Command Palette
Search for a command to run...
دورة تعليمية عبر الإنترنت | أحدث التقنيات في مجال تحويل النص إلى كلام عبر الأجهزة! جهاز NeuTTS-Air يُحقق استنساخًا صوتيًا في 3 ثوانٍ استنادًا إلى نموذج 0.5B

لطالما واجهت نماذج تحويل النص إلى كلام (TTS) التقليدية عالية الجودة تحديات جوهرية عديدة: فهي غالبًا ما تتطلب موارد حوسبة وخدمات سحابية عالية، مما يؤدي إلى تكاليف باهظة يصعب على الشركات الصغيرة والمطورين الأفراد تحملها؛ علاوة على ذلك، تتطلب معظم هذه النماذج عشرات الدقائق، بل وحتى ساعات، من البيانات الصوتية للتدريب. هذه المتطلبات المتعلقة بالنشر والتشغيل لا تزيد من صعوبة استخدام هذه النماذج فحسب، بل تحد أيضًا من تطبيقها في الحالات التي تتطلب الخصوصية.
NeuTTS-Air، أحدث نموذج لتوليف الكلام الشامل مفتوح المصدر، يقدم حلاً جديدًا تمامًا للتحديات المتمثلة في استخدام TTS.باعتباره أول نموذج لغة تحويل النص إلى كلام محلي في العالم يدعم توليف الكلام فائق الواقعية واستنساخ الكلام في الوقت الفعلي،لا يُظهر NeuTTS-Air، الذي يعتمد على برنامج ترميز الصوت 0.5B Qwen LLM وNeuCodec، قدرات ممتازة للتعلم من خلال عدد قليل من اللقطات في النشر الحافة واستنساخ الصوت في الوقت الفعلي فحسب، بل يمكنه أيضًا التعميم على سيناريوهات جديدة مثل الوكلاء المضمنين ونقل الأسلوب، ويدعم استنساخ الصوت لمدة 3 ثوانٍ، ويولد محتوى حوار طبيعي.
يظهر التقييم التجريبي أنيحقق NeuTTS Air أداءً متطورًا (SOTA) بين النماذج مفتوحة المصدر.خاصةً في التوليف فائق الواقعية ومعايير الاستدلال في الوقت الفعلي. يُقدّم التدريب اللاحق دعمًا لـ GGML/ONNX وآلية وضع علامات مائية، مما يُتيح الريادة في مجال البرمجيات مفتوحة المصدر في تقييمات تحويل النص إلى كلام من جانب الحافة وتحسين استهلاك الطاقة، ويُضاهي النماذج مغلقة المصدر في بعض السيناريوهات. والأهم من ذلك، هذا النموذج خفيف الوزن.يمكن إجراء الاستدلال على وحدة المعالجة المركزية.مناسب للأجهزة مثل الهواتف المحمولة وأجهزة الكمبيوتر المحمولة وRaspberry Pi.
رابط البرنامج التعليمي لـ "نشر نموذج استنساخ الصوت NeuTTS-Air على وحدة المعالجة المركزية":
يأتي إصدار NeuTTS-Air في وقتٍ يتزايد فيه الطلب في هذا المجال على أنظمة تحويل نص إلى كلام (TTS) فعّالة، منخفضة الكمون، وواقعية للغاية، لا سيما في مجالات النشر على الأجهزة واستنساخ الصوت في الوقت الفعلي. يُسهّل هذا النظام على المطورين نشر أنظمة تحويل نص إلى كلام عالية الجودة على الأجهزة المحمولة والأجهزة الطرفية، مما يجعل الأصوات "الغريبة" حكرًا على نماذج السحابة الكبيرة.
"NeuTTS-Air: نموذج استنساخ الكلام خفيف الوزن وفعال" متاح الآن على موقع HyperAI (hyper.ai) في قسم "البرامج التعليمية".تعال واستمتع بالنشر بنقرة واحدة!
رابط البرنامج التعليمي:
تشغيل تجريبي
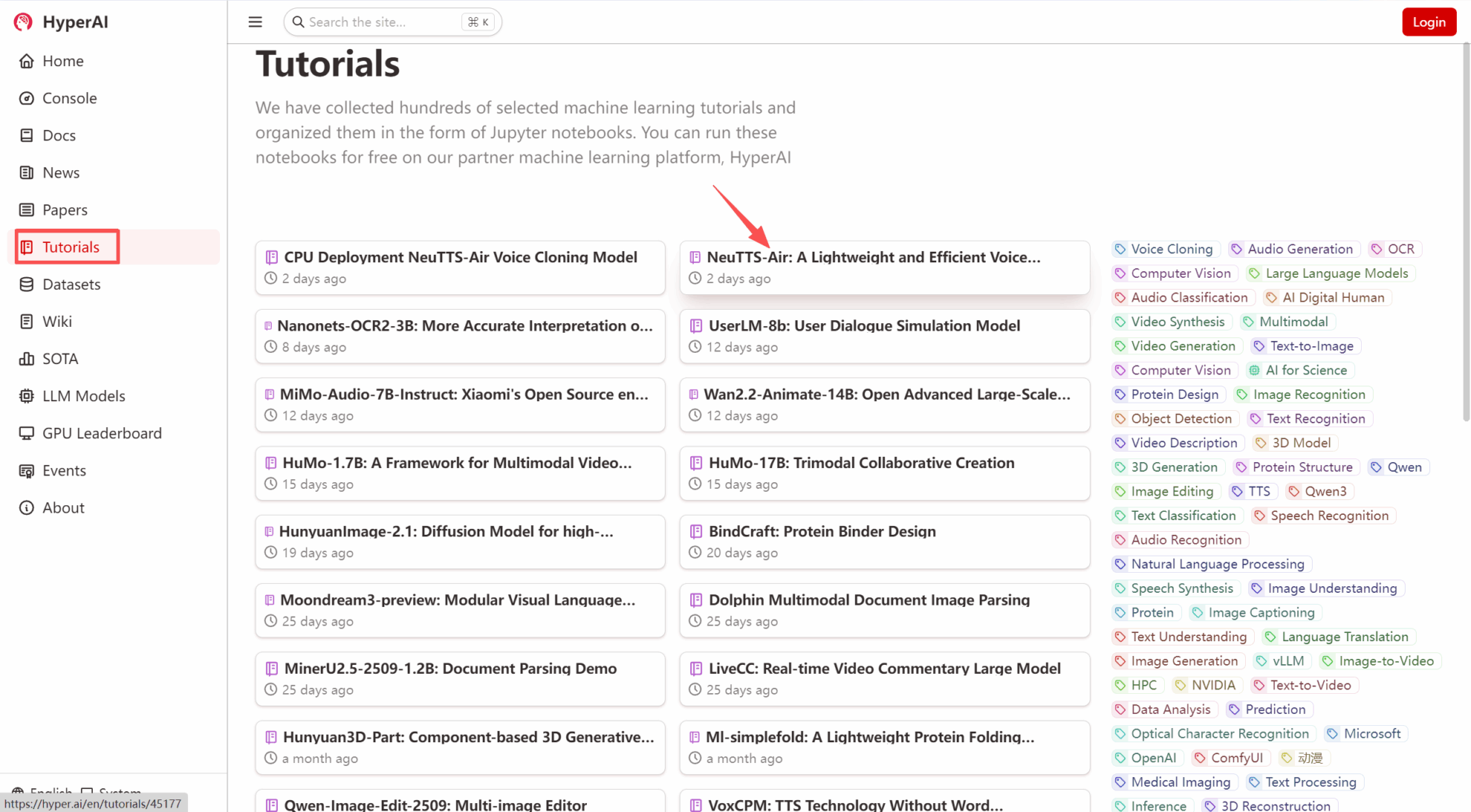
1. بعد الدخول إلى الصفحة الرئيسية لـ hyper.ai، حدد صفحة "البرامج التعليمية"، أو انقر فوق "عرض المزيد من البرامج التعليمية"، وحدد "NeuTTS-Air: نموذج استنساخ الكلام خفيف الوزن وفعال"، وانقر فوق "تشغيل هذا البرنامج التعليمي عبر الإنترنت".
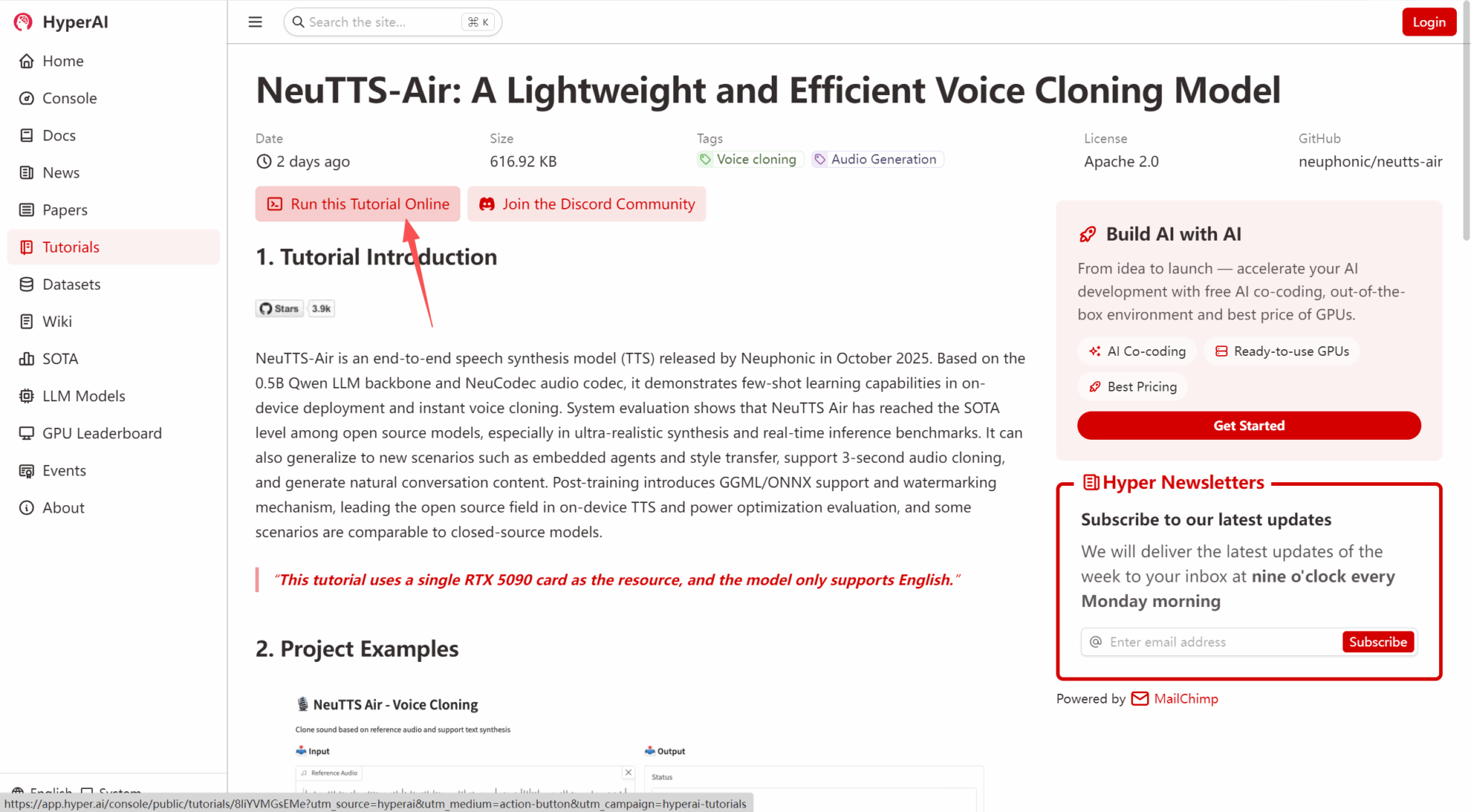
2. بعد إعادة توجيه الصفحة، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
ملاحظة: يمكنك تبديل اللغات في الزاوية العلوية اليمنى من الصفحة. حاليًا، اللغتان الصينية والإنجليزية متاحتان. سيوضح هذا البرنامج التعليمي الخطوات باللغة الإنجليزية.
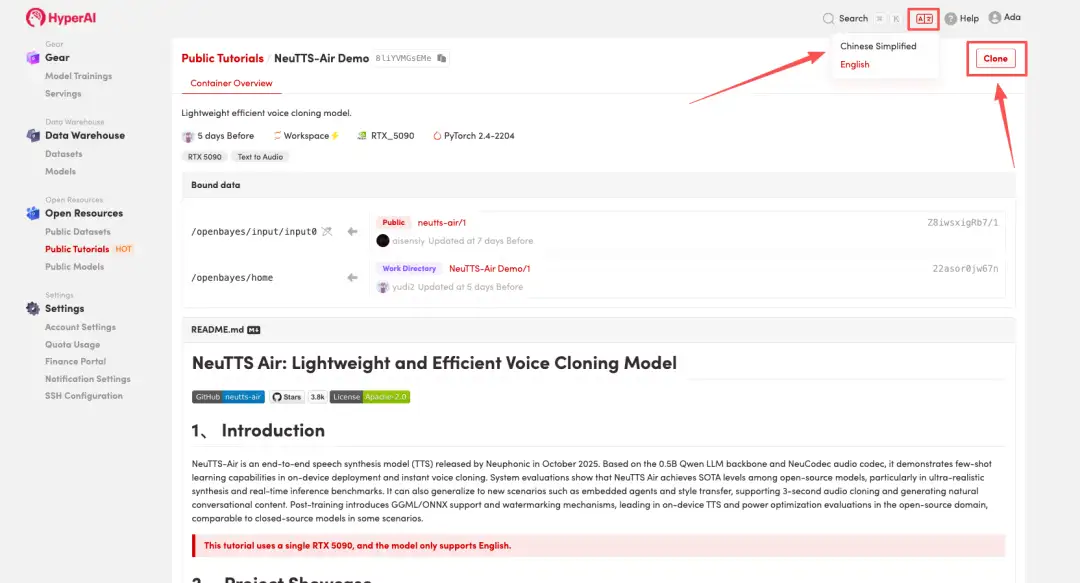
3. حدد صورتي "NVIDIA GeForce RTX 5090" و"PyTorch"، ثم اختر "الدفع حسب الاستخدام" أو "الخطة اليومية/الخطة الأسبوعية/الخطة الشهرية" حسب الحاجة، ثم انقر فوق "متابعة تنفيذ المهمة".
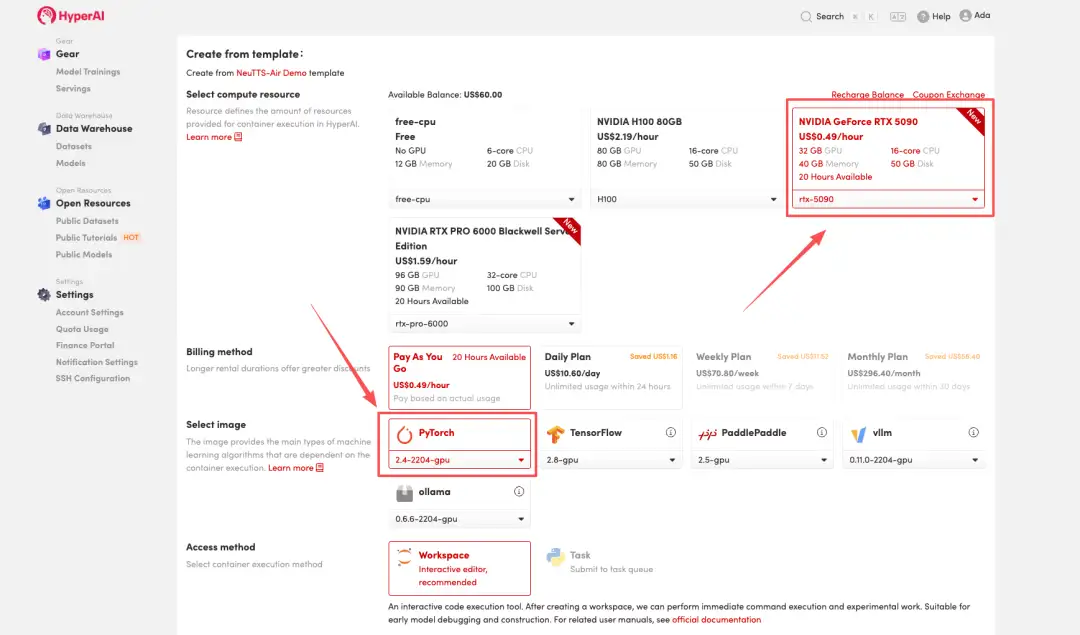

٤. انتظر حتى يتم تخصيص الموارد. تستغرق عملية الاستنساخ الأولى حوالي ٣ دقائق. عندما تتغير الحالة إلى "قيد التشغيل"، انقر على السهم بجوار "عنوان واجهة برمجة التطبيقات" للانتقال إلى صفحة العرض التوضيحي. يُرجى العلم أنه يجب على المستخدمين إكمال مصادقة الاسم الحقيقي قبل استخدام عنوان واجهة برمجة التطبيقات.
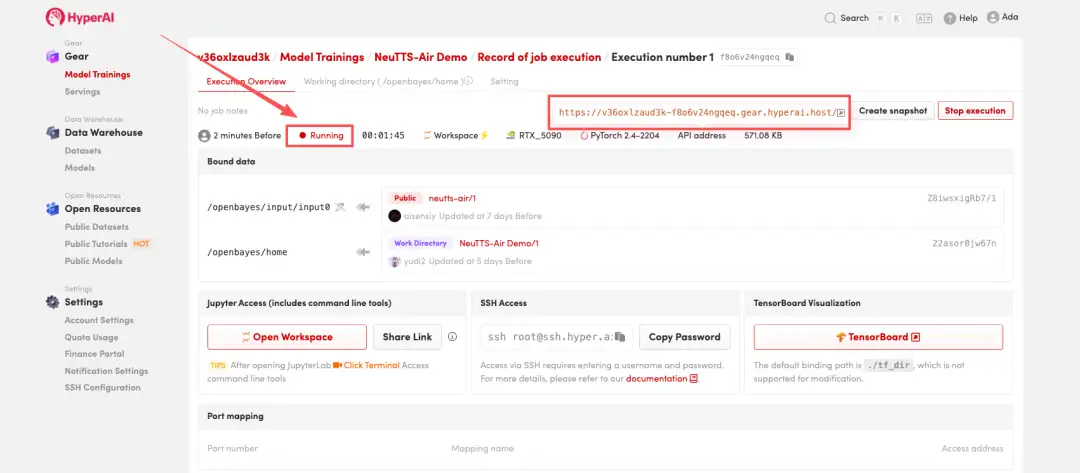
عرض التأثير
بعد الدخول إلى صفحة تشغيل العرض التوضيحي، قم بتحميل الصوت المرجعي في "الصوت المرجعي"، وأدخل النص المرجعي في مربع النص "النص المرجعي"، وأدخل محتوى النص الصوتي المطلوب بعد الاستنساخ في "النص المراد إنشاؤه"، وانقر فوق "إرسال" وانتظر لحظة للحصول على الصوت المستنسخ.
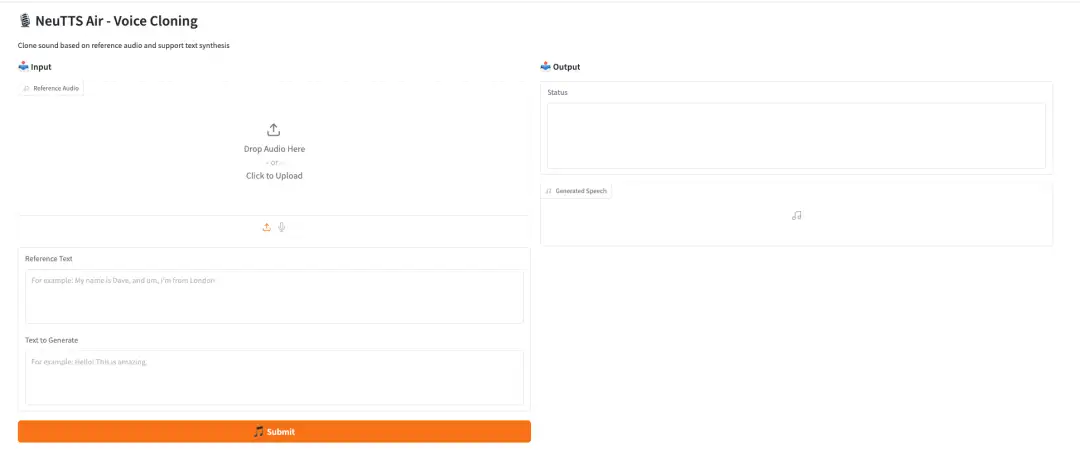
ما سبق هو البرنامج التعليمي الذي توصي به HyperAI هذه المرة. الجميع مدعوون للحضور وتجربته!
رابط البرنامج التعليمي:








