Command Palette
Search for a command to run...
在线教程丨 Deepseek-OCR 以极少视觉 Token 数在端到端模型中实现 SOTA

众所周知,大语言模型在处理千字、万字或是更长文本时,计算量往往急剧增加,甚至直接导致算力的「烧钱」游戏,也因此制约了 LLM 在处理高密度文本信息场景中的效率边界。
当业界不断探索如何优化计算效率时,Deepseek-OCR 提出了一个全新的视角:能不能用「看」的方式来高效地「读」文本?基于这个大胆的设想,研究人员发现包含文档文本的单张图像,可以用远少于等价数字文本的符号来表示丰富的信息。这意味着,当我们选择将文本信息以一张张图像的形式交给大模型进行理解和记忆时,整体的效率可以得到有效提升。这不再是简单的图像处理,而是一种巧妙的「光学压缩」——利用视觉模态作为文本信息的有效压缩媒介,从而实现了远高于传统文本表示的压缩比。
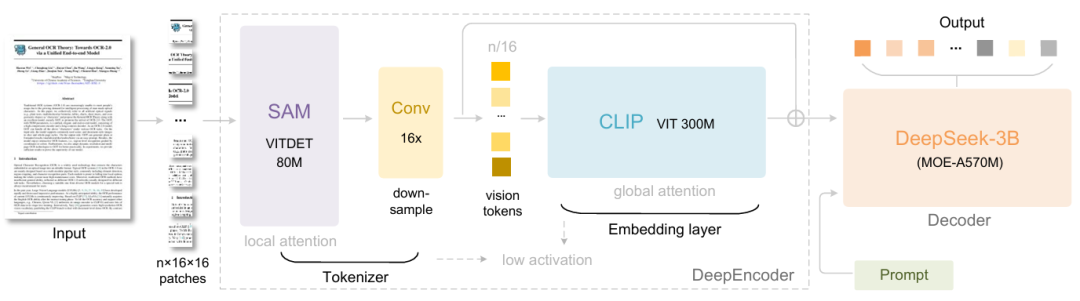
具体而言,DeepSeek-OCR 包含两个组件:DeepEncoder 和 DeepSeek3B-MoE-A570M 。编码器(即 DeepEncoder)负责提取图像特征、分词以及压缩视觉表示,解码器(即 DeepSeek3B-MoE-A570M)用则于根据图像标记和提示生成所需结果。其中 DeepEncoder 作为核心引擎,设计用于在高清输入下保持低激活状态,同时实现高压缩率,以确保视觉 token 的数量既优化又易于管理。实验表明,当文本 token 数量是视觉 token 数量的 10 倍以内(即压缩率 < 10×)时,模型可以实现 97% 的解码(OCR)精度。即使在压缩率为 20× 的情况下,OCR 准确率仍保持在约 60% 。
DeepSeek-OCR 的发布,不仅仅是 OCR 任务的进步,更在长上下文压缩和探索 LLMs 中的记忆遗忘机制等前沿研究领域展示了巨大的潜力。
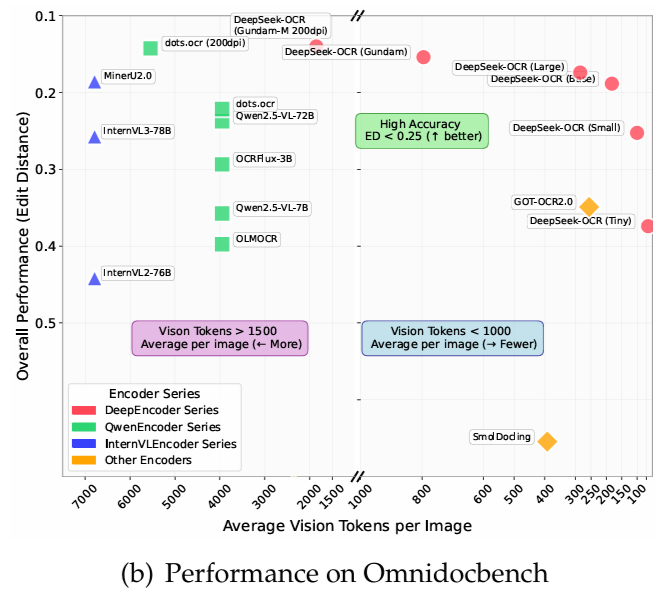
在 OmniDocBench 上,它使用仅 100 个视觉 token 就超越了 GOT-OCR2.0(每页 256 个 token),并且在使用少于 800 个视觉 token 的情况下,表现优于 MinerU2.0(平均每页 6000+ 个 token)。在生产环境中,DeepSeek-OCR 每天可以为 LLMs/VLMs 生成 20 万页以上的训练数据(使用单个 A100-40G)。
「DeepSeek-OCR:「视觉压缩」替代传统字符识别」现已上线 HyperAI 超神经官网(hyper.ai)的「教程」板块,快来一键部署体验!
* 教程链接:
* 查看相关论文:
https://hyper.ai/papers/DeepSeek_OCR
Demo 运行
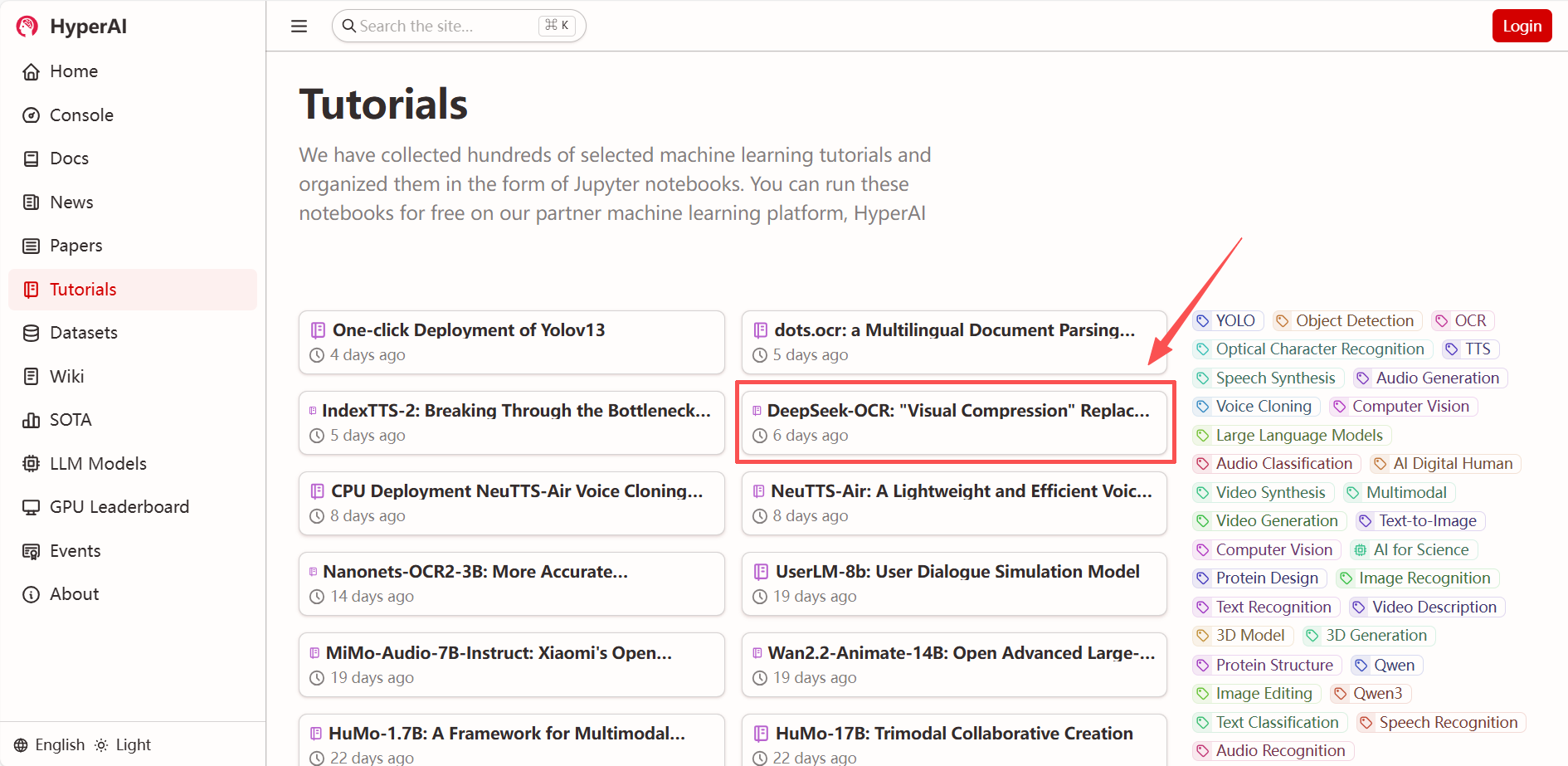
1. 进入 hyper.ai 首页后,选择「DeepSeek-OCR:「视觉压缩」替代传统字符识别」,或进入「教程」页面选择,进入点击「在线运行此教程」。
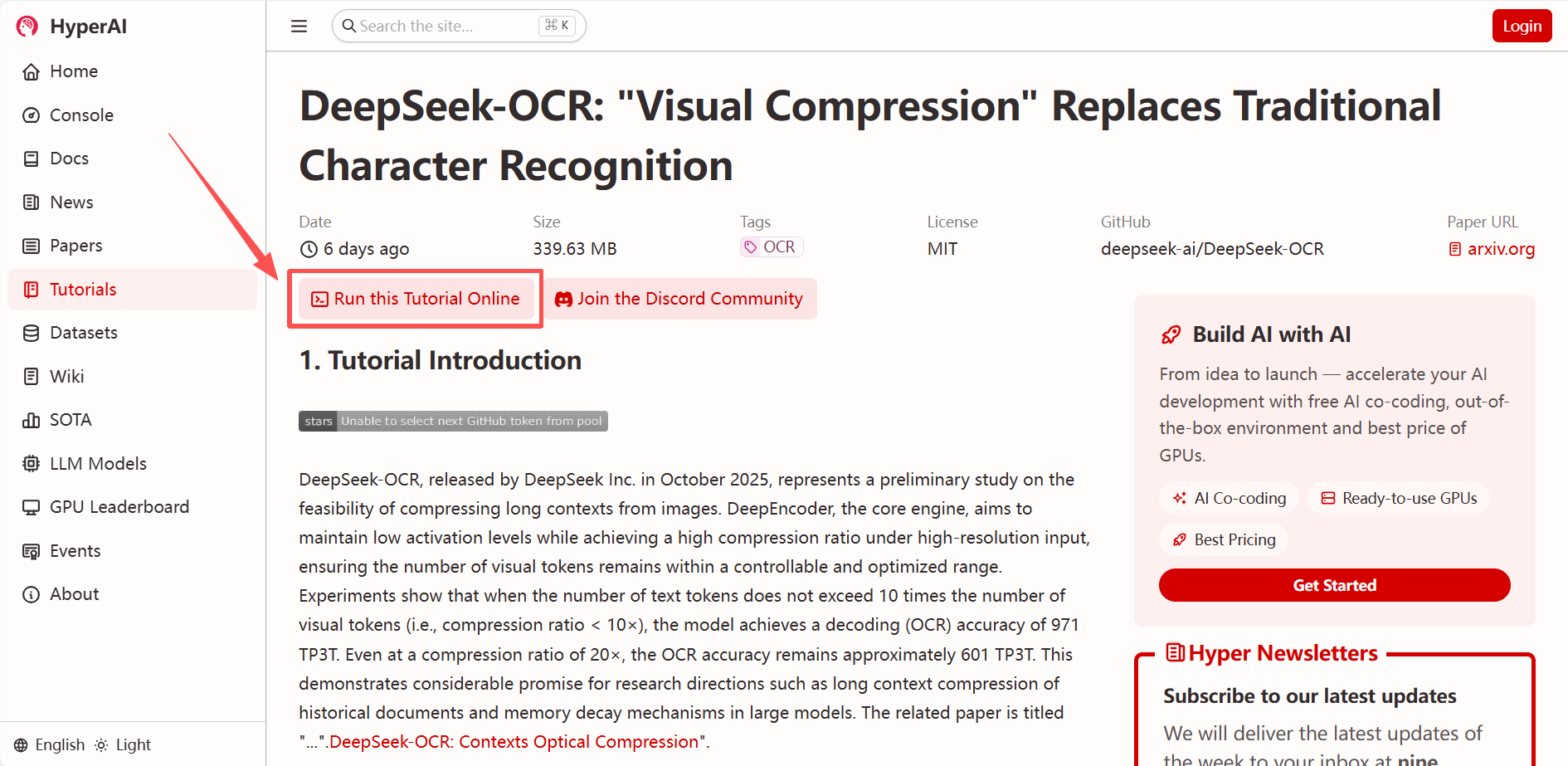
2. 页面跳转后,点击右上角「Clone」,将该教程克隆至自己的容器中。
注:页面右上角支持切换语言,目前提供中文及英文两种语言,本教程文章以英文为例进行步骤展示。
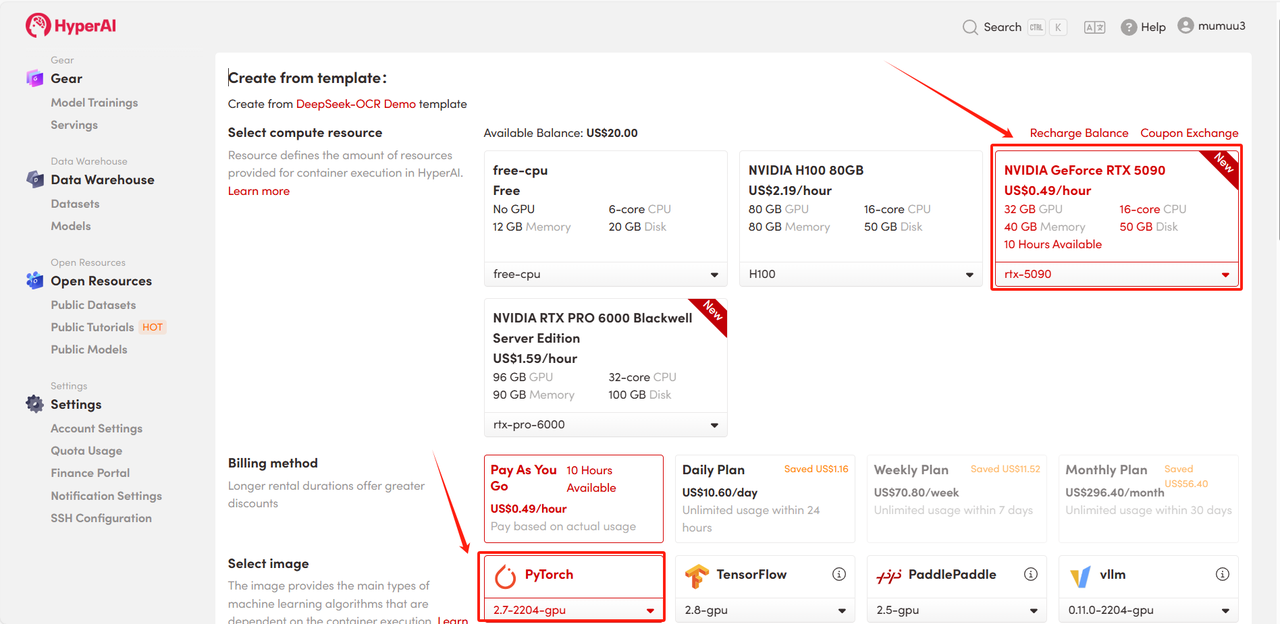
3. 选择「NVIDIA GeForce RTX 5090」以及「PyTorch」镜像,按照需求选择「Pay As You Go(按量付费)」或「Daily Plan/Weekly Plan/Monthly Plan(包日/周/月」,点击「Continue job execution(继续执行)」。
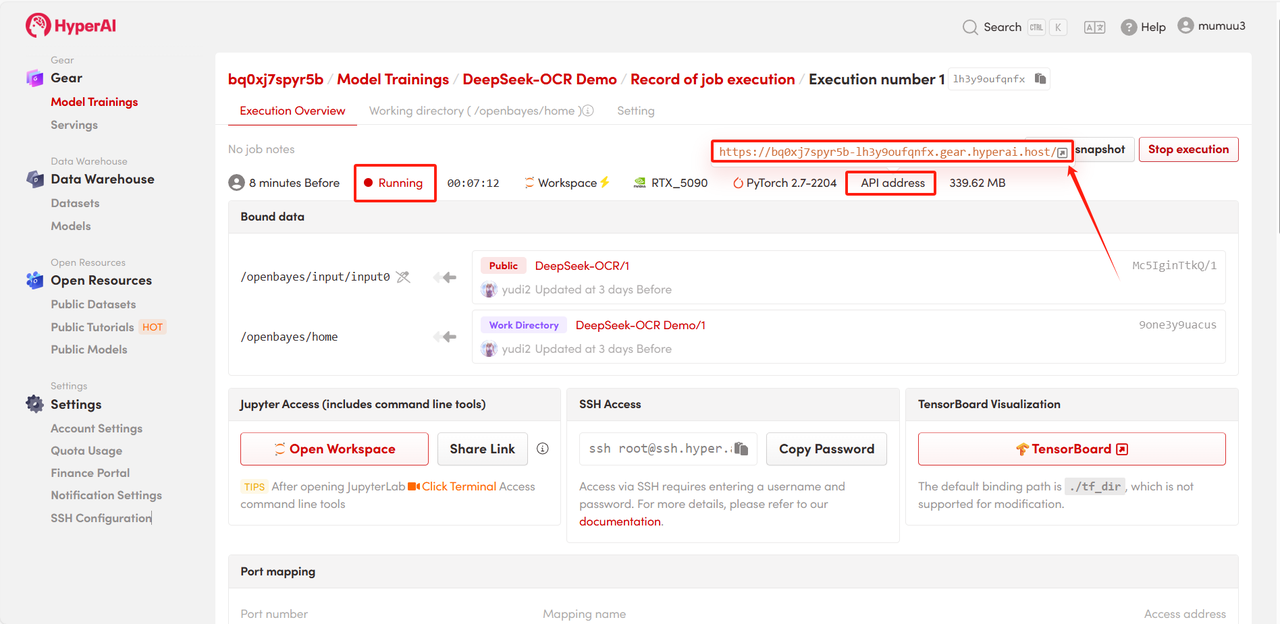
4. 等待分配资源,首次克隆需等待 3 分钟左右的时间。当状态变为「运行中」后,点击「API 地址」旁边的跳转箭头,即可跳转至 Demo 页面。
效果演示
进入 Demo 运行页面后,上传需解析的文档图像,点击「Extract Text」即可开始解析。
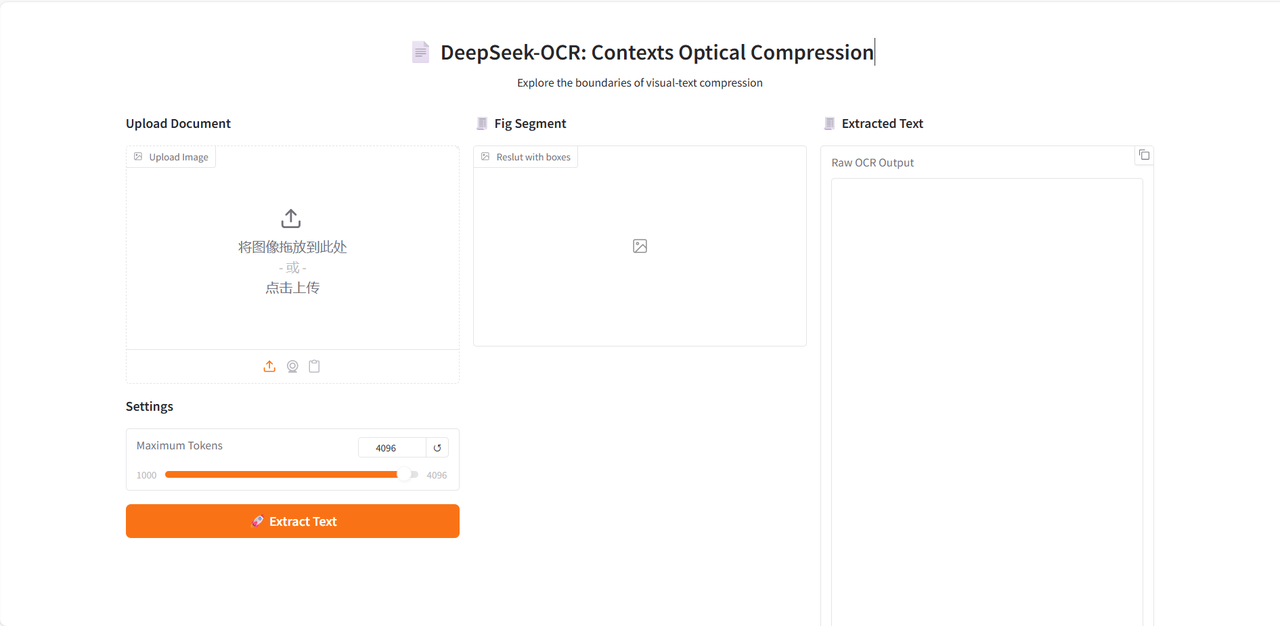
模型会首先对图像中的文本或图表模块进行划分,再输出 Markdown 格式文本。

以上就是 HyperAI 超神经本期推荐的教程,欢迎大家前来体验!
* 教程链接:








