Command Palette
Search for a command to run...
在线教程| 腾讯混元开源端侧翻译工具 HY-MT1.5,1.8B 模型仅需 1G 内存
在机器翻译领域,传统的高性能模型往往面临两个核心难题。对于主流语言,闭源商业模型效果出众但调用成本高,模型参数量动辄百亿级别,需要高昂的算力支持,难以在手机等消费级设备上部署。另一方面,对于数据稀缺的低资源小语种,以及包含专业术语、文化特定表达的文本,模型翻译质量常常不佳,容易出现幻觉问题或语义偏差。这导致用户在日常和移动场景下,常常在高质量、高成本的云端服务与本地化、轻量化但效果不足的方案之间难以抉择。
基于此,腾讯混元团队近日正式开源了全新翻译模型 HY-MT1.5 。本次开源包含两个参数规模的版本:专为移动端设计的 Tencent-HY-MT1.5-1.8B 和面向高性能场景的 Tencent-HY-MT1.5-7B,支持 33 个语种的互译及 5 种中国少数民族语言/方言与汉语的互译,除中、英、日等常见语种外,涵盖捷克语、冰岛语等多个小语种。
* HY-MT1.5-1.8B:
经过量化后,该模型仅需约 1GB 内存即可在手机等端侧设备流畅运行,支持离线实时翻译。模型效率突出,处理 50 tokens 的平均耗时仅 0.18 秒,在 Flores200 等权威测试集上,其效果全面超越中等尺寸开源模型和主流商用 API,达到顶尖闭源模型的 90 分位水平。
* HY-MT1.5-7B:
该模型是腾讯此前在 WMT25 国际翻译比赛中斩获 30 个语种冠军的升级版,重点提升了翻译准确率,并大幅减少了译文夹带无关注释或语种混杂的问题。
具体而言,HY-MT1.5 的创新性在于通过独创的技术方案,有效解决了「轻量化部署」与「高精度翻译」之间的矛盾。其采用了「On-Policy Distillation(大尺寸模型蒸馏)」策略,即令效果更强的 7B 模型作为「教师」,在训练过程中实时引导参数规模为 1.8B 的「学生」模型,纠正其预测偏差,从而让小模型从错误中学习,而非死记硬背。这使得小参数模型获得了超越自身规模的翻译能力。
目前,「HY-MT1.5-1.8B:多语言神经机器翻译模型」已上线 HyperAI 官网(hyper.ai)的教程版块,快来体验极速翻译吧~
HyperAI 超神经还为大家准备了算力福利,新用户注册后使用兑换码「HY-MT」即可获得 2 小时 NVIDIA GeForce RTX 5090 使用时长,数量有限,快来领取吧!
在线运行:https://go.hyper.ai/I0pdR
Demo 运行
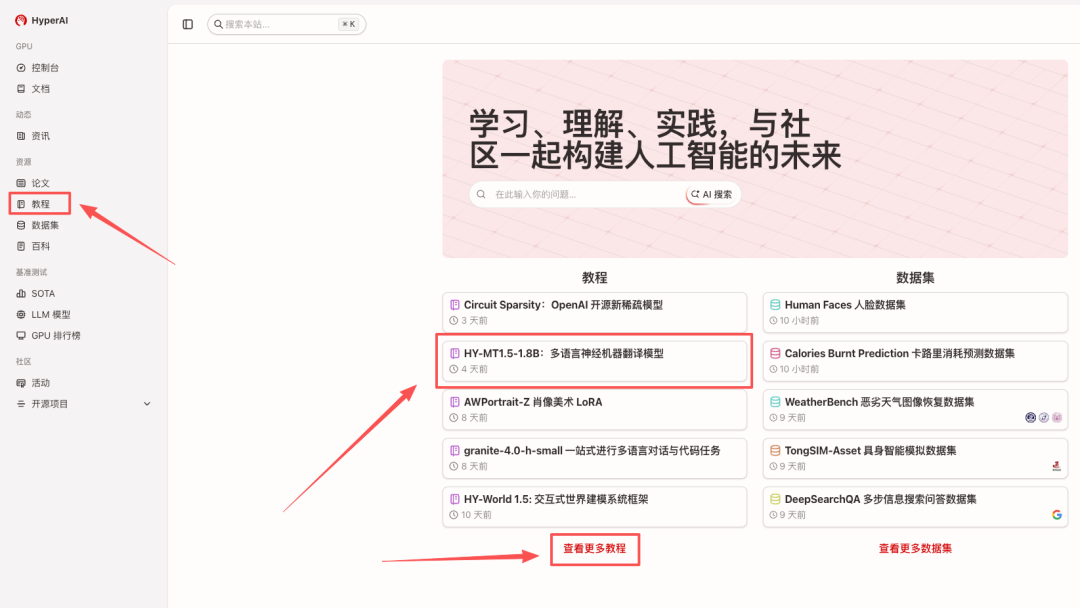
1. 进入 hyper.ai 首页后,选择「HY-MT1.5-1.8B:多语言神经机器翻译模型」,或进入「教程」页面选择。页面跳转后,点击「在线运行此教程」。
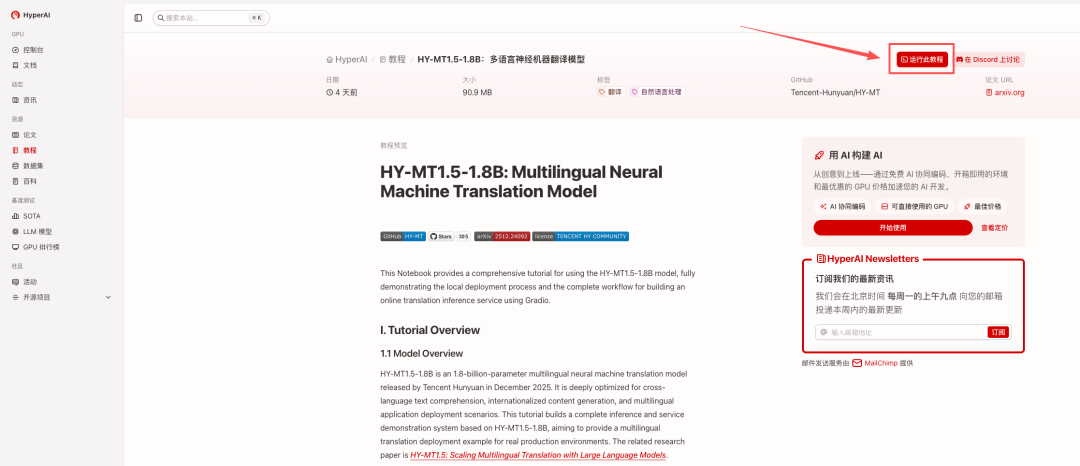
2. 页面跳转后,点击右上角「克隆」,将该教程克隆至自己的容器中。
注:页面右上角支持切换语言,目前提供中文及英文两种语言,本教程文章以英文为例进行步骤展示。
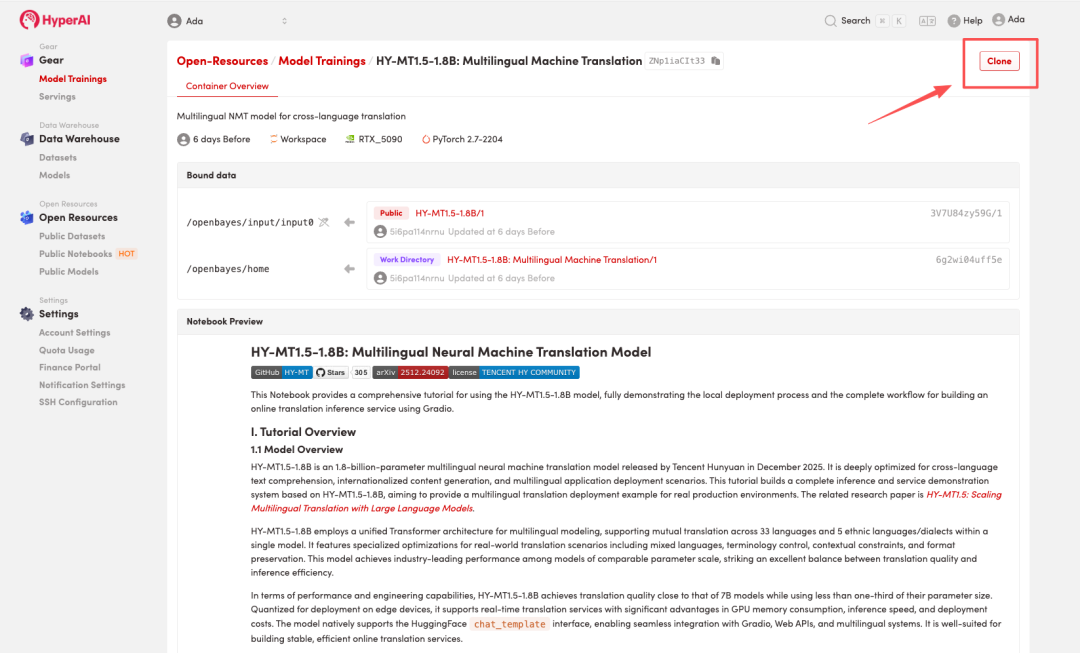
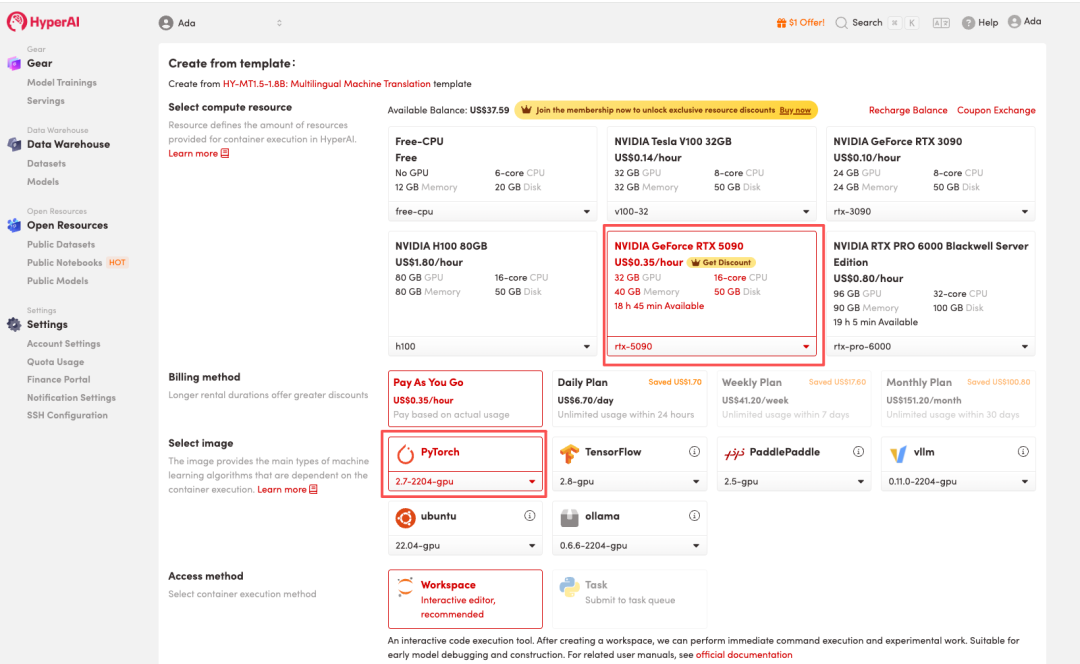
3. 选择「NVIDIA GeForce RTX 5090」以及「PyTorch」镜像,按照需求选择「Pay As You Go(按量付费)」或「Daily Plan/Weekly Plan/Monthly Plan(包日/周/月」,点击「Continue job execution(继续执行)」。
HyperAI 为新用户准备了注册福利,仅需 $1,即可获得 20 小时 RTX 5090 算力(原价 $7),资源永久有效。
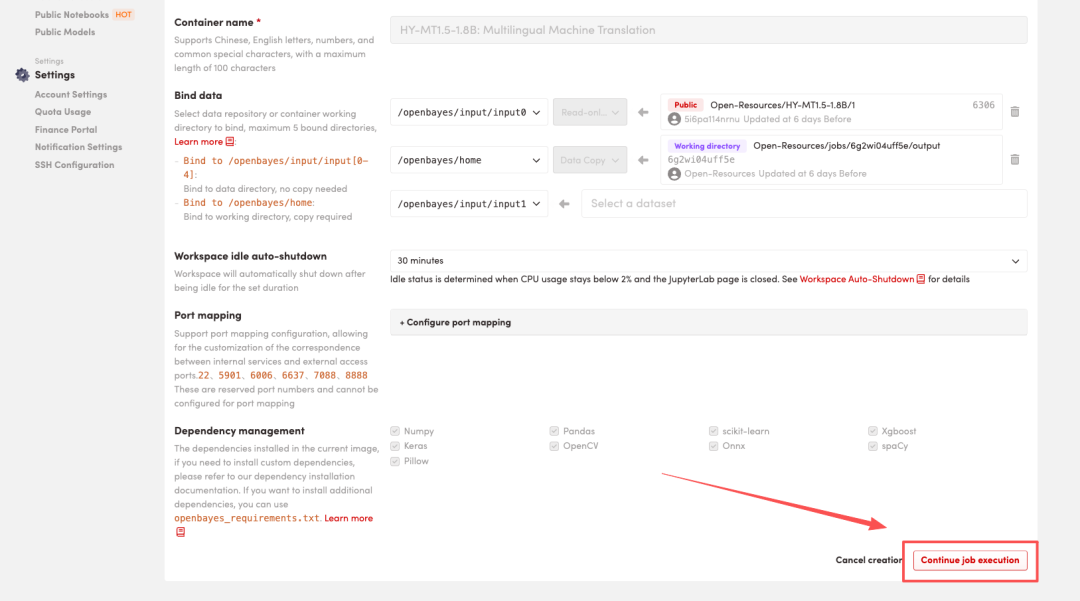
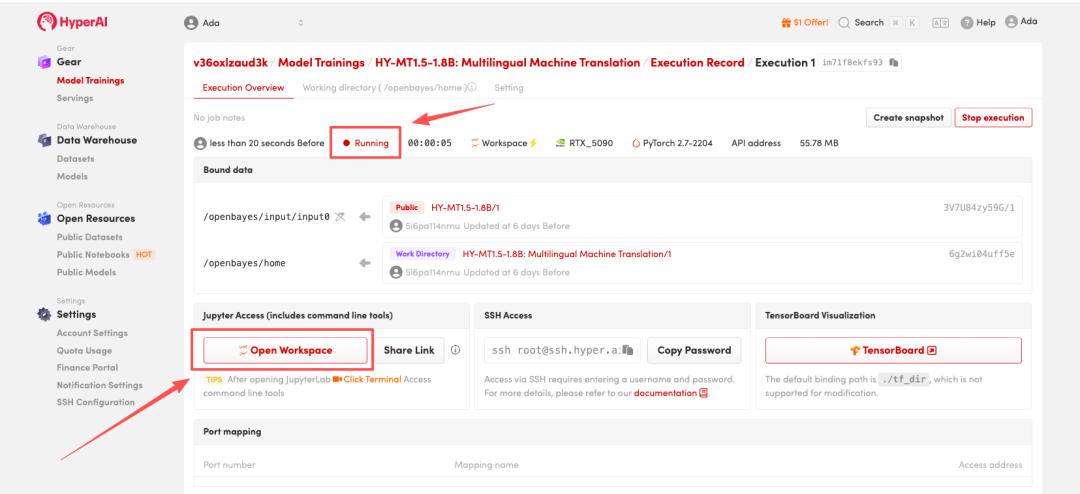
4. 等待分配资源,当状态变为「Running(运行中)」后,点击「Open Workspace」进入 Jupyter Workspace 。
效果演示
页面跳转后,点击左侧 README 页面,进入后点击上方 Run(运行)。
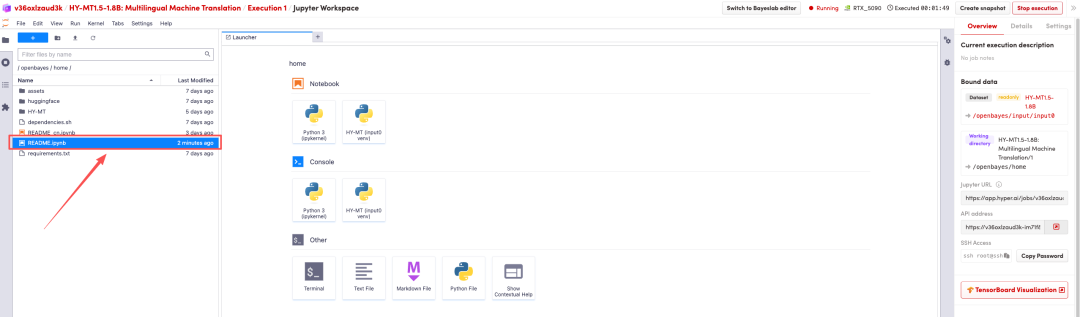
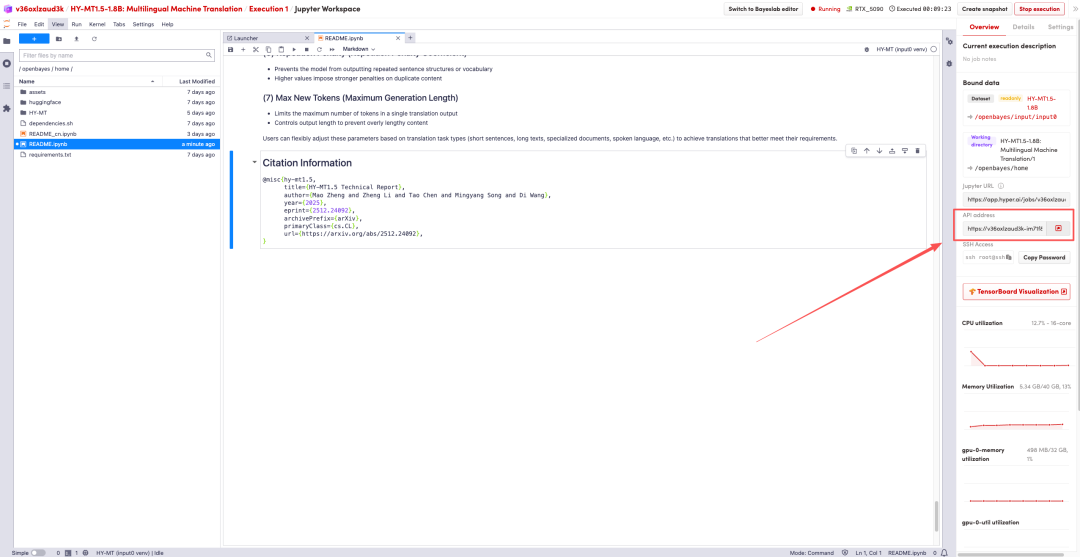
待运行完成,即可点击右侧 API 地址跳转至 demo 页面
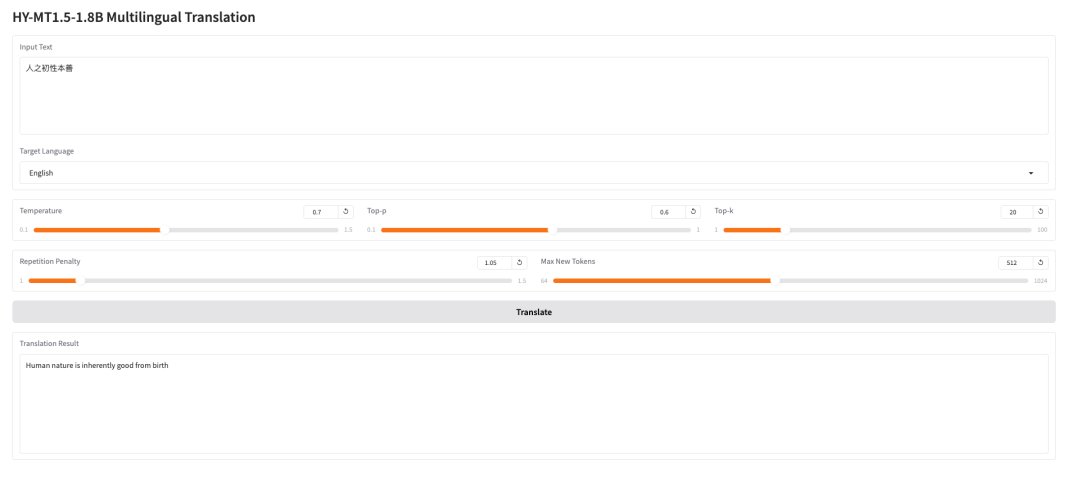
以上就是 HyperAI 超神经本期推荐的教程,欢迎大家前来体验!








