Command Palette
Search for a command to run...
在线教程|DeepSeek-OCR 2 公式/表格解析同步改善,以低视觉 Token 成本实现近 4% 的性能跃迁

在视觉语言模型(VLMs)的发展进程中,文档 OCR 始终面临着布局解析复杂、语义逻辑对齐等核心挑战。传统模型大多采用固定的「左上到右下」栅格扫描顺序处理视觉 token ,这种刚性流程与人类视觉系统遵循的语义驱动型扫描模式相悖,尤其在处理含复杂公式、表格的文档时,容易因忽视语义关联导致解析误差。如何让模型像人类一样「读懂」视觉逻辑,成为提升文档理解能力的关键突破口。
近期,DeepSeek-AI 推出的 DeepSeek-OCR 2 给出了最新答案。其核心是采用全新 DeepEncoder V2 架构:模型摒弃传统 CLIP 视觉编码器,引入 LLM 风格的视觉编码范式,通过双向注意力与因果注意力的融合,实现视觉 token 的语义驱动式重排,为 2D 图像理解构建出一条「双阶段 1D 因果推理」的新路径。
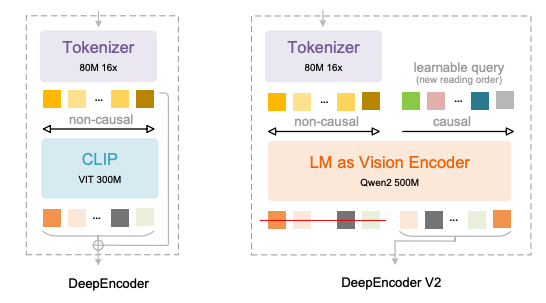
DeepEncoder V2 的关键创新体现在四个方面:
* 以 Qwen2-0.5B 紧凑型 LLM 替代 CLIP,在约 5 亿参数规模下赋予视觉编码因果推理能力;
* 引入与视觉 token 数量等长的「因果流查询(Causal Flow Query)」,通过定制注意力掩码,使视觉 token 保持全局感知,同时允许查询 token 基于语义重组视觉顺序;
* 支持 256–1,120 个视觉 token 的多裁剪策略,在兼顾效率的同时对齐主流大模型的 token 预算;
* 通过「视觉 token + 因果查询」的串联结构,将语义重排与自回归生成解耦,天然适配 LLM 的单向注意力机制。
这一设计有效消除了传统模型的空间顺序偏见,使模型能够像人类阅读一样,依据语义关系动态组织文本、公式与表格,而非传统机械遵循像素位置。
经验证,在 OmniDocBench v1.5 基准测试中,DeepSeek-OCR 2 以 1,120 的视觉 token 上限,实现了 91.09% 的整体准确率,较前代模型提升 3.73%,同时将阅读顺序编辑距离(ED)从 0.085 降至 0.057,证明其视觉逻辑理解能力显著增强。细分任务中,公式解析准确率提升 6.17%,表格理解性能提升 2.5%-3.05%,文本编辑距离减少 0.025,各项核心指标均实现跨越式进步。
同时,其工程实用性同样突出:在保持 16 倍视觉 token 压缩率的前提下,在线服务的重复率从 6.25% 降至 4.17%,PDF 批量处理重复率从 3.69% 降至 2.88%,兼顾了学术创新与产业应用需求。相较同类模型,DeepSeek-OCR 2 以更低的视觉 token 成本,达到了接近甚至超越大参数模型的效果,为资源受限场景下的高精度文档 OCR 提供了更具性价比的方案。
目前,「DeepSeek-OCR 2:视觉因果流」已上线至 HyperAI 超神经官网的「教程」板块,点击下方链接即可体验一键部署教程 ⬇️
教程链接:https://go.hyper.ai/2ma8d
查看相关论文:https://go.hyper.ai/hE1wW
效果展示:
Demo 运行
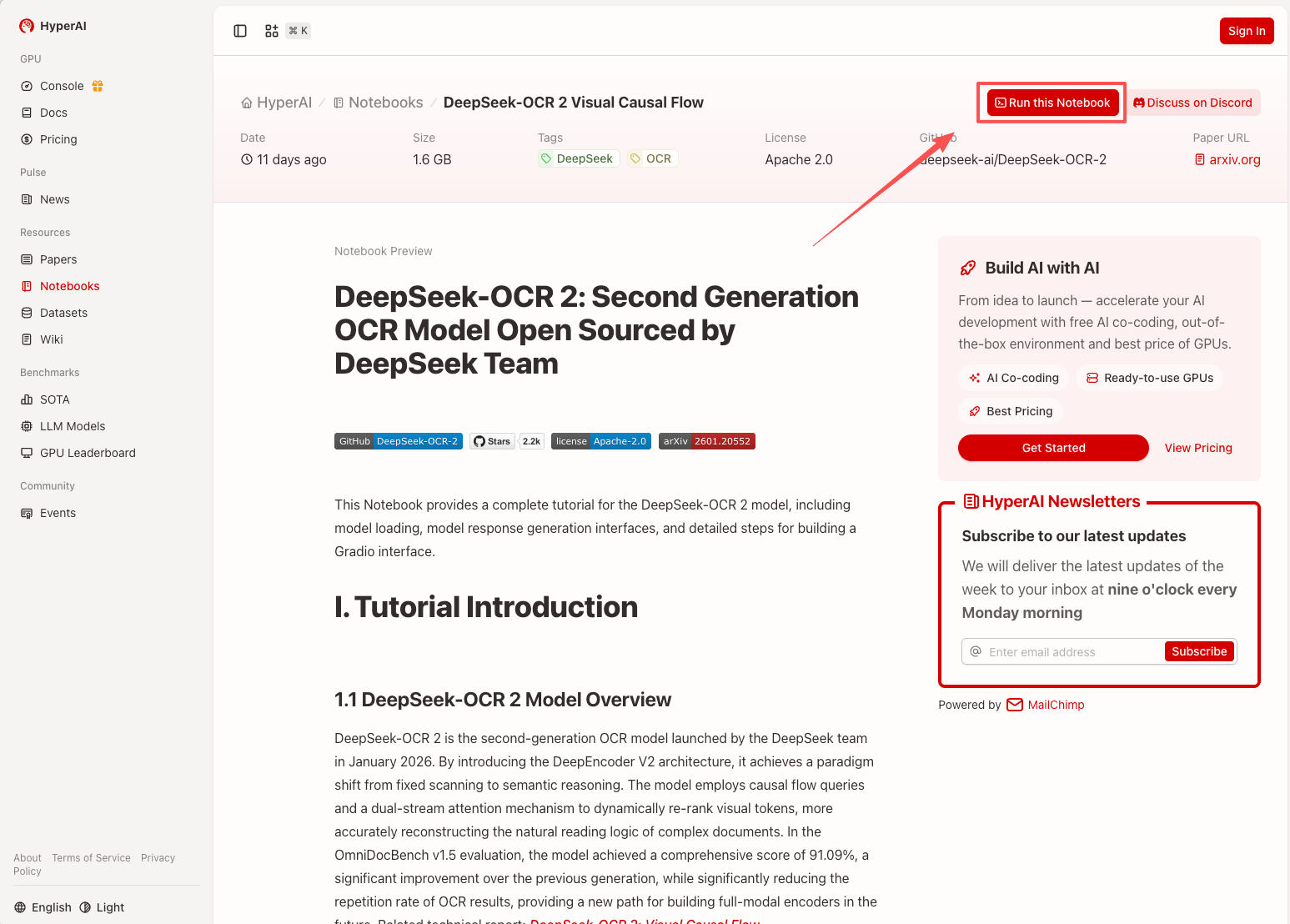
1. 进入 hyper.ai 首页后,选择「教程」页面,或点击「查看更多教程」,选择「DeepSeek-OCR 2 视觉因果流」,点击「在线运行此教程」。

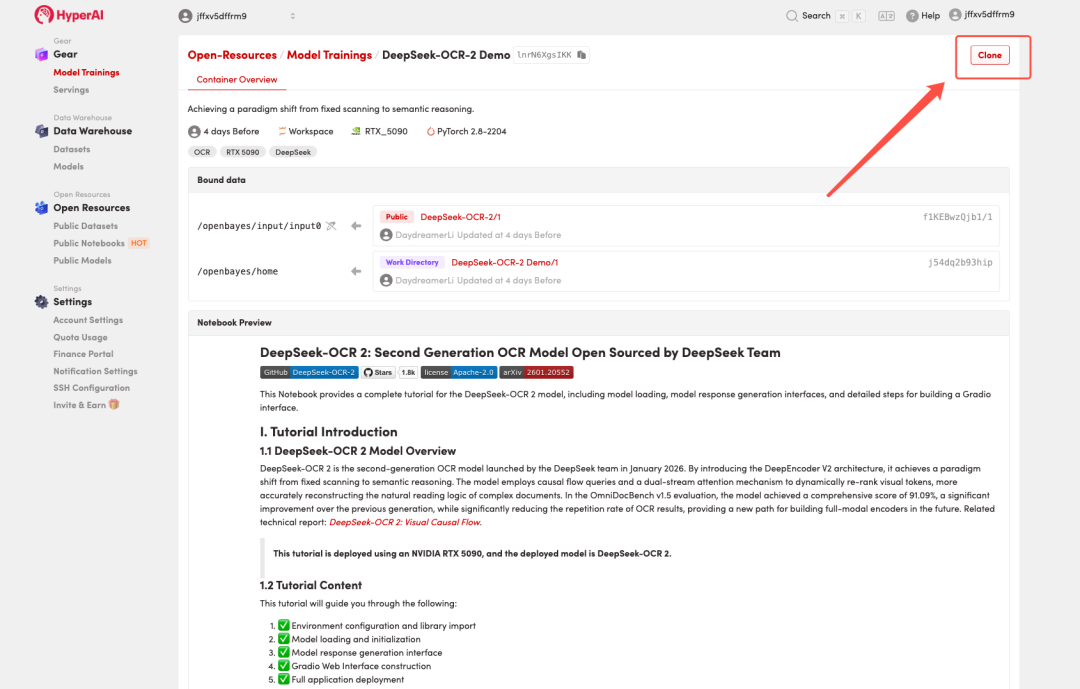
2. 页面跳转后,点击右上角「Clone」,将该教程克隆至自己的容器中。
注:页面右上角支持切换语言,目前提供中文及英文两种语言,本教程文章以英文为例进行步骤展示。
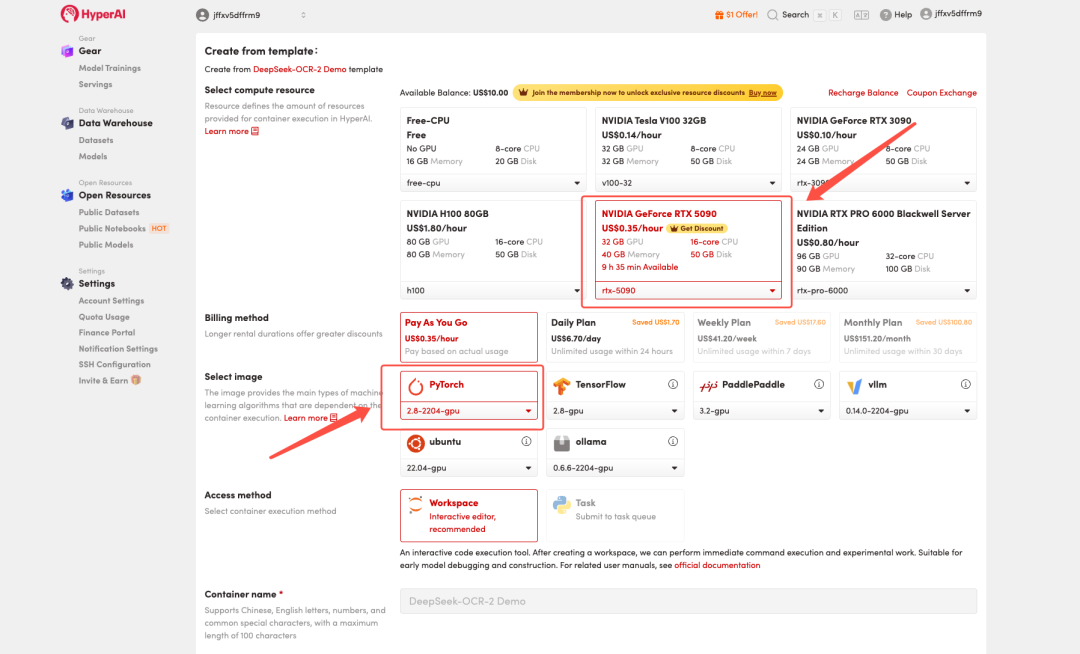
3. 选择「NVIDIA GeForce RTX 5090」以及「PyTorch」镜像,按照需求选择「Pay As You Go(按量付费)」或「Daily Plan/Weekly Plan/Monthly Plan(包日/周/月)」,点击「Continue job execution(继续执行)」。
HyperAI 为新用户准备了注册福利,仅需 $1,即可获得 20 小时 RTX 5090 算力(原价 $7),资源永久有效。
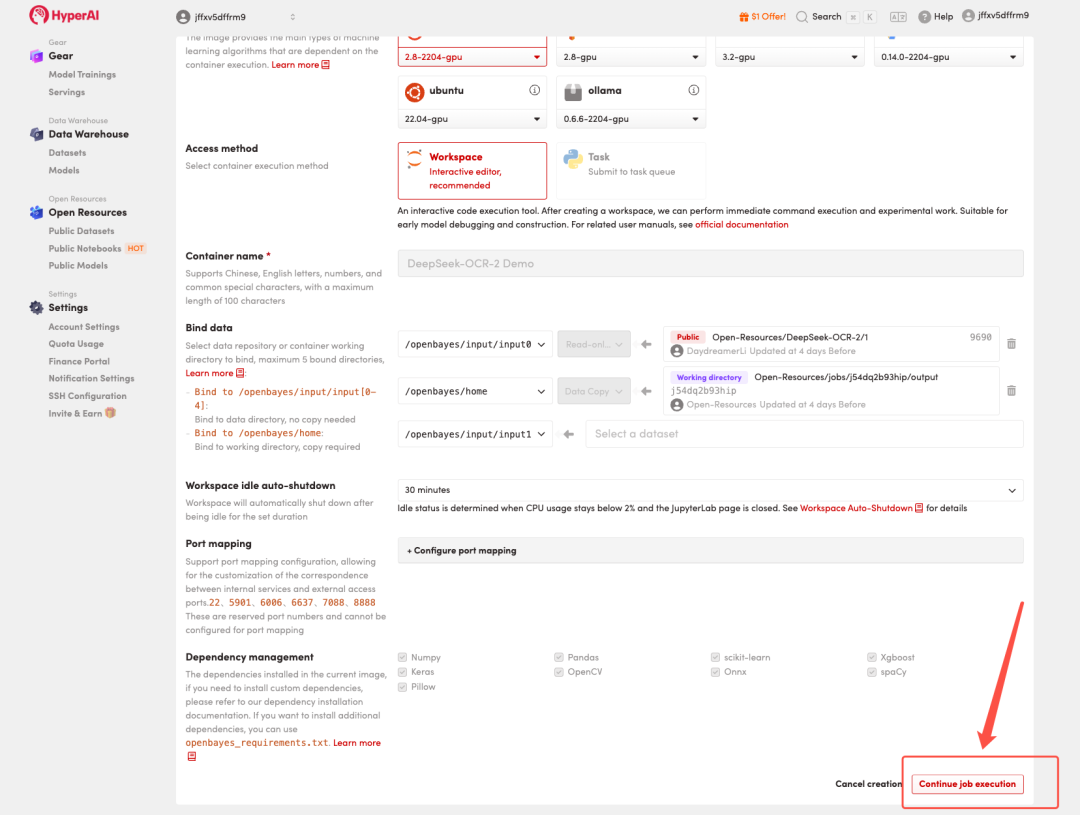
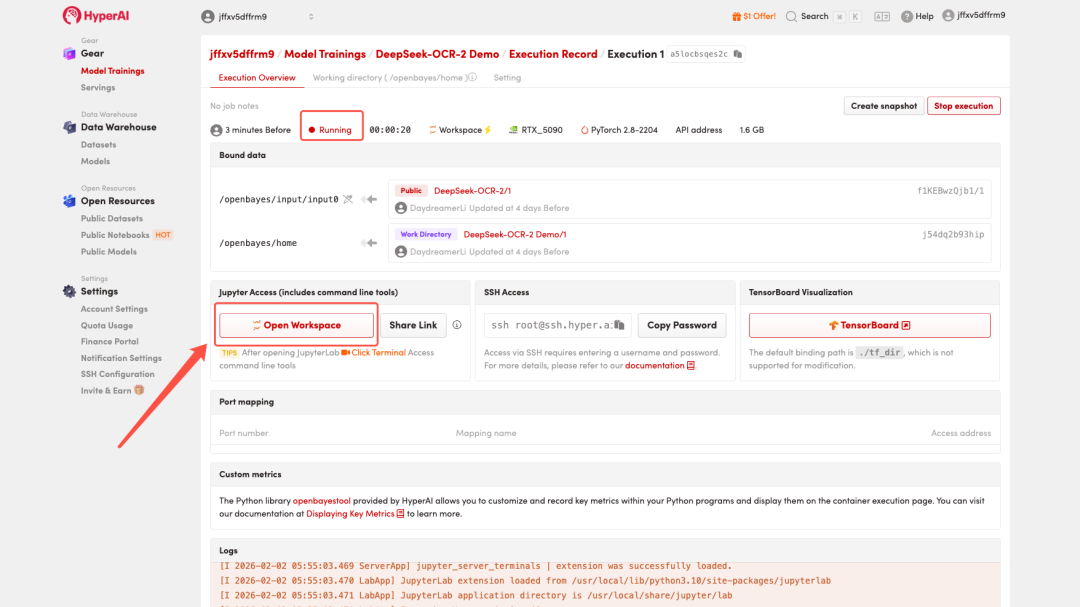
4. 等待分配资源,当状态变为「Running(运行中)」后,点击「Open Workspace」进入 Jupyter Workspace 。
效果演示
页面跳转后,点击左侧 README 页面,进入后点击上方 Run(运行)。
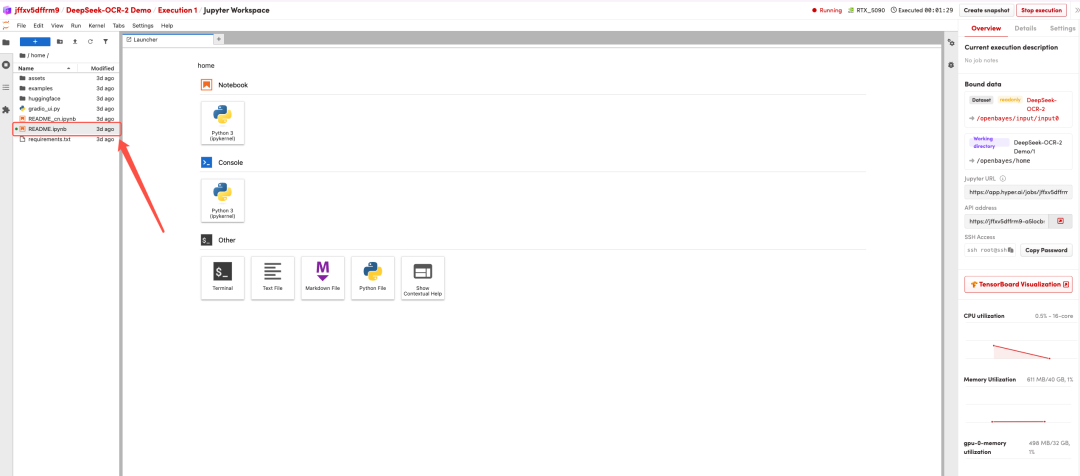
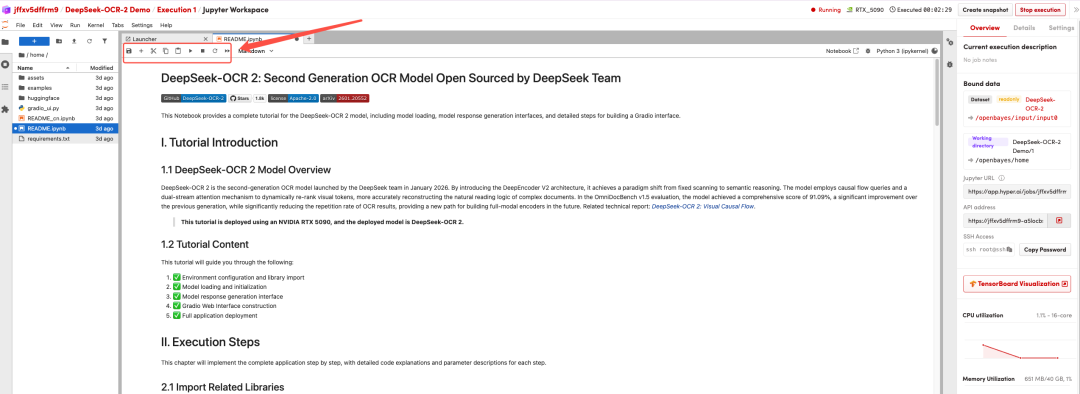
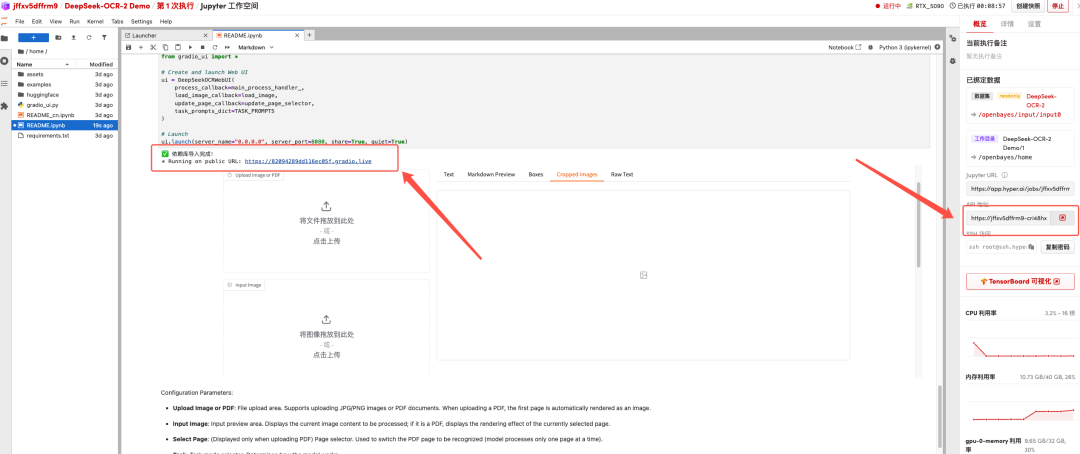
待运行完成,即可点击右侧 API 地址跳转至 demo 页面。
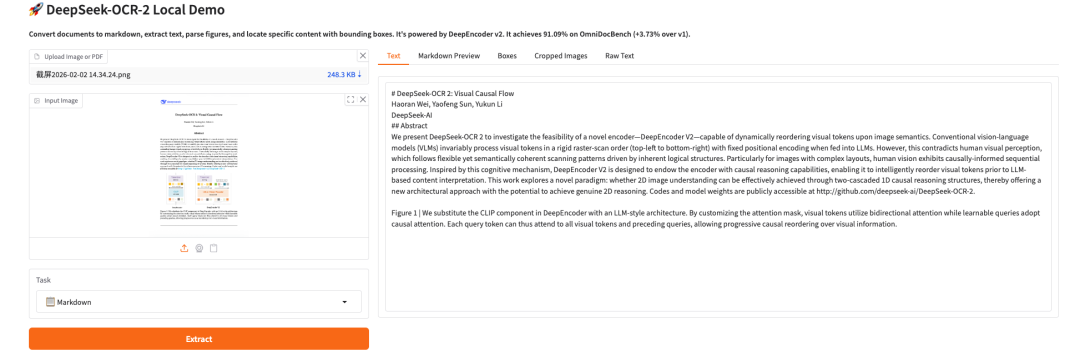
以上就是 HyperAI 超神经本期推荐的教程,欢迎大家前来体验!








