Command Palette
Search for a command to run...
AI 论文周报丨 OCR 前沿技术解读,DeepSeek/腾讯/百度同台竞技,从字符识别到结构化文档解析

过去几年,OCR(光学字符识别)正在从「字符识别工具」快速演进为以视觉—语言模型为核心的通用文档理解系统。在 Microsoft 、 Google 等全球性企业持续投入的同时,百度、腾讯、阿里云等中国头部厂商也在密集布局,推动市场从规则驱动的 OCR 向融合人工智能与自然语言处理的智能文档处理(IDP)快速升级,并在金融、政务、医疗等真实业务场景中不断深化应用。
伴随产业需求的持续拉动,OCR 的研究重心也发生了显著变化:模型不再只追求「识别准确率」,而是开始系统性地解决复杂版式、多模态符号、长上下文建模以及端到端语义理解等更具挑战性的问题。如何高效编码二维视觉信息、更高效解析文本信息,以及如何让模型的阅读顺序更贴近人类的认知逻辑,正成为学术界与工业界共同关注的核心议题。
正是在这种高度互动的背景下,持续追踪并梳理最新的 OCR 学术论文,对于把握技术前沿方向、理解产业真实挑战、乃至寻找下一阶段的范式突破,都显得尤为关键。
本周,我们为大家推荐的 5 篇 OCR 的热门 AI 论文,涵盖 DeepSeek 、腾讯、清华大学等团队,一起来学习吧 ⬇️
此外,为了让更多用户了解学术界在人工智能领域的最新动态,HyperAI 超神经官网(hyper.ai)现已上线「最新论文」板块,每天都会更新 AI 前沿研究论文。
最新 AI 论文:https://go.hyper.ai/hzChC
本周论文推荐
- DeepSeek-OCR 2: Visual Causal Flow
DeepSeek-AI 研究人员在 DeepSeek-OCR 的基础上进一步提出 DeepSeek-OCR 2,如果说 DeepSeek-OCR 是对通过二维光学映射压缩长上下文可行性的一项初步探索,那么 DeepSeek-OCR 2 的提出旨在探究一种新型编码器——DeepEncoderV2——在图像语义驱动下动态重排视觉标记(visual tokens)的可行性。 DeepEncoder V2 被设计为赋予编码器因果推理能力,使其能够在基于 LLM 的内容理解之前,智能地重新排列视觉标记,取代僵化的光栅扫描处理方式,从而实现更接近人类、语义连贯的图像理解,提升 OCR 与文档分析能力。
论文及详细解读:https://go.hyper.ai/ChW45
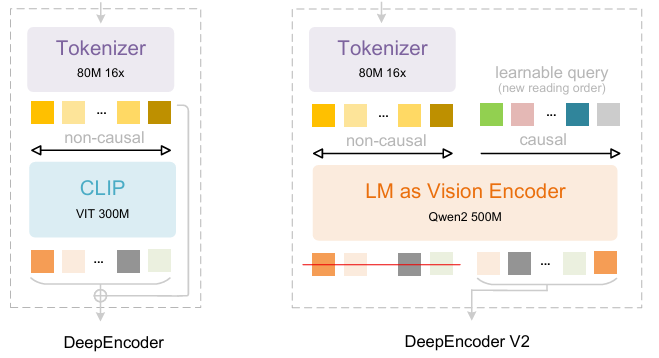
训练数据集由 OCR 1.0 、 OCR 2.0 和通用视觉数据组成,其中 OCR 数据占训练混合数据的 80% 。评估时,使用 OmniDocBench v1.5,该基准包含 1,355 页中英文文档,涵盖杂志、学术论文与研究报告,共 9 个类别。
2. LightOnOCR: A 1B End-to-End Multilingual Vision-Language Model for State-of-the-Art OCR
LightOn 研究人员推出了 LightOnOCR-2-1B,这是一款紧凑的 10 亿参数多语言视觉-语言模型,可直接从文档图像中提取干净、有序的文本,在性能上超越更大模型,同时通过 RLVR 增加图像定位能力,并通过检查点合并提升鲁棒性,模型与基准测试已开源。
论文及详细解读:https://go.hyper.ai/zXFQs
一键部署教程链接:https://go.hyper.ai/vXC4o
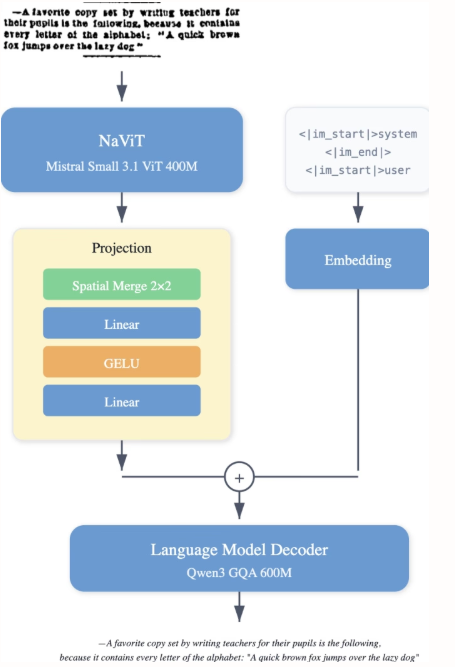
LightOnOCR-2-1B 数据集结合了来自多个来源的教师标注页面,包括扫描文档以增强鲁棒性,以及用于版式多样性的辅助数据。包含由 GPT-4o 标注的裁剪区域(段落、标题、摘要)、空白页样例以抑制幻觉,以及通过 nvpdftex 流程从 arXiv 获取的 TeX 衍生监督。添加公开 OCR 数据集以增加多样性。
3. HunyuanOCR Technical Report
本文提出 HunyuanOCR,这是一个由腾讯及合作者开发的 10 亿参数开源视觉-语言模型,通过数据驱动训练和新颖的强化学习策略,采用轻量级架构(ViT-LLM MLP 适配器)统一了端到端的 OCR 能力——包括文本定位、文档解析、信息抽取和翻译,性能超越更大模型和商业 API,实现了工业与科研应用中的高效部署。
论文及详细解读:https://go.hyper.ai/F9fni
一键部署教程链接:https://go.hyper.ai/C4srs

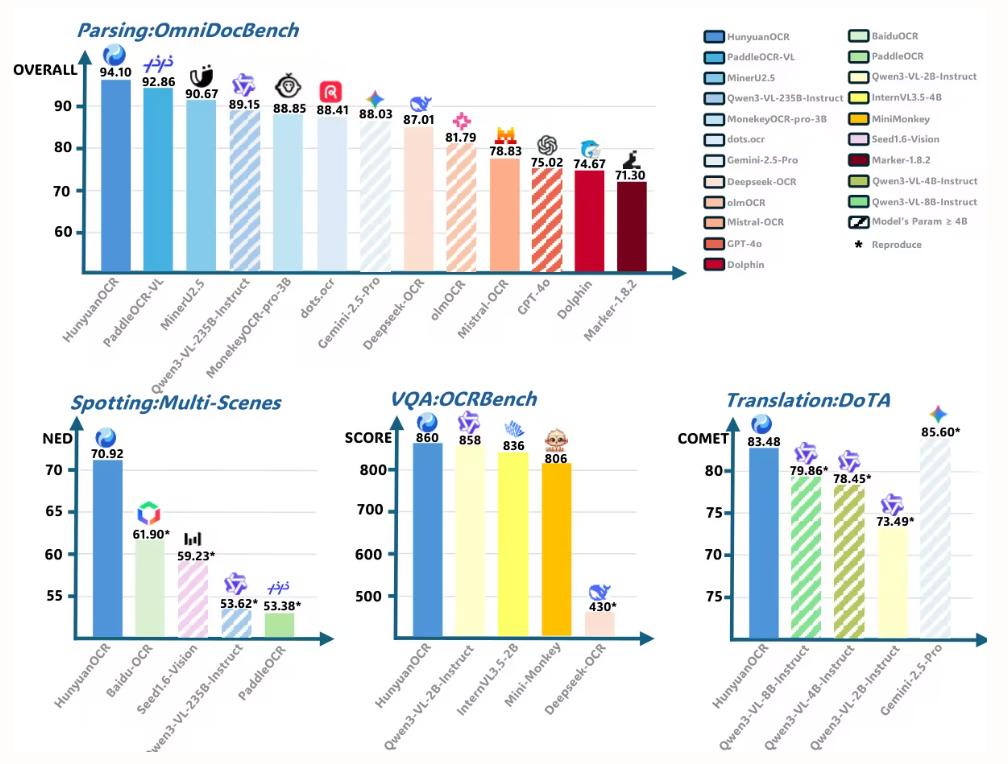
本文实验使用 HunyuanOCR 在 OmniDocBench 上评估文档解析性能。取得 94.10 的最高总分,超越所有其他模型(包括更大模型)。
4 .PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
百度团队提出 PaddleOCR-VL,一种资源高效的视觉-语言模型,融合了 NaViT 风格的动态分辨率编码器与 ERNIE-4.5-0.3B 模型,实现了多语言文档解析的最先进性能,能够准确识别表格、公式等复杂元素,在保持快速推理能力的同时,优于现有方案,适用于真实场景的部署。
论文及详细解读:https://go.hyper.ai/Rw3ur
一键部署教程链接:https://go.hyper.ai/5D8oo
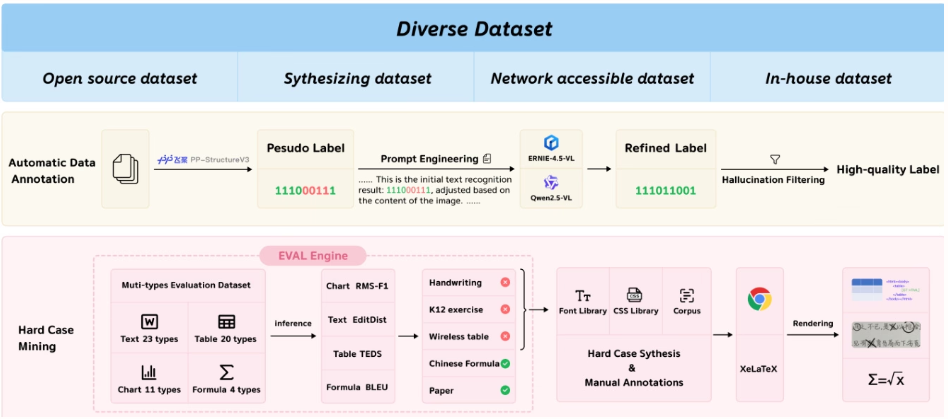
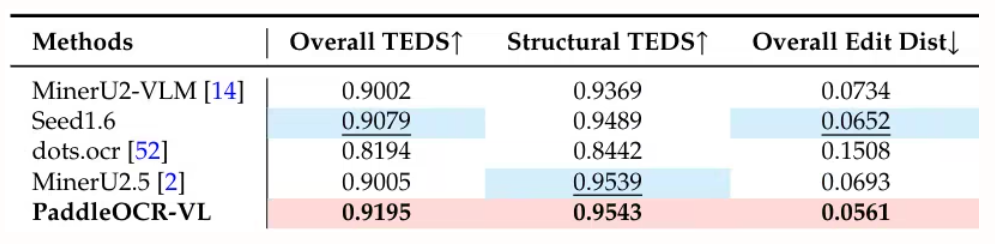
本文实验在 OmniDocBench v1.5 、 olmOCR-Bench 和 OmniDocBench v1.0 上评估页面级文档解析,于 OmniDocBench v1.5 上取得 92.86 的最先进总体得分,优于 MinerU2.5-1.2B(90.67),在文本(编辑距离 0.035)、公式(CDM 91.22)、表格(TEDS 90.89 与 TEDS-S 94.76)和阅读顺序(0.043)方面均领先。
5. General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
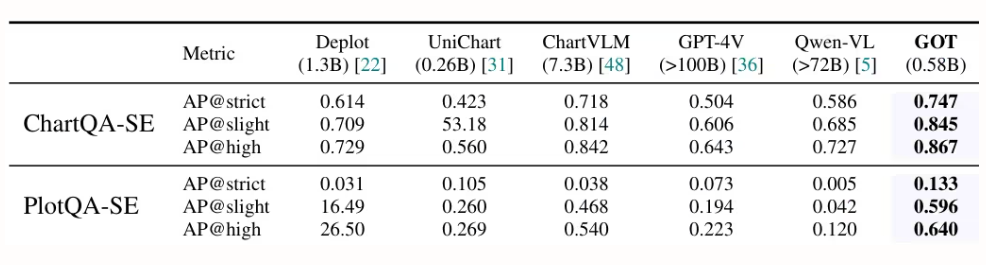
StepFun 、旷视科技、中国科学院大学和清华大学的研究人员提出 GOT,一个 5.8 亿参数的统一端到端 OCR-2.0 模型,通过高压缩编码器和长上下文解码器,将识别能力从文本扩展到多种人工光学信号——如数学公式、表格、图表和几何图形,支持切片/整页输入、格式化输出(Markdown/TikZ/SMILES)、交互式区域级识别、动态分辨率和多页处理,显著推动了智能文档理解的发展。
论文及详细解读:https://go.hyper.ai/9E6Ra
一键部署教程链接:https://go.hyper.ai/HInRr
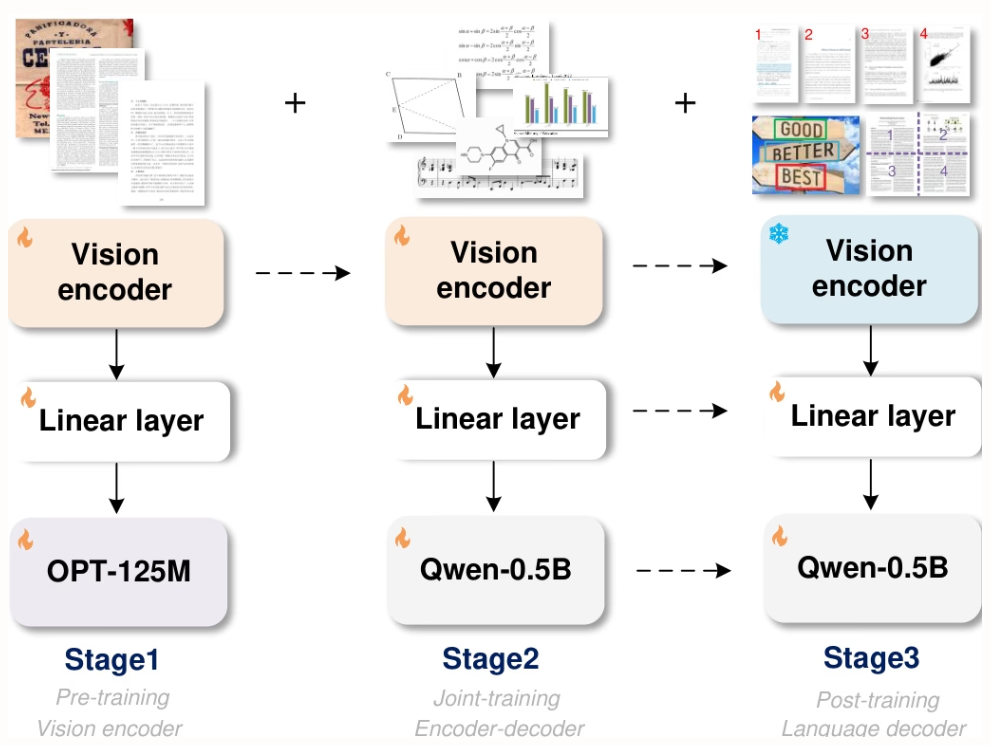
本文实验在 8×8 L40s GPU 上 完成三阶段训练:预训练(3 轮,批量大小 128,学习率 1e-4)、联合训练(1 轮,最大 token 长度 6000)、后训练(1 轮,最大 token 长度 8192,学习率 2e-5),前一阶段保留 80% 数据以维持性能。
以上就是本周论文推荐的全部内容,更多 AI 前沿研究论文,详见 hyper.ai 官网「最新论文」板块。
同时也欢迎研究团队向我们投稿高质量成果及论文,有意向者可添加神经星星微信(微信号:Hyperai01)。
下周再见!








