Command Palette
Search for a command to run...
قام معهد ماساتشوستس للتكنولوجيا بتطوير نموذج Pichia-CLM لتعلم "لغة" الحمض النووي للخميرة، مما قد يزيد من إنتاج البروتينات الخارجية بما يصل إلى ثلاثة أضعاف.

في مجالي المستحضرات الصيدلانية الحيوية والتكنولوجيا الحيوية الصناعية، يظل التعبير الفعال عن البروتينات المؤتلفة عاملاً أساسياً يحدد تكاليف الإنتاج وجدوى العملية. فمن الأجسام المضادة وحيدة النسيلة ومستضدات اللقاحات إلى مستحضرات الإنزيمات الصناعية، حتى الزيادة الطفيفة في مستويات التعبير يمكن أن تُحقق قيمة اقتصادية كبيرة.
في العديد من أنظمة التعبير،تُقدّر خميرة Pichia pastoris (Komagataella phaffii) لقدرتها العالية على التخمر، ونظام التعبير الإفرازي الناضج، وقدراتها الممتازة على معالجة البروتين.أصبحت هذه الصناعة من أهم مراكز الإنتاج الصناعي. ومع ذلك، فإن إحدى المشكلات المزمنة التي تعاني منها هذه الصناعة هي أنه حتى لو كانت تسلسلات الأحماض الأمينية متطابقة تمامًا، فإن مجرد تغيير "الكودونات المترادفة" في الحمض النووي المشفر يمكن أن يؤدي إلى اختلافات هائلة في مستويات التعبير الجيني.
تنشأ هذه الظاهرة من انحياز استخدام الكودونات (CUB)، حيث تُستخدم في العديد من الكائنات الحية كودونات مترادفة معينة بشكل تفضيلي. ويؤثر اختيار الكودونات المترادفة على إنتاج البروتين من خلال التأثير على النسخ، واستقرار الحمض النووي الريبوزي الرسول (mRNA)، والترجمة، وطي البروتين، والتعديلات اللاحقة للترجمة (PTMs)، والذوبان.لذلك، أصبح "تحسين الكودون" خطوة أساسية في التعبير عن البروتينات الخارجية.
في الوقت الحالي، تم تطوير العديد من أدوات وأساليب تحسين الكودونات القائمة على وحدات التحكم في الكودونات المضيفة في الصناعة، ولكن هذه الأساليب قد لا تُنتج باستمرار تركيبات عالية التعبير. في السنوات الأخيرة، ومع تطور الذكاء الاصطناعي، وخاصة تقنيات نمذجة التسلسل،بدأ الباحثون ينظرون إلى تسلسلات الجينات على أنها نوع من "اللغة" ويحاولون تعلم القواعد الضمنية بداخلها باستخدام أساليب مشابهة لمعالجة اللغة الطبيعية.
وفي هذا السياق،اقترح فريق بحثي من معهد ماساتشوستس للتكنولوجيا نموذجًا لغويًا قائمًا على التعلم العميق، يُسمى Pichia-CLM، لتحسين الكودونات في المضيف الصناعي Pichia pastoris لتحسين إنتاج البروتينات المؤتلفة.بخلاف الطرق التقليدية التي تعتمد على مقاييس CUB (التي عادةً ما توفر درجة إجمالية فقط وتتجاهل سياق التسلسل)، يستخدم Pichia-CLM بيانات جينوم المضيف لتعلم ربط الأحماض الأمينية بالكودونات بشكل غير متحيز. وقد تحقق الباحثون تجريبياً من صحة Pichia-CLM على ست فئات بروتينية ذات تعقيد متفاوت، ولاحظوا باستمرار معدلات تعبير أعلى مقارنةً بأربع أدوات تجارية لتحسين الكودونات.
تم نشر نتائج البحث ذات الصلة، بعنوان "Pichia-CLM: خط أنابيب لتحسين الكودون قائم على نموذج اللغة لـ Komagataella phaffii"، في PNAS.
أبرز الأبحاث:
* يستخدم Pichia-CLM بيانات الجينوم المضيف لتعلم عملية ربط الأحماض الأمينية بالكودونات بشكل غير متحيز، مع مراعاة ليس فقط تفضيلات المضيف ولكن أيضًا الاعتماد على الموقع والعلاقات السياقية بعيدة المدى.
* تم التحقق تجريبياً من Pichia-CLM على ستة بروتينات ذات تعقيد متفاوت، وأظهرت باستمرار معدلات تعبير أعلى.
* يمكن تجميع تضمينات الأحماض الأمينية والكودونات التي تعلمها النموذج وفقًا لخصائصها الفيزيائية والكيميائية، مما يشير إلى أن نموذج اللغة يمكنه التقاط أنماط ذات معنى فيزيائي.
عنوان الورقة:
https://www.pnas.org/doi/10.1073/pnas.2522052123
تابع حسابنا الرسمي على WeChat وأجب بكلمة "Pichia pastoris" في الخلفية للحصول على ملف PDF كامل.
قم بإنشاء مجموعة بيانات تسلسلية واسعة النطاق تتمحور حول فطر Pichia pastoris
بخلاف الطرق التقليدية التي تعتمد على قواعد تجريبية، فإن الفكرة الأساسية لـ Pichia-CLM هي تعلم أنماط الترميز مباشرة من جينوم المضيف. ولتحقيق هذه الغاية،قام فريق البحث بإنشاء مجموعة بيانات تسلسلية واسعة النطاق تتمحور حول فطر Pichia pastoris.
لتدريب Pichia-CLM، جمع الباحثون بيانات تسلسل الأحماض الأمينية والترميز لنوعين من Pichia pastoris من NCBI: CBS7435 وGS115. وقد تم استكمال ذلك ببيانات تم إنجازها مسبقًا في مختبرهم، بما في ذلك تسلسل الجينوم وشرح GS115 وK. phaffii (NRRL Y11430) وK. pastoris.في المجمل، تم استخدام ما يقرب من 27000 زوج من بيانات تسلسل ترميز الأحماض الأمينية.
أثناء معالجة البيانات، قام الباحثون بتقسيم الأحماض الأمينية والكودونات إلى رموز، وأدخلوا البادئات (…). إنهاء ( ) واملأ ( تم تصنيف مجموعة البيانات لتمكين النموذج من التعامل مع تسلسلات ذات أطوال متفاوتة ودعم التدريب الدفعي. بالإضافة إلى ذلك، تم تقسيم مجموعة البيانات إلى مجموعتي تدريب واختبار، مع استخدام ما يقارب 201 من بيانات TP3T لتقييم قدرة النموذج على التنبؤ ببيانات غير مرئية.
تجدر الإشارة إلى أن طريقة بناء البيانات هذه لا تُدخل أي "أهداف تحسين" مصطنعة، بل تعتمد كلياً على بيانات الجينوم الطبيعية. وهذا يعني أن النموذج يتعلم تفضيلات التعبير الجيني الحقيقية للكائن المضيف، بدلاً من قواعد تقريبية مصطنعة، مما يرسخ الأساس لتحسينات الأداء اللاحقة.
يستخدم Pichia-CLM بنية التشفير-فك التشفير القائمة على GRU.
الهندسة المعمارية النموذجية
يستخدم نظام Pichia-CLM بنية التشفير-فك التشفير القائمة على وحدات التكرار البوابية (GRUs).تُعدّ GRU بنيةً محسّنةً للشبكات العصبية المتكررة، مصممةً لالتقاط التبعيات طويلة المدى وقصيرة المدى في بيانات التسلسل. ومن خلال تنظيم تدفق المعلومات عبر آليات البوابات، تُخفف GRU بفعالية من مشكلة تلاشي التدرج الشائعة في الشبكات العصبية المتكررة التقليدية. علاوةً على ذلك، يُضاهي أداء GRU أداء شبكات الذاكرة طويلة المدى (LSTM)، ولكنه يتطلب عددًا أقل من المعاملات ويستهلك موارد حاسوبية أقل، مما يوفر مزايا كفاءة أكبر في العديد من مهام نمذجة التسلسل.
بالمقارنة مع بنية أخرى سائدة، وهي Transformer، فإن GRU تتمتع بكفاءة حسابية أعلى واستهلاك أقل للموارد على مجموعات البيانات الصغيرة إلى المتوسطة الحجم.أظهرت الدراسات أنه مع حجم بيانات يبلغ حوالي 27000 تسلسل، فإن إدخال Transformer يمكن أن يزيد في الواقع من التعقيد غير الضروري، في حين أن GRU يمكن أن يحقق توازنًا أفضل بين الأداء والكفاءة.
يستقبل النموذج تسلسل الأحماض الأمينية للبروتين كمدخل، ويُنشئ تسلسل الحمض النووي المقابل بناءً على أنماط مُستخلصة من تسلسل الأحماض الأمينية للبروتين المضيف وتسلسل الترميز. يوضح الشكل أدناه البنية العامة للنموذج.
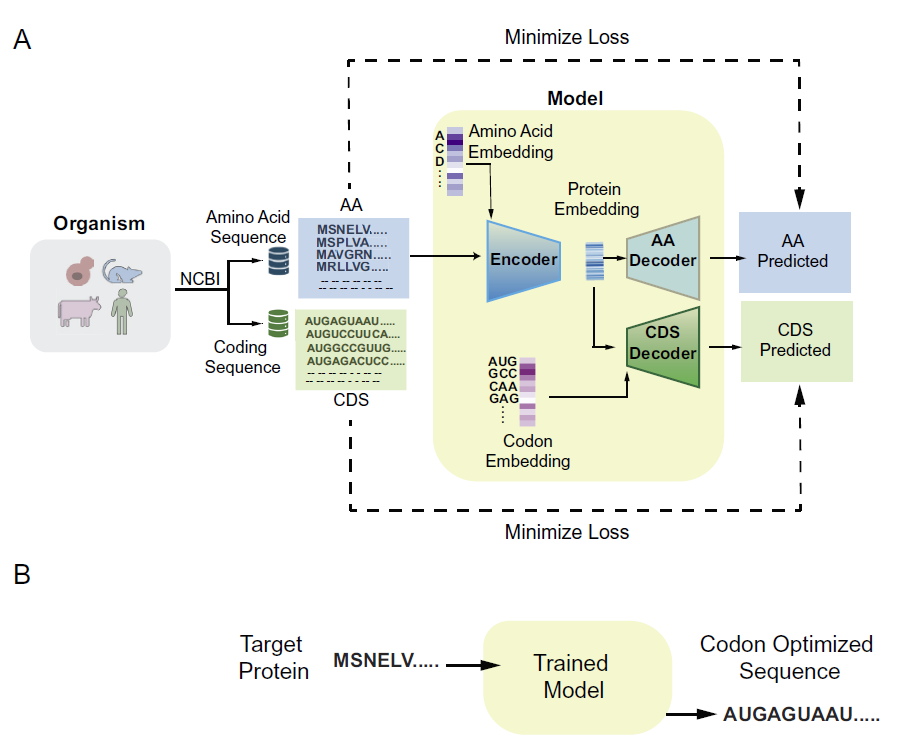
عملية تدريب النماذج
أثناء التدريب، استخدم الباحثون مجموعة التحقق (20% من مجموعة التدريب) للتوقف المبكر بهدف تحسين المعلمات. في الوقت نفسه، تم اختيار المعلمات الفائقة بهدف تقليل خسارة مجموعة التحقق (الإنتروبيا التقاطعية للتصنيف المتفرق).تعتمد عملية تحسين المعلمات الفائقة على استراتيجية تحسين عالمية تسمى التحسين البايزي، بالإضافة إلى التعليمات البرمجية التي تم تنفيذها داخليًا بواسطة الباحثين.
وبالتحديد، يتضمن النموذج المعلمات الفائقة التالية:
* بُعد تضمين الأحماض الأمينية
* بُعد تضمين الكودون
* عدد الوحدات في طبقة التشفير
* حجم طبقة الكودون المتصلة بالكامل في وحدة فك التشفير
* حجم طبقة الأحماض الأمينية المتصلة بالكامل في وحدة فك التشفير
أثناء تدريب النموذج، يكون مُدخل المُفكِّك هو التسلسل المُشفَّر الفعلي (أي الكودونات الحقيقية). في مرحلة التنبؤ، يستخدم النموذج الكودون المُتنبَّأ به في الموضع السابق كمدخل للموضع التالي، مما يُحقق تنبؤًا انحداريًا ذاتيًا كاملًا. يتوقف تنبؤ التسلسل عند مُصادفة كودون توقف.
بعد إتمام عملية اختيار بنية النموذج والتحقق من قدرته التنبؤية على مجموعة الاختبار، أعاد الباحثون تدريب النموذج النهائي باستخدام مجموعة البيانات الكاملة، واستمروا في استخدام استراتيجية الإيقاف المبكر لتجنب فرط التخصيص. استُخدم هذا النموذج النهائي لتصميم التسلسلات المشفرة للبروتينات الخارجية.
تستطيع بكتيريا Pichia-CLM إنتاج تركيبات عالية الإنتاج للبروتين.
في قسم التحقق التجريبي، اختار فريق البحث ستة بروتينات ذات مستويات مختلفة من التعقيد للاختبار، بما في ذلك:
هرمون النمو البشري (hGH)
* عامل تحفيز مستعمرات الخلايا المحببة البشرية (hGCSF)
* الجسم النانوي VHH 3B2 (34)
* متغير مُهندس لوحدة RBD لفيروس SARS-CoV-2 (RBD) (35)
* ألبومين مصل الدم البشري (HSA)
* جسم مضاد أحادي النسيلة من نوع IgG1 تراستوزوماب (تراست)
أداء Pichia-CLM في تعزيز إفراز البروتين في Pichia pastoris
أولاً،قام الباحثون باختيار ثلاثة بروتينات مشتقة من الإنسان بأحجام وتعقيدات مختلفة: hGH و hGCSF و HSA، وقارنوا الاختلافات في إنتاجية إفراز البروتين (العيار) بين تركيبات الجينات التي تم إنشاؤها باستخدام Pichia-CLM وتسلسلات الترميز الأصلية الخاصة بها.بشكل عام، بالنسبة للبروتينات مثل hGH و hGCSF، كانت الزيادة في الإنتاج حوالي 25%؛ بينما بالنسبة لـ HSA، لوحظت زيادة كبيرة بمقدار 3 أضعاف تقريبًا.
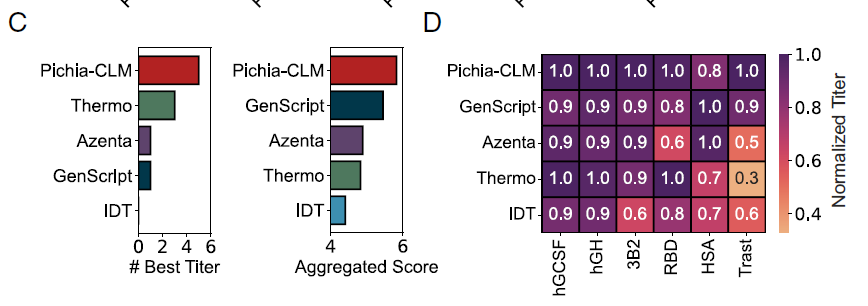
بعد ذلك، قارن الباحثون Pichia-CLM بأربع أدوات تجارية لتحسين الكودونات: Azenta و IDT و GenScript و Thermo Fisher (Thermo)، وقاموا بتقييم ستة بروتينات باستخدام مقياسين:
* BestTiter: عدد البروتينات ذات أعلى عيار تم الحصول عليه بطريقة معينة.
* النتيجة الإجمالية: مجموع العيارات النسبية للبروتينات المختلفة (مُقاسة بالنسبة للقيمة القصوى).
إجمالي،تفوقت Pichia-CLM على الخوارزميات التجارية في كلا المقياسين (الشكل C أدناه)؛ وحققت أعلى عيار في 5 من أصل 6 بروتينات، مع انخفاض طفيف فقط في النتيجة الإجمالية (حوالي 0.2) في HSA بسبب انخفاض طفيف في العيار (الشكل D أدناه).
تقييم خصائص التسلسل الجيني
بعد التحقق من أداء Pichia-CLM في إنتاج البروتينات الخارجية، قام الباحثون بتحليل خصائص التسلسل الجيني للتركيبات المصممة المختلفة.بالإضافة إلى نماذج لغة البروتين الأخرى المذكورة، يعتمد تحسين الكودونات عادةً على مقياس واحد أو أكثر من مقاييس انحياز استخدام الكودونات (CUB) للتصميم أو التقييم. لذلك، استخدمت هذه الدراسة بيانات من ستة بروتينات اختبارية لتقييم العلاقة بين مقاييس انحياز استخدام الكودونات هذه وإنتاجية البروتين.
أظهرت النتائج أن أياً من هذه المؤشرات لم يُظهر ارتباطاً ثابتاً وعالياً مع الإنتاجية عبر مختلف البروتينات. فعلى سبيل المثال، في حالة بروتين مصل الألبومين البشري (كما هو موضح في الشكل أ أدناه)، بلغ الحد الأقصى للارتباط الإيجابي مع تقلب الكودونات وتوزيع تردد الكودونات 0.43 فقط، بينما بلغ الحد الأقصى للارتباط السلبي مع درجة أزواج الكودونات 0.25 فقط.
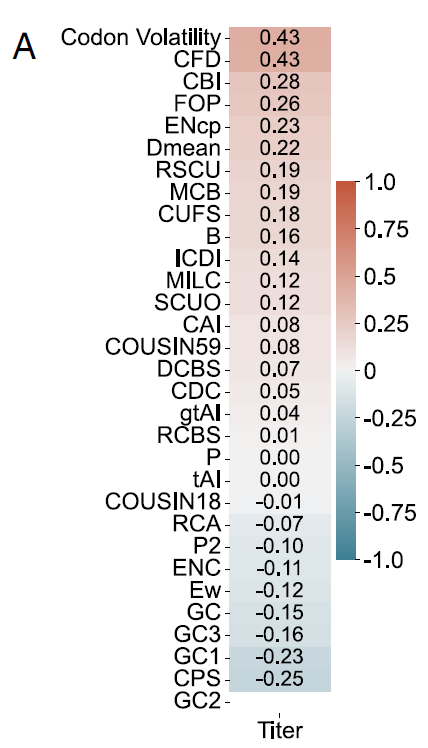
إن مقاييس CUB العالمية المحسوبة بناءً على التسلسل الكامل لها قيود كبيرة في تحديد السمات المتعلقة بإنتاج البروتين الخارجي.وهذا يوضح بشكل أكبر الحاجة إلى مقاييس تقييم جديدة لتقييم أدوات تحسين الكودون، إلى جانب التحقق التجريبي الصارم من البروتينات المتنوعة - وهي نتيجة تتحدى بشكل مباشر الأساس النظري لتحسين الكودون التقليدي.
تقييم ميزات التسلسل
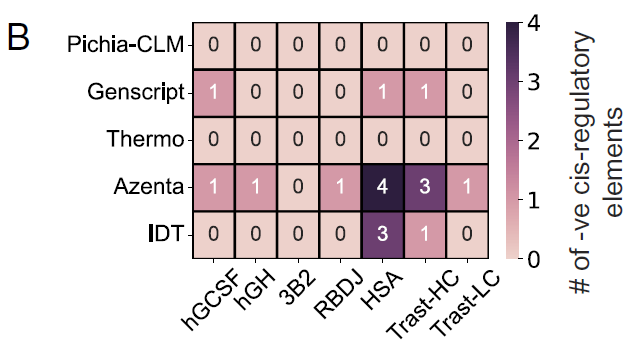
كما قام الباحثون بتقييم وجود عناصر تنظيمية سلبية في تركيبات مختلفة محسّنة للرموز، والتي يمكن أن تتداخل مع آليات التنظيم الخاصة بالمضيف، وبالتالي ينبغي تجنبها قدر الإمكان في تسلسلات الحمض النووي الخارجية.
من بين البروتينات الستة التي تم اختبارها،لم يتم الكشف عن أي عناصر تنظيمية سلبية في التركيبات المصممة باستخدام Pichia-CLM؛ على النقيض من ذلك، احتوى GenScript على عنصر تنظيمي سلبي واحد في ثلاثة من أصل ستة بروتينات؛ أنتجت Azenta و IDT تسلسلات تحتوي على ثلاثة إلى أربعة من هذه العناصر في بروتين واحد على الأقل.كما هو موضح في الشكل ب:
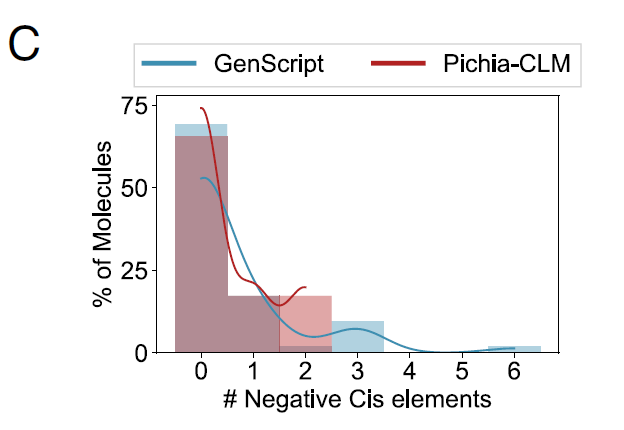
كما قام الباحثون بتحليل أداء Pichia-CLM في 52 بروتينًا متعلقًا بالتكنولوجيا الحيوية، وأظهرت النتائج ما يلي:لا يحتوي تسلسل البروتين 75% على أي عناصر تنظيمية سلبية على الإطلاق، بينما يحتوي تسلسل البروتين 25% المتبقي على عنصرين من هذا القبيل على الأكثر.في المقابل، فإن أفضل خوارزمية تجارية أداءً، وهي GenScript، لا تزال تنتج تركيبات تحتوي على 3 إلى 6 عناصر تنظيمية سلبية في البروتينات التي يبلغ طولها حوالي 15%، كما هو موضح في الشكل C أدناه:
باختصار، تُظهر هذه النتائج أن Pichia-CLM لا يمكنها فقط توليد تركيبات بروتينية عالية الإنتاجية، ولكنها تستطيع أيضًا تعلم السمات الرئيسية للتسلسل الجيني وتحقيق التوازن بين عوامل متعددة، وبالتالي تصميم تسلسلات ترميز قوية مناسبة للتعبير المضيف.
الذكاء الاصطناعي يسرع من تصنيع إنتاج البروتين
في صناعة المستحضرات الصيدلانية الحيوية، لطالما كان تحسين كفاءة إنتاج البروتين عاملاً أساسياً في تحديد نجاح أو فشل ترجمة الأبحاث والتطوير إلى منتجات تجارية. فمن الأجسام المضادة وحيدة النسيلة إلى اللقاحات المؤتلفة، ثم إلى مختلف البروتينات المدمجة ومستحضرات الإنزيمات، يستمر الطلب في السوق بالنمو، وتتزايد متطلبات الإنتاجية والاستقرار والاتساق باستمرار.
ولتحقيق هذا الهدف، طورت الصناعة نظام تحسين متعدد الطبقات: على مستوى المضيف، بالإضافة إلى بكتيريا الإشريكية القولونية التقليدية وخميرة الخباز، أصبحت خميرة بيكيا باستوريس والخلايا الثديية منصات الإنتاج الرئيسية نظرًا لقدراتها الفائقة على التعديل ما بعد الترجمة وكفاءة التعبير؛ على مستوى التصميم الجزيئي، بالإضافة إلى تحسين الكودون، يشمل ذلك تنظيم قوة المحفز، وفحص ببتيد الإشارة، والهندسة الهيكلية للرنا المرسال، وتحسين مسار طي البروتين وإفرازه؛ وعلى مستوى العملية، يلعب التخمر عالي الكثافة، وتحسين استراتيجية التغذية، والتحكم في معلمات المفاعل الحيوي دورًا حاسمًا في الناتج النهائي.
خارج هذا النظام،يظهر نوع جديد من تقنية "إزالة الخلايا" بسرعة: تخليق البروتين الخالي من الخلايا (CFPS).تتجاوز هذه التقنية عملية نمو الخلايا وتستغل نظام النسخ والترجمة في مستخلصات الخلايا مباشرةً لتحقيق إنتاج بروتيني سريع. وقد شاع استخدامها في تطوير وإنتاج الأجسام المضادة والإنزيمات، وحتى مركبات الأجسام المضادة والأدوية. مع ذلك، يُعد نظام التعبير البروتيني الخالي من الخلايا (CFPS) نظامًا متعدد المتغيرات شديد التعقيد، يضم عشرات المكونات مثل قوالب الحمض النووي، وأنظمة الإنزيمات، ومانحات الطاقة، والأحماض الأمينية، والبيئات الأيونية. مساحة التوليفات المتاحة فيه واسعة للغاية، وغالبًا ما تفشل أساليب التحسين التقليدية القائمة على الخبرة في تحقيق التوازن الأمثل بين التكلفة والإنتاجية.
في هذا السياق، يُظهر التحسين الآلي المدعوم بالذكاء الاصطناعي إمكانات ثورية. وقد نشرت شركة OpenAI مؤخرًا، بالتعاون مع شركة Ginkgo Bioworks الرائدة في مجال البيولوجيا التركيبية، نتائج بحثية رائدة.لقد نجح "نظام الأتمتة ذو الحلقة المغلقة" المبني على نموذج اللغة الكبير GPT-5 في تحقيق تحسين مزدوج لتقنية تخليق البروتين الخالي من الخلايا (CFPS) - مما أدى إلى تقليل إجمالي تكلفة إنتاج التقنية بمقدار 401 TP3T، وتقليل تكاليف الكواشف بشكل كبير بمقدار 571 TP3T، وتحسين عيار تخليق البروتين بمقدار 271 TP3T.
في المستقبل، سيتم توسيع نطاق هذه الأساليب لتشمل مجموعة أوسع من سيناريوهات التصنيع الحيوي. فمن تحسين المسارات الأيضية في مصانع الخلايا إلى التحكم في عمليات التخمير في الوقت الفعلي والتصميم الذكي لبنى التعبير الجيني، يتم دمج الذكاء الاصطناعي تدريجياً في جميع جوانب إنتاج الأدوية البروتينية.
مراجع:
1.https://www.pnas.org/doi/10.1073/pnas.2522052123
2.https://phys.org/news/2026-02-ai-yeast-dna-language-boost.html#google_vignette
3.https://mp.weixin.qq.com/s/Qkl6j9HcFB7W_Y5Xh-9BCw








