Command Palette
Search for a command to run...
مع وصول دقة تقدير العمق إلى 0.9، اقترحت Meta نموذج VLM³، مما يدل على أن النماذج المرئية قادرة بطبيعتها على تعلم الأبعاد الثلاثية، وتحقيق نمذجة موحدة لمهام متعددة بناءً على Qwen3-VL-4B.

يُعدّ الإدراك المكاني ثلاثي الأبعاد قدرةً أساسيةً في مجالاتٍ مثل القيادة الذاتية، والروبوتات، وإعادة البناء ثلاثي الأبعاد. ويهدف إلى استعادة البنية المكانية، ومعلومات المقياس، والعلاقات الهندسية للعالم الحقيقي من الصور ثنائية الأبعاد. بالمقارنة مع مهام الرؤية ثنائية الأبعاد مثل تصنيف الصور واكتشاف الأجسام،لا يتطلب الإدراك ثلاثي الأبعاد قدرات الفهم الدلالي فحسب، بل يتطلب أيضًا التفكير المكاني الدقيق والنمذجة الهندسية.لذلك، فقد اعتُبر منذ فترة طويلة أحد أكثر اتجاهات البحث تحديًا في مجال رؤية الحاسوب.
في السنوات الأخيرة، حققت نماذج اللغة المرئية (VLMs) تقدماً ملحوظاً في مهام ثنائية الأبعاد مثل التصنيف والكشف والتجزئة، وذلك بفضل بنيتها الموحدة وتدريبها المسبق واسع النطاق. مع ذلك، في المهام الدقيقة التي تتطلب استدلالاً مكانياً دقيقاً، مثل تقدير العمق ومطابقة البكسلات وتحديد وضعية الكاميرا، لا يزال أداء نماذج اللغة المرئية القياسية متأخراً عن أداء النماذج ثلاثية الأبعاد المتخصصة. حالياً،لم يطور مجال الرؤية ثلاثية الأبعاد بعد نموذجاً أساسياً شاملاً مماثلاً لنموذج الرؤية ثنائية الأبعاد. ولا تزال الأساليب السائدة تعتمد على نماذج متخصصة مصممة لمهام محددة.يشمل ذلك هياكل الشبكات المتخصصة، ووظائف الخسارة، واستراتيجيات التدريب.
أظهرت الأبحاث الحديثة أن نموذج اللغة المرئية القياسي (VLM) - دون تعديلات ثلاثية الأبعاد محددة - يتمتع بقدرة معينة على إدراك العمق على مستوى البكسل. تشير هذه الظاهرة إلى أن نماذج اللغة المرئية العامة قد تمتلك قدرات تمثيل ثلاثي الأبعاد أقوى مما هو متوقع، كما أنها تطرح سؤالاً جديراً بالبحث: هل يستطيع نموذج اللغة المرئية القياسي التعامل مع نطاق أوسع من مهام الإدراك ثلاثي الأبعاد الدقيقة دون الحاجة إلى إضافة مشفرات أو إشارات مرئية أو وحدات نمطية خاصة بكل مهمة؟
ولمعالجة هذه المشكلة،اقترحت شركة ميتا، بالتعاون مع جامعة برينستون، إطار عمل VLM³ (VLM المكعب).استنادًا إلى نموذج اللغة المرئية القياسي، تُحقق هذه الدراسة نمذجة موحدة لأربعة أنواع من المهام - فهم ثلاثي الأبعاد على مستوى الكائن، وتقدير العمق المتري، ومطابقة البكسل، وحل وضعية الكاميرا - من خلال طريقة موحدة لتنظيم البيانات ونموذج تدريب موحد. كما تُقيّم بشكل منهجي حدود قدرة نموذج اللغة المرئية القياسي في الإدراك ثلاثي الأبعاد الدقيق.
تم نشر نتائج البحث ذات الصلة، بعنوان "VLM3: نماذج لغة الرؤية هي متعلمون أصليون ثلاثي الأبعاد"، على منصة ما قبل الطباعة arXiv.
أبرز الأبحاث:
* في معيار SpatialRGPT، يتفوق VLM³-4B على SpatialRGPT-8B الأكبر حجمًا ببنية أكثر تبسيطًا، ولا يتطلب مشفرًا إضافيًا.
* بالمقارنة مع أفضل نموذج لغة مرئية سابق، DepthLM-7B، فإن VLM³-4B يحسن متوسط الدقة δ₁ من 0.84 إلى 0.90، محققًا أداءً على قدم المساواة مع نموذج تقدير العمق الاحترافي UnidepthV2.
* يقلل VLM³ من خطأ نقطة النهاية (EPE) لنماذج اللغة المرئية الأساسية بمقدار عشرة أضعاف، متفوقًا على نماذج الخبراء الكلاسيكية مثل DKM و RoMa.
* يعمل VLM³ بشكل كبير على تحسين مقياس AUC₃₀° من مستوى شبه عشوائي يبلغ 5% إلى 94%، متجاوزًا VGGT ويصل إلى مستوى مماثل لـ DA3-Giant.
عرض الورقة:
https://hyper.ai/papers/2605.30561
مجموعات بيانات هجينة للإدراك ثلاثي الأبعاد متعدد المهام
تتضمن مهام الإدراك ثلاثي الأبعاد عوامل مختلفة مثل حجم المشهد، وتغييرات زاوية الرؤية، ومعايير الكاميرا، والعلاقات الهندسية، مما يفرض متطلبات عالية على جودة بيانات التدريب وتغطيتها. لدعم تعلم قدرات التمثيل ثلاثي الأبعاد الموحدة،تقوم هذه الدراسة بإنشاء نظام بيانات هجين يغطي المشاهد أحادية الرؤية ومتعددة الرؤية، ويشمل ثلاثة أنواع من المهام: تقدير العمق المتري، والفهم ثلاثي الأبعاد على مستوى الكائن، ومطابقة البكسل وتقدير وضع الكاميرا.
في مهمة تقدير العمق المترياستخدم الباحثون مجموعة بيانات هجينة واسعة النطاق ومتعددة المشاهد. وتستند البيانات الأساسية إلى بيانات DepthLM، وتشمل بيانات مشاهد ثلاثية الأبعاد شائعة الاستخدام مثل Argoverse2 وWaymo وNuScenes وScanNet++ وTaskonomy وHM3D وMatterport3D. بالإضافة إلى ذلك، أُضيفت 10 ملايين صورة لمشاهد شوارع خارجية تم إنشاؤها ذاتيًا، مما رفع حجم التدريب من 16 مليونًا إلى 26 مليون صورة.استخدم التدريب النهائي للنموذج ما يقرب من 32 مليون صورة و 320 مليون تعليق توضيحي للعمق.يغطي هذا البرنامج مجموعة متنوعة من السيناريوهات، بما في ذلك المشاهد الداخلية والخارجية ومشاهد الشوارع والبيئات المفتوحة المعقدة.
على عكس الدراسات السابقة، لا تعتمد VLM³ استراتيجية أخذ عينات موحدة. بل تصمم أوزان تدريب متباينة بناءً على حجم مجموعة البيانات، وصعوبة التعلم، وقيمة التعميم. تُظهر التجارب أن مجموعات البيانات الصغيرة أكثر عرضةً للتجاوز أثناء التدريب المختلط، وأن زيادة عدد مصادر البيانات لا تؤدي بالضرورة إلى تحسين الأداء. لذلك، قام فريق البحث بتقليل أوزان التدريب لبعض مجموعات البيانات الصغيرة لتحسين قدرة التعميم الإجمالية.
تستخدم مهمة فهم الكائنات ثلاثية الأبعاد نفس مجموعة البيانات القياسية المستخدمة في SpatialRGPT.تتضمن هذه المجموعة ما يقارب مليون صورة تدريبية، بالإضافة إلى عينات نوعية وكمية للإجابة على الأسئلة. وقد أصبحت هذه المجموعة معيارًا هامًا لمهام فهم الأبعاد الثلاثية على مستوى الكائنات. يفتقر عدد كبير من الصور إلى المعلومات الذاتية للكاميرا، مما يجعلها أقرب إلى سيناريوهات التطبيقات الواقعية، وبالتالي تعكس بشكل أكثر دقة قدرات النموذج على الاستدلال المكاني.
بالنسبة لمهام مطابقة البكسل وتقدير وضعية الكاميرا، قام فريق البحث بإنشاء مجموعة بيانات تدريب موحدة متعددة المشاهد.تتضمن هذه المجموعة من البيانات 14 مصدرًا رئيسيًا للبيانات، بما في ذلك BlendedMVS وDynamicReplica وSailVOS3D وScanNet++، وتحتوي على ما يقارب 9.9 مليون زوج من الصور. ولضمان جودة التدريب، احتفظ الباحثون فقط بالعينات التي تتجاوز فيها نسبة التداخل البصري 251 نقطة TP3T بين الصور، وخصصوا 30 مشهدًا مستقلًا من ScanNet++ كمجموعة اختبار مستقلة، مما يمنع تسرب البيانات بين مجموعتي التدريب والاختبار. وقد تم ضبط أوزان مجموعة البيانات بناءً على العدد الأصلي لأزواج الصور من كل مصدر بيانات، مما يعزز استقرار عملية التدريب وقابليتها للتكيف.
نموذج VLM³: التعلم ثلاثي الأبعاد الموحد وفقًا لمبدأ التعديل الأدنى
لا يهدف تصميم VLM³ إلى بناء بنية رؤية ثلاثية الأبعاد جديدة، بل إلى تقييم إمكانياتها الكامنة في مهام ثلاثية الأبعاد دقيقة مع الحفاظ على البنية الأصلية لنماذج اللغة البصرية القياسية. ولذلك، يتبع الإطار بأكمله "مبدأ الحد الأدنى من التعديل"، دون إضافة مشفرات إضافية، أو دوال خسارة خاصة، أو وحدات مخصصة للمهام.بدلاً من ذلك، ينصب التركيز على تحسين ثلاثة جوانب: تمثيل المدخلات، وأساليب تحديد المواقع المكانية، واستراتيجيات تنظيم البيانات.
تستخدم هذه الدراسة نموذج Qwen3-VL-4B كنموذج أساسي، وتوظف نموذج الضبط الدقيق الخاضع للإشراف (SFT) القياسي طوال عملية التدريب، مما يحافظ على التناسق مع سير عمل التدريب المسبق والضبط الدقيق لنماذج اللغة المرئية الحالية. يضمن هذا التصميم توافق الإطار مباشرةً مع أنظمة نماذج اللغة المرئية الشائعة دون الحاجة إلى إنشاء مسار تدريب إضافي مخصص.
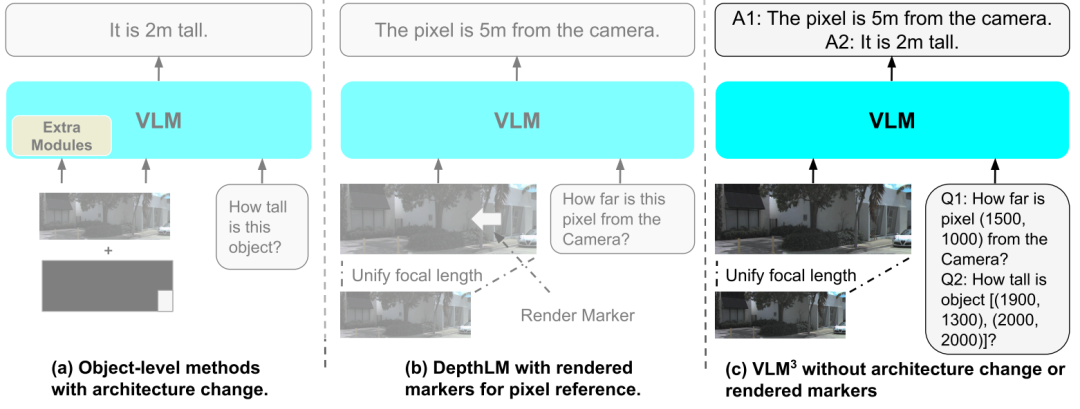
أولاً، فيما يتعلق بمسألة عدم اتساق معايير الكاميرا بين مصادر البيانات المختلفة،يقترح VLM³ استراتيجية موحدة لتوحيد معايير الصور.أظهرت الأبحاث وجود اختلافات كبيرة في المعايير الداخلية للكاميرا بين مجموعات البيانات ثلاثية الأبعاد متعددة المصادر، حتى أن بعض صور الشبكة تفتقر إلى معلومات معايير الكاميرا. يؤثر هذا بشكل مباشر على قدرة النموذج على تعلم العلاقات الهندسية المكانية. لذلك،يقوم الإطار برسم جميع الصور المدخلة إلى مساحة طول بؤري قياسية ويقدر المعلمات الجوهرية المفقودة باستخدام نماذج معايرة الصور الفردية الموجودة.هذا يقلل من تحول التوزيع الناتج عن الاختلافات في ظروف التصوير.
ثانيًا،يتبنى VLM³ نموذجًا موحدًا لتحديد المواقع المكانية النصية.تعتمد نماذج الرؤية ثلاثية الأبعاد التقليدية عادةً على إشارات بصرية إضافية، أو علامات مُجسّمة، أو وحدات ترميز موضعي مصممة خصيصًا لتحقيق تحديد الموقع على مستوى البكسل. أما VLM³، فيُوحّد إحداثيات الصورة في فضاء إحداثيات موحد، ويعبّر عن العلاقات الموضعية في شكل نصي. وبهذه الطريقة، يستطيع النموذج الاستفادة من إمكانيات نمذجة اللغة الأصلية لإجراء تحديد الموقع على مستوى البكسل، وتحديد موقع المنطقة، وتعلم التطابق بين المشاهد دون الحاجة إلى وحدات بصرية إضافية. في الوقت نفسه، يمكن أن تحتوي صورة واحدة على عينات متعددة للإجابة على أسئلة تحديد الموقع، مما يُحسّن كفاءة التدريب بشكل ملحوظ. في مهام تقدير العمق،إن كمية الإشارة الإشرافية التي يمكن أن توفرها عينة واحدة أعلى بحوالي 10 مرات من تلك التي توفرها المخططات التقليدية، في حين أن التكلفة الحسابية تظل دون تغيير تقريبًا.
أما التصميم الأساسي الثالث فهو عبارة عن استراتيجية متطورة لخلط البيانات.على عكس العديد من الطرق التي تعتمد على هياكل شبكية معقدة لتحسين الأداء، يركز نموذج VLM³ جهوده في التحسين على مستوى تنظيم البيانات. من خلال تجارب مكثفة، اكتشف فريق البحث أن زيادة حجم البيانات بشكل عشوائي أو استخدام التدريب المختلط ذي الأوزان المتساوية غالبًا ما يؤدي إلى تشبع الأداء أو حتى تدهوره. في المقابل، يمكن لتصميم استراتيجيات أخذ عينات متباينة بناءً على حجم البيانات وخصائص المهمة أن يحسن بشكل أكثر فعالية قدرات النموذج على تمثيل البيانات ثلاثية الأبعاد. لذلك، يُعتبر تخصيص البيانات عنصرًا أساسيًا في الإطار بأكمله، وليس مجرد عامل مساعد في عملية التدريب.
بناءً على التصميم أعلاهيُمكّن VLM³ كذلك من النمذجة الموحدة لأربعة أنواع من المهام ثلاثية الأبعاد.تعتمد عملية تقدير العمق على إنشاء عينات مُشرفة من خلال تحديد مواقع البكسلات النصية؛ ويستخدم فهم الأبعاد الثلاثية على مستوى الكائن مربعات إحداثيات نصية بدلاً من مُشفِّرات القناع المُخصصة؛ ويُحوِّل مُطابقة البكسلات التطابقات بين المشاهد إلى مسائل تنبؤ بالإحداثيات؛ ويُحلِّل تقدير وضعية الكاميرا المعلمات الهندسية المُعقدة إلى تنسيقات أسئلة وأجوبة نصية مثل مسافة الإزاحة واتجاهها وزاوية الدوران. وتُوحَّد المهام التي كانت تعتمد في الأصل على نماذج مُختلفة للمعالجة في النهاية ضمن الإطار التوليدي التراجعي لنموذج التعلم المرئي القياسي.
لأول مرة، حقق نموذج اللغة المرئية القياسي فهمًا ثلاثي الأبعاد عالي الدقة في مهام ثلاثية الأبعاد متعددة ودقيقة.
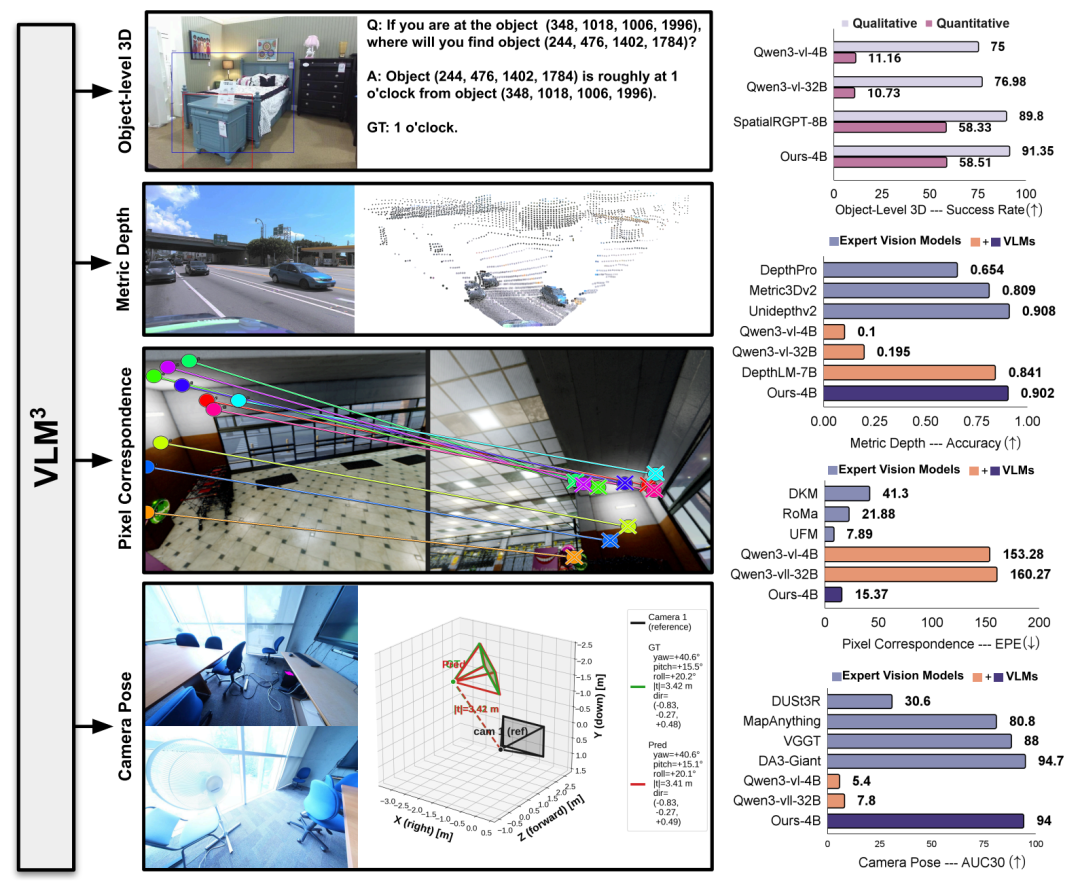
من أجل التقييم المنهجي لفعالية VLM³،أجرى فريق البحث تجارب على أربعة أنواع من المهام: تقدير العمق المتري، وفهم ثلاثي الأبعاد على مستوى الكائن، ومطابقة البكسل، وتقدير وضع الكاميرا.تتم مقارنتها بنماذج اللغة البصرية العامة ونماذج الخبراء السائدة الحالية.
في مهمة تقدير العمق المتريتختار الدراسة تسع مجموعات بيانات عامة للمقارنة مع نموذج التعلم الافتراضي العام وتقارنه بنموذج الخبراء الحالي على خمسة معايير تمثيلية.باستخدام δ₁ كمقياس التقييم الأساسي، تظهر النتائج في الجدول أدناه. يتفوق VLM³-4B بشكل شامل على الطريقة السابقة الممثلة، DepthLM-7B.وقد تحسن متوسط الدقة من 0.84 إلى 0.90، مسجلاً رقماً قياسياً جديداً على مجموعات بيانات متعددة.وفي الوقت نفسه، وصل أداؤها العام إلى مستوى نماذج تقدير العمق الاحترافية مثل UnidepthV2 و MoGe-2.
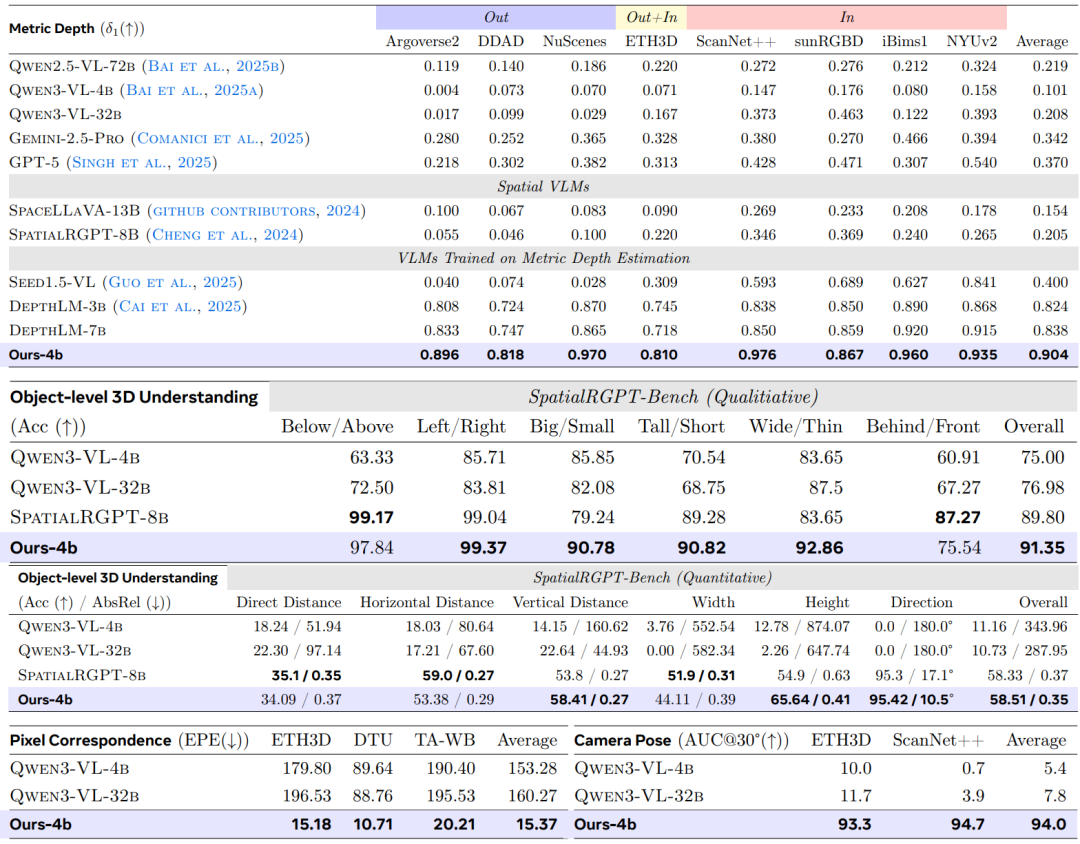
في مهمة فهم الأبعاد الثلاثية على مستوى الكائن، أعادت الدراسة استخدام إطار التقييم الخاص بـ SpatialRGPT بشكل كامل. وتُظهر النتائج أن...يتفوق نموذج VLM³، الذي يبلغ حجم معلماته 4 بايت فقط، على نموذج SpatialRGPT، الذي يبلغ حجمه 8 بايت، في كل من التقييمات النوعية والكمية.يعتمد الأخير على مشفر قناع إضافي لإكمال التحديد المكاني، بينما يمكن لـ VLM³ الحصول على نتائج أفضل بالاعتماد فقط على آلية تحديد موقع النص الموحدة، مما يشير إلى أن نمذجة النصوص الموحدة لها فعالية قوية في مهام الاستدلال المكاني.
تستخدم مهمة مطابقة البكسلات نظام تقييم UFM، مع اعتبار خطأ نقطة النهاية (EPE) المقياس الأساسي. تُظهر النتائج التجريبية أن VLM³ يُقلل الخطأ بمقدار عشرة أضعاف مقارنةً بـ VLM الأساسي، ويتفوق على نماذج الخبراء التقليدية مثل DKM وRoMa، ويقترب قليلاً فقط من أحدث الطرق المتاحة، UFM. وهذا يُشير إلى أن...إن نهج النمذجة الموحد القائم على النصوص لا ينطبق فقط على المشاهد ذات الرؤية الواحدة، بل يمكنه أيضًا تعلم التوافقات الهندسية بين المشاهد بشكل فعال.
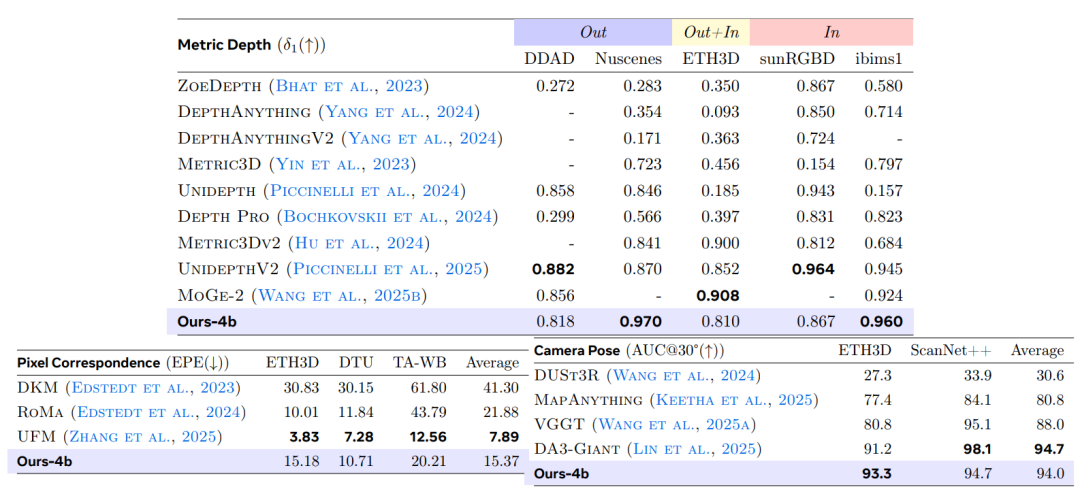
في مهمة تقدير وضعية الكاميرا، تستخدم الدراسة مقياس AUC₃₀° للتقييم على مجموعتي بيانات ETH3D و ScanNet++، على التوالي. وتُظهر النتائج أن...يعمل VLM³ على تحسين أداء VLM الأساسي من مستويات التنبؤ شبه العشوائية إلى AUC₃₀° بقيمة 94%.إنها تتجاوز الأساليب السائدة مثل VGGT و MapAnything، وتقترب من مستوى أداء أفضل نموذج حالي، وهو DA3-Giant.
الكلمات الأخيرة
لطالما اتبعت أبحاث الرؤية ثلاثية الأبعاد نهجًا قائمًا على المهام، حيث صُممت نماذج مخصصة لمهام مختلفة مثل تقدير العمق، ومطابقة البكسلات، وحل مشكلة الوضعية. إلا أن نموذج VLM³ يُظهر إمكانية مختلفة، إذ يُمكن لنموذج لغة بصرية قياسي، دون الحاجة إلى مُشفِّرات إضافية، أو دوال خسارة خاصة، أو آليات توجيه بصري معقدة، أن يحقق أداءً يُضاهي أو حتى يتفوق على بعض النماذج المتخصصة في مهام ثلاثية الأبعاد دقيقة متعددة، وذلك ببساطة من خلال معالجة صور موحدة، ونمذجة مكانية نصية، واستراتيجيات بيانات مُحسَّنة. تشير نتائج هذا البحث إلى أن قدرات التمثيل ثلاثي الأبعاد لنموذج لغة بصرية عام قد تتجاوز التوقعات السابقة بكثير، وتُقدم دليلًا تجريبيًا جديدًا على التحول في مجال الرؤية ثلاثية الأبعاد من "التحسين المُخصص لكل مهمة" إلى "نموذج أساسي موحد".