Command Palette
Search for a command to run...
برنامج تعليمي عبر الإنترنت | Deepseek-OCR يحقق أحدث التقنيات في النماذج الشاملة بأقل عدد من الرموز المرئية

كما هو معروف، عند معالجة نماذج اللغات الكبيرة لنصوصٍ تتألف من آلاف أو عشرات الآلاف، أو حتى أكثر، غالبًا ما يزداد حجم العمليات الحسابية بشكل كبير، مما يؤدي إلى استنزافٍ هائلٍ للقدرة الحاسوبية. هذا أيضًا يحدّ من كفاءة برنامج ماجستير إدارة الأعمال في معالجة سيناريوهات معلومات النصوص عالية الكثافة.
مع استمرار استكشاف الصناعة لطرق تحسين الكفاءة الحسابية، يُقدم Deepseek-OCR منظورًا جديدًا كليًا: هل يُمكننا "قراءة" النص بكفاءة باستخدام نفس الطرق التي نستخدمها "لرؤيته"؟ بناءً على هذه الفكرة الجريئة، اكتشف الباحثون أن صورة واحدة تحتوي على نص مستندي يُمكنها تمثيل ثروة من المعلومات باستخدام رموز أقل بكثير من النص الرقمي المُماثل. هذا يعني أنه عند اختيارنا تغذية المعلومات النصية كصور إلى نماذج كبيرة لفهمها وحفظها، يُمكن تحسين الكفاءة الإجمالية بشكل فعال. لم يعد الأمر مجرد معالجة للصور.وبدلاً من ذلك، فهو عبارة عن "ضغط بصري" ذكي - باستخدام الوسائط البصرية كوسيلة ضغط فعالة لمعلومات النص، وبالتالي تحقيق نسبة ضغط أعلى بكثير من تلك الخاصة بالتمثيل النصي التقليدي.
على وجه التحديد، يتكون DeepSeek-OCR من مكونين: DeepEncoder وDeepSeek3B-MoE-A570M. المشفر (DeepEncoder) مسؤول عن استخراج خصائص الصورة، وتجزئة الكلمات، وضغط التمثيلات المرئية، بينما يُستخدم فك التشفير (DeepSeek3B-MoE-A570M) لتوليد النتائج المطلوبة بناءً على علامات الصورة والمطالبات.تم تصميم DeepEncoder، باعتباره المحرك الأساسي، للحفاظ على حالة تنشيط منخفضة تحت إدخال عالي الدقة مع تحقيق معدل ضغط مرتفع، وذلك لضمان تحسين عدد الرموز المرئية وسهولة إدارتها.تُظهر التجارب أنه عندما يكون عدد رموز النصوص أقل من عشرة أضعاف عدد الرموز المرئية (أي أن نسبة الضغط أقل من 10x)، يمكن للنموذج تحقيق دقة فك تشفير (OCR) تبلغ 971 TP3T. وحتى مع نسبة ضغط تبلغ 20x، تبقى دقة OCR عند حوالي 601 TP3T.
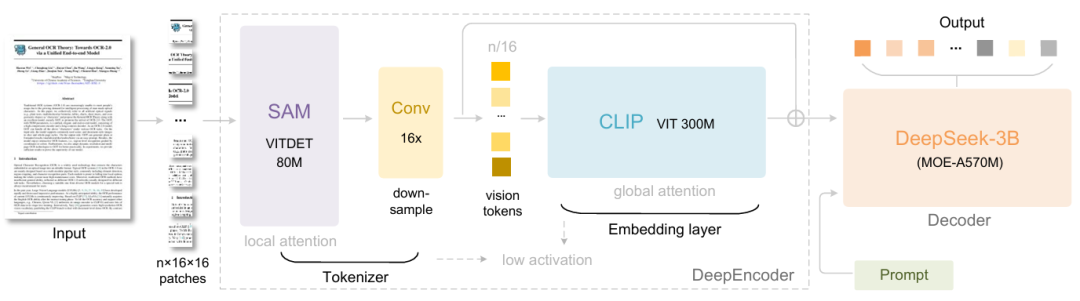
إن إصدار DeepSeek-OCR ليس مجرد تقدم في مهام التعرف الضوئي على الحروف فحسب، بل إنه يوضح أيضًا إمكانات هائلة في مجالات البحث المتطورة مثل ضغط السياق الطويل واستكشاف آليات نسيان الذاكرة في برامج الماجستير في القانون.
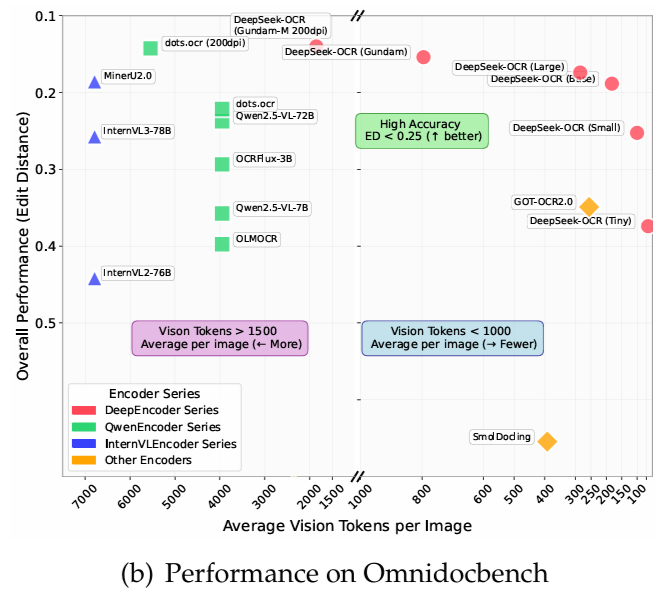
على OmniDocBench،إنه يتفوق على GOT-OCR2.0 (256 رمزًا لكل صفحة) باستخدام 100 رمز مرئي فقط.علاوة على ذلك، يتفوق على MinerU2.0 (أكثر من 6000 رمز لكل صفحة في المتوسط) عند استخدام أقل من 800 رمز مرئي. في بيئة إنتاجية، يمكن لـ DeepSeek-OCR توليد أكثر من 200,000 صفحة من بيانات التدريب لـ LLMs/VLMs يوميًا (باستخدام A100-40G واحد).
"DeepSeek-OCR: الضغط البصري يحل محل التعرف التقليدي على الحروف" متوفر الآن في قسم "الدروس التعليمية" بموقع HyperAI الإلكتروني (hyper.ai). جرّبه بنقرة واحدة!
* رابط البرنامج التعليمي:
* عرض الأوراق ذات الصلة:
https://hyper.ai/papers/DeepSeek_OCR
تشغيل تجريبي
1. بعد الدخول إلى الصفحة الرئيسية لـ hyper.ai، حدد "DeepSeek-OCR: الضغط المرئي بدلاً من التعرف التقليدي على الأحرف"، أو انتقل إلى صفحة "البرامج التعليمية" وحدد "تشغيل هذا البرنامج التعليمي عبر الإنترنت".
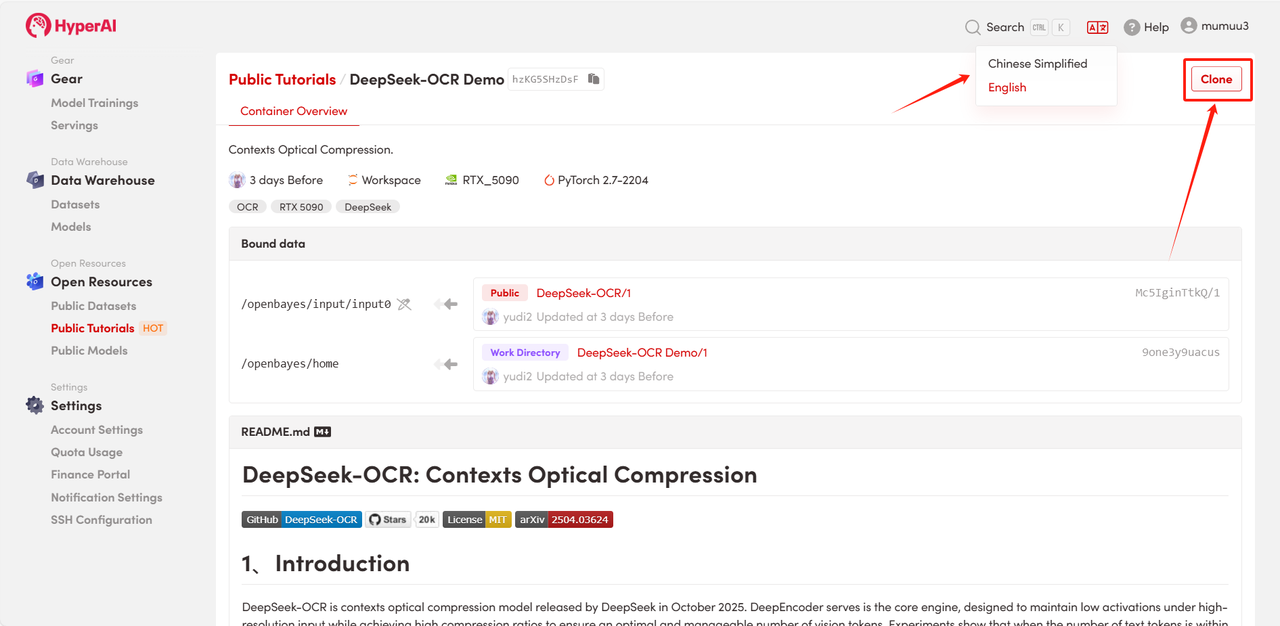
2. بعد إعادة توجيه الصفحة، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
ملاحظة: يمكنك تبديل اللغات في الزاوية العلوية اليمنى من الصفحة. حاليًا، اللغتان الصينية والإنجليزية متاحتان. سيوضح هذا البرنامج التعليمي الخطوات باللغة الإنجليزية.
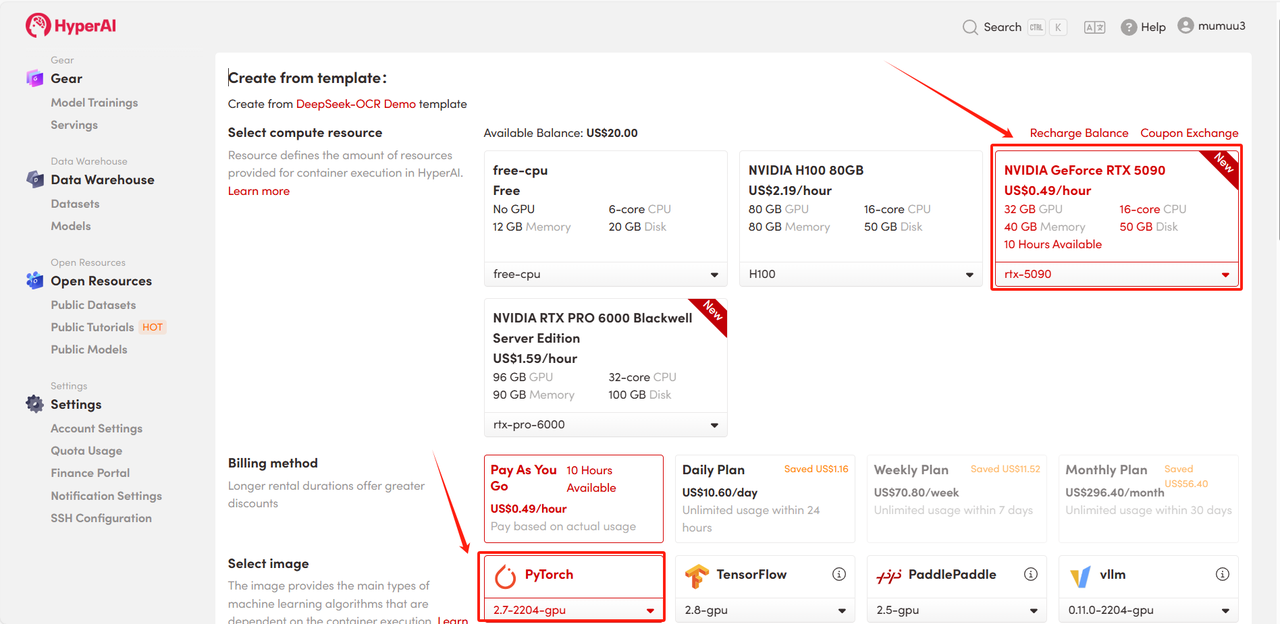
3. حدد صورتي "NVIDIA GeForce RTX 5090" و"PyTorch"، ثم اختر "الدفع حسب الاستخدام" أو "الخطة اليومية/الخطة الأسبوعية/الخطة الشهرية" حسب الحاجة، ثم انقر فوق "متابعة تنفيذ المهمة".
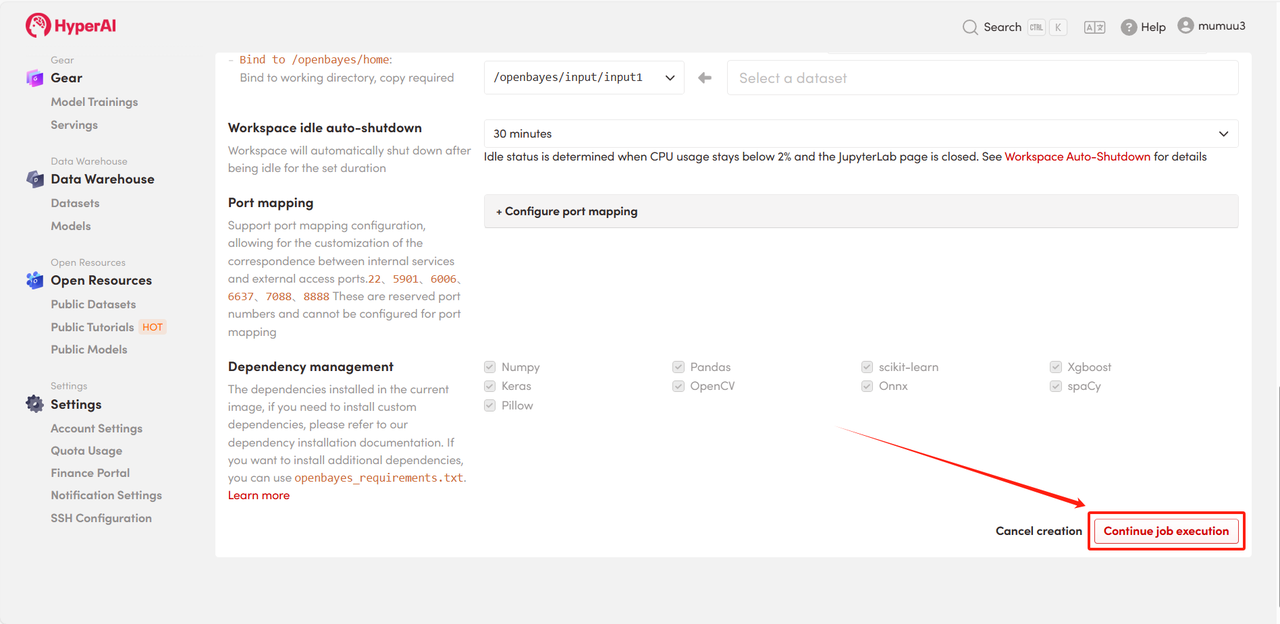
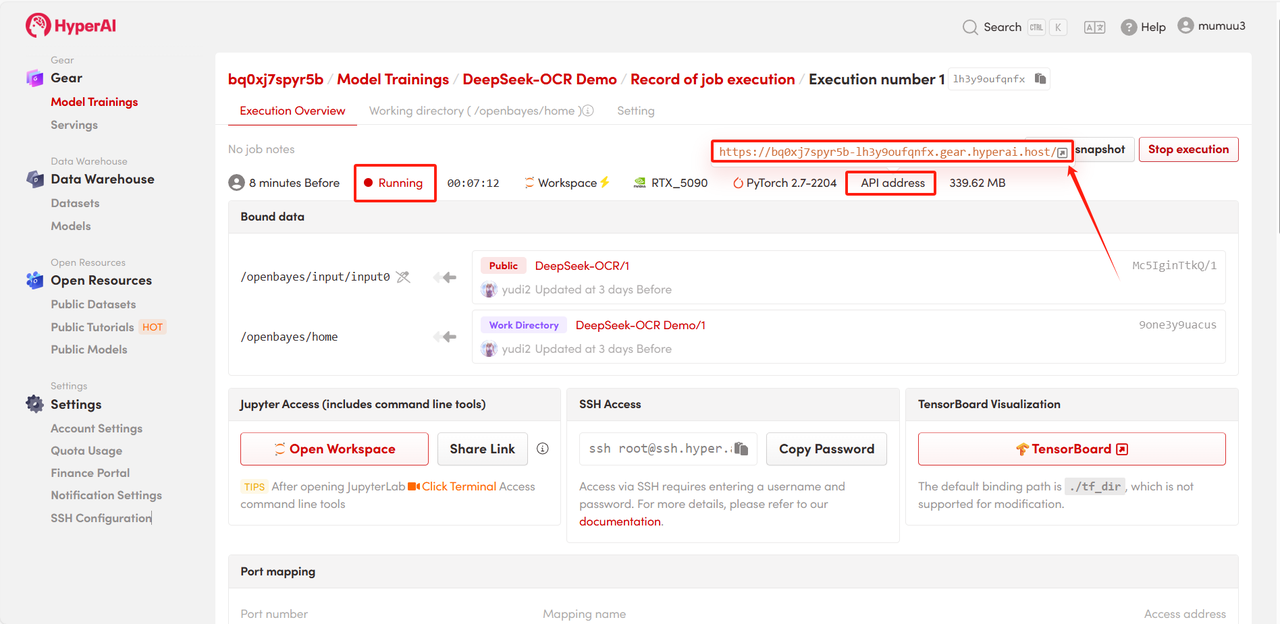
٤. انتظر تخصيص الموارد. سيستغرق الاستنساخ الأول حوالي ٣ دقائق. بمجرد تغيير الحالة إلى "قيد التشغيل"، انقر على سهم الانتقال السريع بجوار "عنوان واجهة برمجة التطبيقات" للانتقال إلى صفحة العرض التوضيحي.
عرض التأثير
بعد الدخول إلى صفحة تشغيل العرض التوضيحي، قم برفع صورة المستند المراد تحليلها، ثم انقر فوق "استخراج النص" لبدء التحليل.
يقوم النموذج أولاً بتقسيم النص أو وحدات الرسم البياني في الصورة، ثم يقوم بإخراج النص بتنسيق Markdown.

ما سبق هو البرنامج التعليمي الذي توصي به HyperAI هذه المرة. الجميع مدعوون للحضور وتجربته!
* رابط البرنامج التعليمي:








