Command Palette
Search for a command to run...
تغطي شركة Polymathic AI 19 سيناريو بما في ذلك الفيزياء الفلكية وعلوم الأرض وعلم الريولوجيا وعلم الصوتيات، وتقوم بإنشاء 1.3 مليار نموذج لتحقيق محاكاة دقيقة للوسط المستمر.
في مجالي الحوسبة العلمية ومحاكاة الهندسة، لطالما شكلت كيفية التنبؤ بكفاءة ودقة بتطور الأنظمة الفيزيائية المعقدة تحديًا أساسيًا للأوساط الأكاديمية والصناعية على حد سواء. ورغم أن الطرق العددية التقليدية قادرة نظريًا على حل معظم المعادلات الفيزيائية، إلا أنها مكلفة حسابيًا عند التعامل مع سيناريوهات متعددة الأبعاد أو ذات خصائص فيزيائية متعددة، أو مع شروط حدودية غير منتظمة، كما أنها تفتقر إلى القدرة على التكيف مع تعدد المهام على نطاق واسع.في الوقت نفسه، دفعت الإنجازات في مجال التعلم العميق في معالجة اللغة الطبيعية ورؤية الكمبيوتر الباحثين إلى استكشاف إمكانية تطبيق "النماذج الأساسية" في عمليات المحاكاة الفيزيائية.
مع ذلك، غالباً ما تتطور الأنظمة الفيزيائية عبر نطاقات زمنية ومكانية متعددة، بينما تُدرَّب معظم نماذج التعلم عادةً على ديناميكيات قصيرة المدى فقط. وعند استخدامها للتنبؤات طويلة المدى، تتراكم الأخطاء في الأنظمة المعقدة، مما يؤدي إلى عدم استقرار النموذج.علاوة على ذلك، فإن اختلاف المقاييس وتجانس الأنظمة يعني أن المهام اللاحقة تتطلب دقة نمذجة متفاوتة، وأبعادًا مختلفة، وأنواعًا مختلفة من الحقول الفيزيائية، مما يشكل تحديًا كبيرًا لبنى التدريب الحديثة التي تفضل تنسيقات إدخال ثابتة. لذلك، لا تزال معظم النماذج الأساسية المستخدمة في المحاكاة حتى الآن محدودة بسيناريوهات بيانات متجانسة نسبيًا، مثل معالجة المشكلات ثنائية الأبعاد فقط بدلًا من المواقف ثلاثية الأبعاد الأكثر واقعية.
في هذا السياق، قدم فريق بحثي من Polymathic AI Collaboration سلسلة من الأساليب الجديدة لمعالجة التحديات المذكورة أعلاه، بما في ذلك: تذبذب الرقع، واستراتيجيات التدريب الموزعة المتوازنة الأحمال لسيناريوهات ثنائية وثلاثية الأبعاد، وآليات التجزئة التكيفية للحوسبة.وبناءً على ذلك، اقترح فريق البحث نموذجًا أساسيًا يسمى Walrus، والذي يحتوي على 1.3 مليار معلمة، ويستخدم Transformer كهيكل أساسي له، وهو موجه بشكل أساسي نحو ديناميكيات الاستمرارية الشبيهة بالسوائل. يغطي نموذج Walrus تسعة عشر سيناريو فيزيائيًا شديد التنوع خلال مرحلة التدريب المسبق، تشمل مجالات متعددة منها الفيزياء الفلكية، وعلوم الأرض، وعلم الريولوجيا، وفيزياء البلازما، وعلم الصوتيات، وديناميكا الموائع الكلاسيكية. تُظهر النتائج التجريبية أن Walrus يتفوق على النماذج الأساسية السابقة في كلٍ من التنبؤات قصيرة المدى وطويلة المدى للمهام اللاحقة، ويُظهر أداءً أقوى في التعميم عبر توزيع بيانات التدريب المسبق بالكامل.
تم نشر نتائج البحث ذات الصلة، بعنوان "Walrus: نموذج أساسي متعدد المجالات لديناميكيات الاستمرارية"، كنسخة أولية على arXiv.
أبرز الأبحاث:
يتميز برنامج Walrus بحجم معلمات نموذج يبلغ 1.3 مليار، وتقنيات تثبيت مبتكرة، والقدرة على تكييف الحساب مع تعقيد المشكلة؛
* يعالج العديد من القيود التي تعتري النماذج الأساسية الحالية لديناميكيات الاستمرارية، مثل التكيف مع التكلفة والاستقرار والتدريب الفعال على بيانات التدريب غير المتجانسة للغاية بدقة أصلية؛
* يعتبر Walrus النموذج الأساسي الأكثر دقة لمحاكاة الاستمرارية حتى الآن، حيث حقق نتائج متطورة في 56 من أصل 65 مقياسًا تم تتبعها عبر 26 مهمة محاكاة استمرارية فريدة من نوعها من مجالات علمية متعددة وعبر أطر زمنية متعددة.

عنوان الورقة:https://arxiv.org/abs/2511.15684
تابع حسابنا الرسمي على WeChat وأجب بكلمة "محاكاة الوسائط" في الخلفية للحصول على ملف PDF كامل.
مزيد من أوراق البحث الرائدة في مجال الذكاء الاصطناعي:
https://hyper.ai/papers
بناء مجموعات بيانات غير متجانسة ومتعددة الأبعاد وعالية الجودة
يرتبط نجاح برنامج Walrus ارتباطًا وثيقًا بتنوع البيانات وجودتها العالية. استخدم فريق البحث مجموعة بيانات هجينة من Well وFlowBench للتدريب المسبق. توفر مجموعة بيانات Well كمية كبيرة من البيانات عالية الدقة المستمدة من مشكلات علمية حقيقية، بينما تُدخل FlowBench عوائق ذات أشكال هندسية معقدة في سيناريوهات السوائل القياسية، مما يتيح للنموذج فرصًا لتعلم أنماط التدفق المعقدة.
استخدم فريق البحث ما مجموعه 19 مجموعة بيانات، تغطي 63 متغير حالة، بما في ذلك المعادلات المختلفة، والشروط الحدودية، وإعدادات المعلمات الفيزيائية.تشمل أبعاد البيانات بُعدين وثلاثة أبعاد لضمان قدرة النموذج على التعميم عبر مختلف الأبعاد المكانية. وللتحقق من قابلية نقل النموذج، قام فريق البحث بضبطه بدقة باستخدام جزء من مجموعات البيانات المحفوظة، بما في ذلك بيانات من Well وFlowBench وPDEBench وPDEArena وPDEGym، بعد التدريب المسبق. واتُبعت استراتيجيات التقسيم القياسية في تقسيم البيانات، أو قُسّمت بنسبة 80/10/10 للتدريب/التحقق/الاختبار بناءً على المسارات.
فيما يتعلق بإعدادات التدريب، خضع نموذج الفظ لحوالي 400,000 خطوة تدريب مسبق، مع حوالي 4 ملايين عينة في كل مجموعة بيانات ثنائية الأبعاد، وحوالي مليوني عينة في كل مجموعة بيانات ثلاثية الأبعاد. استُخدم مُحسِّن AdamW واستراتيجية جدولة معدل التعلّم لتحقيق تعلّم فعّال على بيانات متعددة المهام وعالية الأبعاد. كان مقياس التقييم الأساسي المُستخدم هو VRMSE (متوسط الجذر التربيعي للخطأ المعياري)، والذي يسمح بتقييم موحد عبر مجموعات البيانات والمهام.
تُمكّن بيانات التدريب والاستراتيجية المتنوعة للغاية هذه برنامج Walrus من التقاط خصائص فيزيائية غنية خلال مرحلة ما قبل التدريب ووضع الأساس للتعميم عبر المجالات للمهام اللاحقة.
بنية المحولات القائمة على التحليل المكاني الزمني
يستخدم نموذج الفظ بنية محول مُجزأة مكانيًا وزمنيًا. عند معالجة البيانات المهيكلة الموترية المكانية الزمنية، يُجري عمليات انتباه على طول كل من البُعدين المكاني والزمني لتحقيق نمذجة فعّالة. يوضح الشكل أدناه هذه العملية:
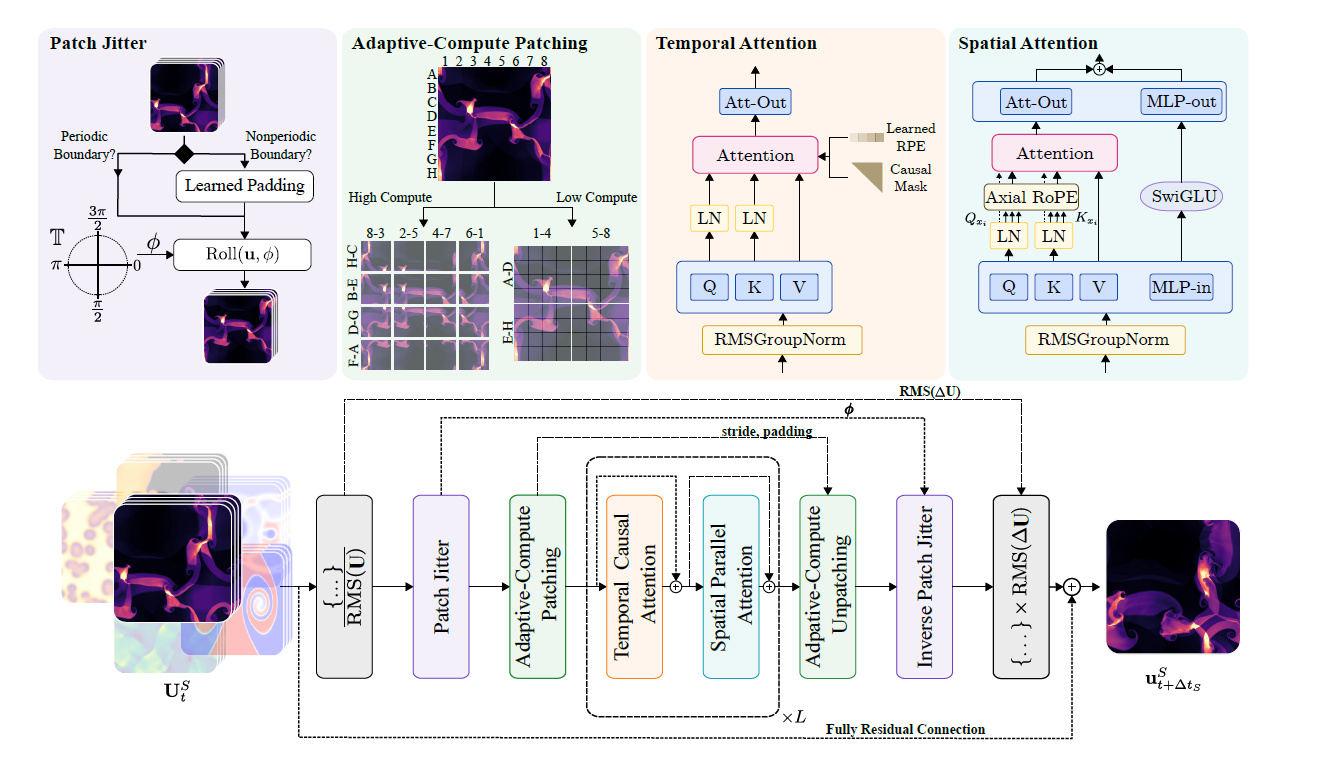
* معالجة المساحة:نستخدم الانتباه المتوازي الذي اقترحه وانغ ونجمعه مع Axial RoPE لترميز الموضع.
* معالجة الجدول الزمني:نستخدم آلية الانتباه السببي مع ترميز الموضع النسبي على نمط T5. ويتم تطبيق تسوية QK في كل من الوحدات المكانية والزمانية لتحسين استقرار التدريب.
* الضغط التكيفي الحسابي:في وحدتي التشفير وفك التشفير، تُستخدم تقنية تعديل الخطوة الالتفافية (CSM) لمعالجة البيانات بدقة مختلفة. ويتم تحقيق مرونة في التعامل مع الدقة من خلال ضبط مستويات تقليل/زيادة حجم العينة في كل وحدة من وحدات التشفير/فك التشفير. غالبًا ما كانت نماذج المحاكاة السابقة تستخدم مشفرات ضغط ثابتة، والتي لم تكن مرنة بما يكفي لتلبية متطلبات الدقة المتغيرة للمهام اللاحقة. تتيح تقنية CSM للباحثين ضبط خطوة الالتفاف لتقليل حجم العينة، وبالتالي اختيار مستوى ضغط مكاني يتناسب مع المهمة.
* وحدة التشفير وفك التشفير المشتركة:تشترك جميع الأنظمة الفيزيائية ذات الأبعاد المتشابهة في مُشفِّر ومُفكِّك واحد لتعلم الخصائص المشتركة. تتوافق البيانات ثنائية الأبعاد وثلاثية الأبعاد مع مُشفِّرين ومُفكِّكين على التوالي، ويتم تشفيرها وفك تشفيرها باستخدام شبكة عصبية متعددة الطبقات هرمية خفيفة الوزن (hMLP).
* RMS GroupNorm وتطبيع المدخلات/المخرجات غير المتماثل:تُستخدم تقنية RMSGroupNorm للتطبيع داخل كل وحدة من وحدات Transformer لتحسين استقرار التدريب. ويُستخدم التطبيع غير المتماثل للتنبؤات التزايدية للمدخلات والمخرجات لضمان الاستقرار العددي عبر مختلف السيناريوهات.
* تذبذب الرقعة:من خلال تغيير بيانات الإدخال بشكل عشوائي ثم معالجتها بشكل عكسي عند الإخراج، يتم تقليل تراكم القطع الأثرية عالية التردد، مما يؤدي إلى تحسين استقرار التنبؤ على المدى الطويل بشكل كبير، خاصة في بنى نمط ViT.
* تدريب عالي الكفاءة على مهام متعددة:تُستخدم تقنيات أخذ العينات الهرمية ودالة الخسارة المعيارية لضمان عدم هيمنة التنبؤات الخاصة بالحقول سريعة التغير على التنبؤات الخاصة بالحقول بطيئة التغير. وفي الوقت نفسه، تُدمج استراتيجيات المعالجة الجزئية والتجزئة التكيفية لحل مشكلة عدم انتظام الحمل في تدريب البيانات غير المتجانسة عالية الأبعاد.
* تمثيل موحد للتمثيلات ثنائية الأبعاد وثلاثية الأبعاد:من خلال إضافة بُعد واحد إلى البيانات ثنائية الأبعاد وملؤها بالأصفار، وتضمينها في فضاء ثلاثي الأبعاد، ثم استخدام تحسين التناظر (الدوران، الانعكاس) للتضخيم المتنوع، يتم تحقيق القدرة على التدريب متعدد الأبعاد.
بشكل عام، لا تقوم بنية Walrus بمعالجة بيانات الموتر بكفاءة في كل من الأبعاد المكانية والزمانية فحسب، بل تعالج أيضًا تحديات سيناريوهات المهام المتعددة والسيناريوهات الفيزيائية المتعددة من خلال استراتيجيات متنوعة وتدريب موزع فعال.
يُظهر برنامج Walrus مزايا كبيرة في العديد من المهام اللاحقة ثنائية وثلاثية الأبعاد.
وللتحقق من أداء نموذج Walrus كنموذج أساسي وأدائه في المهام اللاحقة، صمم الباحثون سلسلة من التجارب:
① أداء المهام اللاحقة
بالمقارنة مع النماذج الأساسية الحالية مثل MPP-AViT-L و Poseidon-L و DPOT-H، فإن Walrus يقلل متوسط VRMSE بحوالي 63.61 TP3T في التنبؤ بخطوة واحدة، و 56.21 TP3T في التنبؤ بالمسار قصير المدى، و 48.31 TP3T في التنبؤ بالمسار متوسط المدى، كما هو موضح في الشكل أدناه:
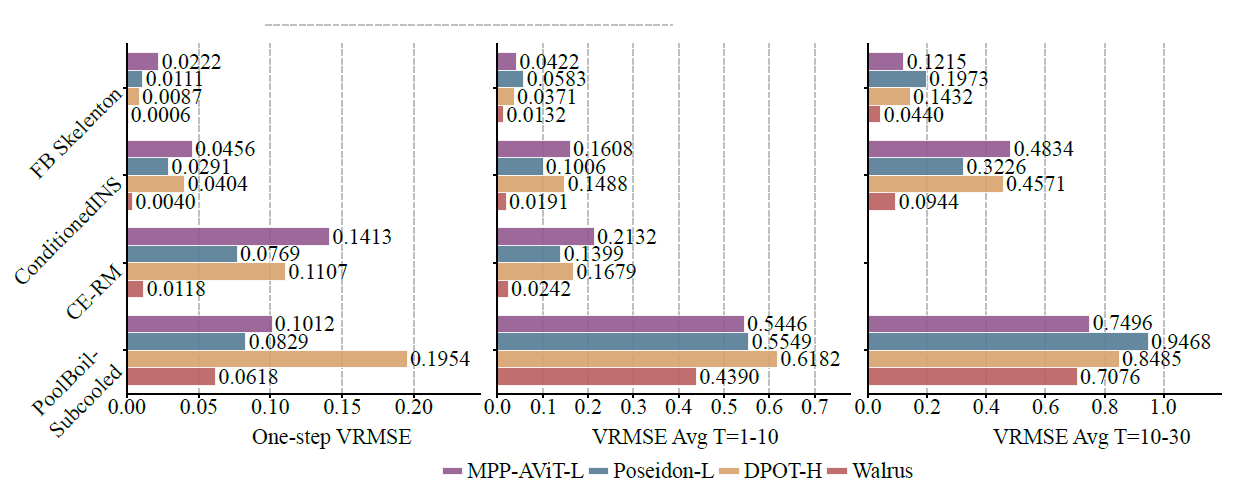
في الأنظمة غير الفوضوية، يؤدي انخفاض توليد القطع الأثرية الناتج عن تذبذب الرقعة إلى استقرار أداء التنبؤ طويل المدى للنموذج؛ في الأنظمة الأكثر عشوائية (مثل Pool-BoilSubcool في BubbleML)، على الرغم من أن Walrus يتقدم في البداية، إلا أن ميزة التنبؤ المتداول طويل المدى تضعف لأن المعلومات التاريخية قصيرة المدى لا يمكنها أن تعكس بشكل كامل خصائص المواد والمواقد.
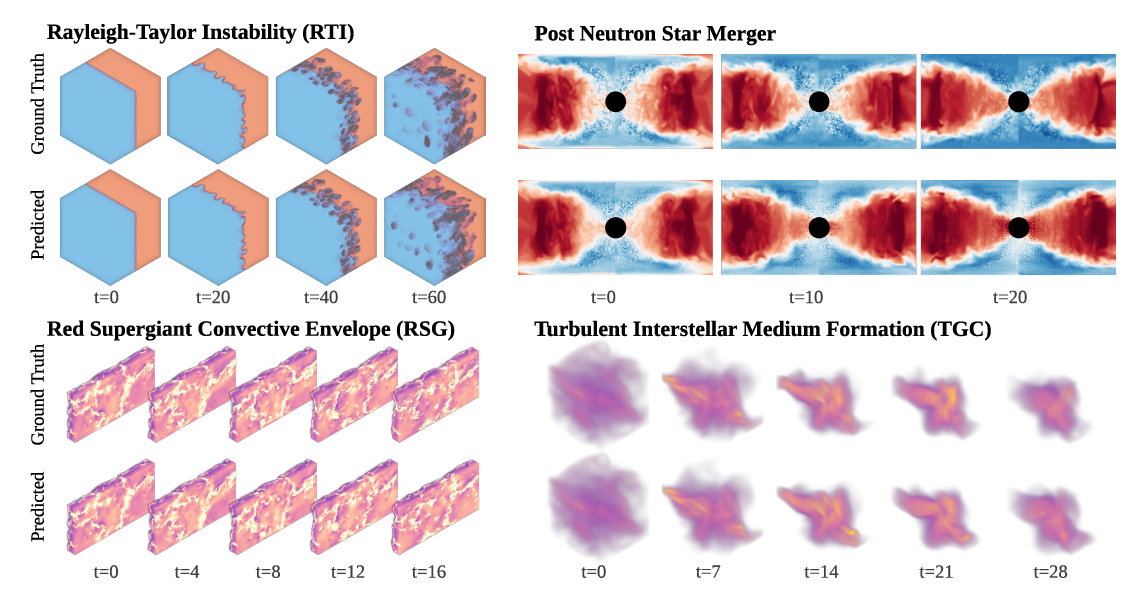
تُعدّ المهام ثلاثية الأبعاد ذات أهمية خاصة لأن معظم عمليات محاكاة الفيزياء في العالم الحقيقي هي أنظمة ثلاثية الأبعاد. يُظهر برنامج Walrus أداءً استثنائيًا على مجموعتي بيانات PNS (ما بعد اندماج النجوم النيوترونية) وRSG (الغلاف الجوي للعمالقة الحمراء)، على الرغم من أن توليد هاتين المجموعتين من البيانات يتطلب ملايين الساعات من موارد المعالجات، كما هو موضح في الشكل أدناه:
② القدرات عبر المجالات
تم أيضًا التحقق من قدرات Walrus متعددة المجالات؛ بالمقارنة مع خط الأساس الأمثل، قلل Walrus متوسط الخسارة بمقدار 52.21 TP3T في التنبؤ بخطوة واحدة.بعد إجراء عملية ضبط دقيقة على 19 مجموعة بيانات مدربة مسبقًا، حقق Walrus أقل خسارة في خطوة واحدة في 18/19 مهمة، ومتوسط مزايا قدره 30.5% و 6.3% في التنبؤات المتداولة متوسطة المدى عند 20 و 20-60 خطوة على التوالي، كما هو موضح في الجدول أدناه:
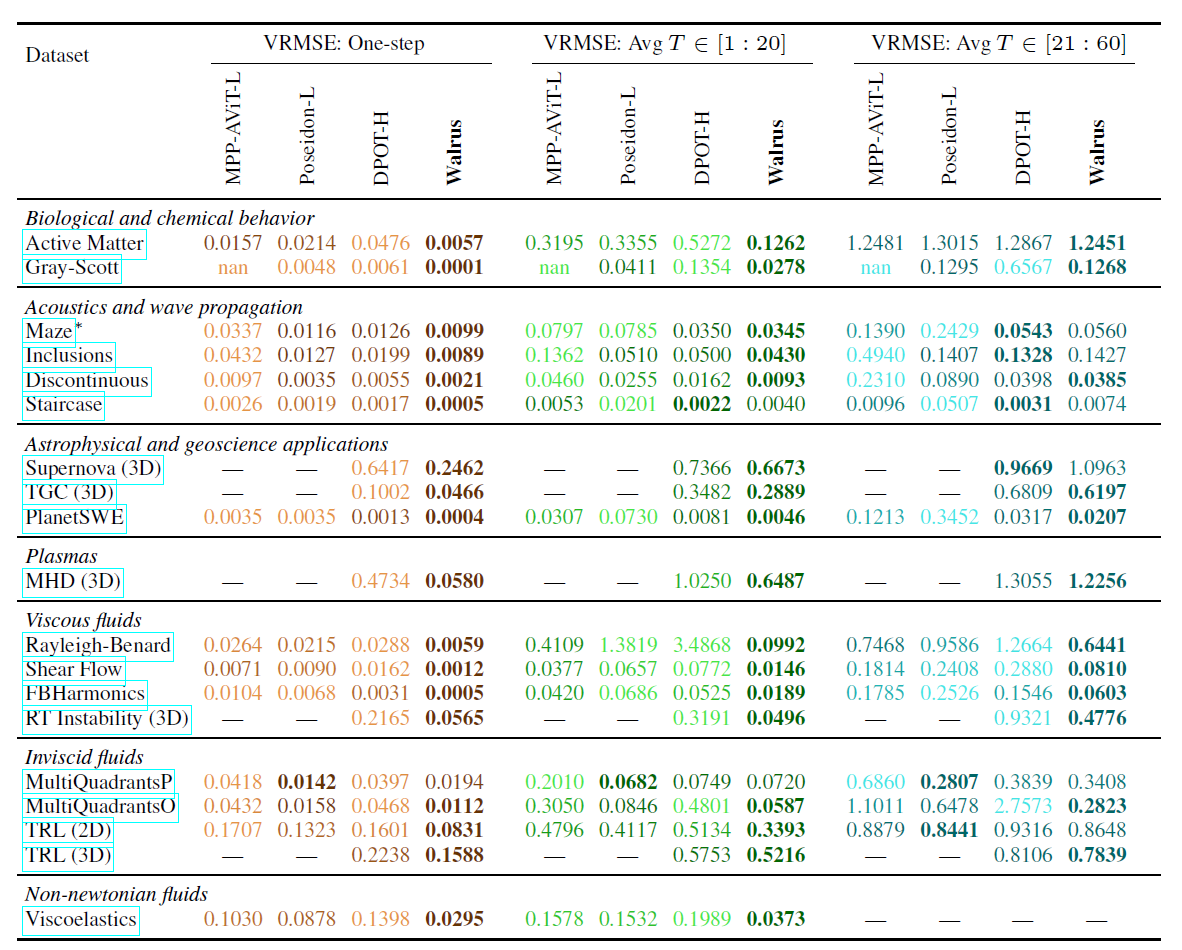
بالمقارنة، يُظهر نموذج DPOT أداءً قريبًا من نموذج Walrus في مهام انتشار الموجات الصوتية والخطية، بينما يتفوق نموذج Poseidon في مهام التدفق غير اللزج. مع ذلك، يحقق نموذج Walrus نتائج تنافسية أو حتى أفضل في معظم المهام بفضل التدريب المسبق المكثف وبنية عامة.
3- تأثير استراتيجيات ما قبل التدريب
تُظهر تجارب الاستئصال أن استراتيجيات التدريب المسبق المتنوعة لنموذج والروس تُعدّ أساسيةً للأداء اللاحق. حتى مع النموذج نصف الحجم (نصف والروس) الذي يستخدم بيانات ثنائية الأبعاد فقط، فإن استراتيجية التدريب المسبق مع التحسينات المكانية والزمانية الشاملة تتفوق بشكل ملحوظ على النماذج المدربة من الصفر أو باستخدام استراتيجيات تدريب مسبق ثنائية الأبعاد بسيطة في مهام جديدة تمامًا لم يسبق رؤيتها.
في مهام الشبكة العصبية المركزية ثلاثية الأبعاد، يحقق نموذج HalfWalrus تحسناً طفيفاً حتى مع كمية بيانات ضئيلة جداً، بل وحتى بدون رؤية بيانات ثلاثية الأبعاد مسبقاً. أما نموذج Walrus الكامل، من خلال التدريب المسبق باستخدام بيانات ثلاثية الأبعاد، فقد حقق ميزة كبيرة، مما يُبرز أهمية البيانات متعددة الأبعاد والمتنوعة.
تعمل تقنية الذكاء الاصطناعي متعددة التخصصات على تسريع تنفيذ تطبيقات الذكاء الاصطناعي متعددة التخصصات.
في مجالي الحوسبة العلمية والنمذجة الهندسية، يُحدث استخدام النماذج الأساسية نقلة نوعية جديدة. يُعد مشروع Polymathic AI مشروعًا بحثيًا مفتوح المصدر جديرًا بالاهتمام، ويهدف بشكل أساسي إلى بناء نماذج أساسية عامة الأغراض للبيانات العلمية لتسريع تطبيق تطبيقات الذكاء الاصطناعي متعددة التخصصات.
بخلاف النماذج الكبيرة ذات الأغراض العامة للغة الطبيعية أو مهام الرؤية، يركز الذكاء الاصطناعي متعدد التخصصات على مشاكل الحوسبة العلمية النموذجية مثل الأنظمة الديناميكية المستمرة، ومحاكاة المجال الفيزيائي، ونمذجة النظام الهندسي.تتمثل فكرتها الأساسية في تدريب نموذج موحد من خلال بيانات واسعة النطاق ومتعددة الفيزياء ومتعددة المقاييس، مما يتيح لها امتلاك قدرات نقل عبر المجالات، وبالتالي تقليل تكلفة بناء نموذج من الصفر لكل مشكلة علمية - وتعتبر "قدرة التعميم عبر المجالات" هذه بمثابة اختراق رئيسي في الذكاء الاصطناعي العلمي.
يُقال إن شركة Polymathic AI تجمع فريقًا من الباحثين المتخصصين في التعلم الآلي وعلماء المجال، وتتلقى التوجيه من مجموعة استشارية علمية تضم نخبة من الخبراء العالميين، ويشرف عليها يان ليكان، الحائز على جائزة تورينج وكبير علماء شركة Meta. كما تحظى بدعم من العديد من الشخصيات الأكاديمية البارزة، من بينهم مايلز كرانمر، الأستاذ المساعد في الذكاء الاصطناعي وعلم الفلك/الفيزياء بجامعة كامبريدج، بهدف التركيز على تطوير نماذج أساسية للبيانات العلمية واستخدام مفاهيم مشتركة متعددة التخصصات لحل تحديات الصناعة في مجال الذكاء الاصطناعي للعلوم.
في عام 2025، عرض أعضاء فريق التعاون متعدد التخصصات في الذكاء الاصطناعي نموذجين جديدين للذكاء الاصطناعي، تم تدريبهما على مجموعات بيانات علمية واقعية، ومصممان لمعالجة مشكلات في علم الفلك والأنظمة الشبيهة بالسوائل. أحدهما هو "والروس" (Walrus)، الذي ذُكر سابقًا، والآخر هو "أيون-1" (AION-1)، وهو أول نموذج أساسي متعدد الوسائط واسع النطاق لعلم الفلك. يدمج "أيون-1" معلومات رصدية غير متجانسة، مثل الصور والأطياف وبيانات فهرس النجوم، ويُنمذجها من خلال شبكة أساسية موحدة للدمج المبكر. لا يقتصر أداؤه على كونه استثنائيًا في سيناريوهات التدريب الصفري، بل يتميز أيضًا بدقة كشف خطية تُضاهي النماذج المُخصصة لمهام محددة، مما يُظهر أداءً فائقًا عبر نطاق واسع من المهام العلمية. حتى مع الكشف الأمامي البسيط، يصل أداؤه إلى مستويات متقدمة، ويتفوق بشكل ملحوظ على النماذج الأساسية الخاضعة للإشراف في سيناريوهات البيانات المحدودة.
عنوان الورقة:AION-1: نموذج أساسي متعدد الوسائط للعلوم الفلكية
عنوان الورقة:https://arxiv.org/abs/2510.17960
بشكل عام، يمثل الذكاء الاصطناعي متعدد التخصصات استكشافًا متطورًا للنموذج التكنولوجي الناشئ لـ "النماذج الأساسية للذكاء الاصطناعي العلمي". تكمن أهميته على المدى الطويل ليس فقط في تحسين الأداء، ولكن أيضًا في بناء أساس حاسوبي عام لنقل المعرفة متعددة التخصصات، مما يمهد الطريق لانتقال "الذكاء الاصطناعي من أجل العلوم" من تطبيقات مستوى الأدوات إلى قدرات مستوى البنية التحتية.
مراجع:
1.https://arxiv.org/abs/2511.15684
2.https://www.thepaper.cn/newsDetail_forward_32173693
3.https://polymathic-ai.org
4.https://arxiv.org/abs/2510.17960
5.https://www.163.com/dy/article/KGMRMMQM055676SU.html








