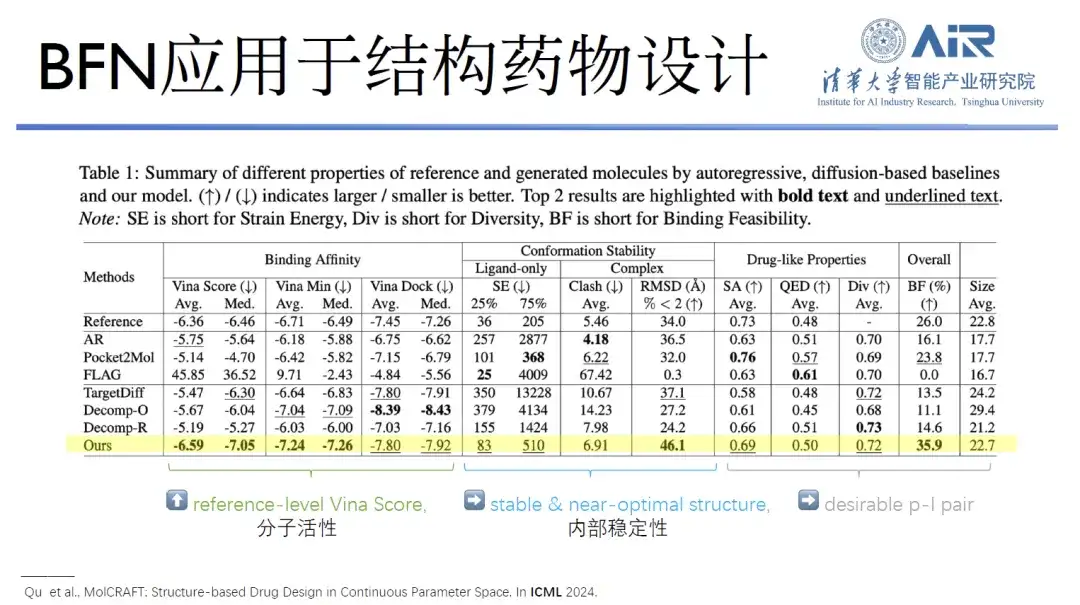
Titel des Artikels:MolCRAFT: Strukturbasiertes Wirkstoffdesign im kontinuierlichen Parameterraum
Link zum Artikel:https://icml.cc/virtual/2024/poster/34336
Zusätzlich zu diesen Arbeiten veröffentlichte das Team von Professor Zhou Hao auch einen Artikel auf der International Conference on Machine Learning (ICML), um die Möglichkeit der Anwendung von GeoBFN auf strukturbasiertes Arzneimitteldesign zu untersuchen. Die Ergebnisse zeigten, dass die mit diesem Modell erzeugten Moleküle sehr stabile Konformationen und eine gute Aktivität aufweisen.
Beginnen Sie mit dem Aufbau der Grundlagen und legen Sie vor dem Training eine Grundlage mit umfassendem Datenwissen fest.
Abschließend erklärte Professor Zhou Hao allen, wie man ausgehend vom Basisaufbau eine Vortrainingsbasis mit umfangreichem Datenwissen aufbaut.
In der bestehenden Forschung sind experimentelle Daten zur Erzeugung kleiner Moleküle sehr spärlich, und der Versuch, dieses Problem mithilfe von Methoden der Informatik zu lösen, ist eine wichtige Idee.
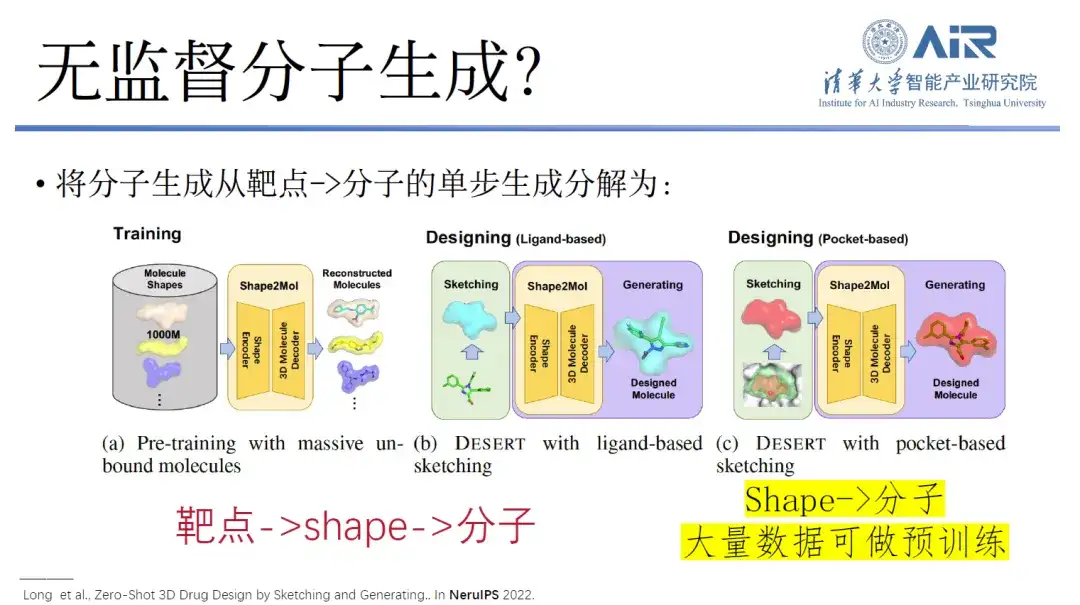
Titel des Artikels:Zero-Shot 3D-Arzneimitteldesign durch Skizzieren und Generieren
Link zum Artikel:https://neurips.cc/virtual/2022/poster/54457
In diesem Zusammenhang hat das Team von Professor Zhou Hao eine neue Idee vorgeschlagen.Das heißt, die einstufige Erzeugung von Molekülen vom Ziel zum Molekül wird in einen Prozess vom Ziel zur Form und dann von der Form zum Molekül zerlegt.Tatsächlich ist die Datenmenge, die direkt vom Ziel zum Molekül übertragen wird, zwar gering, die Datenmenge, die von der Form zum Molekül übertragen wird, ist jedoch sehr groß. Diese Daten reichen aus, um verschiedene Formen vom Ziel zu sammeln und dann ein Vortrainingsmodell im supergroßen Maßstab von der Form bis zum Molekül zu erstellen. Schließlich können wir den Übergang vom Ziel zum Molekül schnell realisieren und sogar ein unbeaufsichtigtes oder minimal überwachtes Arzneimittelmoleküldesign erreichen.
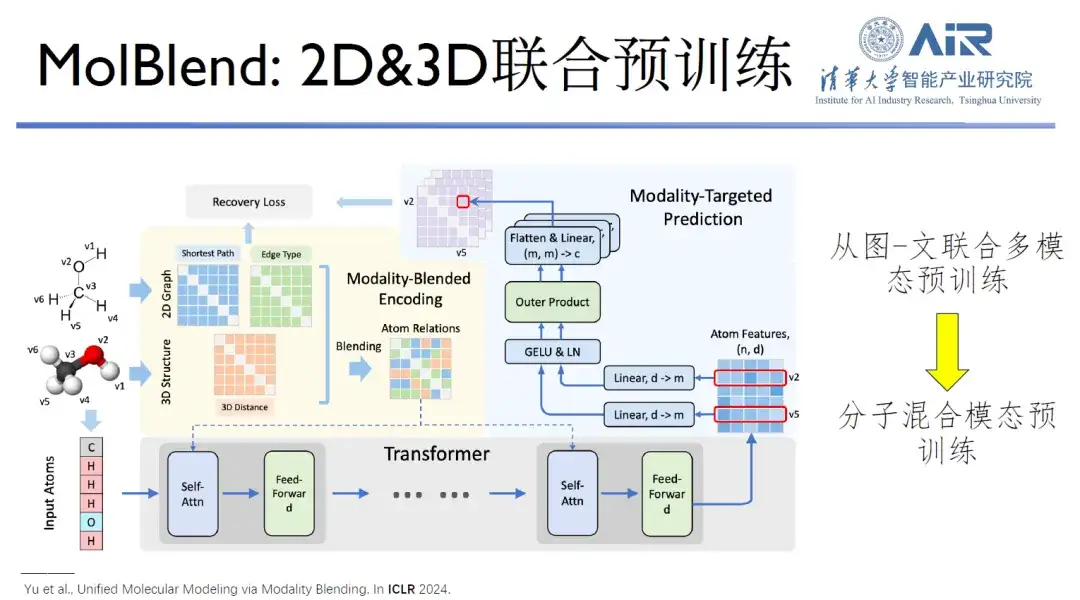
Titel des Artikels:Multimodales molekulares Vortraining durch Modalitätsmischung
Link zum Artikel:https://iclr.cc/virtual/2024/poster/17824
Darüber hinaus realisiert das von ihnen vorgeschlagene MolBlend-Modell das gemeinsame Vortraining zweidimensionaler und dreidimensionaler Moleküle, was ein typischer Fall der Erweiterung vom Bild- und Textvortraining zum molekularen Vortraining ist.
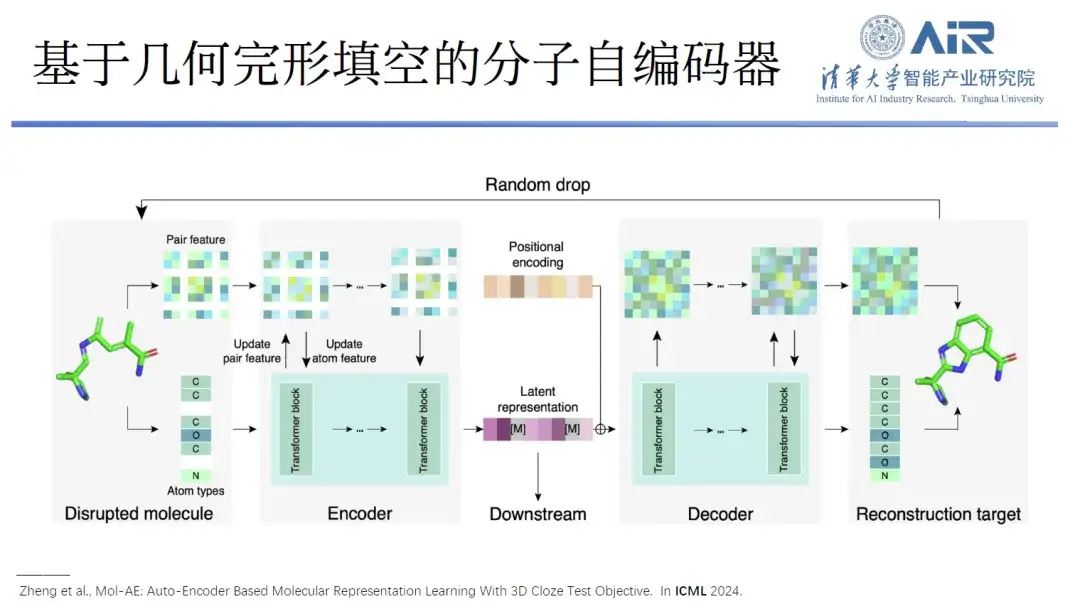
Titel des Artikels:Mol-AE: Auto-Encoder-basiertes Lernen molekularer Darstellungen mit 3D-Lückentext-Ziel
Link zum Artikel:https://icml.cc/virtual/2024/poster/33340
Zusätzlich,Sie schlugen außerdem einen molekularen Autoencoder Mol-AE auf Basis geometrischer Cloze-Verfahren vor.Mit den neuen Trainingszielen des 3D-Cloze-Tests kann das vorgeschlagene Modell die räumlichen Beziehungen von Atomen in realen Molekülstrukturen besser erlernen. Im Vergleich zu den fortschrittlichsten 3D-Molekülmodellierungsmethoden erreicht Mol-AE eine erhebliche Leistungsverbesserung.

Sie haben sich auch für die Forschung zum universellen Vortraining von Proteinen entschieden. Es versteht sich, dass das aktuelle allgemeine Vortraining von Proteinen hauptsächlich in drei Kategorien unterteilt ist: DeepMind Alphafold-Serie, David Bakers RoseTTAFold-Serie und Meta ESM-Serie.Das Team von Professor Zhou Hao hat derzeit das ESM-AA-Modell entwickelt.
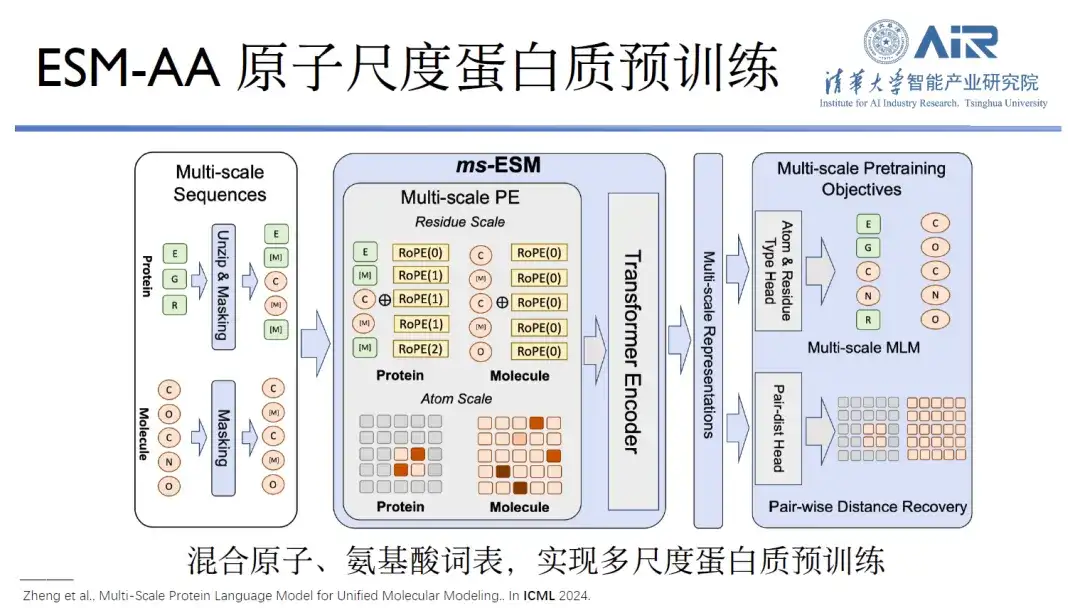
Titel des Artikels:Multiskaliges Proteinsprachenmodell für einheitliche molekulare Modellierung
Link zum Artikel:https://icml.cc/virtual/2024/poster/35119
Dies liegt daran, dass das Upgrade von Alphafold2 auf Alphafold3 eine vollständig atomare Basis aufgebaut hat, und das Gleiche gilt für die RoseTTAFold-Serie. Lediglich die ESM-Reihe verfügt noch nicht über eine vollständig atomare Basis. Daran arbeitet das Team von Professor Zhou Hao seit September letzten Jahres. Durch die Kombination von Atom- und Aminosäurevokabular kann ein Proteintraining auf mehreren Ebenen erreicht werden. Bei der gemeinsamen Aufgabe von Proteinen und kleinen Molekülen schneidet ESM-AA besser ab als einzelne Vortrainingsbasen wie ESM, andere Protein-Vortrainingsbasen oder Vortrainingsbasen für kleine Moleküle.
Auch auf Twitter wurde das vortrainierte Dock vielfach gelobt. Als Vertreter der Sequenzbasis wird ESM-AA mit RoseTTAFold und Alphafold3, Vertretern der Strukturbasis, konkurrieren. „Ich denke, das ist auch unser zukünftiges Ziel“, sagte Professor Zhou Hao.
Über Professor Zhou Hao
Zhou Hao, geboren 1990, PhD, assoziierter Forscher an der Tsinghua-Universität. Sein Forschungsschwerpunkt ist die generative künstliche Intelligenz für komplexe symbolische Systeme. Zu seinen Hauptanwendungen zählen Sprachmodelle im ultragroßen Maßstab, Molekülgenerierung, Proteindesign, Entdeckung neuer Materialien usw.

Er war Forschungswissenschaftler und stellvertretender Direktor bei ByteDance, wo er die F&E-Teams für die Textgenerierungsplattform und das KI-gestützte Arzneimitteldesign von ByteDance leitete. Seine F&E-Produkte werden in mehr als 20 Ländern auf der ganzen Welt eingesetzt und haben eine Benutzerbasis von mehr als 1 Milliarde. Er fungiert seit langem als Fachgebietsleiter führender Konferenzen zum Thema künstliche Intelligenz wie ICML, NeurIPS, ICLR und ACL und hat über 80 Artikel auf wichtigen internationalen Konferenzen zum Thema künstliche Intelligenz veröffentlicht. Er gewann 2019 den Outstanding Doctoral Dissertation Award der China Artificial Intelligence Society, den Best Paper Award (1/3350) der ACL 2021, der wichtigsten internationalen Konferenz im Bereich der Verarbeitung natürlicher Sprache, und 2021 den NLPCC Young Emerging Scholar Award der China Computer Society.








