Command Palette
Search for a command to run...
تم إصدار Anima V1، وهو نموذج جديد تمامًا للصور الخام، ويركز على توليد الصور بأسلوب الأنمي؛ وتغطي مجموعة بيانات تقييم الذاكرة طويلة المدى متعددة الوسائط MemLens آليات الاستدلال من النص إلى الصورة عبر المحادثات وآليات تحديث المعرفة.

Anima V1 هو نموذج لتوليد الصور بأسلوب الأنمي تم إصداره بواسطة CircleStone Labs في عام 2026، وهو مصمم خصيصًا لرسوم الشخصيات والرسوم التوضيحية وغيرها من الإبداعات البصرية ثنائية الأبعاد.يمكنك إخراج صور جميلة بسرعة عن طريق وصف تفاصيل الشخص والإضاءة باستخدام موجه نصي.بفضل واجهة Grado المتكاملة للمشروع، يمكن للمطورين التخلص من استدعاءات البرامج النصية البحتة المرهقة وتعديل المعلمات الرئيسية مباشرة مثل الحجم وخطوات أخذ العينات وCFG في المتصفح، مما يجعلها أكثر ملاءمة لسير العمل العملي مثل تحديد الأدوار وإثبات المفهوم.
يعرض موقع HyperAI الآن "Anima V1: توليد الصور بأسلوب الأنمي"، لذا جربه!
الاستخدام عبر الإنترنت:https://go.hyper.ai/4PF0Y
نرحب بكم لزيارة موقعنا الإلكتروني الرسمي لمزيد من المعلومات:
نظرة سريعة على تحديثات الموقع الرسمي لشركة hyper.ai من 16 مايو إلى 22 مايو:
* مجموعات البيانات العامة عالية الجودة: 5
* مجموعة مختارة من الدروس التعليمية عالية الجودة: 4
* تفسير المقالات المجتمعية: 4 مقالات
* إدخالات الموسوعة الشعبية: 5
قم بزيارة الموقع الرسمي:هايبر.اي
مجموعات البيانات العامة المختارة
1. مجموعة بيانات الاستدلال البصري VisCoR-55K
VisCoR-55K هي مجموعة بيانات عالية الجودة للاستدلال البصري، أُصدرت عام 2026 من قِبل جامعة هوا تشونغ للعلوم والتكنولوجيا بالتعاون مع علي بابا كلاود. تحتوي المجموعة على ما يقارب 55,000 عينة استدلال بصري، تُولّد كل منها عملية استدلال مُقابلة باستخدام عينات مُقارنة. تُغطي المجموعة خمس فئات رئيسية من مجموعات بيانات الاستدلال البصري عالية الجودة: العامة، والاستدلال، والرياضية، والرسوم البيانية، والتعرف الضوئي على الأحرف (OCR)، وتهدف إلى تعزيز البحث في مجال الاستدلال البصري الموثوق والقوي باستخدام نماذج اللغة البصرية.
الاستخدام عبر الإنترنت:https://go.hyper.ai/iQlsz
2. مجموعة بيانات مسار تفاعل الوكلاء الأذكياء من AgentTrove
AgentTrove عبارة عن مجموعة بيانات مفتوحة المصدر واسعة النطاق لمسارات تفاعل الوكلاء، أصدرها فريق OpenThoughts-Agent. تحتوي هذه المجموعة على 1,696,847 صفًا من البيانات من 219 مجموعة بيانات، تغطي مهامًا مثل إصلاح الشفرات البرمجية، وكتابة البرامج النصية، وحل المسائل الرياضية، ومسابقات البرمجة، والحوسبة العامة.
الاستخدام عبر الإنترنت:https://go.hyper.ai/iEMLh
3. مجموعة بيانات هيدرولوجية كبيرة الحجم من مجتمع كارافان العالمي
كارافان عبارة عن مجموعة بيانات هيدرولوجية عالمية مفتوحة المصدر وواسعة النطاق، تعمل على توحيد ودمج سبع مجموعات بيانات هيدرولوجية واسعة النطاق موجودة، تحتوي على بيانات التأثيرات المناخية، وخصائص مستجمعات المياه، وبيانات التدفق لمستجمعات المياه العالمية. وتتضمن مجموعة البيانات بيانات التأثيرات المناخية، وبيانات الجريان السطحي، وخصائص مستجمعات المياه الثابتة (مثل الخصائص الجيوفيزيائية والاجتماعية والمناخية) لـ 6830 مستجمع مياه.
الاستخدام عبر الإنترنت:https://go.hyper.ai/OUa2g
4. مجموعة بيانات MemLens المعيارية متعددة الوسائط ذات السياق الطويل
MemLens هي مجموعة بيانات مرجعية لتقييم ذاكرة الحوار طويلة المدى في نماذج اللغة المرئية. تختبر هذه المجموعة قدرة النموذج على استرجاع المعلومات المرئية والنصية المضمنة في حوارات متعددة المحادثات، وتحديثها، واستنتاجها، ضمن نوافذ سياقية بأحجام 32 ألف، و64 ألف، و128 ألف، و256 ألف. تحتوي مجموعة البيانات على 789 سؤالًا تغطي خمسة أنواع من التقييم: استرجاع المعلومات، وتحديث المعرفة، والاستدلال الزمني، والاستدلال متعدد المحادثات، والرفض (الامتناع)، وتوفر أربعة تكوينات لأطوال السياق (32 ألف/64 ألف/128 ألف/256 ألف).
الاستخدام عبر الإنترنت:https://go.hyper.ai/ZR0s9
5. مجموعة بيانات LongBlocks للإجابة على الأسئلة متعددة اللغات ذات السياق الطويل
LongBlocks هي مجموعة بيانات اصطناعية متعددة اللغات ذات سياق طويل، صدرت عام 2026 من قِبل جامعة لشبونة، ومعهد الاتصالات، وشركة TransPerfect، ومؤسسات أخرى. تحتوي هذه المجموعة على ما يقارب 194,000 مثال على أسئلة وأجوبة ذات سياق طويل، تغطي مجموعات وثائق طويلة مثل الكتب، ونصوص صفحات الويب، ومقالات ويكيبيديا، وأوراق arXiv، وشفرات البرمجة، وأسئلة وأجوبة المجتمع.
الاستخدام عبر الإنترنت:https://go.hyper.ai/dc0W6
دروس تعليمية عامة مختارة
1. أنيما الإصدار الأول: توليد الصور بأسلوب الأنمي
Anima V1 هو نموذج لتوليد الصور بأسلوب الأنمي، أطلقته شركة CircleStone Labs عام 2026، وهو مصمم لسيناريوهات مثل رسومات الشخصيات، والأعمال الفنية، وفنون التصميم، وإنشاء الصور ثنائية الأبعاد. يمكن للمستخدمين وصف الشخصيات، والملابس، والوضعيات، والإضاءة، والأجواء باستخدام نصوص توضيحية، مما يُنتج صورًا ذات جماليات أنمي مميزة.
تشغيل عبر الإنترنت:https://go.hyper.ai/4PF0Y

2. MLSysBook: تجارب تفاعلية في مختبرات التعاون
مختبرات MLSysBook التفاعلية هي منصة تعليمية تفاعلية لأنظمة التعلم الآلي، طورتها جامعة هارفارد. تحتوي المنصة على 33 مختبرًا يمكن تشغيلها مباشرةً عبر المتصفح دون الحاجة إلى تثبيت أي برامج أو تهيئة بيئة العمل. يستغرق كل مختبر حوالي 50 دقيقة، ويتبع دورة تعليمية قائمة على "التنبؤ، والاكتشاف، والشرح"، مما يوجه المتعلمين لحل مشكلات واقعية في أنظمة التعلم الآلي.
تشغيل عبر الإنترنت:https://go.hyper.ai/0XrSs
3. ماجيك ريزوم: محرر سيرة ذاتية مدعوم بالذكاء الاصطناعي
ماجيك ريزوم هو محرر سيرة ذاتية مجاني يعمل بتقنية الذكاء الاصطناعي، تم تطويره كمصدر مفتوح من قِبل سيوي عام ٢٠٢٥. لا يُعد هذا المشروع مجرد مجموعة تقليدية من قوالب السيرة الذاتية الثابتة، بل هو منصة عمل حديثة عبر الإنترنت مصممة خصيصًا للباحثين عن عمل. يدعم البرنامج المعاينة الفورية، والحفظ التلقائي، والتخزين المحلي، والسمات المخصصة، والوضع الداكن، والتصميم المتجاوب، وتصدير ملفات PDF. يمكن للمستخدمين إدخال معلوماتهم الشخصية، ومؤهلاتهم التعليمية، وخبراتهم العملية، وخبراتهم المهنية، وغيرها من البيانات في منطقة التحرير، ثم معاينة سيرتهم الذاتية النهائية فورًا.
تشغيل عبر الإنترنت:https://go.hyper.ai/oLXO5
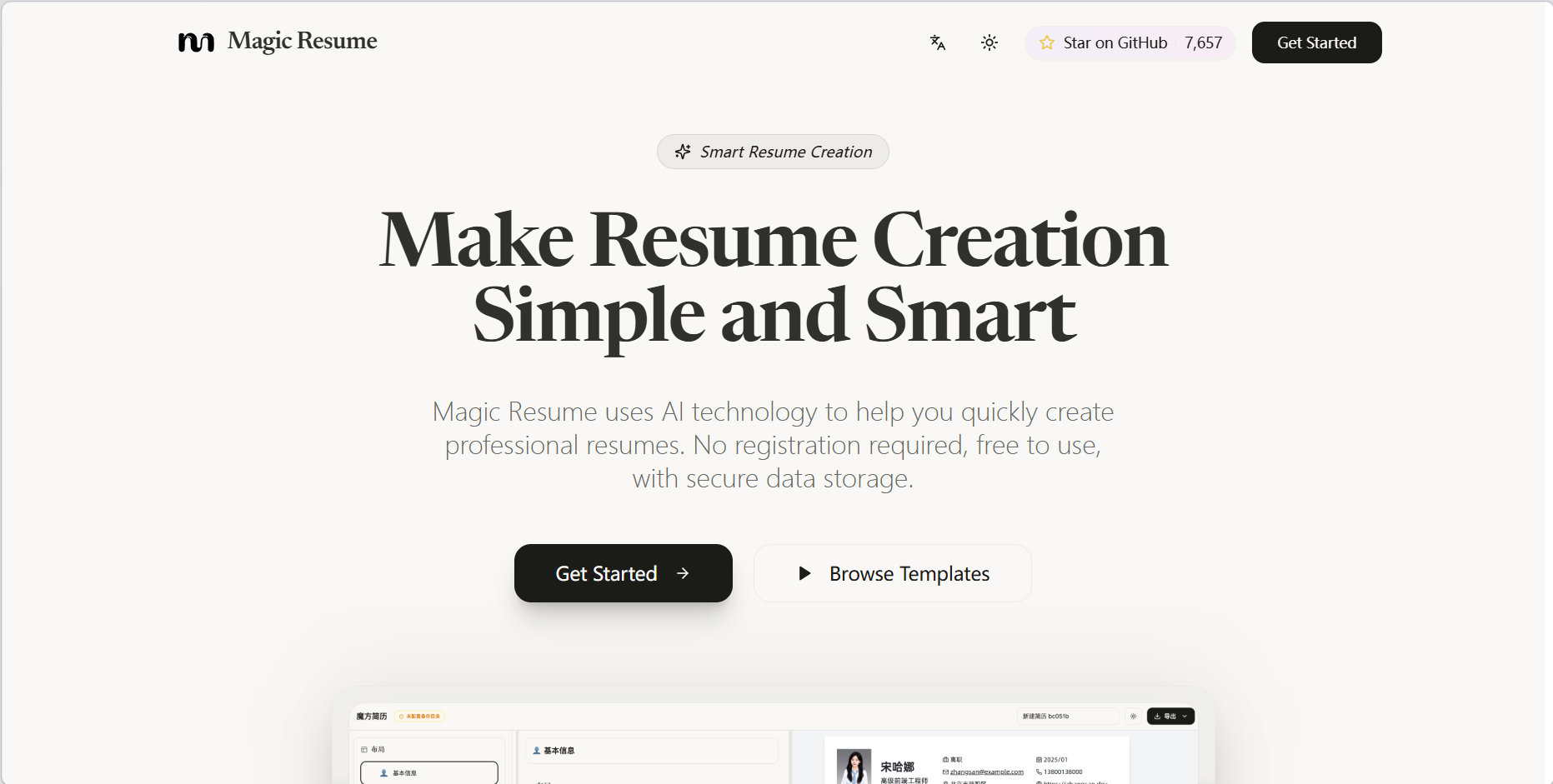
4. سوبرتونيك-3: نظام توليف كلام محلي متعدد اللغات خفيف الوزن
أصدر فريق Supertonic في مايو 2026 نموذج Supertonic-3، وهو نموذج خفيف الوزن لتحويل النص إلى كلام متعدد اللغات، مناسب لسيناريوهات الحوسبة المحلية، وغير المتصلة بالإنترنت، والحوسبة الطرفية. يوفر التطبيق الرسمي منهجية استدلال عالية المستوى تعتمد على حزمة تطوير البرمجيات Supertonic Python SDK، بينما يتم تنفيذ عملية توليف الكلام الأساسية من خلال ONNX Runtime، مما يجعله مناسبًا للتحقق السريع ونمذجة التطبيقات في بيئة وحدة المعالجة المركزية.
تشغيل عبر الإنترنت:https://go.hyper.ai/uRYzv
💡لقد قمنا أيضًا بتأسيس مجموعة تبادل تعليمية حول الانتشار المستقر. مرحبًا بالأصدقاء لمسح رمز الاستجابة السريعة والتعليق على [برنامج تعليمي SD] للانضمام إلى المجموعة لمناقشة المشكلات الفنية المختلفة ومشاركة نتائج التطبيق ~

تفسير مقالة المجتمع
1. بفضل دقة بلغت 94%، حقق فريق إسباني اكتشافًا آليًا للأجسام القريبة من الأرض وخطوط الأقمار الصناعية استنادًا إلى YOLO11، مع تحديد مستقر عبر الإطارات المتتالية.
يستطيع نظام StreakMind، الذي طوّره المرصد الفلكي التابع للأكاديمية البحرية الملكية الإسبانية، تحديد المسارات الخطية التي تخلفها الأقمار الصناعية أو الكويكبات في الصور الفلكية تلقائيًا، واستخراج طول هذه المسارات وموقعها واتجاهها لتوفير بيانات موحدة للقياسات الفلكية اللاحقة وإدخالها في قواعد البيانات. وقد أظهر النموذج، في مجموعة اختبار مستقلة، أداءً موثوقًا به للمسارات القصيرة والمتوسطة والطويلة، محققًا دقة إجمالية قدرها 941 نقطة لكل 3 مراتب (TP3T) واستدعاءً قدره 971 نقطة لكل 3 مراتب (TP3T)، حيث نجح في رصد 107 مسارات من أصل 110 مسارات حقيقية.
شاهد التقرير الكامل:https://go.hyper.ai/lo6jI
2. بفضل تسريع يصل إلى 252 مرة، استخدمت جامعة ستانفورد وجامعة كاليفورنيا في لوس أنجلوس ومؤسسات أخرى تقنية LSTM لنقل عمليات المحاكاة البصرية غير الخطية من الدرجة الثانية إلى عصر الميلي ثانية.
استنادًا إلى الأبحاث السابقة حول تطبيق الشبكات العصبية المتكررة (RNNs) على انتشار نبضات الألياف، اقترح فريق من جامعة ستانفورد وجامعة كاليفورنيا في لوس أنجلوس ومختبر SLAC الوطني للمسرعات نموذجًا بديلًا يعتمد على شبكات الذاكرة طويلة المدى التي يمكنها التنبؤ بسرعة ودقة بالمجال البصري الناتج عن SFG مع تقليل التكاليف الحسابية بشكل كبير.
شاهد التقرير الكامل:https://go.hyper.ai/7VsCZ
3. حقق فريق ألماني إنجازاً جديداً في مجال البحوث الطبية الحيوية ذات العينات الصغيرة باستخدام نماذج الذكاء الاصطناعي التوليدية لزيادة البيانات، مما قد يقلل من عدد حيوانات المختبر المطلوبة بمقدار 30-50 لكل TP3T.
قام فريق بحثي مشترك من جامعة فرانكفورت ومعهد فراونهوفر لتكنولوجيا المعلومات والمعالجة الطبية بتطوير نموذج genESOM، وهو نموذج ذكاء اصطناعي توليدي يعتمد على خرائط التنظيم الذاتي الناشئة، ومصمم خصيصًا لبيانات الطب الحيوي ذات العينات الصغيرة. ويكمن الابتكار الأساسي لهذا النموذج في فصل عملية تعلم البنية عن عملية توليد البيانات، ومنع انتشار الأخطاء من خلال تعديل الأبعاد، وإدخال متغير تحكم سلبي لمراقبة جودة البيانات المولدة في الوقت الفعلي.
شاهد التقرير الكامل:https://go.hyper.ai/4kngS
4. تم تحديث نظام جوجل العالمي للتنبؤ بالفيضانات إلى الإصدار 2، مما أدى إلى تمديد مدة التنبؤ الموثوقة بمقدار 6 أيام وتحسين الدقة بشكل كبير.
أصبح نظام التنبؤ العالمي بالفيضانات من الجيل الثاني (الإصدار الثاني) التابع لشركة جوجل للأبحاث جاهزًا للعمل، ويُشكّل المحرك الأساسي لوحدة التنبؤ بالأنهار في منصة جوجل فلود هب. وبالمقارنة مع الإصدار الأول، يُعالج الإصدار الثاني ثلاثة تحديات رئيسية مُزمنة كانت تُعيق تسويقه تجاريًا، وهي: نقص بيانات التدريب، ومحدودية طول السلاسل الزمنية، وتحيز توزيع بيانات الإدخال. تُعزز هذه التحسينات بشكلٍ كبير استقرار وموثوقية التنبؤات بالجريان السطحي على نطاق عالمي.
شاهد التقرير الكامل:https://go.hyper.ai/xI1Xe
مقالات موسوعية شعبية
1. ذاكرة الوكيل
2. العنصر البشري في الحلقة
3. التعلم الموحد
4. التعلم أثناء النشر
5. بنية متعددة الوكلاء
فيما يلي مئات المصطلحات المتعلقة بالذكاء الاصطناعي التي تم تجميعها لمساعدتك على فهم "الذكاء الاصطناعي" هنا:
إن ما ورد أعلاه هو كل محتوى اختيار المحرر لهذا الأسبوع. إذا كان لديك موارد تريد تضمينها على الموقع الرسمي لـ hyper.ai، فنحن نرحب بك أيضًا لترك رسالة أو إرسال مقال لإخبارنا بذلك!
نراكم في الاسبوع القادم!
حول HyperAI
HyperAI (hyper.ai) هي شركة رائدة في مجال الذكاء الاصطناعي والحوسبة عالية الأداء في الصين.نحن ملتزمون بأن نصبح البنية التحتية في مجال علوم البيانات في الصين وتوفير موارد عامة غنية وعالية الجودة للمطورين المحليين. حتى الآن، لدينا:
* يوفر نقاط تنزيل محلية معجلة لأكثر من 2100 مجموعة بيانات عامة
* يتضمن أكثر من 700 درس تعليمي كلاسيكي وشائع عبر الإنترنت
* تحليل أكثر من 300 دراسة حالة من أوراق بحثية حول الذكاء الاصطناعي للعلوم
* يدعم البحث عن أكثر من 700 مصطلح ذي صلة
* استضافة أول وثائق كاملة حول Apache TVM باللغة الصينية في الصين
قم بزيارة الموقع الرسمي لبدء رحلة التعلم الخاصة بك:








