Command Palette
Search for a command to run...
دورة تعليمية عبر الإنترنت | فريق الذكاء الاصطناعي في WeChat يقترح WeDLM، وهو نموذج لغة انتشاري يحقق سرعة استدلال أسرع بثلاث مرات لنشر نموذج الواقع المعزز مقارنةً بـ vLLM

في عمليات النشر واسعة النطاق والتطبيقات التجارية، تزداد أهمية سرعة الاستدلال، حتى أنها تتجاوز في كثير من الحالات عدد معلمات النموذج، لتصبح عاملاً رئيسياً في تحديد قيمته الهندسية. وعلى الرغم من أن نموذج توليد الانحدار الذاتي (AR) لا يزال الطريقة السائدة لفك التشفير نظراً لاستقراره ونضج نظامه البيئي،ومع ذلك، فإن آلية توليد الرموز المتأصلة فيها تجعل من المستحيل تقريبًا على النموذج الاستفادة الكاملة من موارد الحوسبة المتوازية أثناء مرحلة الاستدلال.يبرز هذا القيد بشكل خاص في السيناريوهات التي تتضمن توليد نصوص طويلة، واستدلال معقد، وخدمات عالية التزامن، وهو يزيد بشكل مباشر من زمن استجابة الاستدلال وتكاليف الحوسبة.
وللتغلب على هذه العقبة، ظل مجتمع البحث يستكشف باستمرار مسارات فك التشفير المتوازية في السنوات الأخيرة.ومن بينها، تعتبر نماذج لغة الانتشار (DLMs) واحدة من أكثر البدائل الواعدة نظرًا لخاصيتها المتمثلة في "توليد رموز متعددة في كل خطوة".مع ذلك، لا تزال هناك فجوة كبيرة بين الوضع المثالي والواقع: ففي بيئات النشر العملية، فشلت العديد من نماذج التعلم العميق الموزعة (DLLMs) في إظهار ميزة السرعة المتوقعة، بل وتكافح حتى للتفوق على محركات استدلال الواقع المعزز (AR) عالية الكفاءة (مثل نماذج التعلم العميق الموزعة vLLMs). لا تنبع المشكلة من التوازي بحد ذاته، بل من تعارض أعمق كامن في بنية النموذج وعلى مستوى النظام.تعتمد العديد من طرق الانتشار الحالية على آليات الانتباه ثنائية الاتجاه، مما يقوض حجر الزاوية في كفاءة أنظمة الاستدلال الحديثة - التخزين المؤقت للقيم الرئيسية - ويجبر النموذج على إعادة حساب السياق بشكل متكرر، وبالتالي ينفي الفوائد المحتملة للتوازي.
وفي هذا السياق،اقترح فريق الذكاء الاصطناعي في WeChat التابع لشركة Tencent نموذج WeDLM (نموذج لغة الانتشار في WeChat).يُعدّ هذا أول نموذج لغوي انتشاري يتفوق على نماذج الواقع المعزز المماثلة من حيث سرعة الاستدلال في ظل تحسين محرك الاستدلال الصناعي (vLLM). وتتمثل فكرته الأساسية في ربط كل موضع مُقنّع بجميع الرموز المميزة المرصودة حاليًا مع الحفاظ على إخفاء سببي دقيق. ولتحقيق هذه الغاية، قدّم الباحثون طريقة لإعادة الترتيب الطوبولوجي، حيث يتم نقل الرموز المميزة المرصودة إلى مناطق البادئات الفيزيائية دون تغيير مواقعها المنطقية.
تُظهر النتائج التجريبية أن WeDLM يحقق تسارعًا ملحوظًا في الاستدلال مع الحفاظ على جودة توليد البنية الأساسية القوية للانحدار الذاتي. فعلى وجه التحديد، يحقق WeDLM تسارعًا يزيد عن ثلاثة أضعاف مقارنةً بنماذج الانحدار الذاتي المُستخدمة بواسطة vLLM في مهام مثل الاستدلال الرياضي، كما أن كفاءة الاستدلال في سيناريوهات الإنتروبيا المنخفضة أسرع بأكثر من عشرة أضعاف.
يتوفر حاليًا "إطار عمل فك تشفير نماذج اللغة الكبيرة عالي الكفاءة WeDLM" في قسم "الدروس التعليمية" على موقع HyperAI الإلكتروني. يمكنك الاطلاع على الدروس التعليمية عبر الرابط أدناه ⬇️
دروس تعليمية عبر الإنترنت:
عنوان المصدر المفتوح:
https://github.com/tencent/WeDLM
ولتحسين تجربة الجميع للدروس التعليمية عبر الإنترنت، تقدم HyperAI أيضًا مزايا في قوة الحوسبة.يمكن للمستخدمين الجدد الحصول على ساعتين من وقت استخدام NVIDIA GeForce RTX 5090 باستخدام رمز الاسترداد "WeDLM" بعد التسجيل (المورد صالح لمدة شهر واحد).كميات محدودة متوفرة، احصل على منتجك الآن!
تشغيل تجريبي
1. بعد الدخول إلى الصفحة الرئيسية لموقع hyper.ai، حدد صفحة "الدروس التعليمية"، أو انقر فوق "عرض المزيد من الدروس التعليمية"، وحدد "إطار عمل فك تشفير نموذج اللغة الكبير عالي الكفاءة WeDLM"، وانقر فوق "تشغيل هذا البرنامج التعليمي عبر الإنترنت".
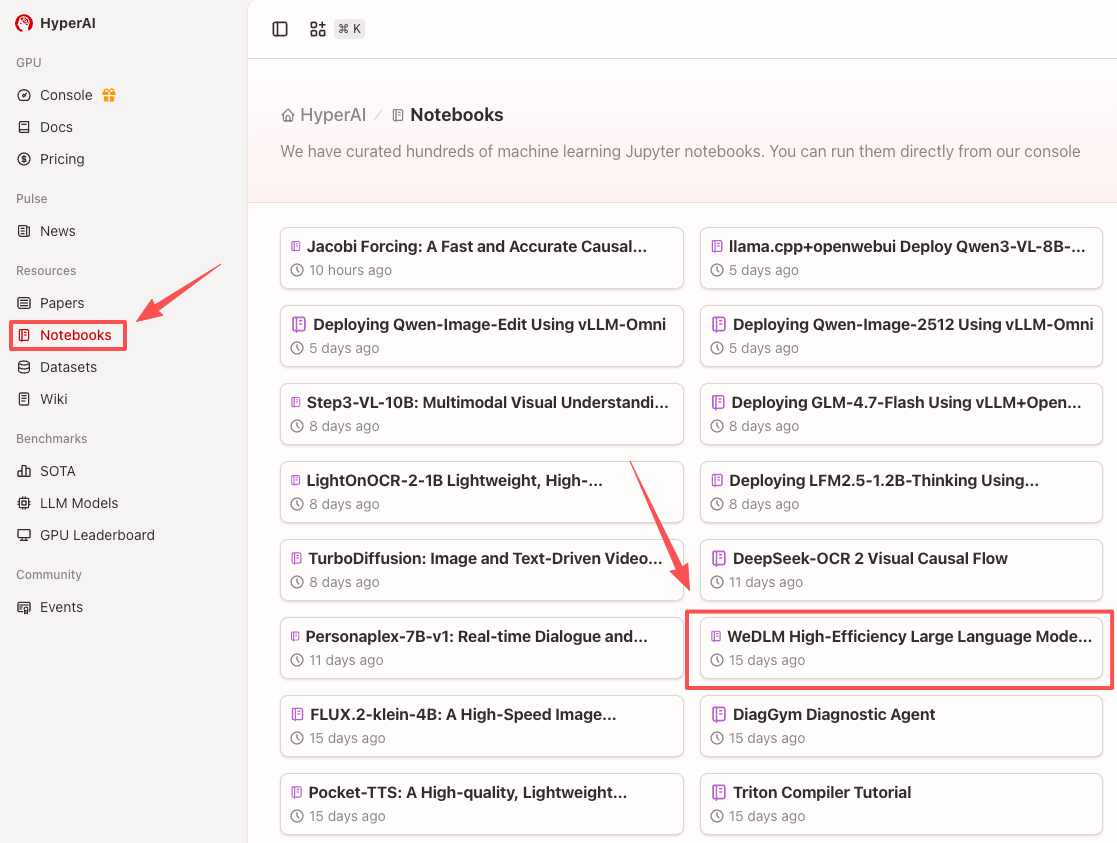
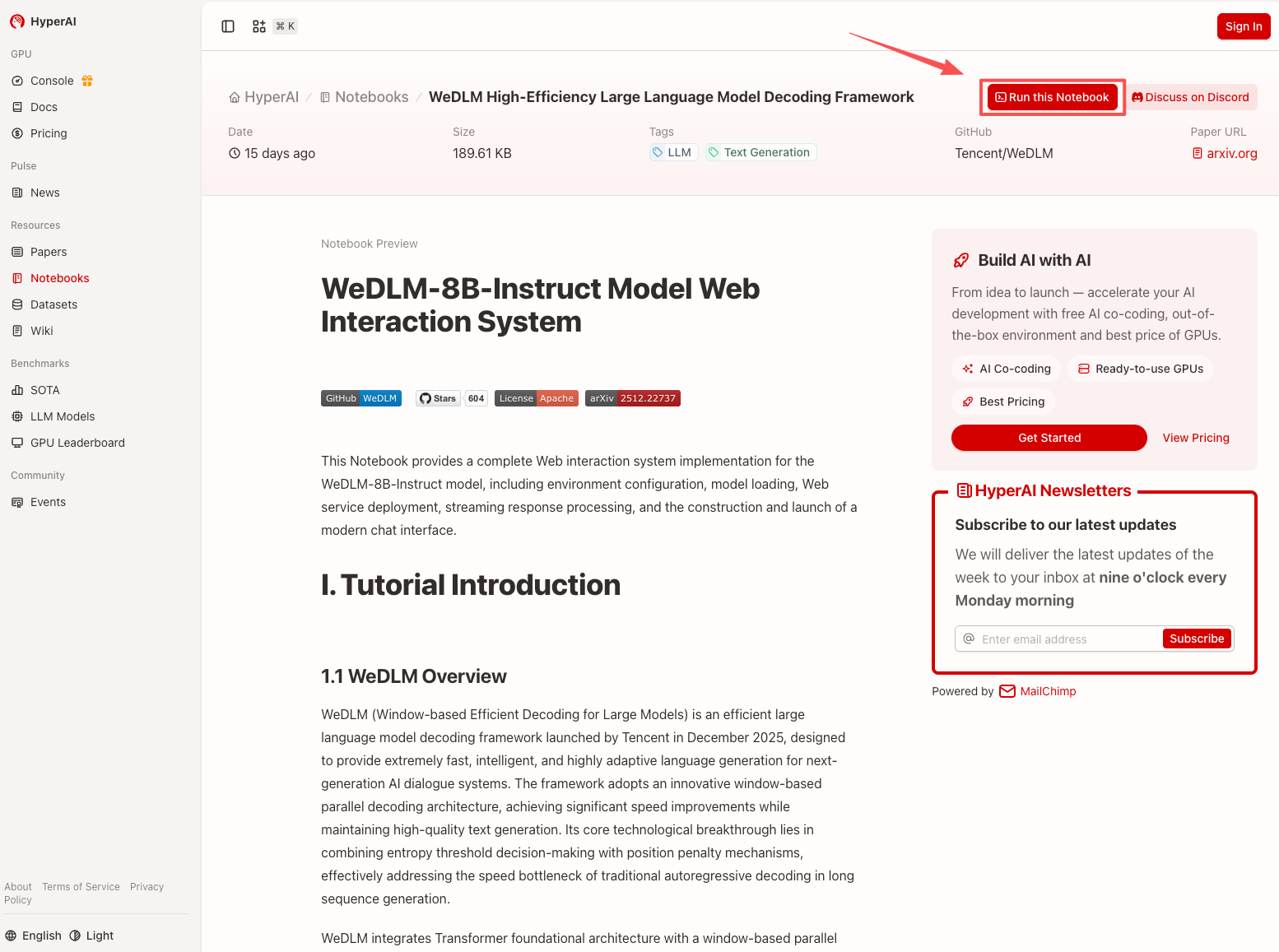
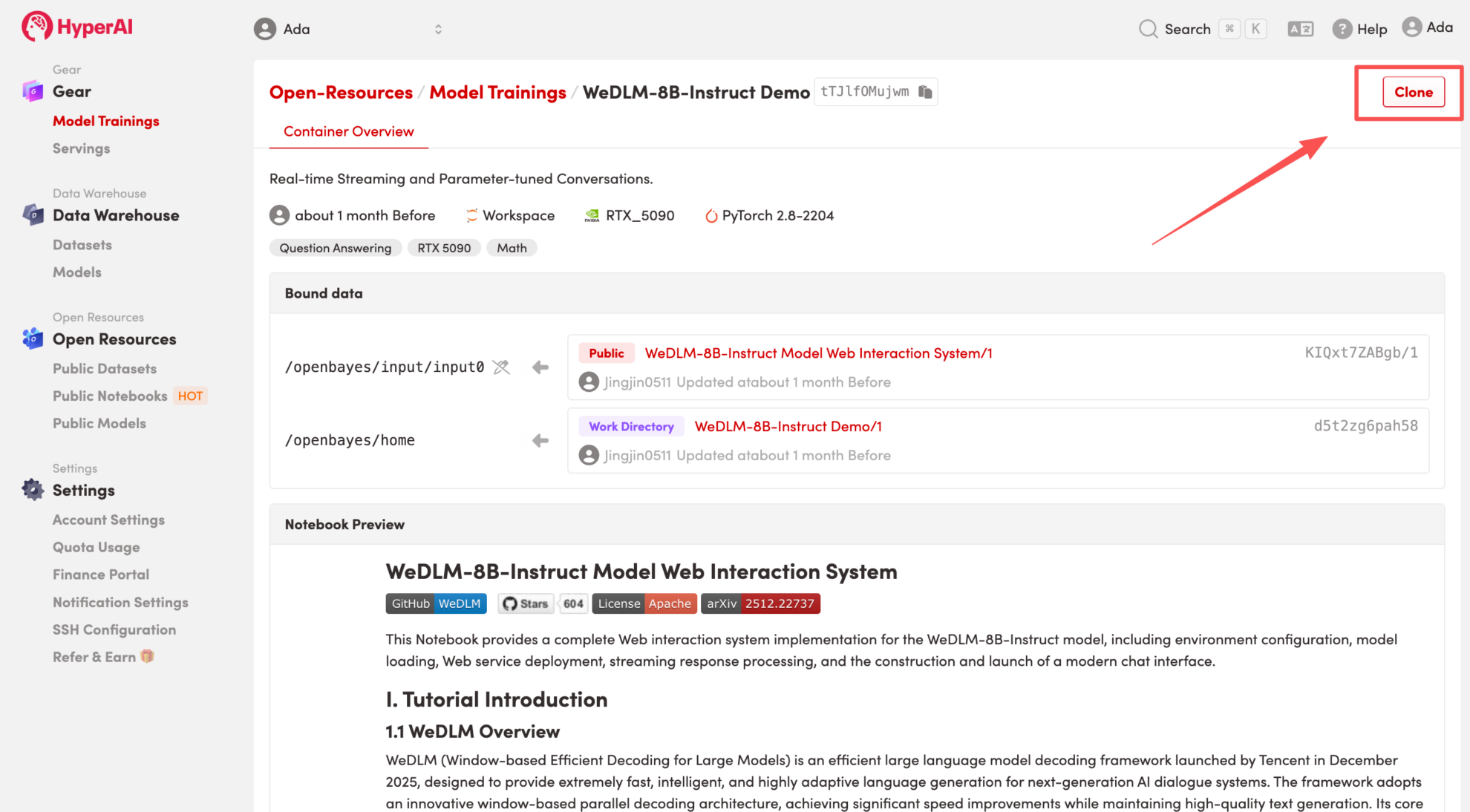
2. بعد إعادة توجيه الصفحة، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
ملاحظة: يمكنك تبديل اللغات في الزاوية العلوية اليمنى من الصفحة. حاليًا، اللغتان الصينية والإنجليزية متاحتان. سيوضح هذا البرنامج التعليمي الخطوات باللغة الإنجليزية.
3. حدد صور "NVIDIA GeForce RTX 5090" و "PyTorch"، واختر "الدفع حسب الاستخدام" أو "الخطة اليومية/الخطة الأسبوعية/الخطة الشهرية" حسب الحاجة، ثم انقر فوق "متابعة تنفيذ المهمة".
تقدم HyperAI فوائد التسجيل للمستخدمين الجدد.مقابل $1 فقط، يمكنك الحصول على 20 ساعة من قوة الحوسبة RTX 5090 (السعر الأصلي $7).المورد صالح بشكل دائم.
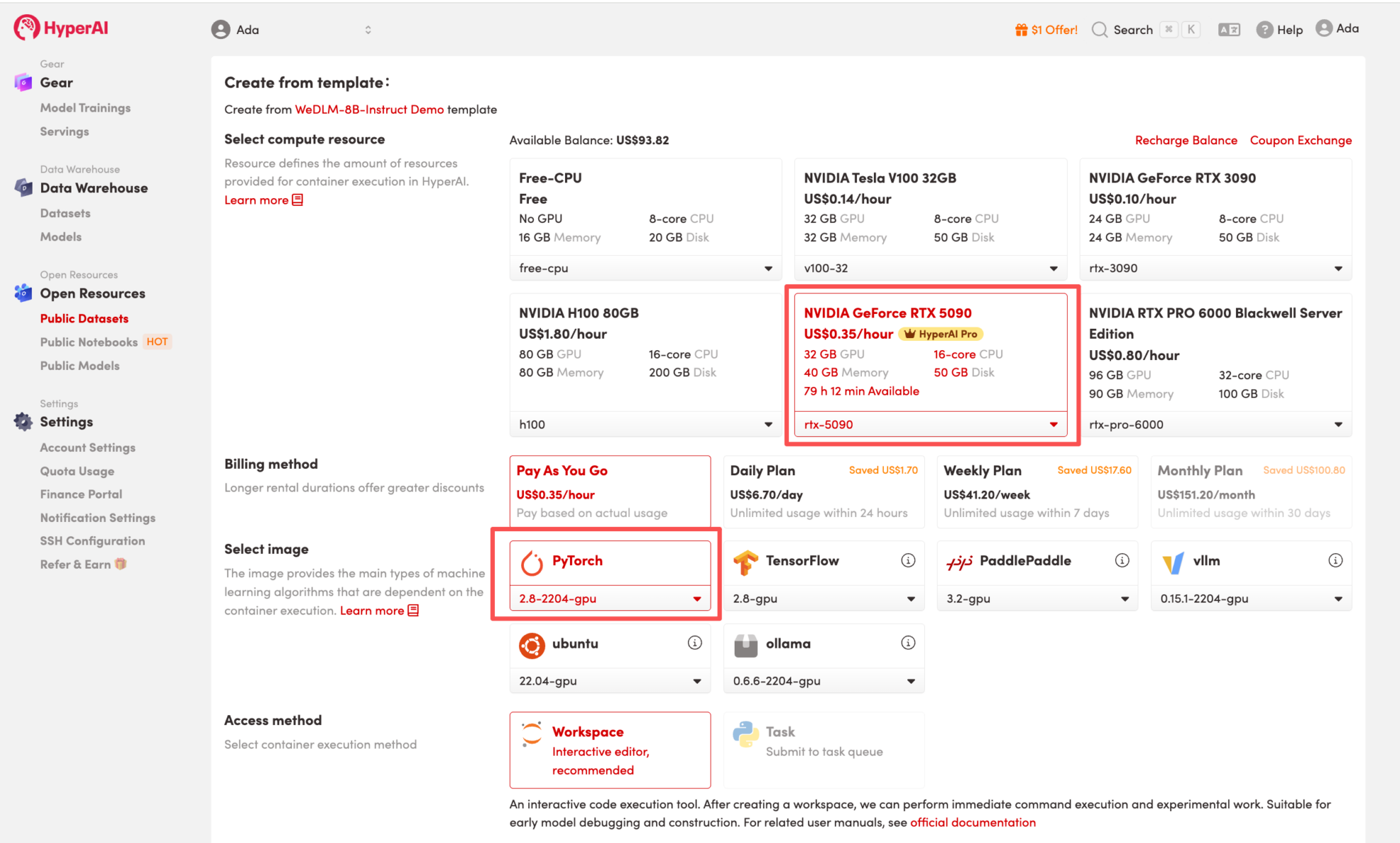
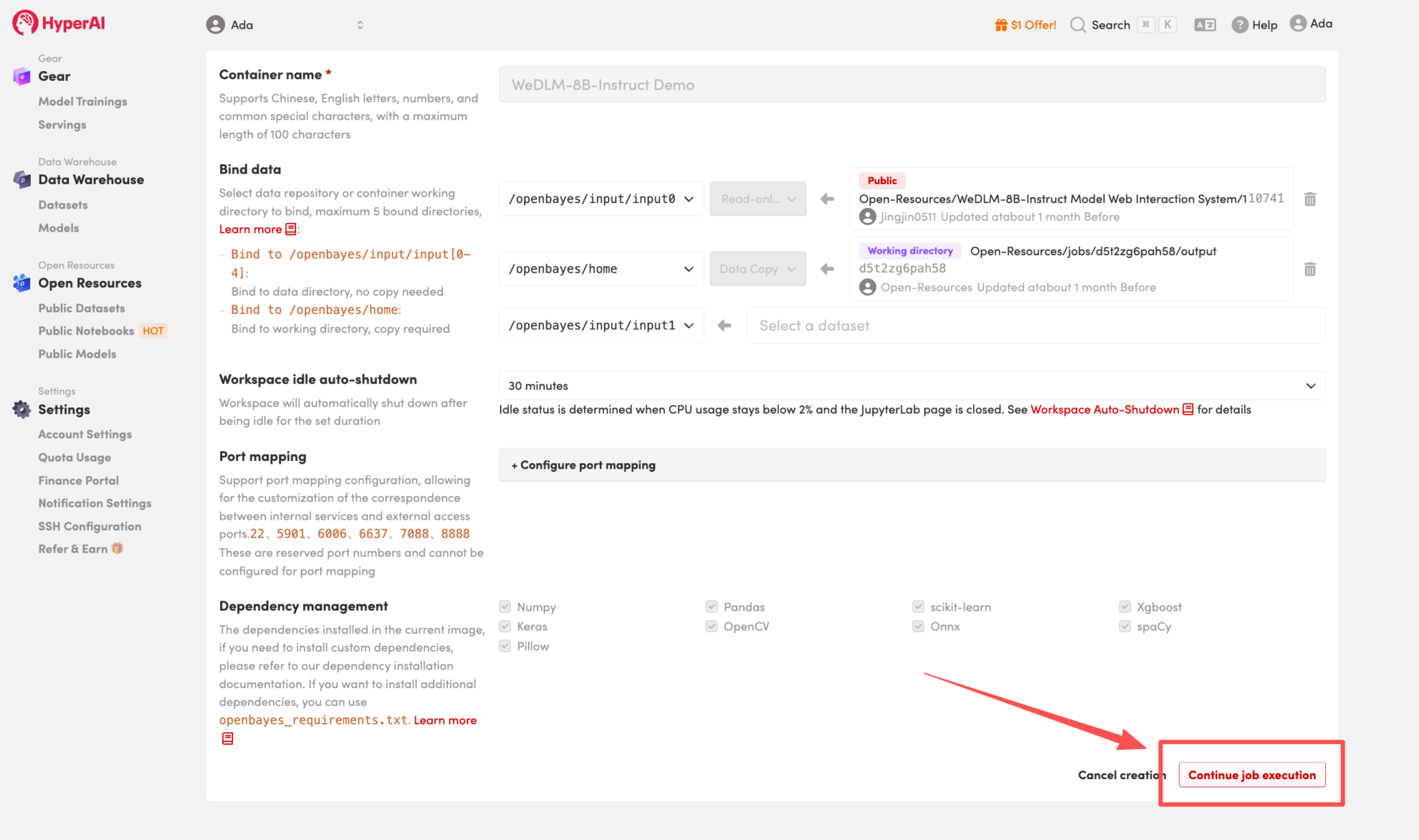
4. انتظر حتى يتم تخصيص الموارد. بمجرد أن تتغير الحالة إلى "قيد التشغيل"، انقر فوق "فتح مساحة العمل" للدخول إلى مساحة عمل Jupyter.
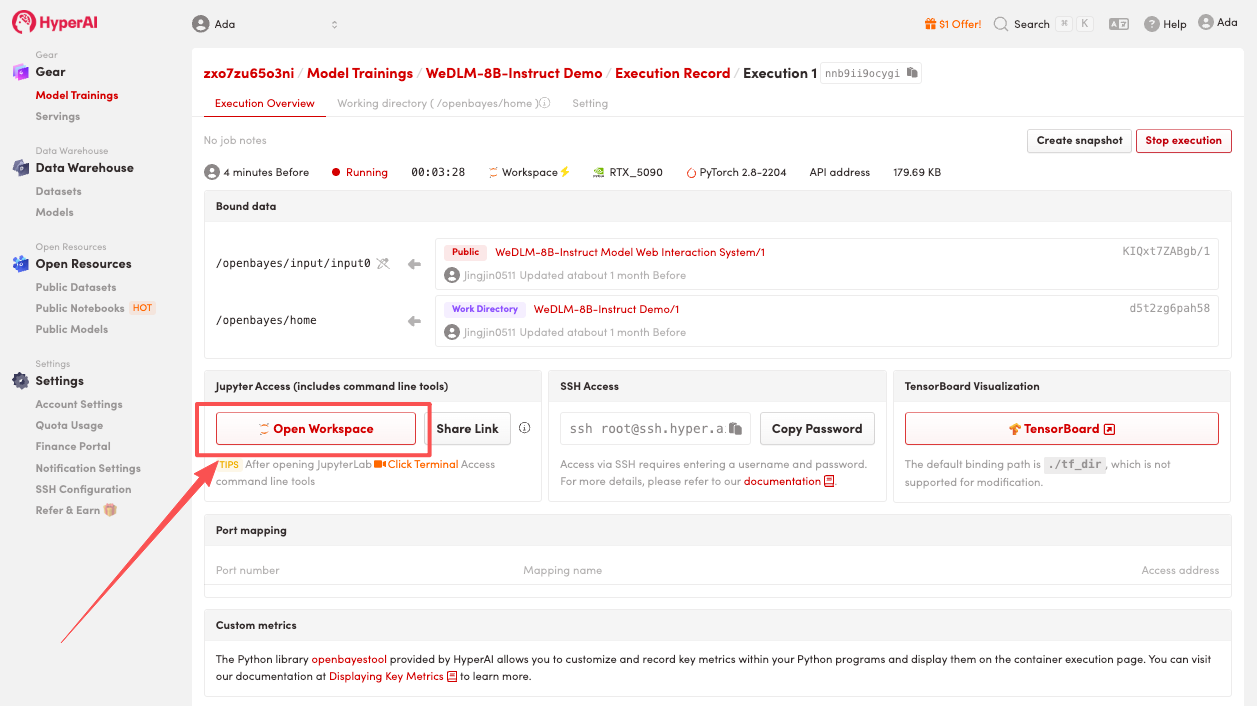
عرض التأثير
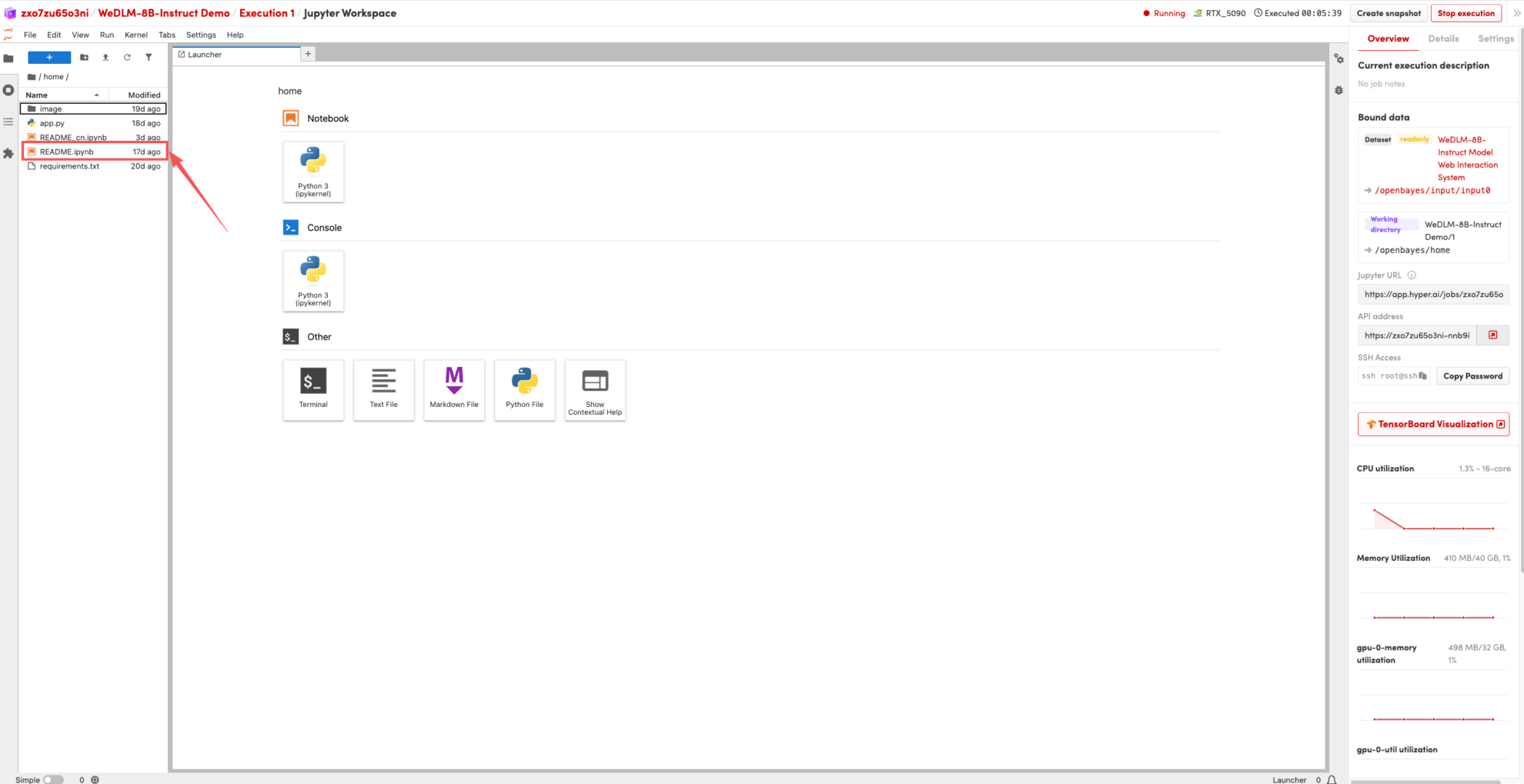
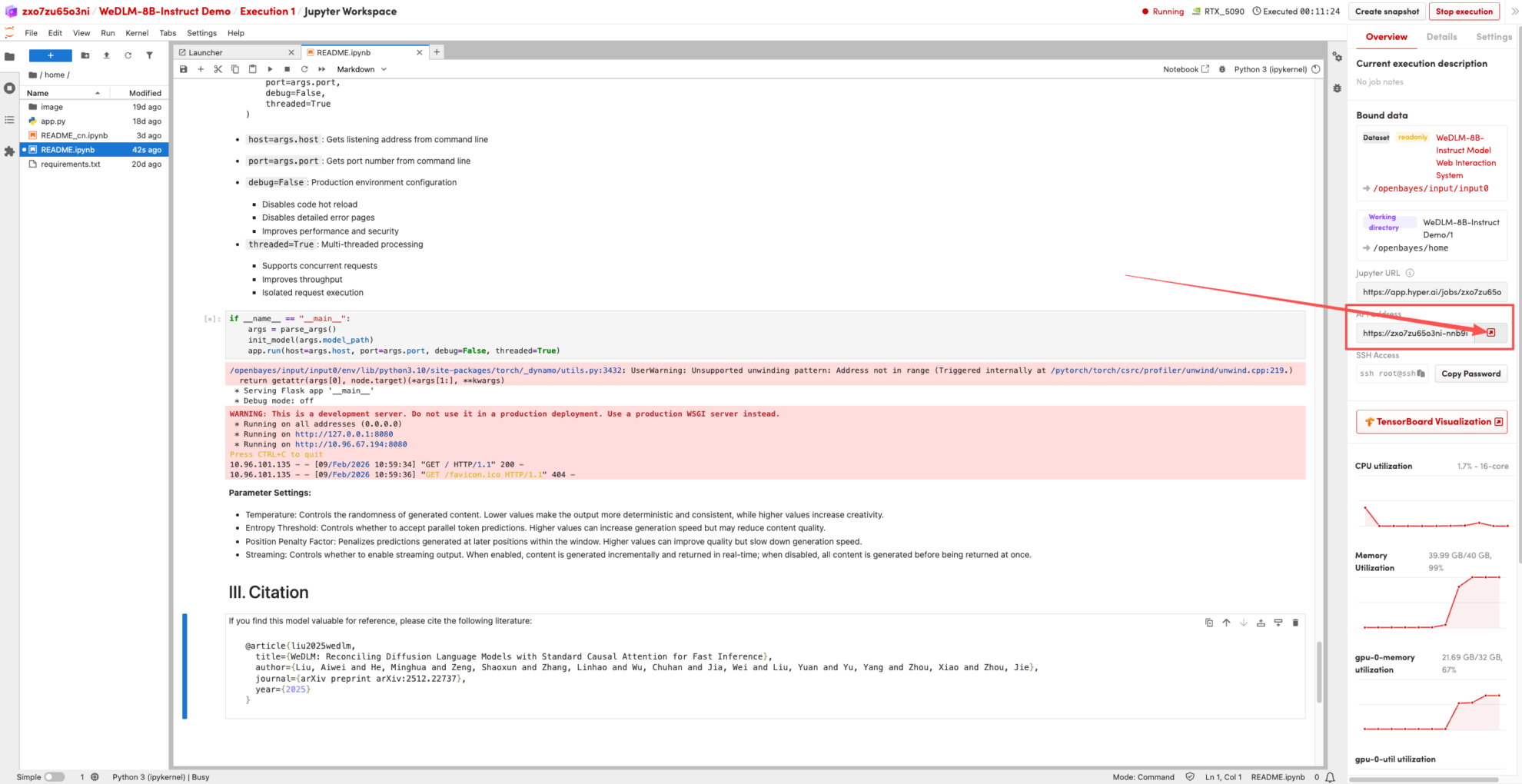
1. بعد إعادة توجيه الصفحة، انقر على صفحة README على اليسار، ثم انقر فوق تشغيل في الأعلى.
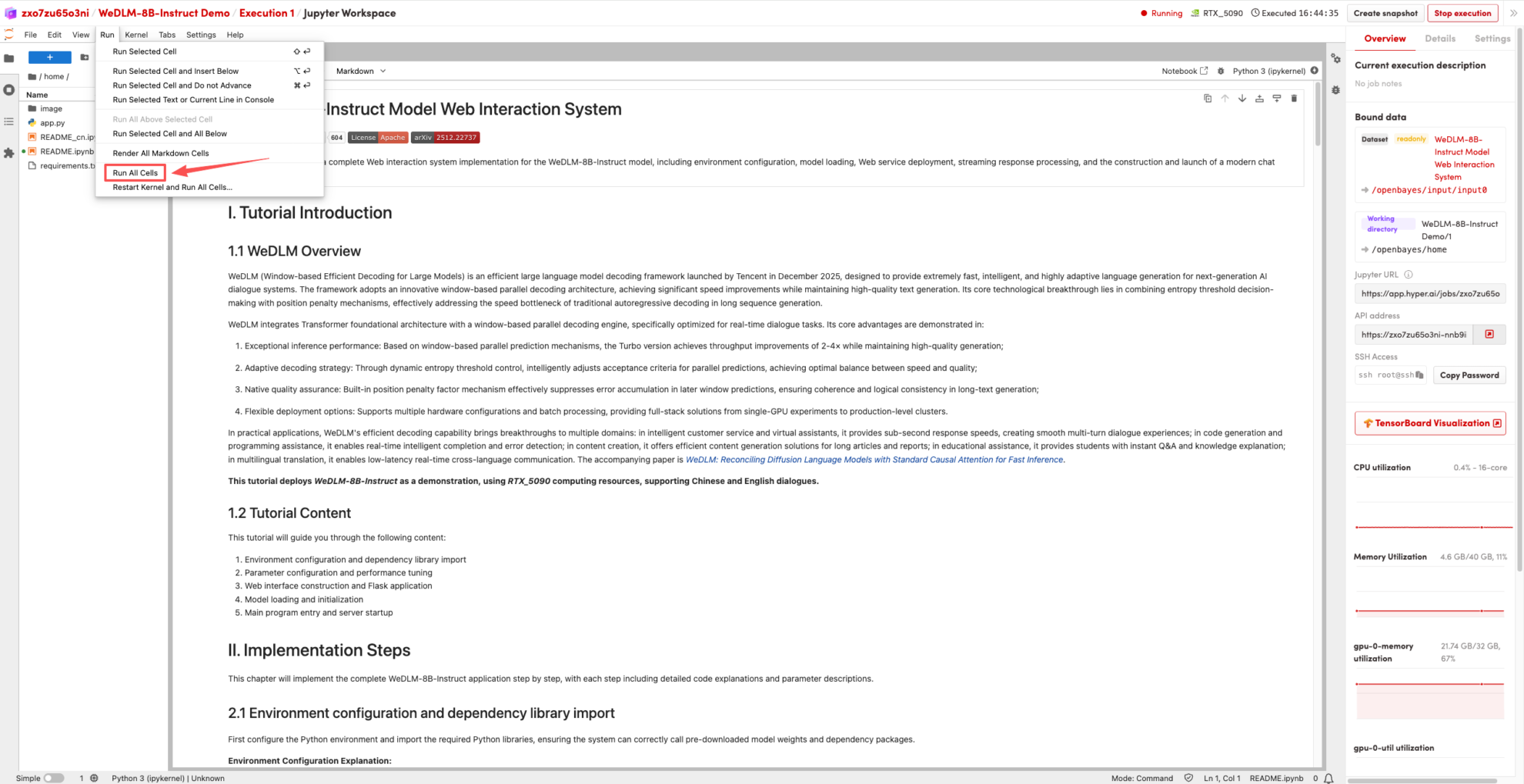
2. بمجرد اكتمال العملية، انقر فوق عنوان API الموجود على اليمين للانتقال إلى صفحة العرض التوضيحي.
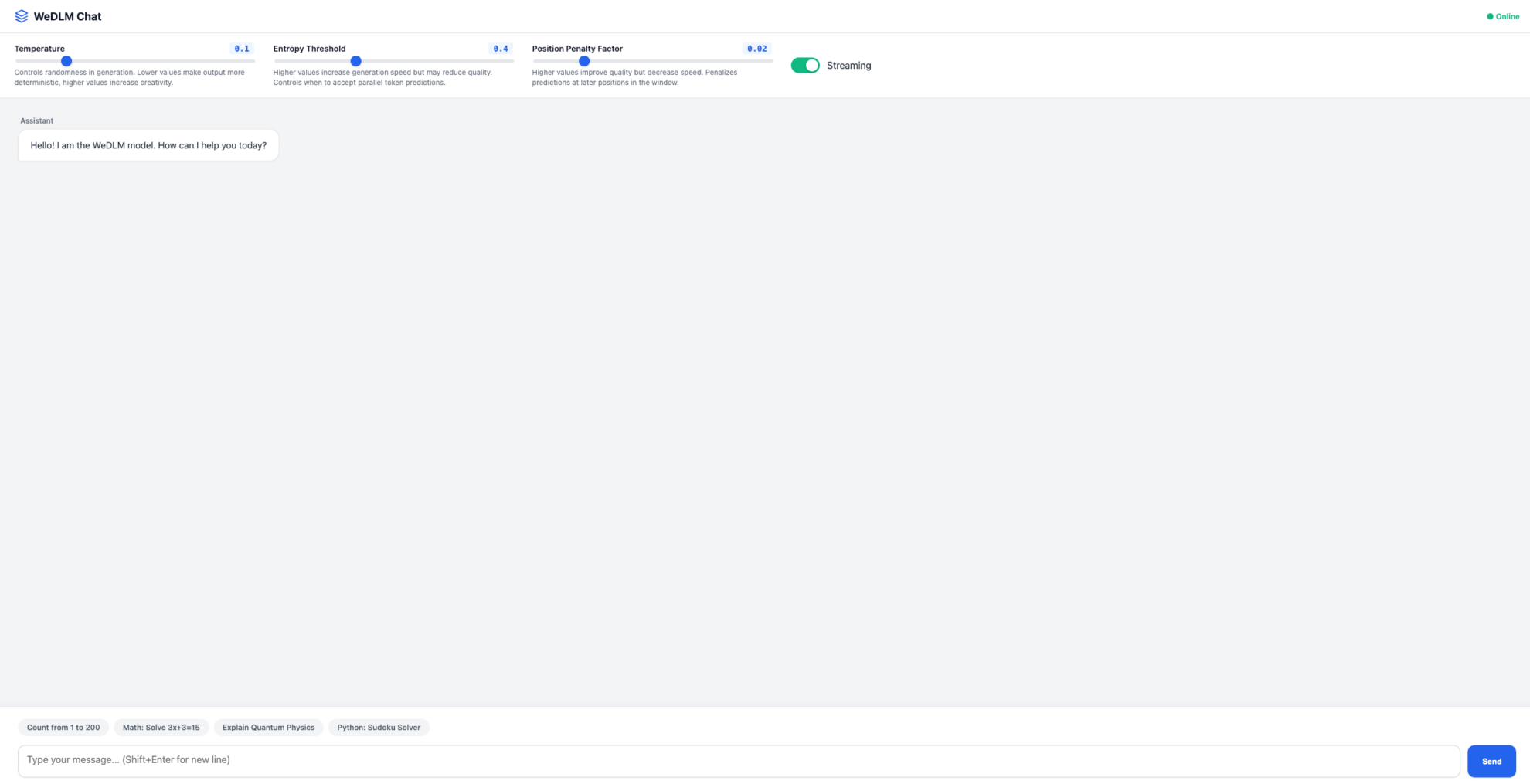
ما سبق هو البرنامج التعليمي الذي توصي به HyperAI هذه المرة. الجميع مدعوون للحضور وتجربته!
رابط البرنامج التعليمي:https://go.hyper.ai/qf0Y6








