Command Palette
Search for a command to run...
استلهامًا من DeepSeek Engram، حقق "الدماغ الخارجي" للنموذج الأساسي للجينوم، Gengram، تحسنًا في الأداء يصل إلى 22.61 TP3T.

تُعدّ نماذج الجينوم الأساسية أدواتٍ جوهرية لفكّ شفرة الحياة، إذ تُتيح الكشف عن معلومات بيولوجية أساسية، مثل وظائف الخلايا ونمو الكائنات الحية، من خلال تحليل تسلسلات الحمض النووي. مع ذلك، تعاني نماذج الجينوم الأساسية القائمة على تقنية Transformer من عيبٍ جوهري: فهي تعتمد على تدريبٍ مُسبق واسع النطاق وحساباتٍ مُكثّفة لاستنتاج أنماط النيوكليوتيدات المتعددة بشكلٍ غير مباشر، وهو ما لا يُعدّ غير فعّال فحسب، بل يُحدّ من قدراتها في مهام الكشف عن العناصر الوظيفية المُستندة إلى الأنماط.
حديثاً،نموذج Gengram (النقش الجينومي) الذي اقترحه فريق Genos، والذي يتألف من أعضاء من معهد أبحاث علوم الحياة BGI ومختبر Zhejiang Zhijiang،يوفر هذا حلاً ثورياً لهذه المشكلة. يتجنب هذا التصميم تضمين القواعد البيولوجية بشكل ثابت، بينما يمنح النموذج فهماً واضحاً لـ "قواعد" الجينوم.
باعتبارها وحدة ذاكرة شرطية خفيفة الوزن مصممة خصيصًا لنمذجة أنماط الجينوم، يكمن الابتكار الأساسي لـ Gengram في آلية ذاكرة التجزئة k-mer الخاصة بها، والتي تُنشئ مستودع ذاكرة أنماط متعدد القواعد عالي الكفاءة. على عكس النماذج التقليدية التي تستنتج الأنماط بشكل غير مباشر،يقوم بتخزين k-mers مباشرة بأطوال تتراوح من 1 إلى 6 قواعد ومتجهات تضمينها، ويلتقط التبعيات السياقية المحلية للزخارف الوظيفية من خلال آلية تجميع النوافذ المحلية.ثم تُدمج معلومات النمط مع الشبكة الأساسية عبر وحدة تحكم بالبوابة. وذكر فريق البحث أنه عند دمج Gengram في نموذج الجينوم المتطور Genos، وفي ظل ظروف التدريب نفسها، يحقق تحسينات كبيرة في الأداء عبر مهام الجينوم الوظيفي المتعددة، مع أقصى تحسن قدره 22.61 TP3T.

عنوان الورقة:https://arxiv.org/abs/2601.22203
عنوان الكود:https://github.com/BGI-HangzhouAI/Gengram
أوزان النموذج:https://huggingface.co/BGI-HangzhouAI/جينجرام
تشمل بيانات التدريب جينومات الرئيسيات البشرية وغير البشرية.
تحتوي مجموعة بيانات التدريب على 145 تسلسلًا عالي الجودة تم تحليلها وتجميعها باستخدام تحليل النمط الفرداني، وتغطي جينومات الرئيسيات البشرية وغير البشرية.استُمدت التسلسلات البشرية بشكل أساسي من اتحاد مرجع الجينوم البشري الشامل (HPRC، الإصدار الثاني)، مع إضافة مرجعي الجينوم GRCh38 وCHM13. أُدمجت تسلسلات الرئيسيات غير البشرية من قاعدة بيانات NCBI RefSeq لتضمين التنوع التطوري. عُولجت جميع التسلسلات باستخدام ترميز أحادي ساخن. تشمل المفردات أربعة قواعد قياسية (A، T، C، G)، والنيوكليوتيدات الغامضة (N)، وعلامات نهاية المستند.
أخير،قام النظام بإنشاء ثلاث مجموعات من البيانات لدعم تجارب الاستئصال والتدريب المسبق الرسمي.
50 مليار رمز @ 8192 (الاستئصال)
200 مليار رمز مميز بسعر 8 آلاف (10 مليارات رمز مميز للتدريب المسبق الرسمي)
100 مليار رمز مميز بسعر 32 ألف (10 مليارات رمز مميز للتدريب المسبق الرسمي)
والحفاظ على نسبة خلط البيانات بين البشر وغير البشر = 1:1.
يتحول نمذجة الجينوم من "اشتقاق الانتباه" إلى "تحسين الذاكرة".
استلهامًا من آلية الذاكرة الخاصة بـ DeepSeek Engram، قام فريق Genos بتطوير ونشر Gengram بسرعة.توفر هذه الوحدة إمكانيات تخزين وإعادة استخدام الأنماط بشكل صريح لنماذج الجينوم الأساسية، متجاوزةً بذلك قيود نماذج الجينوم التقليدية التي تفتقر إلى ذاكرة أنماط منظمة، وتعتمد فقط على توسيع "الذاكرة الضمنية" لبيانات التدريب. وهذا ما يدفع نمذجة الجينوم من "استخلاص الانتباه" إلى "تحسين الذاكرة". يوضح الشكل أدناه بنية الوحدة:
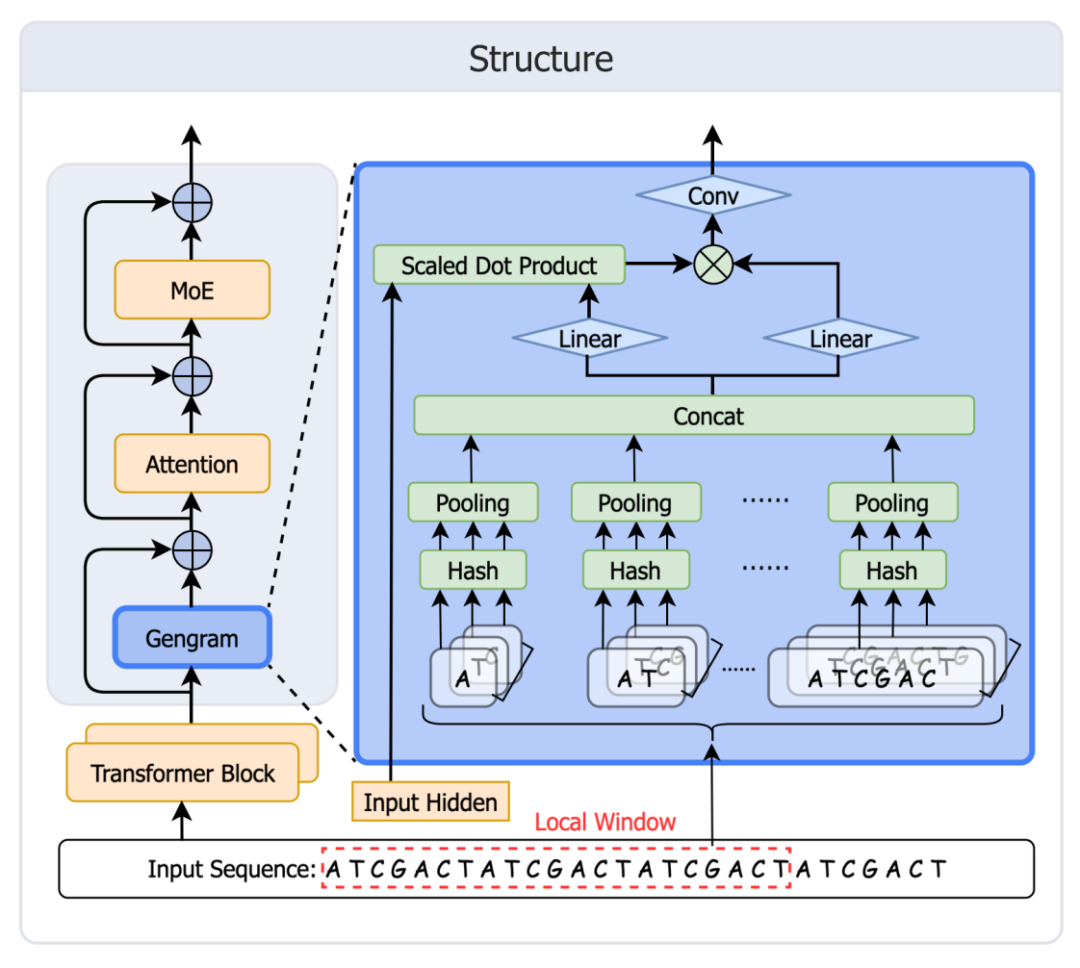
إنشاء الجدول: قم بإنشاء ذاكرة تجزئة (مفتاح ثابت + قيمة تضمين قابلة للتعلم) لجميع قيم k-mer من k=1 إلى 6.
الاسترجاع: قم بربط جميع قيم k-mer التي تظهر في النافذة بإدخالات الجدول.
التجميع: أولاً، قم بالتجميع عند كل k، ثم قم بالربط عبر k.
التحكم في البوابات: تتحكم البوابة في التنشيط، وتكتب دليل الزخارف في التيار المتبقي، ثم تدخل الانتباه.
إحدى ميزات التصميم الرئيسية: تجميع النوافذ المحلية (W=21bp)
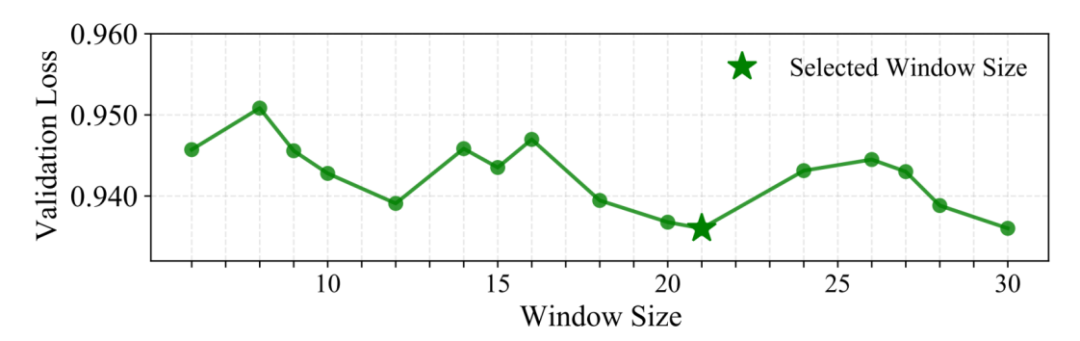
بدلاً من استرجاع سلسلة n-gram واحدة في كل موقع، يستخدم Gengram تجميع تضمينات k-mer متعددة ضمن نافذة ثابتة لإدخال أدلة على وجود أنماط محلية متسقة بنيوياً بشكل أكثر موثوقية. وقد تحقق الباحثون من ذلك من خلال البحث باستخدام استراتيجية حجم النافذة.وجدنا أن 21 زوجًا قاعديًا يحقق الأداء الأمثل على مجموعة التحقق.أحد التفسيرات البيولوجية المحتملة هو أن دورة اللولب المزدوج النموذجية للحمض النووي تبلغ حوالي 10.5 زوجًا من القواعد لكل دورة، لذا فإن 21 زوجًا من القواعد تدور مرتين بالضبط. هذا يعني أن قاعدتين تفصل بينهما مسافة 21 زوجًا من القواعد تقعان على نفس جانب اللولب في الفضاء ثلاثي الأبعاد، وتواجهان بيئات كيميائية حيوية متشابهة. قد يكون تحديد النطاق على هذا المستوى أكثر ملاءمة لمواءمة اتساق الطور لإشارات التسلسل المحلية.
تحسينات كبيرة في التقييم: معايير صغيرة، تغييرات كبيرة
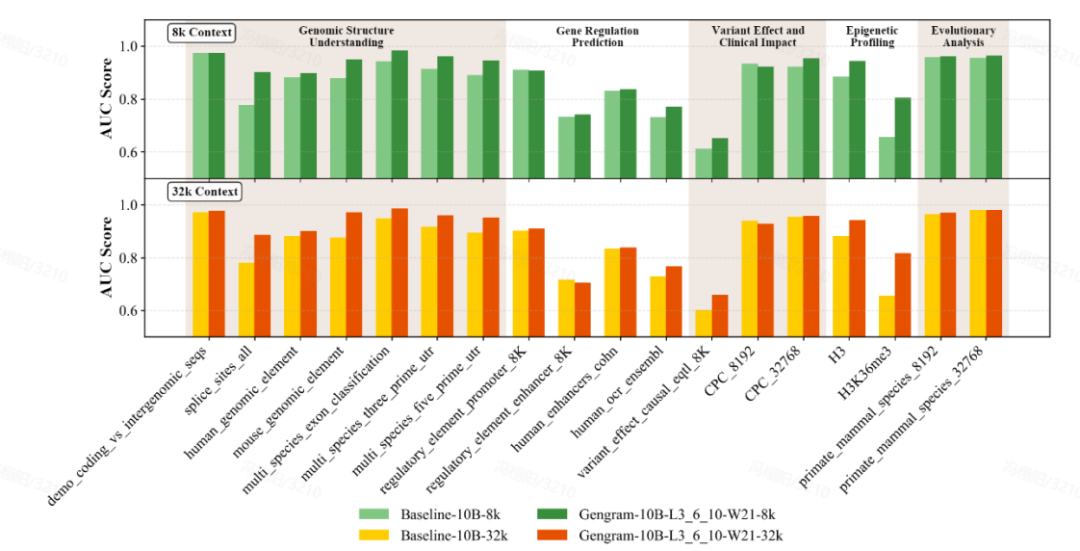
أجرى الفريق تقييمًا شاملاً للنموذج باستخدام مجموعات بيانات مرجعية متعددة المعايير، تغطي المعايير الجينومية (GB)، ومعايير محولات النيوكليوتيدات (NTB)، والمعايير طويلة المدى (LRB)، ومعايير جينوس (GeB).تم اختيار ثمانية عشر مجموعة بيانات تمثيلية، تغطي خمس فئات رئيسية من المهام:فهم البنية الجينومية، والتنبؤ بتنظيم الجينات، والتوصيف اللاجيني، وتأثير المتغيرات والتأثير السريري، والتحليل التطوري.
يمثل Gengram، وهو إضافة خفيفة الوزن تحتوي على حوالي 20 مليون مُعامل فقط، جزءًا ضئيلاً من مُعاملات النموذج الأساسي الذي يحتوي على مئات المليارات من المُعاملات، ومع ذلك يُحقق تحسينات كبيرة في الأداء. في ظل ظروف التدريب نفسها، مع أطوال سياق تبلغ 8 آلاف و32 ألف...تفوقت النماذج المدمجة مع Gengram على الإصدارات غير المدمجة في الغالبية العظمى من المهام.من حيث المظاهر المحددةتحسنت درجة AUC لمهمة التنبؤ بموقع الربط من 0.776 إلى 0.901، بزيادة قدرها 16.11 TP3T؛تحسنت درجة AUC لمهمة التنبؤ اللاجيني (H3K36me3) من 0.656 إلى 0.804، بزيادة قدرها 22.61 TP3T.
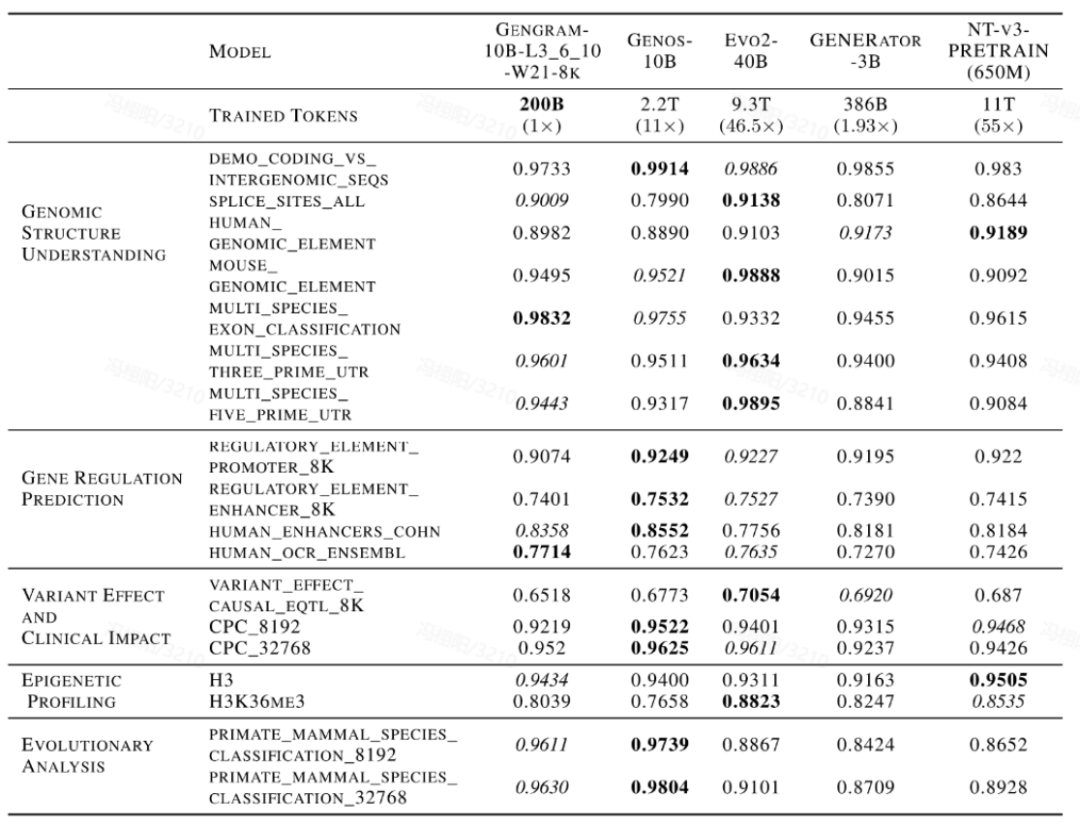
علاوة على ذلك، يترافق هذا التحسن في الأداء مع تأثير كبير لـ "الاستفادة من البيانات". في مقارنة أفقية مع النماذج السائدة القائمة على الحمض النووي مثل Evo2 وNTv3 وGENERATOR-3B،لا تتطلب النماذج التي تدمج Gengrams سوى كمية صغيرة جدًا من بيانات التدريب وعدد أقل من معلمات التنشيط لمنافسة النماذج المتاحة للجمهور والتي تحتوي على بيانات تدريب أكبر بعدة إلى عشرات المرات في المهام الأساسية.يُظهر ذلك كفاءة عالية في تدريب البيانات.
تحليل معمق لجينغرام
لماذا يمكن لـ Gengram تسريع التدريب؟
قدّم الفريق تباعد كولباك-لايبير كمقياس تشخيصي تمثيلي لعملية التدريب، واستخدم LogitLens-KL لتحديد وتتبع "جاهزية التنبؤ" للطبقات المختلفة. وأظهرت النتائج أن...من خلال إدخال مخططات الجينات، يمكن للنموذج تشكيل توزيع تنبؤ مستقر في وقت مبكر في الطبقات السطحية:بالمقارنة مع النموذج الأساسي، تنخفض قيم KL بين الطبقات بشكل أسرع وتدخل نطاق القيم المنخفضة في وقت مبكر، مما يشير إلى أن إشارات الإشراف الفعالة يتم تنظيمها في تمثيلات قابلة للاستخدام في وقت مبكر، مما يجعل تحديثات التدرج أكثر مباشرة ومسارات التحسين أكثر سلاسة، مما يؤدي في النهاية إلى سرعة تقارب أسرع وكفاءة تدريب أعلى.
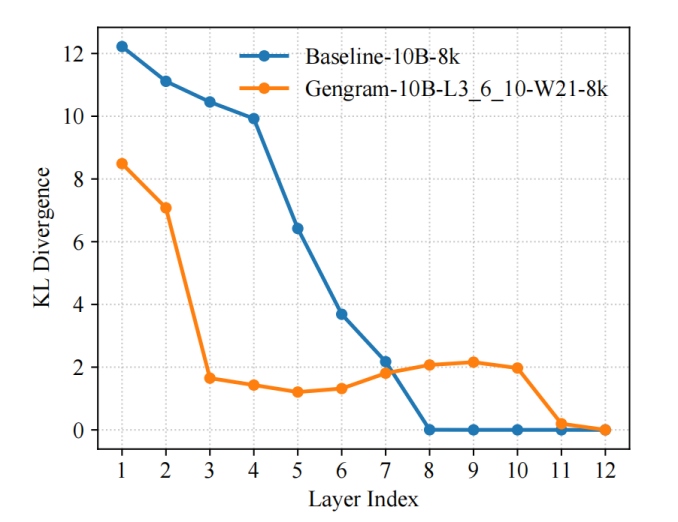
لم تحدث هذه الظاهرة من فراغ، بل كانت مدفوعة مباشرة بالتصميم الهيكلي لشركة جينجرام:
يُسهّل استرجاع الذاكرة الصريح للزخارف الانتقال من الدليل إلى التمثيل. في المهام الجينومية، غالبًا ما تُفعّل الإشارات الإشرافية بواسطة زخارف قصيرة ومتفرقة (مثل تسلسلات التوافق الموصولة، والقطع المرتبطة بالمحفزات، والمقاطع منخفضة التعقيد، وما إلى ذلك). تحتاج نماذج المحولات الأساسية إلى "استخلاص وتثبيت" هذه الأدلة المحلية تدريجيًا عبر طبقات متعددة من الانتباه/الشبكة العصبية متعددة الطبقات؛ بينما توفر نماذج Gengrams، من خلال الوصول الصريح إلى k-mers، هذه الأنماط المحلية عالية الكثافة المعلوماتية مباشرةً إلى الشبكة في شكل ذاكرة، بحيث لا يضطر النموذج إلى انتظار الطبقات العميقة لتشكيل كاشفات الزخارف تدريجيًا، ويكون أقرب إلى حالة قابلة للتنبؤ منذ البداية.
إن تجميع النوافذ والبوابات الديناميكية يجعلان الأدلة المحقونة "مستقرة وقابلة للتحكم". لا تقوم مخططات الجينات (Gengrams) بإجراء حقن صعب موضعًا تلو الآخر؛ بدلاً من ذلك، تقوم بتجميع تضمينات k-mer متعددة ضمن نافذة ثابتة.علاوة على ذلك، تُستخدم الكتابة الانتقائية المُتحكَّم بها في التدفق المتبقي: حيث يُرجَّح تنشيط الاسترجاع في المناطق الوظيفية وتثبيطه في مناطق الخلفية الكبيرة. تُقلِّل طريقة الكتابة هذه، التي تُعرف باسم "العناصر الوظيفية المتراصة والمُحاذية"، من تداخل الضوضاء من جهة، وتُمكِّن الشبكة من الحصول على إشارات تدريب عالية نسبة الإشارة إلى الضوضاء في وقت مبكر، مما يُقلِّل من صعوبة التحسين.
من أين تأتي ذكريات الموتيف؟ شرح مفصل لآلية كتابة جينجرام.
لاحظ فريق البحث أولاً ظاهرة واضحة ومتسقة عبر المهام في التقييمات اللاحقة:في ظل نفس إعدادات التدريب، أدى إدخال نماذج Gengrams إلى تحسين النموذج بشكل ملحوظ في المهام النموذجية القائمة على الأنماط، لا سيما في السيناريوهات التي تعتمد على تسلسلات برمجية قصيرة، مثل تحديد مواقع الربط والتنبؤ بمواقع تعديل الهيستون اللاجيني. على سبيل المثال، في المهام التمثيلية، ارتفع مؤشر AUC للتنبؤ بمواقع الربط من 0.776 إلى 0.901، وارتفع مؤشر AUC للتنبؤ بـ H3K36me3 من 0.656 إلى 0.804، مما يُظهر مكاسب مستقرة وكبيرة.
وللإجابة بشكل أكبر على السؤال "من أين تأتي هذه التحسينات؟"، لم يتوقف الفريق عند مستوى المقياس، بل استخرج عمليات الكتابة المتبقية من Gengram من الانتشار الأمامي للنموذج وعرض توزيع شدتها في بُعد التسلسل كخريطة حرارية للتحليل.تظهر النتائج أن الإشارة المكتوبة تُظهر بنية متفرقة للغاية وعالية التباين: معظم المواقع قريبة من خط الأساس، وعدد قليل فقط من المواقع تشكل قممًا حادة؛والأهم من ذلك، أن هذه القمم ليست عشوائية، ولكنها غنية بشكل كبير ومتوافقة مع المناطق والحدود ذات الصلة الوظيفية، بما في ذلك أجزاء صندوق TATA بالقرب من المحفزات، وأجزاء poly-T منخفضة التعقيد، والمواقع الرئيسية بالقرب من حدود المناطق الوظيفية مثل الجينات/الإكسونات.وهذا يعني أن الكتابة إلى مخطط جينغرام أشبه بـ "فهم الأدلة المحلية على وظيفته الحاسمة" بدلاً من إدخال المعلومات بشكل عشوائي عبر التسلسل بأكمله.
استناداً إلى الظواهر المذكورة أعلاه وسلسلة الأدلة،يمكن للباحثين تلخيص آلية ذاكرة الزخارف في Gengram على النحو التالي: "الاسترجاع عند الطلب - الكتابة الانتقائية - المحاذاة المنظمة":تتحكم الوحدة في كثافة الاسترجاع والكتابة من خلال التحكم في تدفق البيانات، حيث تُدخل بشكل أكثر فعالية أدلة الأنماط القابلة لإعادة الاستخدام في المناطق ذات الكثافة المعلوماتية الوظيفية الأعلى، وتُثبط الكتابة في المناطق الخلفية لتقليل التشويش. ونتيجة لذلك، لم يعد إتقان النموذج للأنماط يعتمد بشكل أساسي على "الذاكرة الضمنية" التي توفرها البيانات واسعة النطاق، بل يتحول إلى قدرة منظمة على الوصول الصريح إلى التمثيلات وكتابتها بشكل قابل للتفسير.

خاتمة
في السنوات الأخيرة، شهد مجال نمذجة الجينوم تحولاً رئيسياً من "التعلم الإحصائي للتسلسل" إلى "النمذجة الواعية بالبنية".
تكشف آليات ذاكرة الزخارف الشرطية، التي يمثلها Gengram، عن مسار تقني يختلف عن الحوسبة المكثفة التقليدية: من خلال نمذجة الزخارف الوظيفية متعددة القواعد بشكل صريح على أنها ذكريات منظمة قابلة للاسترجاع، يمكن للنموذج تحقيق استخدام أكثر كفاءة واستقرارًا للمعلومات الوظيفية مع الحفاظ على التوافق المعماري العام.لم يُظهر هذا النهج مزايا أداء كبيرة في مهام علم الجينوم الوظيفي المتعددة فحسب، بل قدم أيضًا حلاً هندسيًا موحدًا للحسابات المتفرقة، ونمذجة التسلسل الطويل، وقابلية تفسير النموذج.
علاوة على ذلك، من منظور صناعي، يُقلل نموذج "المعلومات المسبقة المنظمة + التحسين المعياري" الذي يجسده برنامج Gengram بشكل كبير من التكاليف الحدية لنماذج الجينوم واسعة النطاق من حيث قوة الحوسبة والبيانات ودورات التدريب، مما يجعل نشره على نطاق واسع في سيناريوهات عالية القيمة مثل تطوير الأدوية، وفحص المتغيرات، وتحليل تنظيم الجينات أمرًا عمليًا. وبالنظر إلى المستقبل، قد تصبح هذه المكونات المعمارية القابلة لإعادة الاستخدام والتوصيل هي التكوين القياسي لنماذج الجينوم الأساسية من الجيل التالي، مما يدفع الصناعة من "النماذج الأكبر" إلى "النماذج الأكثر ذكاءً" ويسرع التحول المستمر لنتائج البحوث الأكاديمية إلى منصات صناعية وتطبيقات سريرية.








