Command Palette
Search for a command to run...
إعادة تعريف تصنيف نماذج لغة البروتين بناءً على العلاقة بين البنية/التسلسل/الوظيفة: يشرح الدكتور لي مينغتشين نماذج لغة البروتين بالتفصيل

افتتحت الدورة الثالثة من "مدرسة الذكاء الاصطناعي للهندسة الحيوية الصيفية" بجامعة شنغهاي جياو تونغ رسميًا في الفترة من 8 إلى 10 أغسطس 2025.جمعت هذه المدرسة الصيفية أكثر من 200 من المواهب الشابة والباحثين العلميين وممثلي الصناعة من أكثر من 70 جامعة وأكثر من 10 مؤسسات بحثية علمية وأكثر من 10 شركات رائدة في الصناعة حول العالم، مع التركيز على التطوير المتكامل للذكاء الاصطناعي والهندسة الحيوية.
ومن بينهم، في قسم دورة "حدود خوارزميات الذكاء الاصطناعي"، شارك لي مينغ تشين، وهو زميل ما بعد الدكتوراه في مجموعة هونغ ليانغ البحثية في معهد العلوم الطبيعية بجامعة شنغهاي جياو تونغ، مع الجميع الإنجازات المتطورة لنماذج لغة البروتين في التنبؤ بالوظيفة، وتوليد التسلسل، والتنبؤ بالبنية، وما إلى ذلك، تحت عنوان "النموذج الأساسي للبروتينات والجينومات"، بالإضافة إلى التقدم البحثي ذي الصلة في قوانين التوسع ونماذج الجينوم.

قامت شركة HyperAI بجمع وتلخيص مداخلة الدكتور لي مينغ تشن الرائعة دون المساس بالهدف الأصلي. فيما يلي نص لأهم ما جاء في الكلمة.
تصنيف جديد لنماذج لغة البروتين: العلاقة بين بنية البروتين وتسلسله ووظيفته
للبروتينات تطبيقات واسعة النطاق، تشمل مجالات كالهندسة الكيميائية، والزراعة، والأغذية، ومستحضرات التجميل، والطب، والاختبارات، بقيمة سوقية تتجاوز تريليونات الدولارات. ببساطة، نمذجة لغة البروتين هي مسألة توزيع احتمالي. إنها تعادل تحديد احتمالية وجود تسلسل حمض أميني في الطبيعة، وأخذ العينات بناءً عليه. من خلال التدريب المسبق على كميات هائلة من البيانات، يمكن للنموذج تمثيل توزيع الاحتمالات الموجود في الطبيعة بفعالية.
يحتوي نموذج لغة البروتين على ثلاث وظائف أساسية:
* عملية تعلم تمثيل تسلسلات البروتين كمتجهات عالية الأبعاد
* تحديد عقلانية تسلسل الأحماض الأمينية
* توليد تسلسلات بروتينية جديدة
تُصنّف العديد من الأوراق البحثية نماذج لغة البروتين بناءً على بنية المحول، حيث تصفها مباشرةً بأنها إما قائمة على مُشفّر المحول أو مُفكّك المحول. يصعب على باحثي الأحياء فهم هذا التصنيف، وغالبًا ما يُسبب التباسًا. لذلك، سأُقدّم طريقة تصنيف جديدة:التصنيف على أساس العلاقة بين بنية البروتين وتسلسله ووظيفته.
تسلسل البروتين هو تسلسل أحماضه الأمينية. بمجرد معرفة تسلسل الأحماض الأمينية، يُمكن تصنيعه في مختبر أو مصنع وتطبيقه عمليًا. وتُعد بنية البروتين بالغة الأهمية، إذ ترجع وظيفته إلى بنيته المحددة في الفضاء ثلاثي الأبعاد، مما يُمكّنه من أداء وظيفته على المستوى المجهري.
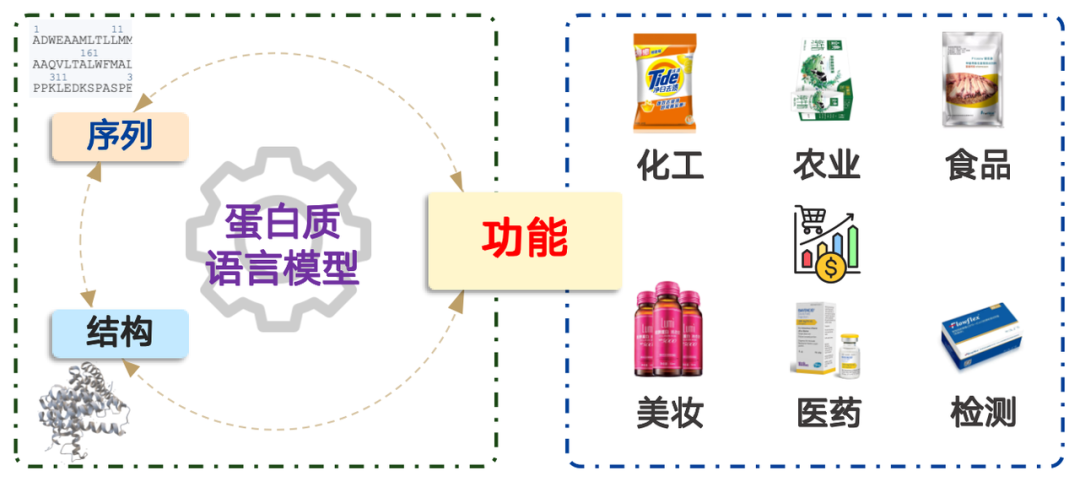
وبناءً على هذه الفكرة، يمكن تقسيم نماذج لغة البروتين إلى الفئات الأربع التالية:
1. التسلسل → الوظيفة:التنبؤ بوظيفة تسلسل معين من الأحماض الأمينية، أي: نموذج التنبؤ الوظيفي.
2. الوظيفة → التسلسل:قم بتصميم تسلسل الأحماض الأمينية المقابلة وفقًا للوظيفة المعطاة، بما في ذلك النماذج التوليديةو نموذج التعدين.
3. التسلسل → الهيكل:يُطلق على التنبؤ ببنيته بناءً على تسلسل الأحماض الأمينية عادةً اسم "نموذج التنبؤ الهيكلي"ينتمي AlphaFold الحائز على جائزة نوبل إلى هذا النوع من النماذج.
4. الهيكل → التسلسل:يُطلق على تصميم التسلسل المقابل بناءً على بنية بروتينية معينة عادةً اسم "نموذج الطي العكسي".
سيناريوهات التطبيق والمسارات التقنية: تحليل أربعة نماذج رئيسية
"التسلسل → الوظيفة"
الطريقة الأسهل لفهم "التسلسل → الوظيفة" هي التعلم الخاضع للإشراف.
أولاً، يتضمن نموذج التنبؤ بالدالة الأساسي التعبير عن تسلسلات البروتين كمتجهات، ثم تدريبها على مجموعة بيانات محددة. على سبيل المثال، إذا أردنا التنبؤ بدرجات انصهار البروتين، فعلينا أولاً جمع كمية كبيرة من علامات درجات انصهار البروتين، وتحويل جميع تسلسلات البروتين في مجموعة التدريب إلى متجهات عالية الأبعاد، وتدريبها باستخدام أساليب التعلم المُشرف. وأخيرًا، يمكننا إجراء استدلال على تسلسلات في مجموعة الاختبار أو التنبؤ للتنبؤ بالدالة. يمكن لهذا النهج التعامل مع مجموعة واسعة من المهام، وهو موضوع بحثي شائع حاليًا، بالإضافة إلى سهولة نسبية في إنتاج النتائج.
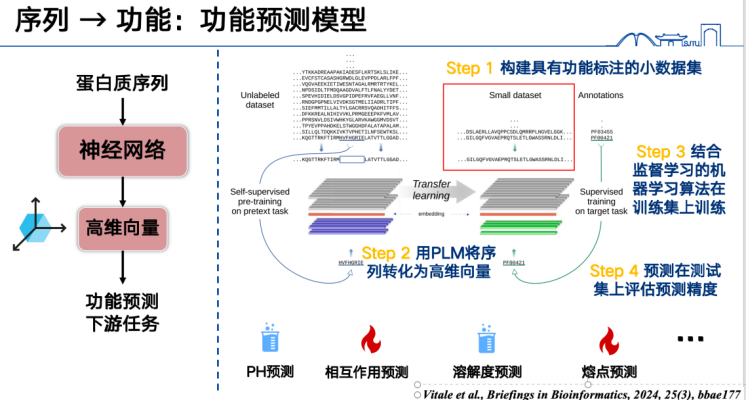
ثانياً، يمكن لنموذج لغة البروتين أيضًا التنبؤ بوظائف الطفرة.الفكرة الأساسية هي إجراء بعض التغييرات على بعض الأحماض الأمينية في تسلسل البروتين، ثم استخدام نموذج لغة البروتين لتحديد ما إذا كان التغيير "معقولاً".
لا يشير "المعقول" هنا إلى التوافق المنطقي في الحياة الواقعية، بل إلى مدى توافق تغير الأحماض الأمينية مع توزيع احتمالات تسلسلات البروتينات الطبيعية. يأتي هذا التوزيع الاحتمالي من عدد كبير من إحصائيات تسلسلات الأحماض الأمينية الحقيقية، وهذه التوزيعات نفسها هي نتاج عشرات الملايين من السنين من التطور.
يتعلم نموذج لغة البروتين هذه القوانين التطورية أثناء التدريب، وبالتالي يمكنه تحديد ما إذا كانت الطفرة تتوافق مع هذه القوانين أم تنحرف عنها. رياضيًا، يمكن تحويل هذا التحديد إلى نسبة احتمالات التسلسلين قبل الطفرة وبعدها. لتسهيل الحساب، غالبًا ما تُحوّل هذه النسبة إلى لوغاريتم، وتحويلها إلى صيغة طرح.
يمكن لنسبة الاحتمالية بين البروتينات الطافرة والبروتينات البرية، التي تستخدمها نماذج اللغة، تقدير قوة تأثير الطفرة. وقد طُرحت هذه الفكرة لأول مرة في ورقة بحثية نُشرت في مجلة Nature Methods عام ٢٠١٨، قدّمت نموذج DeepSequence، إلا أن هذا النموذج كان صغيرًا نسبيًا في ذلك الوقت. لاحقًا، في عام ٢٠٢١، أظهر نموذج ESM-1v أن نماذج لغة البروتين قادرة أيضًا على التنبؤ بفعالية بتأثيرات الطفرات باستخدام نسب الاحتمالية.
لتقييم دقة نموذج التنبؤ بوظيفة طفرة البروتين، هناك حاجة إلى معيار.
المعايير المرجعية هي مجموعات صغيرة من البيانات تُجمع لقياس الدقة. على سبيل المثال، يُعدّ بروتين جيم، الذي طُوّر بالتعاون بين كلية الطب بجامعة هارفارد وجامعة أكسفورد، المعيار المرجعي الأكثر استخدامًا. يحتوي على بيانات حول 217 بروتينًا متحورًا وملايين تسلسلات الطفرات. يُعطي الباحثون درجات لكل تسلسل من هذه التسلسلات باستخدام نموذج لغة البروتين، ثم يُقارنون درجات النموذج المتوقعة بالدرجات الفعلية. يشير الارتباط الأعلى إلى أداء أفضل للنموذج.
ومع ذلك، فإن ProteinGym هو معيار عالي الإنتاجية ومنخفض الدقة.رغم محدودية الظروف التجريبية، يُمكن اختباره على نطاق واسع، إلا أن دقته قد تكون محدودة. قد يُؤدي تكرار التجربة إلى أخطاء في الارتباط بين النتائج والبيانات الأصلية، مما يجعل نتائج التقييم تعكس أداء النموذج في التطبيقات العملية بشكل غير دقيق.
لحل هذه المشكلة،لقد قمنا بتطوير معيار عينة صغير عالي الدقة ومنخفض الإنتاجية مثل VenusMutHub.على الرغم من أن كمية البيانات ليست كبيرة، فإن كل قطعة من البيانات دقيقة نسبيًا، ونتائج التجارب المتكررة متسقة تقريبًا، وهو ما يقترب من سيناريوهات التطبيق الحقيقية.
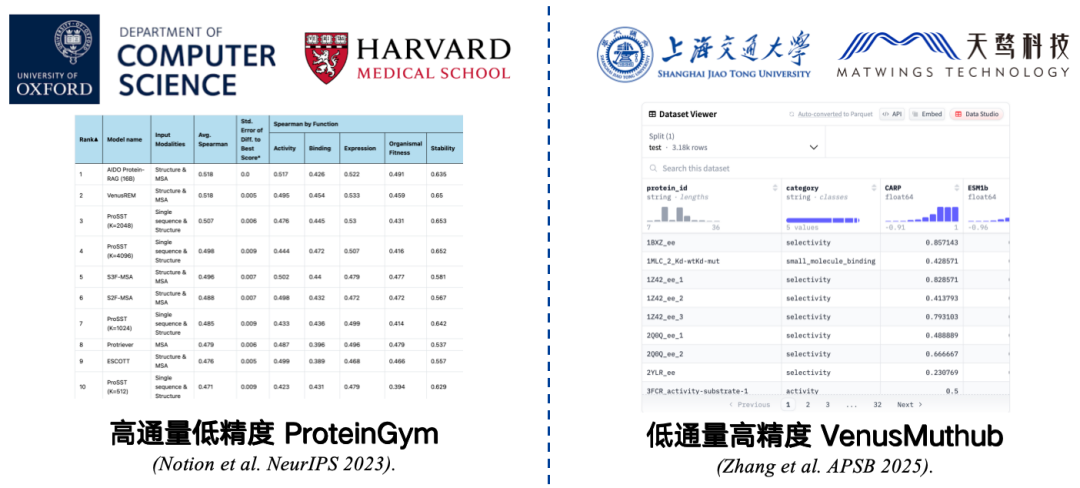
* عنوان الورقة:Zhang L، Pang H، Zhang C، وآخرون. VenusMutHub: تقييم منهجي لمؤشرات تأثير طفرة البروتين على بيانات تجريبية صغيرة النطاق [J]. Acta Pharmaceutica Sinica B، 2025، 15(5): 2454-2467.
علاوة على ذلك، يمكن إدخال البنية لتحسين دقة التنبؤ بالطفرات في نماذج لغة البروتين. في العام الماضي، نشر فريقنا ورقة بحثية حول نموذج لغة البروتين، نموذج ProSST، في مؤتمر NeurIPS. يستخدم هذا النموذج كلاً من تسلسلات الأحماض الأمينية والتسلسلات المنظمة لإجراء تدريب مسبق متعدد الوسائط. وقد احتل نموذج ProSST المرتبة الأولى في مؤشر ProteinGym Benchmark، وهو أكبر مؤشر للتنبؤ بالطفرات بدون أخطاء.
* عنوان الورقة:لي م، تان ي، ما س، وآخرون. ProSST: نمذجة لغة البروتين ببنية مُكمّمة وانتباه مُفكك [ج]. التطورات في أنظمة معالجة المعلومات العصبية، 2024، 37: 35700-35726.
عند إجراء التجارب أو التصميمات، غالبًا ما تواجه أسئلة مثل: "أي نموذج يجب أن أستخدم؟" و"كيف يجب أن أختار كمستخدم؟"
وفي دراسة نشرت هذا العام،توصل فريقنا إلى أن حيرة نموذج لغة البروتين لتسلسل الهدف يمكن أن تعكس دقته تقريبًا في مهمة التنبؤ بالطفرة.تكمن ميزة هذا النموذج في قدرته على تقديم تقدير للأداء دون الحاجة إلى أي بيانات عن طفرة البروتين المستهدف. وتحديدًا، كلما قلّت درجة الحيرة، كان فهم النموذج للتسلسل أفضل، مما يعني غالبًا أن تنبؤاته بالطفرات في ذلك التسلسل ستكون أكثر دقة.
بناءً على هذه الفكرة، طوّرنا نموذجًا تجميعيًا يُسمى VenusEEM. يُوزّن هذا النموذج النماذج بناءً على درجة الحيرة، أو يختار مباشرةً النموذج الأقل حيرة. يُحسّن هذا دقة التنبؤ بالطفرات إلى مستوى عالٍ. وبغض النظر عن الاستراتيجية المُتبعة، تبقى النتيجة النهائية للتنبؤ مستقرة نسبيًا، مما يمنع انخفاضًا كبيرًا في الأداء نتيجةً لاختيار نموذج غير صحيح.
* عنوان الورقة:يو ي، جيانغ ف، تشونغ ب، وآخرون. اختيار نموذج التعلم العميق المُدار بالإنتروبيا للبروتينات الفيروسية [م]. مجلة المراجعة الفيزيائية للأبحاث، 2025، 7(1): 013229.
أخيرًا، في إطار بحث "التسلسل إلى الوظيفة"، بالإضافة إلى النماذج المذكورة سابقًا، طوّر فريقنا العام الماضي نموذجًا جديدًا لتصميم الطفرات التكرارية عالية الموقع، PRIME. على وجه التحديد، قمنا أولًا بتدريب نموذج لغة بروتينية كبير مسبقًا على 98 مليون تسلسل بروتيني. لمهمة التنبؤ بالطفرات عالية الموقع، حصلنا أولًا على بيانات الطفرات منخفضة الموقع وأدخلناها في نموذج لغة البروتين، وترميزناها في متجه دالة. بناءً على هذا المتجه، دربنا بعد ذلك نموذج انحدار للتنبؤ بالطفرات عالية الموقع.ومن خلال هذا التفاعل التكراري، يمكن تطوير منتج بروتيني ممتاز في جولتين أو ثلاث جولات فقط من التجارب.
* عنوان الورقةجيانغ ف، لي م، دونغ ج، وآخرون. نموذج لغوي عام موجه بدرجة الحرارة لتصميم بروتينات ذات استقرار ونشاط معززين [م]. التقدم العلمي، ٢٠٢٤، ١٠(٤٨): eadr2641.

「الوظيفة→التسلسل」
ما ناقشناه سابقًا يتعلق بالتسلسل إلى الدالة. لنفكر فيما إذا كان بإمكاننا استنتاج التسلسل من الدالة عكسيًا؟
هناك مشكلةٌ أماميةٌ وعكسيةٌ بين المتتاليات والدوال. فبينما تتعلق المشكلة الأمامية بإيجاد إجابةٍ حاسمة، تتضمن المشكلة العكسية البحث عن حلٍّ قابلٍ للحل ضمن مساحةٍ واسعةٍ ممكنة. ويُعدّ توليد المتتاليات من الدوال هذه المشكلة العكسية تحديدًا. ويرجع ذلك إلى أن المتتاليات عادةً ما تتوافق مع دالةٍ واحدةٍ أو بضع دالاتٍ فقط، بينما يمكن تنفيذ دالةٍ واحدةٍ باستخدام مجموعةٍ متنوعةٍ من المتتاليات المختلفة تمامًا. علاوةً على ذلك، لا يوجد معيارٌ موثوقٌ للمشكلة العكسية. فعندما يُولّد نموذجٌ متتالياتٍ من دالةٍ معينة، لا يُمكن عادةً اختبار دقته إلا تجريبيًا.

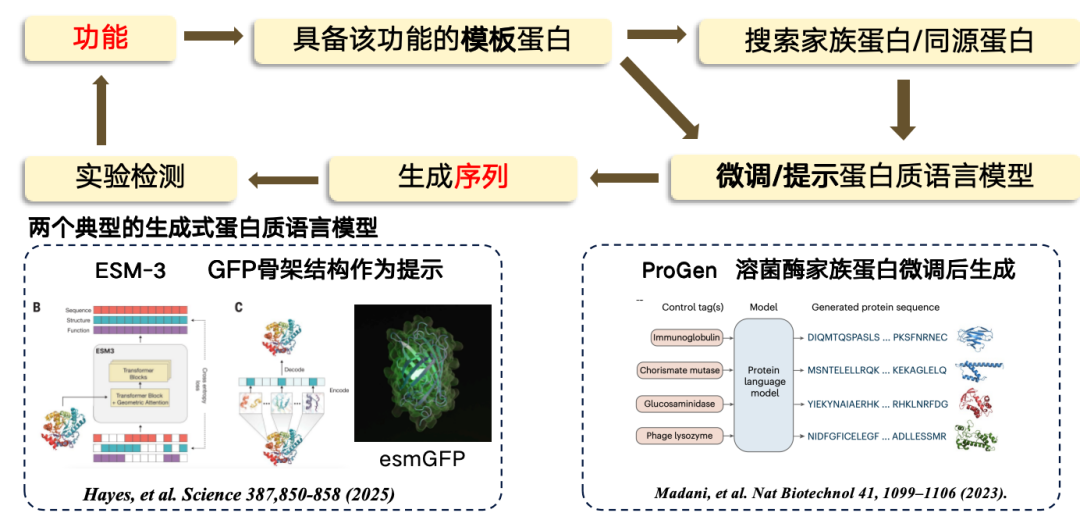
وفي الدراسة الحالية،يعتمد التصميم من الوظيفة إلى التسلسل في الغالب على نهج قائم على القالب. إذا عُرف أن لبروتين القالب وظيفة محددة، فيمكن استخدامه كأساس لإيجاد أو إنشاء منطقة جديدة.وتتمثل العملية في الانتقال أولاً من الوظيفة إلى تسلسل القالب، ثم البحث عن بعض البروتينات العائلية/البروتينات المتجانسة من بروتين القالب، ثم ضبط نموذج لغة البروتين، واستخدام نموذج اللغة المضبوط بدقة لتوليد مناطق تسلسل جديدة، وأخيرًا إجراء الاختبارات التجريبية.
حاليًا، يتضمن نموذجا اللغة البروتينية التوليدية الأكثر تمثيلًا ما يلي:
*ESM-3، تم إنتاجه باستخدام البروتين الفلوري الأخضر (GFP) كقالب، ولكن البروتين الناتج أقل وظيفية.
* ProGen هو نموذج لغوي انحداري بحت، يشبه ChatGPT، ويمكن توليده بناءً على إشارات وظيفية. يتم توليده عن طريق ضبط بنية بروتين الليزوزيم بدقة.
بالإضافة إلى توليد تسلسلات بروتينية جديدة بشكل مباشر،يمكنك أيضًا البحث مباشرةً من الكمية الهائلة من تسلسلات البروتين الموجودة.يُرمَّز البروتين القالب في فضاء عالي الأبعاد، وتُحدِّد المسافة بين المتجهات ما إذا كان للبروتينين نفس الوظيفة. وأخيرًا، تُستخرَج النتائج من قاعدة بيانات. يكمن مبدأ هذا النهج في أن المسافة بين ترميزات أو متجهات بروتينين في فضاء عالي الأبعاد تعكس تقريبًا ما إذا كان للبروتينين وظائف متشابهة.
يوضح الشكل أدناه مثالين نموذجيين لتعدين نماذج لغة البروتين. الأول هو ESM-Ezy، الذي طورته جامعة ويستليك، والذي يستخدم نموذج ESM-1b لإجراء عمليات بحث متجهية وتعدين تعبيرات متعددة لملء الفراغات. أما الثاني فهو نموذج VenusMine واسع النطاق، الذي يستخدم هيدروليزات PET عالية الكفاءة.
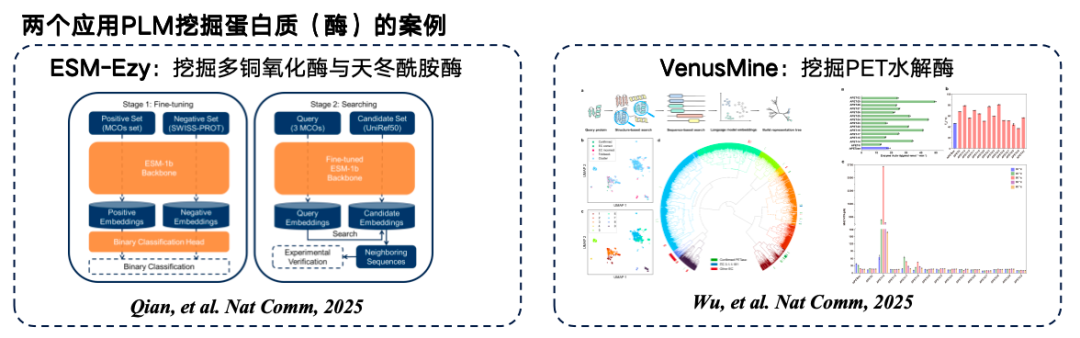
* عنوان الورقةوو ب، تشونغ ب، تشنغ ل، وآخرون. تسخير نموذج لغة البروتين لاكتشاف هيدروليزات PET عالية الكفاءة والمتانة، استنادًا إلى البنية [مجلة]. نيتشر كوميونيكيشنز، ٢٠٢٥، ١٦(١): ٦٢١١.
بالإضافة إلى "الوظيفة → التسلسل"، يمكنك أيضًا إضافة "وسيط" بين الوظيفة والتسلسل:
* عندما يتم استخدام البنية كوسيط: يتم استنتاج بنية البروتين على أساس الوظيفة (أدوات شائعة مثل RFdiffusion)، ثم يتم إدخال البنية الناتجة في نموذج لغة طي البروتين العكسي (مثل ProteinMPNN) لتوليد التسلسل أخيرًا.
عند استخدام اللغة الطبيعية كوسيلة: على سبيل المثال، تُوَحِّد الطريقة الموضحة في ورقة البحث "إطار عمل تصميم بروتين موجه نصيًا" اللغة الطبيعية وتسلسلات البروتين في فضاء عالي المستوى من خلال التعلم المقارن. بعد ذلك، يُمكن توليد تسلسل بروتين مباشرةً في هذا الفضاء عالي المستوى باستخدام توجيه اللغة الطبيعية.
التسلسل → الهيكل
فيما يتعلق بتسلسل البنية، يُعدّ نموذج AlphaFold بلا شك النموذج الأكثر شيوعًا. فلماذا لا نزال بحاجة إلى نماذج لغة البروتين للتنبؤ بالبنية؟السبب الرئيسي هو السرعة.
السبب الرئيسي لبطء AlphaFold هو اعتماد بحثه MSA (محاذاة التسلسلات المتعددة) على وحدة المعالجة المركزية للبحث في قواعد البيانات الكبيرة. مع إمكانية تسريع وحدة معالجة الرسومات، إلا أن التسريع الفعلي أبطأ. ثانيًا، يتطلب AlphaFold أيضًا مطابقة القالب أثناء عملية الطي، مما يستهلك أيضًا وقتًا طويلاً. يمكن أن يُسرّع استبدال هاتين الوحدتين بنموذج لغة البروتين عملية التنبؤ بالبنية بشكل كبير. مع ذلك، ووفقًا لبحث منشور حاليًا، لا تزال دقة التنبؤ بالبنية المستندة إلى نماذج لغة البروتين أقل عمومًا من دقة نموذج AlphaFold في معظم مقاييس التقييم.
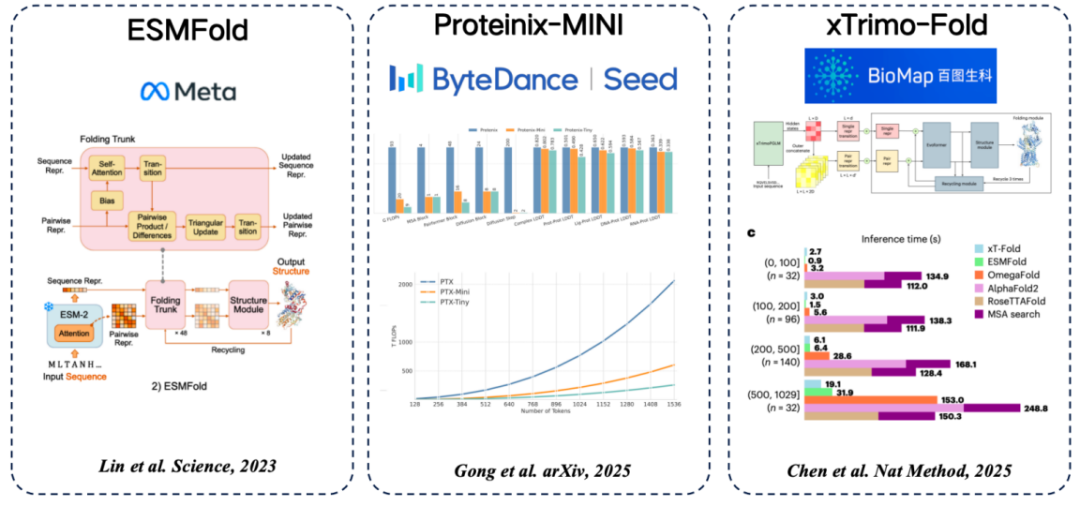
هناك العديد من نماذج لغة البروتين الشائعة من التسلسل إلى البنية.تم اعتماد الفكرة الشائعة لاستخدام الميزات المستخرجة من نماذج لغة البروتين لتحل محل MSA:
* ESMFold (Meta): الطريقة الأولى للتنبؤ المباشر ببنية البروتين باستخدام نموذج لغة البروتين، وتحقيق دقة عالية دون الاعتماد على بحث MSA.
* Proteinix-MINI (ByteDance): يستخدم نموذج لغة البروتين بدلاً من MSA، والذي يحقق أيضًا نتائج سريعة جدًا ولديه دقة تنبؤ قريبة من نموذج AlphaFold 3.
* xTrimo-Fold (Baidu Biosciences): يستخدم ميزات نموذج 100 مليار معلمة بدلاً من MSA، مما يؤدي إلى تسريع عملية البحث.
الهيكل → التسلسل
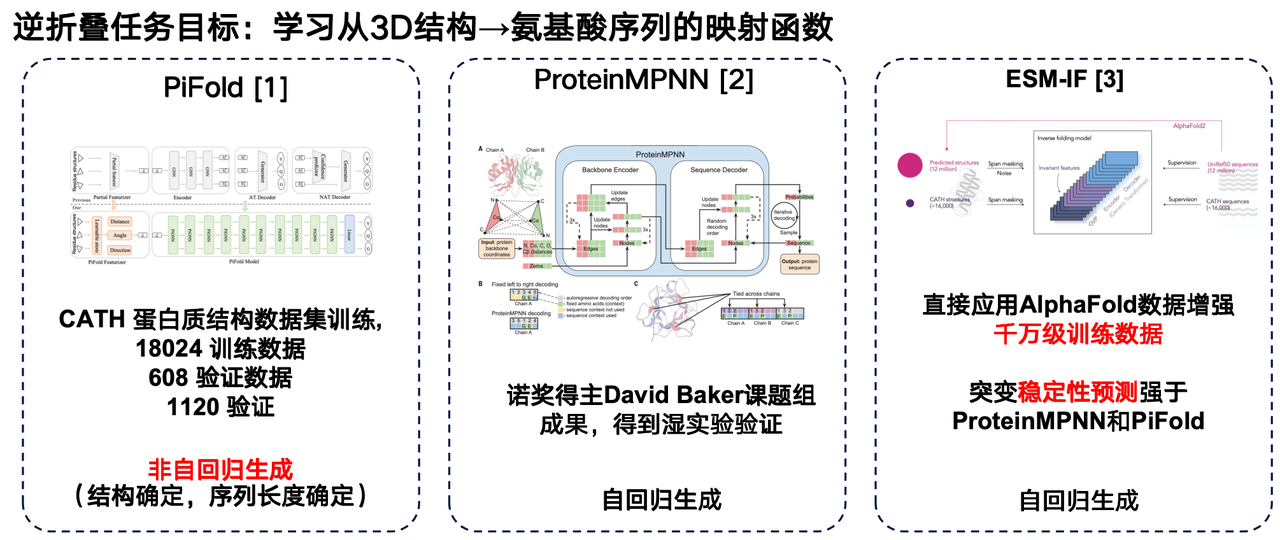
تم تصميم البنية بناءً على وظائف معروفة، ولكن كيف يمكن تصنيعها في المختبر؟ويجب علينا أيضًا تحويله إلى سلسلة من الأحماض الأمينية، وهو ما يسمى "نموذج اللغة القابل للطي العكسي" الذي ذكرناه سابقًا.
يمكن اعتبار نموذج اللغة للطي العكسي بمثابة "المشكلة العكسية" لـ AlphaFold. فعلى عكس AlphaFold، الذي يتنبأ بالبنية ثلاثية الأبعاد من تسلسلات الأحماض الأمينية، يهدف نموذج الطي العكسي إلى تعلم دالة ربط بين البنية ثلاثية الأبعاد للبروتين وتسلسل أحماضه الأمينية.
أودُّ مُشاركةَ بعضِ أعمالي في هذا المجال: العملُ الأولُ هو نموذجُ PiFold من فريقِ البحثِ بجامعةِ ويستليك. ومن أهمِّ ابتكاراتِه استخدامُ طريقةِ التوليدِ غيرِ الانحدارية.
النموذج الثاني هو ProteinMPNN، الذي طورته مجموعة ديفيد بيكر البحثية. يُعد هذا النموذج أحد أكثر نماذج الطي العكسي استخدامًا، إذ يستخدم توليد الانحدار الذاتي لتشفير هياكل البروتين الفردية عبر الشبكات العصبية البيانية، ثم توليد تسلسلات الأحماض الأمينية واحدًا تلو الآخر.
يُعد نموذج ESM-IF من Meta تقدمًا هامًا أيضًا. يكمن أبرز ما يميزه في الاستفادة من البيانات الهيكلية الضخمة التي تنبأ بها AlphaFold للتنبؤ بشكل موحد بالهياكل ثلاثية الأبعاد المقابلة لعشرات الملايين من تسلسلات البروتين، مما يُمكّن من بناء مجموعة تدريب ضخمة للغاية. تصل بيانات تدريب ESM-IF إلى عشرات الملايين من الوحدات، ويتجاوز عدد المعلمات في النموذج 100 مليون. وبناءً على ذلك، لا يقتصر دور النموذج على أداء مهام الطي العكسي فحسب، بل يُظهر أيضًا أداءً قويًا في التنبؤ باستقرار الطفرات.
طرق متعددة لتعزيز نماذج لغة البروتين
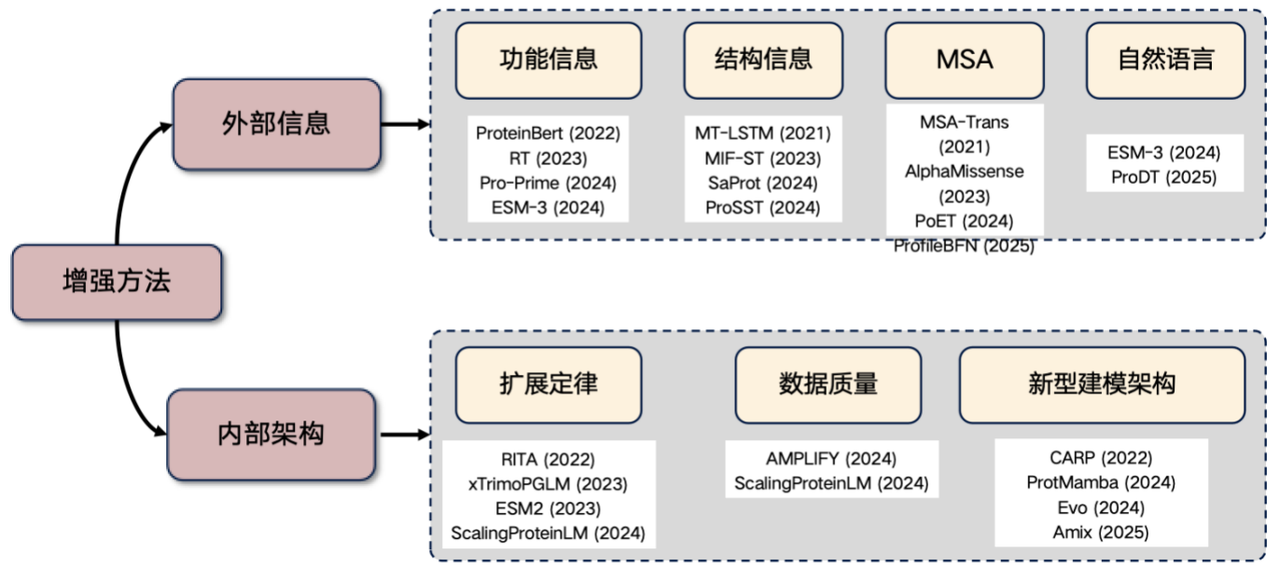
أخيرًا، دعوني أضيف اتجاهًا بحثيًا شائعًا جدًا حاليًا، وهو تحسين نموذج لغة البروتين. إذا كنتم تخططون لإجراء بحث في هذا المجال، يمكنكم الانطلاق من الأفكار التالية:تقديم المعلومات الخارجية وتحسين البنية الداخلية.
1. تقديم المعلومات الخارجية
* معلومات وظيفية: على سبيل المثال، إدخال خصائص مثل درجة الحرارة ودرجة الحموضة في المحول. يمكن دمج هذه المعلومات في مدخلات النموذج بشكل صريح أو من خلال إجراءات مكتسبة لتحسين أداء نموذج لغة البروتين.
* المعلومات البنيوية: تقديم معلومات عن البنية ثلاثية الأبعاد أو التسلسل البنيوي.
* معلومات محاذاة التسلسلات المتعددة (MSA): تُعد محاذاة التسلسلات المتعددة (MSA) نوعًا مفيدًا جدًا من المعلومات. فإدخالها في نموذج اللغة غالبًا ما يُحسّن الأداء بشكل ملحوظ.
* المعلومات باللغة الطبيعية: في السنوات الأخيرة، حاولت بعض الدراسات دمج المعلومات باللغة الطبيعية، ولكن هذا الاتجاه لا يزال قيد الاستكشاف.
2. تحسين البنية الداخلية
* قانون التوسع: يتم تحقيق تحسين الأداء عن طريق زيادة عدد معلمات النموذج وحجم بيانات التدريب بشكل كبير.
* تحسين جودة البيانات: تقليل الضوضاء في البيانات وتحسين الدقة.
* استكشاف هياكل معمارية جديدة: مثل هياكل CARP، وProtMamba، وEvo.
في السنوات الأخيرة، أصبح استخدام معلومات بنية البروتين لتحسين أداء النموذج اتجاهًا بحثيًا ساخنًا.
من أوائل الدراسات التمثيلية ورقة بحثية نُشرت عام ٢٠٢١ بعنوان "تعلم لغة البروتين: التطور، البنية، والوظيفة"، والتي أوضحت كيفية استخدام المعلومات البنيوية لتعزيز قدرات نماذج لغة البروتين. لاحقًا، اقترح نموذج SaProt نهجًا ذكيًا: فهو يربط مفردات الأحماض الأمينية للبروتين مع ٢٠ مفردات بنية افتراضية مُولّدة بواسطة Foldseek لهياكل البروتين، مما أدى في النهاية إلى توليد مفردات مجمعة من ٤٠٠ كلمة (٢٠ × ٢٠). استُخدمت هذه المفردات لتدريب نموذج لغة مُقنّع، محققةً دقة ممتازة.
قام فريقنا أيضًا بتدريب نموذج تدريب مسبق متعدد الوسائط ProSST بشكل مستقل لتسلسل البروتين وبنيته. يحقق هذا النموذج تمثيلًا منفصلًا للمعلومات البنيوية عن طريق تحويل البنية المستمرة للبروتين إلى رموز منفصلة (2048 رمزًا مختلفًا).
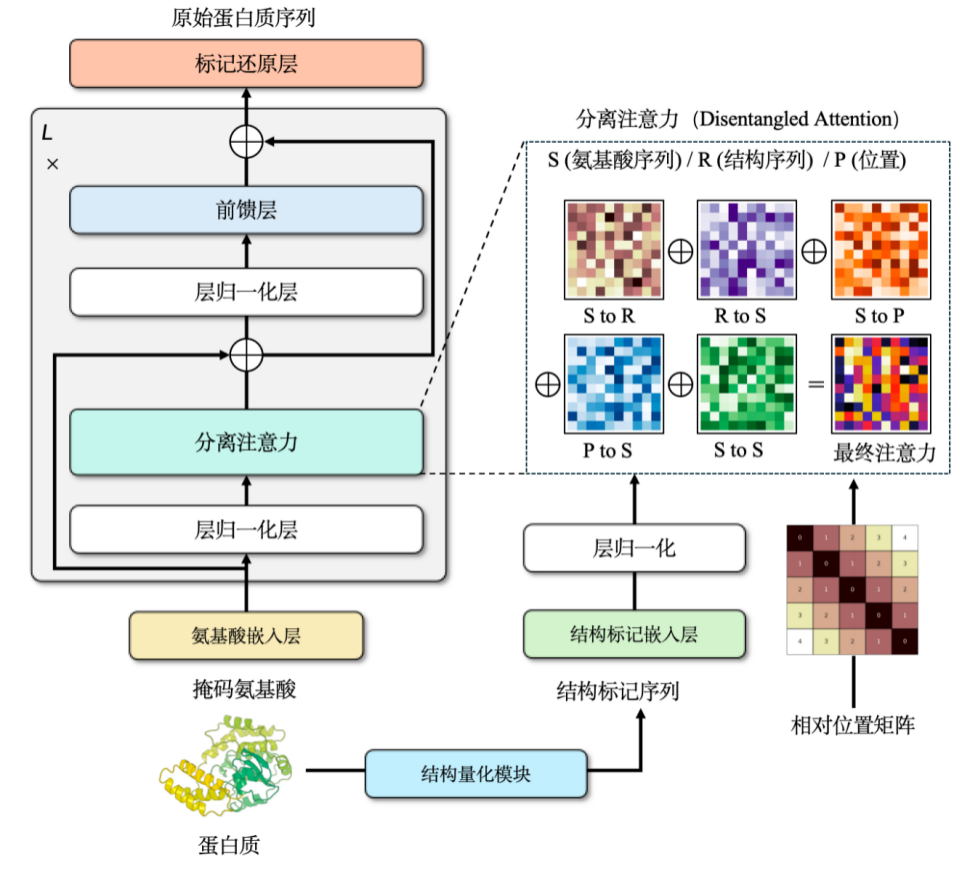
يُمكن أن يُحسّن دمج المعلومات الهيكلية في نماذج لغة البروتين أداء النموذج بشكل ملحوظ. ومع ذلك، قد تظهر مشكلة أثناء هذه العملية: إذا استُخدمت بيانات الهيكلية التي يتنبأ بها AlphaFold مباشرةً للتدريب، بينما يتناقص فقدان البيانات في مجموعة التدريب تدريجيًا، يزداد فقدان البيانات في مجموعة التحقق أو الاختبار تدريجيًا.المفتاح لحل هذه المشكلة هو تنظيم المعلومات البنيوية.وبعبارات بسيطة، فإن ذلك يعني تبسيط البيانات المعقدة لجعلها أكثر ملاءمة لمعالجة النماذج.
عادةً ما تُمثَّل هياكل البروتينات كإحداثيات متصلة في فضاء ثلاثي الأبعاد. ويتطلب ذلك تبسيطًا بتحويلها إلى تسلسلات منفصلة من الأعداد الصحيحة. ولتحقيق ذلك، استخدمنا بنية شبكة عصبية بيانية ودربناها باستخدام مُرمِّز مُزيل للضوضاء، لنتمكن في النهاية من بناء مفردات هياكل منفصلة تضم حوالي 2048 رمزًا.
مع المعلومات البنيوية والتسلسلية،لقد اخترنا آلية الاهتمام المتبادل للجمع بين الاثنين.هذا يسمح لنموذج المحول المُعدَّل بإدخال كلٍّ من تسلسلات الأحماض الأمينية والتسلسلات البنيوية. خلال مرحلة ما قبل التدريب، صُمِّم هذا النموذج كمهمة تطوير نموذج لغوي.تحتوي بيانات التدريب على أكثر من 18.8 مليون بنية بروتينية عالية الجودة بحجم معلمة يبلغ حوالي 110 مليون.حقق النموذج نتائج متطورة في ذلك الوقت، وعلى الرغم من أنه تم تجاوزه منذ ذلك الحين بواسطة نماذج أحدث، إلا أنه لا يزال يحمل أفضل النتائج لفئته في وقت نشره.
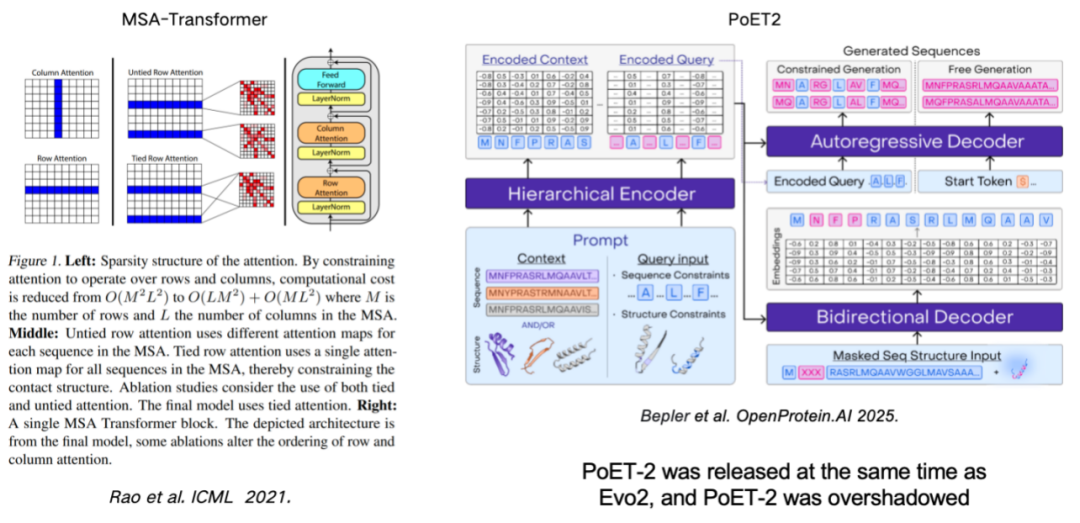
إن استخدام MSA (محاذاة التسلسلات المتعددة) لتحسين نموذج لغة البروتين يعد أيضًا وسيلة مهمة لتحسين أداء النموذج.يعود هذا العمل إلى مُحوِّل MSA، الذي دمج معلومات MSA بفعالية في النموذج من خلال إدخال قواعد الصفوف والأعمدة. يستخدم نموذج PoET2، الذي صدر مؤخرًا، مُشفِّرًا هرميًا لمعالجة معلومات MSA ودمجها في بنية نموذجية كاملة. بعد تدريب واسع النطاق، أظهر أداءً متميزًا.
قانون التوسع: هل النموذج الأكبر دائمًا أكثر قوة؟
نشأ ما يُسمى بقانون التدرج في مجال معالجة اللغة الطبيعية. وهو يكشف عن قانون عالمي:سيستمر أداء النموذج في التحسن مع زيادة مقياس المعلمات وحجم بيانات التدريب وموارد الحوسبة.
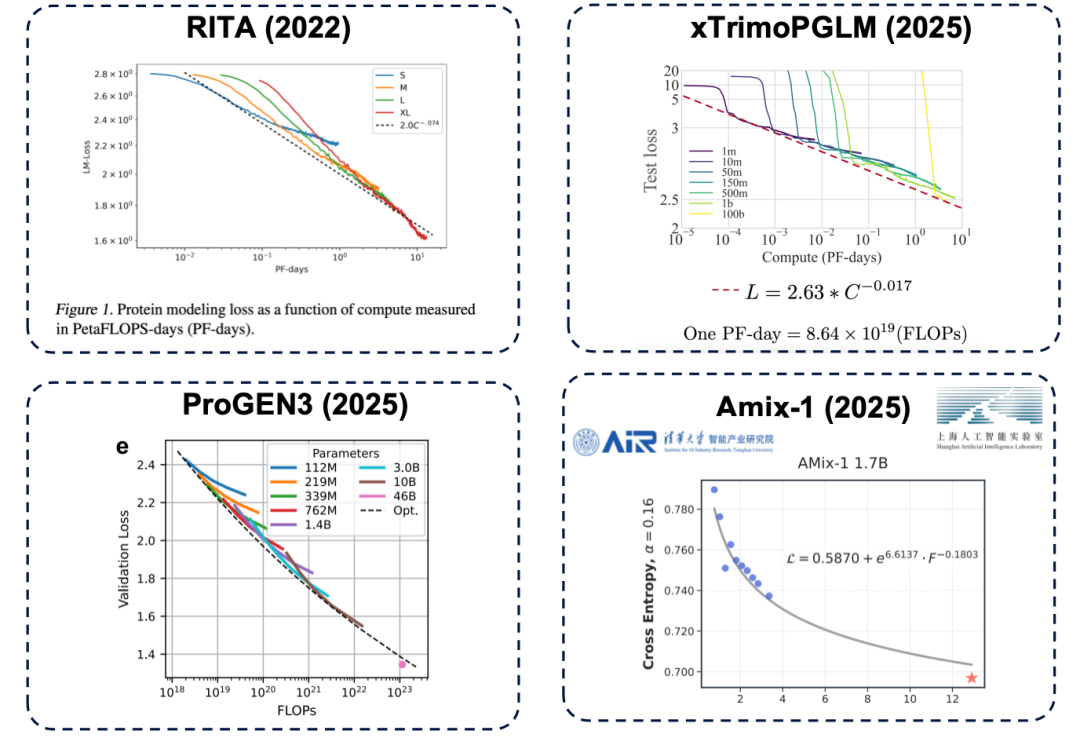
يُعد حجم المعلمات عاملاً أساسياً في تحديد الحد الأقصى لأداء النموذج. فإذا كان عدد المعلمات غير كافٍ، حتى مع استثمار المزيد من موارد الحوسبة (بعبارة أبسط، "إنفاق المزيد من المال")، سيصل أداء النموذج إلى نقطة ضعف. ينطبق هذا المبدأ نفسه أيضاً على نماذج لغة البروتين، وقد أكدته العديد من الدراسات، بما في ذلك أعمال نموذجية مثل RITA وxTrimoPGLM وProGEN3 وAmix-1.
* نموذج RITA: تم تطويره من قبل جامعة أكسفورد وكلية الطب بجامعة هارفارد وLightOn AI.
* نموذج xTrimoPGLM: تم تطويره بواسطة فريق Baitu Bioscience، وهو يقيس معلمات النموذج إلى ما يقرب من 100 مليار.
* نموذج ProGEN3: تم تطويره بواسطة فريق Profluent Biotech.
* نموذج Amix-1: تم اقتراحه من قبل معهد الصناعات الذكية بجامعة تسينغهوا ومختبر الذكاء الاصطناعي في شنغهاي، ويستخدم بنية شبكة مطابقة التدفق البايزية ولديه أيضًا قانون توسع.
يشير "قانون التدرج" الذي ذكرناه سابقًا إلى عملية ما قبل التدريب. ومع ذلك، في أبحاث البروتينات، نركز في المقام الأول على أداء المهام اللاحقة. وهذا يثير السؤال التالي:هل يساعد تحسين الأداء قبل التدريب بالضرورة في أداء المهام اللاحقة؟
وفي تقييم xTrimoPGLM، وجد فريق البحث أنه في حوالي 44% من المهام اللاحقة، هناك بالفعل ارتباط إيجابي بين "أداء ما قبل التدريب الأفضل والأداء الأقوى في المصب".
في الوقت نفسه، أظهر نموذج Amix-1 قدرةً ناشئةً في مهام التنبؤ بالبنية. يشير هذا إلى المهام التي يعجز فيها نموذج صغير تمامًا عن حل المشكلة، ولكن الأداء يتحسن فجأةً وبشكل ملحوظ عندما يتجاوز حجم معاملات النموذج نقطةً حرجةً معينة. في هذه التجربة، برزت هذه الظاهرة بشكلٍ خاص في مهام التنبؤ بالبنية، حيث أظهر تحسن الأداء "خطًا أحمرًا حادًا" عندما يتجاوز حجم المعاملات النقطة الحرجة.
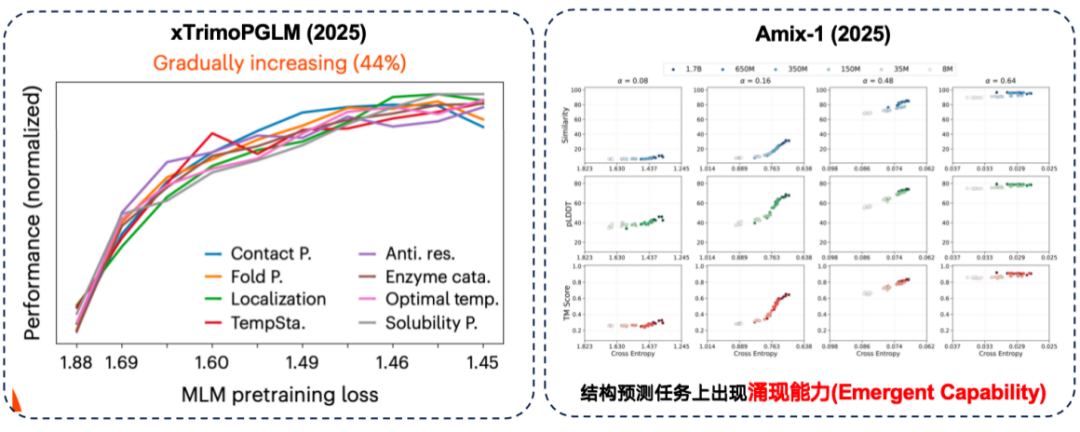
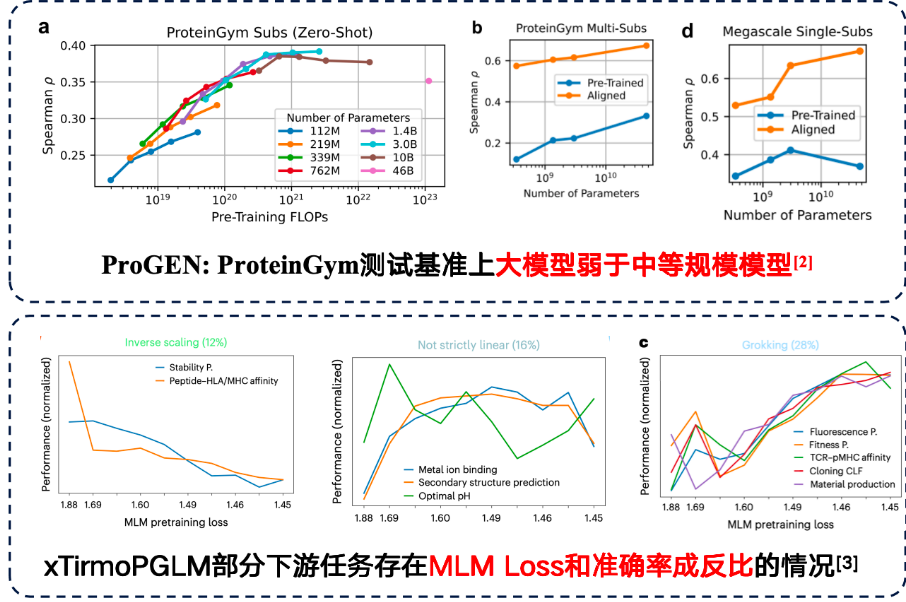
على الرغم من أنه في بعض المهام، يمكن للنماذج الكبيرة بالفعل تحقيق أداء أفضل في المراحل اللاحقة.ومع ذلك، اكتشفت المهام اللاحقة أيضًا قانونًا عكسيًا للتوسع.وهذا يعني أنه كلما كان النموذج أصغر، كلما كان الأداء أفضل.
أظهرت الدراسات أن مجرد زيادة عدد معلمات النموذج لا يُحسّن النتائج عندما تكون بيانات التدريب نفسها عالية الضوضاء، لذا ينبغي إيلاء جودة البيانات اهتمامًا أكبر. في مهمة التنبؤ بطفرات البروتين على معيار ProteinGym، كان أداء النماذج متوسطة الحجم أفضل من حيث الدقة. علاوة على ذلك، اكتشف الفريق المُطوّر لـ xTirmoPGLM أيضًا بعض حالات الارتباط غير الإيجابي، حيث لم يتطابق أداء ما قبل التدريب مع أداء المهمة اللاحقة.
النمذجة الجينومية: من تصميم الحمض النووي إلى تحسين إنتاج البروتين
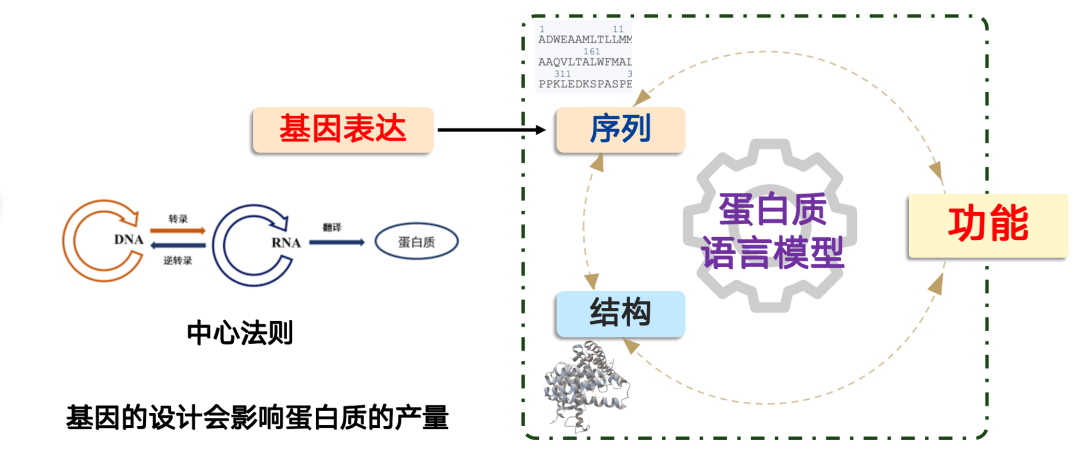
المشكلة التي يحلها نموذج الجينوم هي: كيف ننتج البروتين؟
في علم الأحياء الاصطناعي،إن إنتاج البروتين يتبع العقيدة المركزية لعلم الأحياء الجزيئي: "DNA → RNA → البروتين".في الخلايا، يتحكم جسم الخلية بهذه العملية، ويمكننا إكمالها بتصميم الجينات. لكن السر يكمن في أن تصميم الجينات يؤثر مباشرةً على إنتاج البروتين.
في التطبيقات العملية، غالبًا ما نواجه حالات يكون فيها أداء البروتين الوظيفي ممتازًا، ولكن بسبب ضعف تصميمه الجيني، يكون مستوى تعبيره منخفضًا للغاية، مما لا يلبي احتياجات التصنيع أو التطبيقات واسعة النطاق. في هذه الحالة، يمكن لنماذج الذكاء الاصطناعي أن تلعب دورًا مهمًا.
تتمثل مهمة نموذج الذكاء الاصطناعي في استنباط كيفية تصميم تسلسلات الحمض النووي مباشرةً من تسلسلات البروتين وزيادة إنتاجها. يعتمد نموذج ProDMM الذي اقترحه فريقنا على استراتيجية تدريب مسبق، ويتكون من مرحلتين:
في المرحلة الأولى، يُستخدم التدريب المسبق المشترك لتعلم تمثيلات البروتينات والحمض النووي. تتضمن المدخلات تسلسلات البروتين والحمض النووي، ويُدرَّب نموذج لغوي باستخدام بنية المحول. الهدف هو تعلم تمثيلات تسلسلات البروتين والكودون والحمض النووي في آنٍ واحد. في المرحلة الثانية، تُدرَّب المهام التوليدية على المهام اللاحقة، مثل الانتقال من البروتين إلى تسلسل الترميز (CDS). عند إعطاء بروتين، يمكن توليد تسلسل الحمض النووي.
* عنوان الورقة:لي م، رين ي، يي ب، وآخرون. تسخير نمذجة تسلسلية موحدة متعددة الوسائط للكشف عن الترابط بين البروتين والحمض النووي [مجلة]. bioRxiv، 2025: 2025.02. 26.640480.
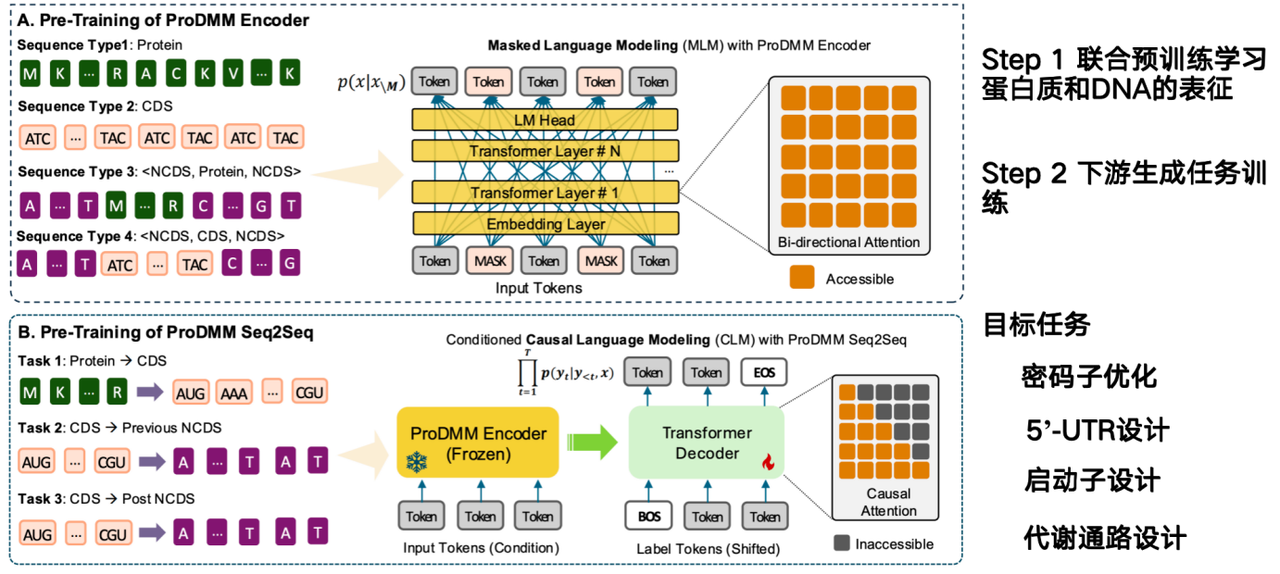
الهدف من المشروع من الكودونات إلى الحمض النووي غير المشفر (NCDS) هو استكمال تحسين الكودونات، وتصميم 5'-UTR، وتصميم المحفز، وتصميم المسار الأيضي.
يتضمن تصميم المسار الأيضي العمل المنسق لبروتينات متعددة داخل جين واحد لتخليق منتج محدد. نحتاج إلى تحسين نواتج المسار الأيضي بأكمله، وهي مهمة فريدة تناسب النماذج الجينومية، إذ تعمل نماذج البروتين على تحسين بروتين واحد فقط، وهي مستقلة عن السياق. ومع ذلك، فإن التحدي الأكبر الذي يواجه النماذج الجينومية هو حاجتها إلى مراعاة العلاقات المتبادلة داخل البيئة الخلوية، وهو التحدي الأكبر الذي تواجهه حاليًا.
حول الدكتور لي مينغشن
المتحدث الضيف في هذه الجلسة التشاركية هو لي مينغ تشن، زميل ما بعد الدكتوراه في مجموعة هونغ ليانغ البحثية بمعهد العلوم الطبيعية بجامعة شنغهاي جياو تونغ. حصل على درجة الدكتوراه في هندسة علوم وتكنولوجيا الحاسوب، وبكالوريوس العلوم في الرياضيات من جامعة شرق الصين للعلوم والتكنولوجيا. يتركز اهتمامه البحثي الرئيسي على تدريب نماذج لغة البروتين مسبقًا وضبطها.
فاز بلقب خريج شنغهاي المتميز، والمنحة الوطنية، والميدالية الذهبية لقسم شنغهاي في مسابقة "إنترنت+" للابتكار وريادة الأعمال لطلاب الجامعات. نشر ما مجموعه 10 أوراق بحثية في مجال علوم الحاسوب، بصفته المؤلف الأول/المؤلف المشارك/المؤلف المراسل، في مجلات ومؤتمرات علمية محكمة مثل NeurIPS، وScience Advances، وJournal of Cheminformatics، وPhysical Review Research، وشارك في نشر 10 أوراق بحثية في مجال علوم الحاسوب.
احصل على أوراق بحثية عالية الجودة ومقالات تفسيرية متعمقة في مجال AI4S من عام 2023 إلى عام 2024 بنقرة واحدة⬇️









