Command Palette
Search for a command to run...
ملخص الأبحاث | أحدث التطورات في مجال التعلم المعزز واسع النطاق: مايكروسوفت، وجوجل، وستانفورد، وجامعة رينمين، وشياوهونغشو، وغيرها تُعلن عن إنجازات هامة في تخصيص الرصيد، والاستدلال المعقد، والتعلم المعزز للوكلاء

بالنظر إلى التطور الحالي للتعلم المعزز، سواء كان ذلك تحسين قدرات تخصيص الرصيد في الاستدلال طويل السلسلة، أو تعزيز الاستكشاف الذاتي للنموذج في البيئات المعقدة، أو بناء أنظمة وكلاء ذكية ذات قدرات تخطيط طويلة الأجل وتعلم التغذية الراجعة، فإن أهدافها الأساسية جميعها تشير إلى نفس الاتجاه.تجاوز قيود المكافآت المحدودة والإشراف الثابت،فهو يمكّن النموذج من التعلم والتطور باستمرار من خلال التفاعل.
التعلم المعزز هو في جوهره أسلوب يسمح للوكيل الذكي بتحسين استراتيجياته السلوكية باستمرار من خلال حلقة مغلقة من "الإدراك - القرار - التنفيذ - التغذية الراجعة". على عكس التعلم الخاضع للإشراف التقليدي، الذي يعتمد على توزيع بيانات ثابت، يركز التعلم المعزز على قدرة النموذج على التعلم من خلال التجربة والخطأ في التفاعلات البيئية، مما يُمكّنه من تكوين آلية اتخاذ قرار تدريجيًا تُعظّم الفوائد طويلة الأجل في المهام الديناميكية.باختصار، التعلم المعزز يدفع الذكاء الاصطناعي من "القدرة على الإجابة على الأسئلة" إلى "القدرة على التصرف بشكل مستقل"، مما يكمل قفزة كبيرة من "التوليد السلبي" إلى "الذكاء النشط".
هذا الاسبوع،اختارت لكم HyperAI ستة من أحدث الأبحاث في مجال التعلم المعزز للنماذج الكبيرة.يضم الفريق القائم على هذا المشروع نخبة من الجامعات المرموقة مثل جامعة ستانفورد وجامعة رينمين الصينية، بالإضافة إلى عمالقة التكنولوجيا مثل مايكروسوفت وجوجل وكوايشو وشياوهونغشو. وتقدم أبحاثهم حلولاً جديدة ملهمة لبناء نماذج واسعة النطاق من الجيل التالي، تتميز بقدرات استدلالية وتعلم ذاتي قوية. هيا نتعلم معاً! ⬇️
بالإضافة إلى ذلك، ولتمكين المزيد من المستخدمين من فهم أحدث التطورات في مجال الذكاء الاصطناعي في الأوساط الأكاديمية،يضم الموقع الرسمي لشركة HyperAI الآن قسم "أحدث الأوراق البحثية"، مما يسمح للمستخدمين بالبقاء على اطلاع دائم بأحدث أبحاث الذكاء الاصطناعي.
أحدث أبحاث الذكاء الاصطناعي:https://go.hyper.ai/hzChC
توصيات الورقة البحثية لهذا الأسبوع
1 صدى
عنوان الورقة:
إيكو: وكلاء طرفيون يتعلمون نماذج العالم مجاناً
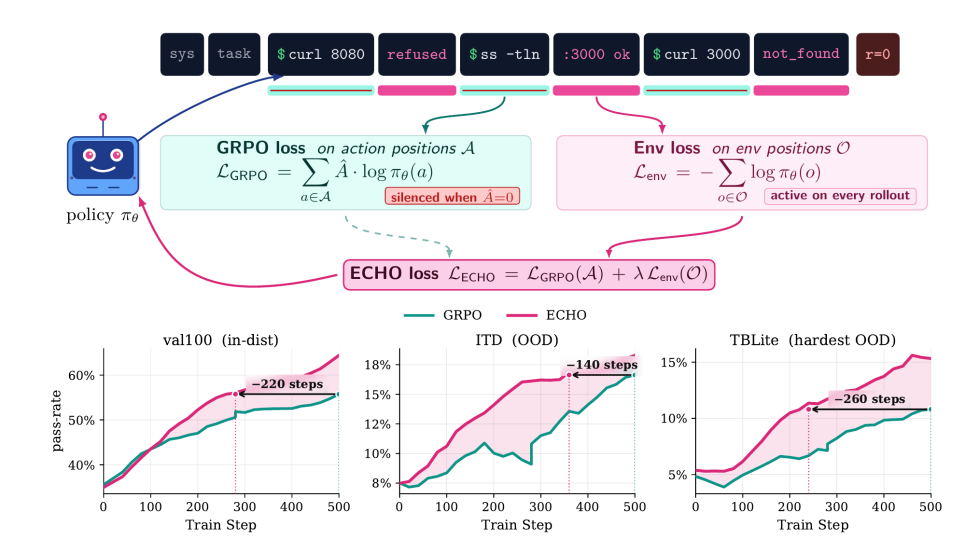
تُنتج تفاعلات الوكلاء الطرفيين كميات هائلة من بيانات التغذية الراجعة البيئية، لكن التعلم المعزز التقليدي يستخدم مكافآت محدودة لتحديث تصنيفات الأفعال، مما يُهدر بيانات الملاحظة بشكل كبير. يقترح هذا البحث طريقة ECHO، التي تحافظ على خسارة الأفعال، وتحسب في الوقت نفسه خسارة التنبؤ بالإنتروبيا المتقاطعة لتصنيفات التغذية الراجعة البيئية. لا تزيد هذه الآلية من عبء الانتشار الأمامي، مما يُمكّن السياسة من التنبؤ بشكل متزامن باستجابات الجهاز الطرفي للتعليمات أثناء التدريب، وبالتالي تعلم نموذج العالم تلقائيًا.
تُظهر النتائج التجريبية أن هذه الطريقة تضاعف دقة الاستجابة الأولى على معيار التحكم الطرفي، وتعزز بشكل كبير القدرة على التنبؤ بديناميكيات الطرفية غير المرئية، وتقلل بشكل كبير من الاعتماد على عروض الخبراء، ويمكنها حتى تحقيق التطور الذاتي دون تحقق خارجي.
ورقة وتفسير مفصل:https://go.hyper.ai/qma4O
2 دلتا
عنوان الورقة:
دلتا: تخصيص ائتمان الرموز المميزة للتعلم المعزز من المكافآت القابلة للتحقق
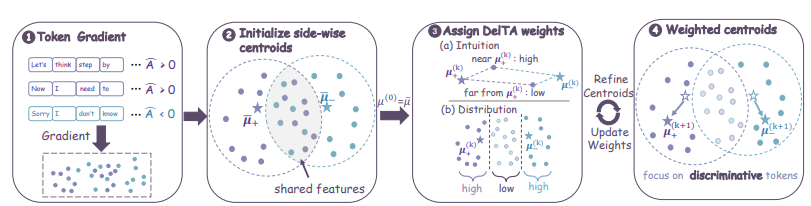
غالبًا ما يواجه التعلم المعزز القائم على المكافآت القابلة للتحقق تحديًا يتمثل في دقة تخصيص الرصيد غير الدقيقة. إذ تُهيمن الأنماط المشتركة عالية التردد، مثل أنماط الطباعة، على التحديثات المنتظمة بسهولة، مما يُعيق تحديد مؤشرات الاستدلال الرئيسية التي تُحقق عوائد عالية بالفعل. ولمعالجة هذه المشكلة، يقترح هذا البحث خوارزمية DelTA، التي تُعيد ترجيح دالة الهدف ذاتية التطبيع عن طريق حساب معاملات فريدة. تُضخّم هذه الآلية بدقة اتجاهات تدرج المؤشرات الفريدة لكل من جانبي المكافآت الإيجابية والسلبية، وتُثبّط بشدة الاتجاهات المشتركة ضعيفة التمييز، وتُحسّن بشكل ملحوظ تباين تحديثات التدرج. في تقييمات الاستدلال الرياضي وتوليد الشفرة، تتفوق هذه الطريقة بشكل شامل على أفضل الطرق الأساسية في نطاقها، وتُظهر قدرة تعميم ممتازة عبر مختلف البنى.
ورقة وتفسير مفصل:https://go.hyper.ai/IdI42
3 GoLongRL
عنوان الورقة:
GoLongRL: التعلم المعزز ذو السياق الطويل الموجه نحو القدرات مع مواءمة المهام المتعددة
غالبًا ما يواجه التعلم المعزز للسياقات الطويلة قيودًا بسبب تجانس بيانات التدريب على الاسترجاع، كما أن الخوارزميات التقليدية عُرضة لتشويه تقدير الميزة نتيجةً لاختلافات الحجم والصعوبة عند التعامل مع مكافآت مختلطة عبر مهام متعددة. يقترح هذا البحث مخطط GoLongRL الموجه نحو القدرات، والذي يُعد رائدًا في استخدام مجموعة بيانات مفتوحة المصدر تغطي تسع قدرات أساسية ومكافآت مُخصصة. ولمعالجة تحديات التحسين، تم تصميم آلية TMN-Reweight، التي تستخدم التطبيع على مستوى المهمة لمواءمة مقاييس المكافآت المختلفة، وتجمع بين أوزان مُتكيفة مع الصعوبة للتركيز على العينات الصعبة ذات القيمة العالية. تُظهر التقييمات أن هذا المخطط يتفوق بشكل شامل على النماذج الرائدة الحالية في العديد من معايير النصوص الطويلة، ويتجنب بشكل فعال تراجع قدرات الاستدلال والذاكرة العامة.
ورقة وتفسير مفصل:https://go.hyper.ai/omy5E
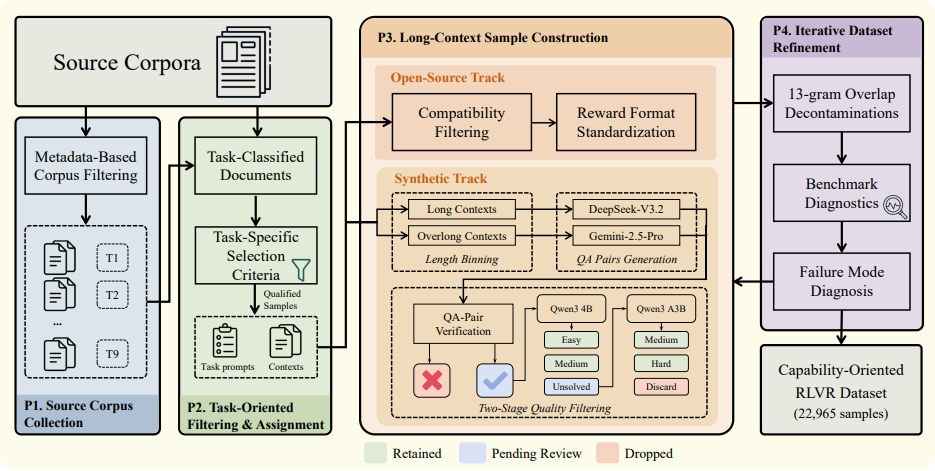
قام المؤلفون بإنشاء مجموعة بيانات تحتوي على 22965 عينة، تغطي تسع مهام موجهة نحو القدرات، بأطوال سياق تتراوح من 0.1 ألف إلى 256 ألف رمز.
4 مضاد SD
عنوان الورقة:
تقنية مقاومة التقطير الذاتي للاستدلال المعزز عبر المعلومات المتبادلة النقطية
يؤدي التقطير الذاتي التقليدي في مهام الاستدلال الرياضي بسهولة إلى دفع النماذج إلى "اتخاذ طرق مختصرة"، مما يؤدي إلى الاعتماد المفرط على الإجابات المعروفة وكبح عملية التفكير التي تُحرك عمليات البحث متعددة الخطوات. ولمعالجة هذه المشكلة، يقترح هذا البحث طريقة "مضاد التقطير الذاتي" (AntiSD). فبدلاً من تضييق الفجوة بين نماذج المعلم والمتعلم بشكل سلبي، تعمل هذه الطريقة على زيادة تباعد JS إلى أقصى حد لعكس إشارة التدرج، مع مكافأة مؤشرات التفكير الاستكشافي على وجه التحديد، وتُكمل ذلك بآلية بوابات قائمة على الإنتروبيا للحفاظ على استقرار التدريب. في الاختبارات التي أُجريت على نماذج كبيرة متعددة ذات مقاييس معلمات متفاوتة، تتطلب هذه الطريقة من خُمس إلى نصف خطوات التدريب الأساسية فقط لتحقيق الهدف، مع تحسين الدقة النهائية بما يصل إلى 11.5 نقطة مئوية على معايير متعددة للاستدلال الرياضي.
ورقة وتفسير مفصل:https://go.hyper.ai/Vax3f
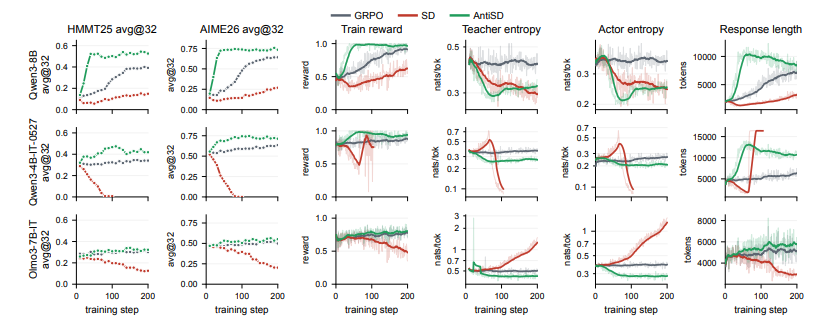
5 RubricEM
عنوان الورقة:
RubricEM: التعلم المعزز الفائق مع تحليل السياسات الموجه بالمعايير بما يتجاوز المكافآت القابلة للتحقق
غالبًا ما تفتقر مهام البحث المعمقة طويلة الأمد إلى مكافآت موضوعية، كما أن التعلم المعزز التقليدي لا يُقدم سوى تغذية راجعة عامة لا تُسهم في تراكم الخبرة الفعّالة. يقترح هذا البحث إطار عمل RubricEM، الذي يستخدم بشكل مبتكر "مقياس تقييم" كواجهة أساسية. يُقسّم النموذج المسارات الطويلة إلى مراحل التخطيط والاسترجاع والمراجعة والاستجابة، استنادًا إلى مقياس مُصمم خصيصًا، مما يُحقق تخصيصًا دقيقًا للنقاط. في الوقت نفسه، يُدرّب إطار العمل السياسات الفوقية بشكل غير متزامن، مُستخرجًا التفاعلات السابقة في ذاكرات انعكاسية قابلة لإعادة الاستخدام. في العديد من تقييمات البحث طويلة الأمد، يتفوق هذا النموذج (8B) على العديد من الحلول مفتوحة المصدر، ويقترب من أفضل أنظمة المصادر المغلقة، مُحققًا تعلمًا فعالًا للسياقات الطويلة وتعميمًا ممتازًا بين المهام بأقل عدد من خطوات التدريب.
ورقة وتفسير مفصل:https://go.hyper.ai/xSVTh
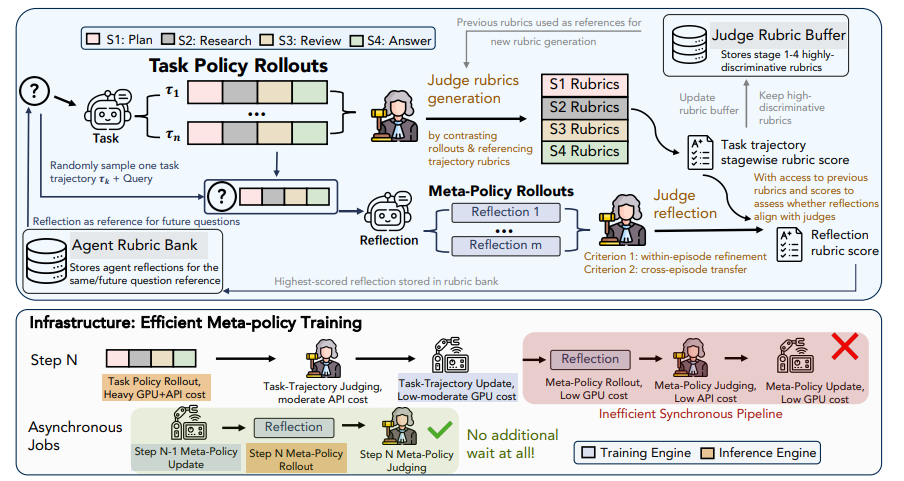
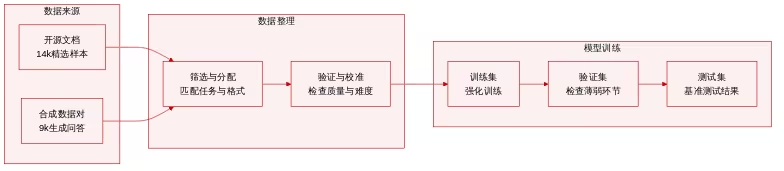
تكوين مجموعة البيانات ومصدرها: قام فريق البحث بإنشاء مجموعة بيانات ضبط دقيق خاضعة للإشراف تحتوي على ما يقارب 11000 عينة. مصدر البيانات هو مسارات العوامل التي تم إنشاؤها بواسطة نموذج Gemini التعليمي وتم تكييفها مع Qwen3.

6 بولي-إيبو
عنوان الورقة:
بولي-إي بي أو: تدريب نماذج الاستدلال الاستكشافي
غالبًا ما يؤدي التدريب اللاحق لنماذج التعلم المعزز واسعة النطاق إلى انهيار التنوع التوليدي، مما يعيق استكشاف مسارات استدلال جديدة وتوسيع نطاق الحساب أثناء الاختبار. ولمعالجة الاستكشاف والاستخدام التعاونيين، تقترح هذه الدراسة خوارزمية Poly-EPO القائمة على التعلم المعزز الجماعي. تتجاوز هذه الطريقة النهج التقليدي لتقييم الاستجابات الفردية بمعزل عن بعضها، حيث تضرب متوسط مكافأة مجموعة من الاستجابات في درجة تنوع سياسة الاستدلال كهدف تحسين مشترك، وبالتالي تدمج بشكل أصيل إشارات تشجع على الاستكشاف المتنوع في دالة الميزة. في تقييمات الاستدلال الرياضي، تتجنب هذه الخوارزمية بنجاح تجانس السياسة، محققةً تحسينًا في تغطية pass@k يصل إلى 20%، ومظهرةً إمكانات توسع أقوى في ظل آليات التصويت بالأغلبية.
ورقة وتفسير مفصل:https://go.hyper.ai/j9Z3C
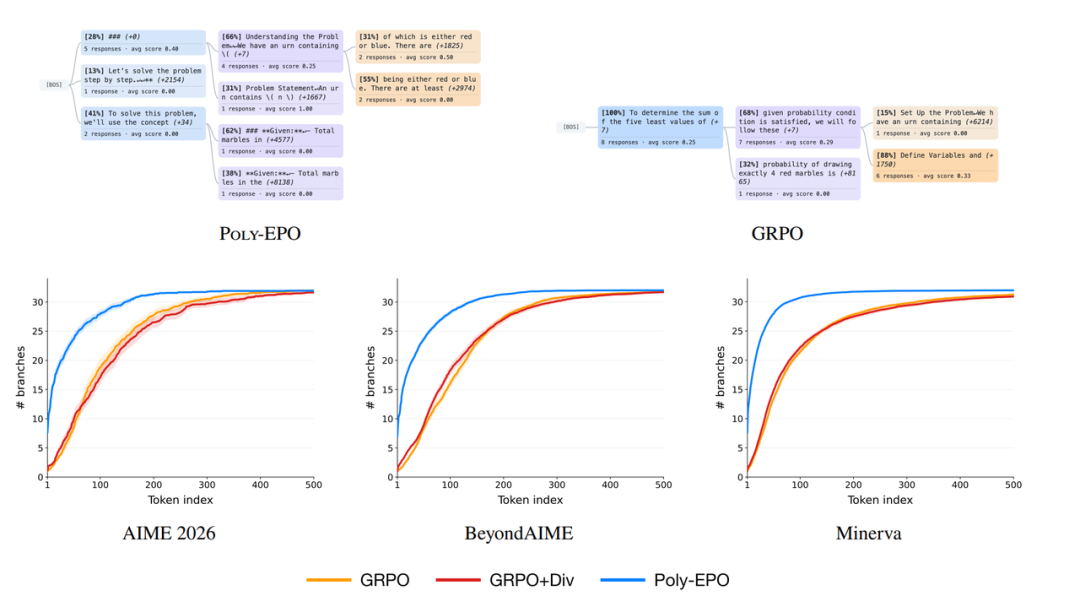
هذا هو محتوى توصيات البحث لهذا الأسبوع. لمزيد من أبحاث الذكاء الاصطناعي المتطورة، يُرجى زيارة قسم "أحدث الأبحاث" على الموقع الرسمي لـ hyper.ai.
نراكم في الاسبوع القادم!








