Command Palette
Search for a command to run...
三维视觉新突破:字节 Seed 推出 DA3,实现任意视角重建视觉空间;7w+真实工业环境数据!CHIP 填补 6D 姿态估计工业数据空白

从视觉输入中感知和理解三维空间信息的能力,是空间智能的基石,也是机器人与混合现实(Mixed Reality,ML)等应用的关键需求。这一基础能力催生了多种三维视觉任务,例如单目深度估计(Monocular Depth Estimation)、运动恢复结构(Structure from Motion)、多视图立体视觉(Multi-View Stereo)以及同步定位与建图(Simultaneous Localization and Mapping)。
这些任务往往仅因输入视图数量等个别因素而产生差异,因此在概念上具有高度的重叠性,但目前的主流范式仍是为每项任务开发高度专用的模型。构建能够统一处理多项任务的三维理解模型,已成为重要的研究方向。但现有的解决方案通常依赖于复杂而定制的网络架构,并通过多任务联合优化进行从零训练,因而难以充分吸收和利用大规模预训练模型的知识与优势。
基于此,字节跳动 Seed 团队推出了 Depth Anything 3(DA3),一个经专门训练、基于特定射线表示的单一 Transformer 模型,能够联合任意视角深度和姿态估计。在追求建模极简化的过程中,DA3 带来两个关键发现:
*仅使用一个标准 Transformer(例如 vanilla DINO 编码器)即可作为骨干网络,无需任何任务特定的结构定制;
*仅通过单一的深度射线预测目标,即可实现优异性能,无需复杂的多任务学习机制。
研究团队还建立了涵盖摄像机姿态估计、任意视角几何和视觉渲染的新视觉几何基准。在该测试中,DA3 在所有任务中刷新 SOTA,相机姿态准确率平均比 VGGT 高出 35.7%,几何精度提升 23.6%,单目深度估计方面优于前代模型 DA2 。实验表明,这种极简方法足以从任意数量(无论相机姿态是否已知)的图像中重建视觉空间。
目前,HyperAI 超神经官网已上线了「Depth-Anything-3:从任何视角恢复视觉空间」,快来试试吧~
在线使用:https://go.hyper.ai/MXyML
12 月 15 日-12 月 19 日,hyper.ai 官网更新速览:
* 优质公共数据集:10 个
* 优质教程精选:3 个
* 本周论文推荐: 5 篇
* 社区文章解读:5 篇
* 热门百科词条:5 条
* 1 月截稿顶会:11 个
访问官网:hyper.ai
公共数据集精选
1. VideoRewardBench 视频奖励模型评测数据集
VideoRewardBench 是由中国科学技术大学联合与华为诺亚方舟实验室发布的首个全面覆盖感知、知识、推理和安全四个视频理解核心维度的综合评测基准,旨在系统评估模型在复杂视频理解场景下对生成结果进行偏好判断与质量评估的能力。该数据集共包含 1,563 条带标注的样本,涉及 1,482 个不同视频和 1,559 个不同问题,每个样本由一个视频–文本提示、一个优选响应和一个拒绝响应组成。
直接使用:https://go.hyper.ai/JIB1B
2. Arena-Write 写作生成评测数据集
Arena-Write 是由新加坡科技设计大学联合清华大学知识工程实验室发布的一个面向超长文本生成模型评测的写作任务数据集,旨在在贴近真实使用场景的条件下系统评估大语言模型在长篇内容生成与复杂写作任务中的综合能力。数据集共包含 100 条用户写作任务,每条数据由一条真实写作提示构成,并标注对应的写作场景类型。
直接使用:https://go.hyper.ai/4NQdD
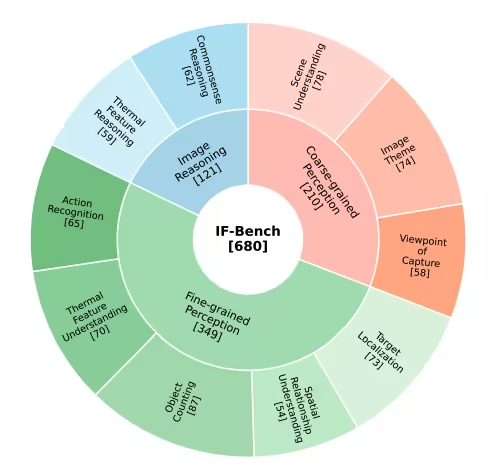
3. IF-Bench 红外图像理解基准数据集
IF-Bench 是由中国科学院自动化研究所联合中国科学院大学人工智能学院发布的一个面向红外图像多模态理解的高质量评测基准,旨在系统评估多模态大语言模型(MLLMs)对红外图像的语义理解能力。该数据集包含 499 张红外图像和 680 组视觉问答(VQA)对,图像来源于 23 个不同的红外图像数据集,整体分布保持相对均衡。
直接使用:https://go.hyper.ai/hty3u
4. CHIP 工业椅子 6D 姿态估计数据集
CHIP 是由 FBK-TeV 联合 Ikerlan 和 Andreu World 发布的一个面向真实工业场景下机器人操控的 6D 姿态估计数据集,旨在弥补现有基准主要集中于家庭物体和实验室布置而缺乏真实工业条件的数据缺口。该数据集共包含 77,811 张 RGB-D 图像,覆盖 7 种不同结构与材质的椅子模型。
直接使用:https://go.hyper.ai/AR5Xm
5. SSRB 半结构化数据自然语言查询数据集
SSRB 是由哈尔滨工业大学(深圳)联合香港理工大学、清华大学等机构发布的一个面向半结构化数据自然语言查询的大规模基准数据集,已入选 NeurIPS 2025 Datasets and Benchmarks,旨在评估和推动模型在复杂自然语言查询条件下对半结构化数据的检索能力。
直接使用:https://go.hyper.ai/szsqF
6. INFINITY-CHAT 真实开放式问答数据集
INFINITY-CHAT 由华盛顿大学联合卡内基梅隆大学、 Allen Institute for Artificial Intelligence 等发布的首个面向真实世界开放式用户提问的大规模数据集,荣获 NeurIPS 2025 Best Paper (DB track),旨在系统研究语言模型在开放式生成中的多样性、人类偏好差异以及「人工蜂群效应」等关键问题。
直接使用:https://go.hyper.ai/KmH1N
7. MUVR 多模态非裁剪视频检索基准
MUVR 是由南京航空航天大学联合南京大学、香港理工大学发布的一个面向多模态非裁剪视频检索任务的基准数据集,已入选 NeurIPS 2025 Datasets and Benchmarks,旨在推动长视频平台场景下的视频检索研究。该数据集包含来自 Bilibili 的约 53,000 条未剪辑视频、 1,050 条多模态查询以及 84,000 条查询 – 视频匹配关系,覆盖新闻、旅行、舞蹈等多种常见视频类型。
直接使用:https://go.hyper.ai/NRaSw

8. OpenGU 图遗忘综合评测数据集
OpenGU 是由北京理工大学发布的一个图遗忘(Graph Unlearning, GU)综合评测数据集,已入选 NeurIPS 2025 Datasets and Benchmarks,旨在为图神经网络中的遗忘方法提供统一的评测框架、多领域数据资源和标准化实验设置。
直接使用:https://go.hyper.ai/qqHct
9. FrontierScience 推理科研任务评测数据集
FrontierScience 是由 OpenAI 发布的一个推理 + 科研任务评测数据集,旨在系统性评估大模型在专家级科学推理与科研子任务的能力。该数据集采用了「专家原创 + 双层任务结构 + 可自动评分机制」的设计机制,划分为 Olympiad 和 Research 两个子集。
直接使用:https://go.hyper.ai/fUUzF
10. FirstAidQA 急救知识问答数据集
FirstAidQA 是由伊斯兰科技大学发布的一个面向急救与应急响应场景的领域专用问答数据集,旨在支持模型在资源受限的应急环境中的训练与应用。该数据集共包含 5,500 条高质量问答对,内容覆盖多种典型的急救与应急响应场景。
直接使用:https://go.hyper.ai/QQphC
公共教程精选
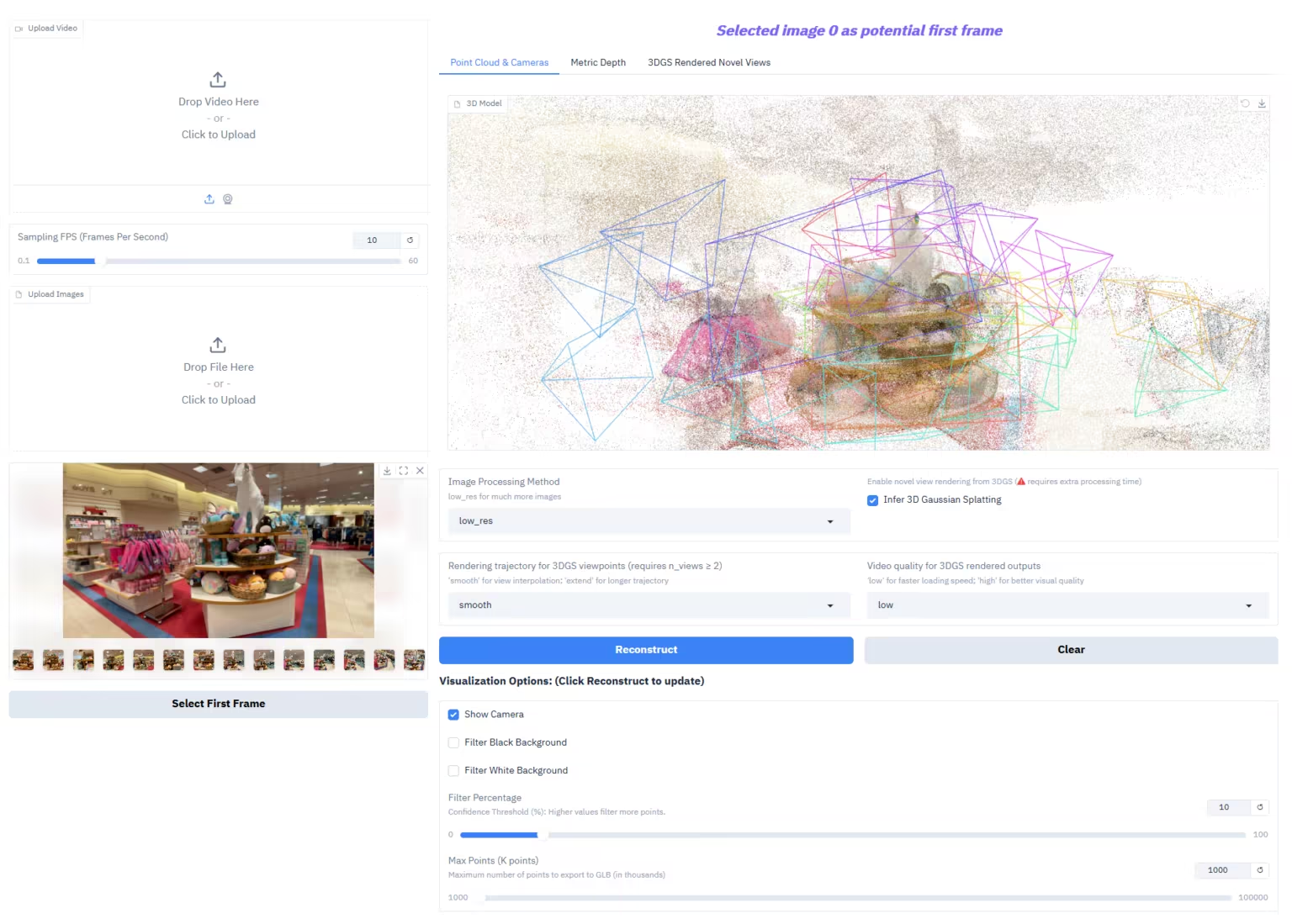
1. Depth-Anything-3:从任何视角恢复视觉空间
Depth-Anything-3(DA3)是由 ByteDance-Seed 团队发布的突破性视觉几何模型,以「极简建模」理念革新视觉几何任务:仅采用单一普通 Transformer(如 vanilla DINO 编码器)作为骨干网络,通过「深度射线表示」替代复杂多任务学习,即可从任意视觉输入(已知/未知相机姿态均可)中预测空间一致的几何结构。
在线运行:https://go.hyper.ai/MXyML
2. MarkItDown 微软开源的文档转换工具
MarkItDown 是由 Microsoft 团队推出的轻量级、即插即用式 Python 文档转换工具。它旨在将各类常见文档与富媒体格式高效、结构化地转换为 Markdown ,专门为大语言模型(LLM)的文本理解与分析流水线提供优化的输入格式。
在线运行:https://go.hyper.ai/7WIGP
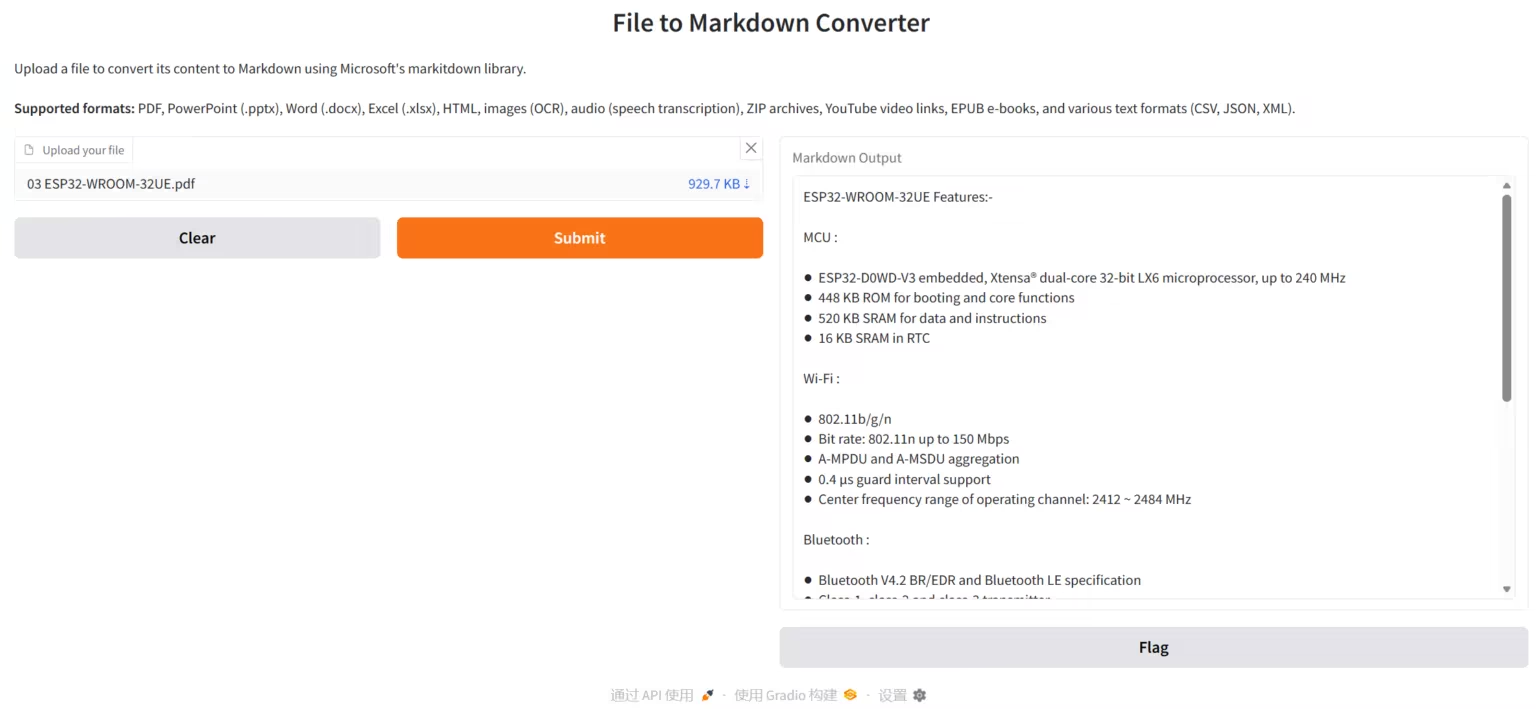
3. Chandra:高精度文档 OCR
Chandra 是由 Datalab-to 团队开发的高精度文档 OCR(Optical Character Recognition)系统,专注于文档布局感知和文本抽取。 Chandra 可直接处理 PDF 和图像文件,生成结构化文本、 Markdown 和 HTML 输出,同时提供可视化布局图,便于检查 OCR 结果。
在线运行:https://go.hyper.ai/nZhF5
💡我们还建立了 Stable Diffusion 教程交流群,欢迎小伙伴们扫码备注【SD 教程】,入群探讨各类技术问题、分享应用效果~

本周论文推荐
1. LongVie 2: Multimodal Controllable Ultra-Long Video World Model
本文提出 LongVie 2,一个端到端的自回归框架,在长程可控性、时间连贯性与视觉保真度方面均达到当前最优水平,并支持长达五分钟的连续视频生成,标志着向统一视频世界建模迈出了关键一步。
论文链接:https://go.hyper.ai/toK8K
2. MMGR: Multi-Modal Generative Reasoning
本文提出多模态生成推理评估与基准测试框架 MMGR,这是一个基于五种核心推理能力的系统性评估体系:物理推理、逻辑推理、三维空间推理、二维空间推理以及时间推理。 MMGR 在三个关键领域对生成模型的推理能力进行评估:抽象推理(ARC-AGI 、数独)、具身导航(真实世界三维导航与定位)以及物理常识理解(体育场景与复合交互行为)。
论文链接:https://go.hyper.ai/Gxwuz
3. QwenLong-L1.5: Post-Training Recipe for Long-Context Reasoning and Memory Management
本文推出了 QwenLong-L1.5,该模型通过系统性的后训练创新,实现了卓越的长上下文推理能力。基于 Qwen3-30B-A3B-Thinking 架构,QwenLong-L1.5 在长上下文推理基准测试中表现接近 GPT-5 与 Gemini-2.5-Pro 水平,相较其基线模型平均提升 9.90 分。在超长任务(100 万至 400 万 token)上,其记忆代理(memory-agent)框架相较基线代理实现 9.48 分的显著提升。
论文链接:https://go.hyper.ai/DxYGd
4. Memory in the Age of AI Agents
本文旨在系统梳理当前智能体记忆研究的最新图景。首先明确智能体记忆的界定范围,将其与相关概念——如大语言模型(LLM)记忆、检索增强生成(Retrieval-Augmented Generation, RAG)以及上下文工程(context engineering)——进行清晰区分。随后,从形式、功能与动态三个统一视角对智能体记忆展开分析。
论文链接:https://go.hyper.ai/zfHTr
5. ReFusion: A Diffusion Large Language Model with Parallel Autoregressive Decoding
本文提出 ReFusion——一种新型掩码扩散模型,通过将并行解码从词元层级提升至更高层级的「槽位」(slot)层级,实现了卓越的性能与效率。每个槽位为固定长度、连续的子序列。 ReFusion 不仅在性能上相较先前 MDMs 平均提升 34%,推理速度平均提升超过 18 倍,同时显著缩小了与强自回归模型之间的性能差距,且仍保持平均 2.33 倍的加速优势。
论文链接:https://go.hyper.ai/YosaF
更多 AI 前沿论文:https://go.hyper.ai/iSYSZ
社区文章解读
1. 以不足 10 万结构数据训练,瑞士洛桑联邦理工提出 PET-MAD,原子模拟精度媲美专业模型
瑞士洛桑联邦理工学院提出的 PET-MAD 模型,依托覆盖广泛原子多样性的数据集,在使用远少于传统规模的训练样本的情况下,仍实现了与专用模型相当的精度,为原子模拟向更高效、更普适的方向发展提供了有力示。
查看完整报道:https://go.hyper.ai/cpeR5
2. 在线教程丨微软开源 VibeVoice,可实现 90 分钟 4 角色自然对话
微软开源了 VibeVoice,旨在实现可扩展的长格式、多说话人语音合成。模型能够在 64K 上下文窗口中合成长达 90 分钟、包含最多 4 名说话人的语音,音色更为丰富、语调更趋自然,并捕捉真实对话氛围,在跨语言应用中表现出更强的迁移能力,综合表现已超越现有的开源与专有对话模型。。
查看完整报道:https://go.hyper.ai/YfDjq
3. CUDA 初始团队成员锐评 cuTile「专打」Triton,Tile 范式能否重塑 GPU 编程生态竞争格局
2025 年 12 月,在 CUDA 发布近二十年后,NVIDIA 推出新的 GPU 编程入口「cuTile」,通过 Tile-based 编程模型重构 GPU 内核,使开发者无需深入 CUDA C++ 即可高效编写 Kernel,引发社区热议。尽管仍处早期,Tile 思维的抽象优势、社区探索迁移工具及实践尝试表明,cuTile 有潜力成为 GPU 编程新范式,其未来取决于生态成熟度、迁移成本及性能表现。
查看完整报道:https://go.hyper.ai/H1b0n
4. 坚持提前监管,离开 OpenAI 后,Dario Amodei 将 AI 安全写入公司使命
在全球 AI 竞速按下「加速键」的当下,Dario Amodei 却以「提前监管」的少数派立场成为硅谷最不可忽视的力量。从推动 Constitutional AI,到影响欧美监管框架,他试图为 AI 时代奠定一套类似 TCP/IP 的「治理协议」。这不仅关乎安全,更关乎未来十年 AI 能否从技术狂飙走向稳定应用。 Amodei 的策略,正在重塑全球 AI 产业的底层逻辑。
查看完整报道:https://go.hyper.ai/SwyNW
5. 预测精度可提升 60%,清华李勇团队提出神经符号回归方法,自动推导高精度网络动力学公式
清华大学电子工程系李勇教授及团队提出了一种神经符号回归方法 ND²,通过从数据中自动推导出数学公式来刻画系统动力学。该方法将高维网络上的搜索问题等价地简化为一维系统,并利用预训练神经网络引导高精度的公式发现。
查看完整报道:https://go.hyper.ai/wVktJ
热门百科词条精选
1. 核范数 Nuclear Norm
2. 双向长短期记忆 Bi-LSTM
3. 地面真实值 Ground Truth
4. 具身导航 Embodied Navigation
5. 每秒帧数 Frames Per Second (FPS)
这里汇编了数百条 AI 相关词条,让你在这里读懂「人工智能」:
1 月截稿顶会

一站式追踪人工智能学术顶会:https://go.hyper.ai/event
以上就是本周编辑精选的全部内容,如果你有想要收录 hyper.ai 官方网站的资源,也欢迎留言或投稿告诉我们哦!
下周再见!
关于 HyperAI 超神经 (hyper.ai)
HyperAI 超神经 (hyper.ai) 是国内领先的人工智能及高性能计算社区,致力于成为国内数据科学领域的基础设施,为国内开发者提供丰富、优质的公共资源,截至目前已经:
* 为 1800+ 公开数据集提供国内加速下载节点
* 收录 600+ 经典及流行在线教程
* 解读 200+ AI4Science 论文案例
* 支持 600+ 相关词条查询
* 托管国内首个完整的 Apache TVM 中文文档
访问官网开启学习之旅:








