Command Palette
Search for a command to run...
البرنامج التعليمي عبر الإنترنت 丨Niangniang Shiji يتحول على الفور إلى "فتاة سيتشوان وتشونغتشينغ"؟ يحقق برنامج Step-Audio-TTS استنساخ الصوت/توليف الموسيقى/توليف الكلام ثلاثة في واحد

لا يزال الحماس العالمي الذي أحدثته تقنية DeepSeek مفتوحة المصدر موجودًا. في الآونة الأخيرة، قامت شركة Step Star ومجموعة Geely Auto Group مرة أخرى بالتحرك وفتحت المصدر لنموذج Step-Audio-TTS-3B، والذي أثار مرة أخرى نقاشًا واسع النطاق في الصناعة.
كان ياما كان،إن تنوع وتعقيد بيانات اللهجة والطلب الكبير على تعميم النموذج يجعل نموذج استنساخ الصوت يعمل بشكل ضعيف على اللهجات.يمكن لجهاز Step-Audio-TTS-3B تفسير خصائص اللغات المحلية بشكل واضح. يتم تدريبه على أساس مجموعة البيانات التركيبية واسعة النطاق لنموذج LLM-Chat، ولديه نظرة عميقة في بنية اللغة. إنه قادر على استيعاب التغييرات الدقيقة في اللغة من بين السطور. سواء كانت لهجة سيتشوان العاطفية أو اللهجة الكانتونية ذات التسعة والستة نغمات، فإنها قادرة على التقاط إيقاعها ونبرتها بدقة، مما يوضح العادات المحلية القوية.
ليس هذا فحسب، بل إنه أيضًا أول نموذج TTS يحقق توليد RAP والهمهمة، مما يملأ الفجوة في تركيب الكلام الموسيقي. في الماضي، كان إنشاء محتوى راب إيقاعي يتطلب مغنين محترفين. الآن، بمساعدة Step-Audio-TTS-3B، يمكن للمستخدمين إنشاء صوت RAP بسرعة بإيقاع دقيق وتدفق سلس، مما يلهم إمكانيات لا حصر لها.
حاليًا، تم إطلاق "نموذج توليد الكلام باللهجة على مستوى الإنتاج Step-Audio-TTS-3B" في قسم "البرنامج التعليمي" على الموقع الرسمي لشركة HyperAI.يتضمن هذا البرنامج التعليمي ثلاث وظائف: توليف الكلام، وتوليف الموسيقى، واستنساخ الصوت. تعال وجربها بنفسك~
عنوان البرنامج التعليمي:
تشغيل تجريبي
1. قم بتسجيل الدخول إلى hyper.ai، في صفحة البرنامج التعليمي، حدد Step-Audio-TTS-3B Production-Level Dialect Speech Generation Model، ثم انقر فوق تشغيل هذا البرنامج التعليمي عبر الإنترنت.
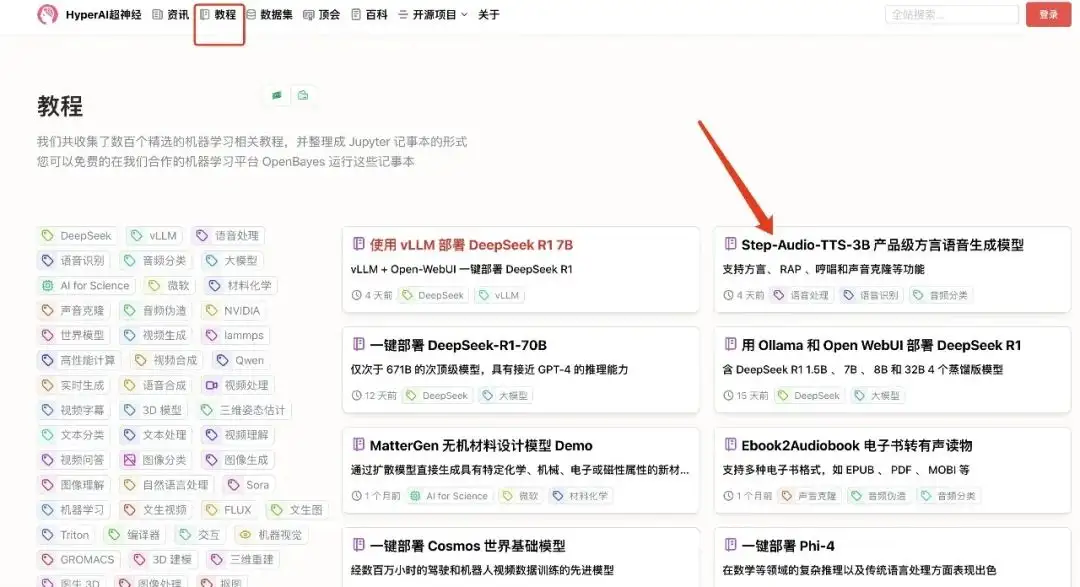
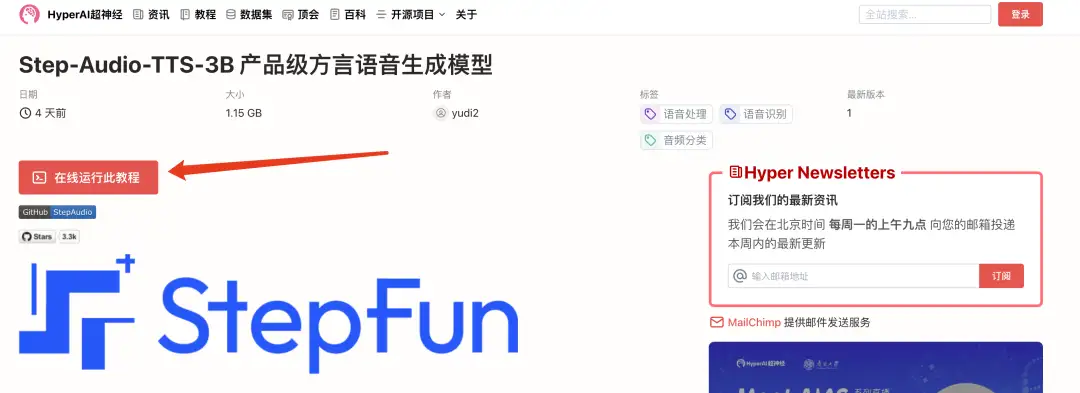
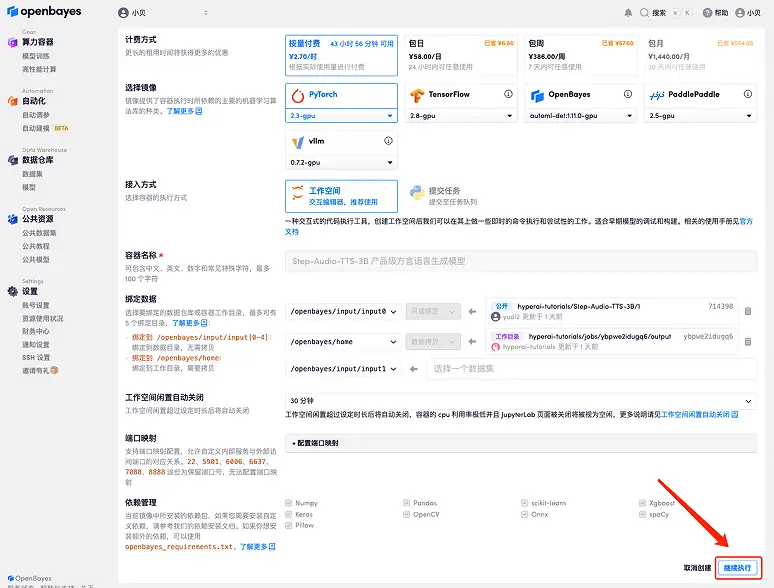
2. بعد الانتقال إلى الصفحة التالية، انقر فوق "استنساخ" في الزاوية اليمنى العليا لاستنساخ البرنامج التعليمي في الحاوية الخاصة بك.
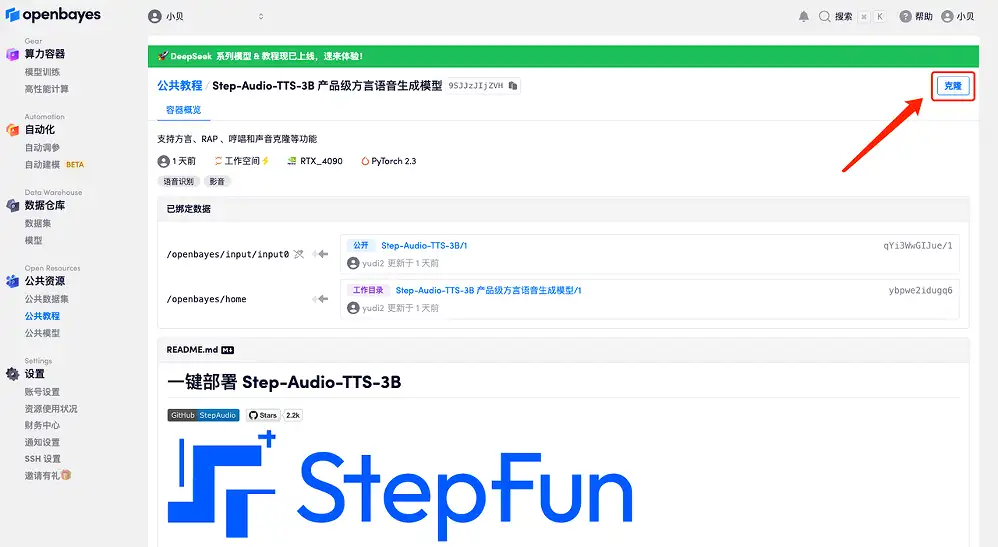
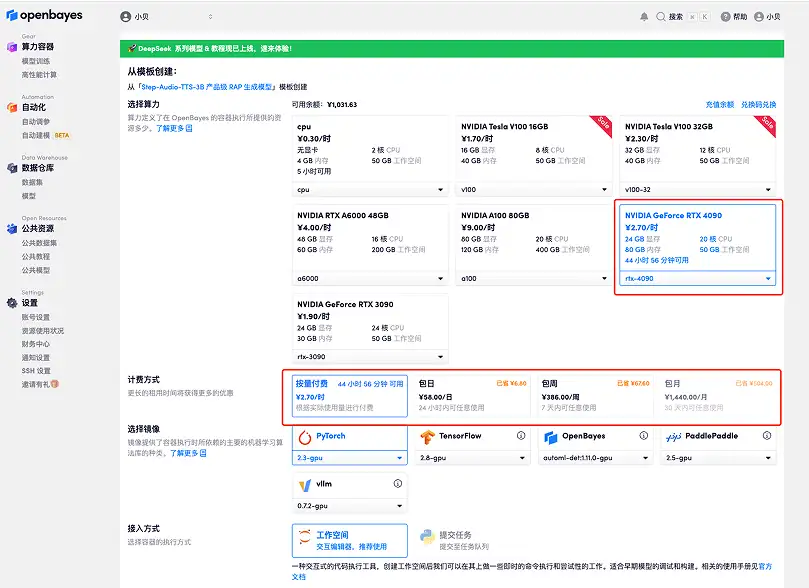
3. حدد الصور "NVIDIA RTX A6000" و"PyTorch". أطلقت منصة OpenBayes طريقة فوترة جديدة. يمكنك اختيار "الدفع حسب الاستخدام" أو "الباقة اليومية/الأسبوعية/الشهرية" وفقًا لاحتياجاتك. انقر فوق "متابعة". يمكن للمستخدمين الجدد التسجيل باستخدام رابط الدعوة أدناه للحصول على 4 ساعات من RTX 4090 + 5 ساعات من وقت فراغ وحدة المعالجة المركزية!
رابط دعوة حصرية لـ HyperAI (انسخ وافتح في المتصفح):
https://openbayes.com/console/signup?r=Ada0322_QZy7
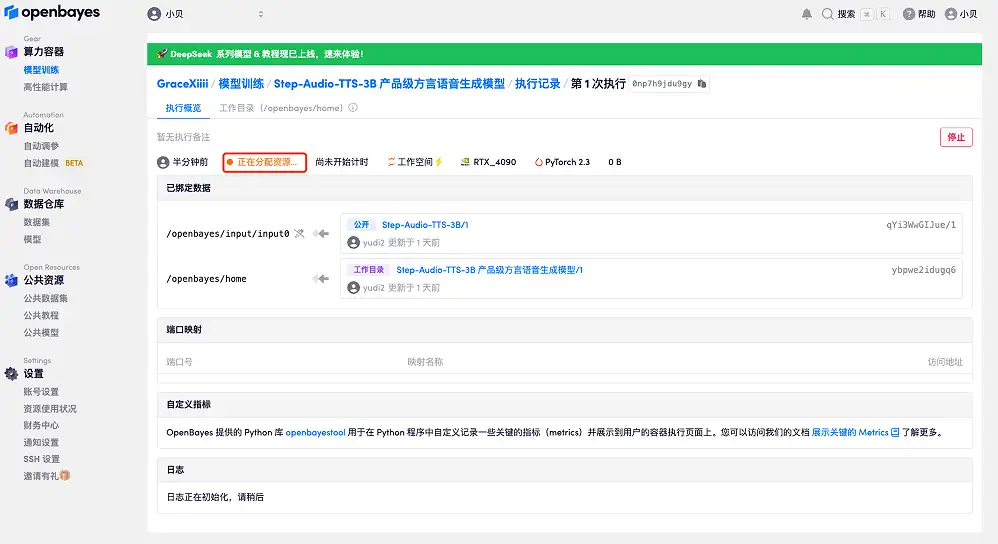
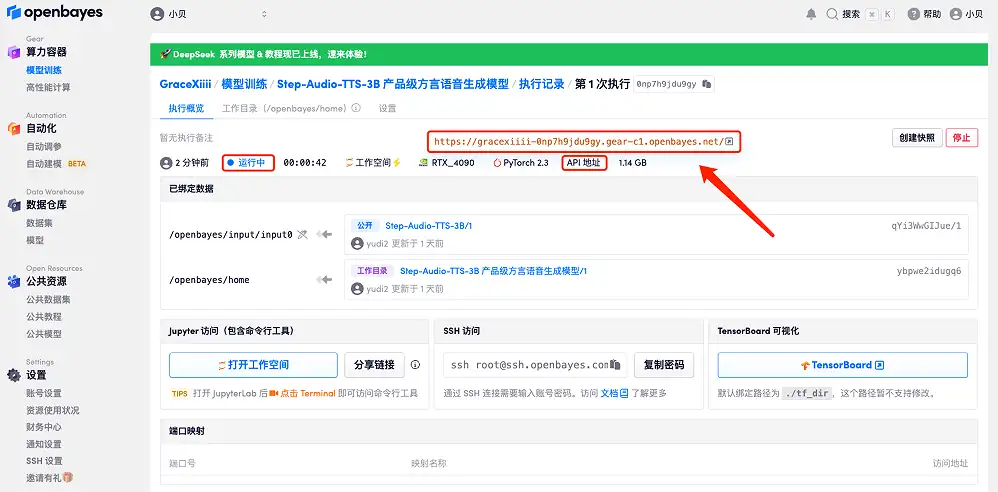
4. انتظر حتى يتم تخصيص الموارد. تستغرق عملية الاستنساخ الأولى حوالي دقيقتين. عندما تتغير الحالة إلى "قيد التشغيل"، انقر فوق سهم الانتقال بجوار "عنوان API" للانتقال إلى صفحة العرض التوضيحي. يرجى ملاحظة أنه يجب على المستخدمين إكمال مصادقة الاسم الحقيقي قبل استخدام وظيفة الوصول إلى عنوان API.

عرض التأثير
يتضمن هذا البرنامج التعليمي ثلاث وظائف: توليف الكلام العام، وتوليف الموسيقى، واستنساخ الكلام.
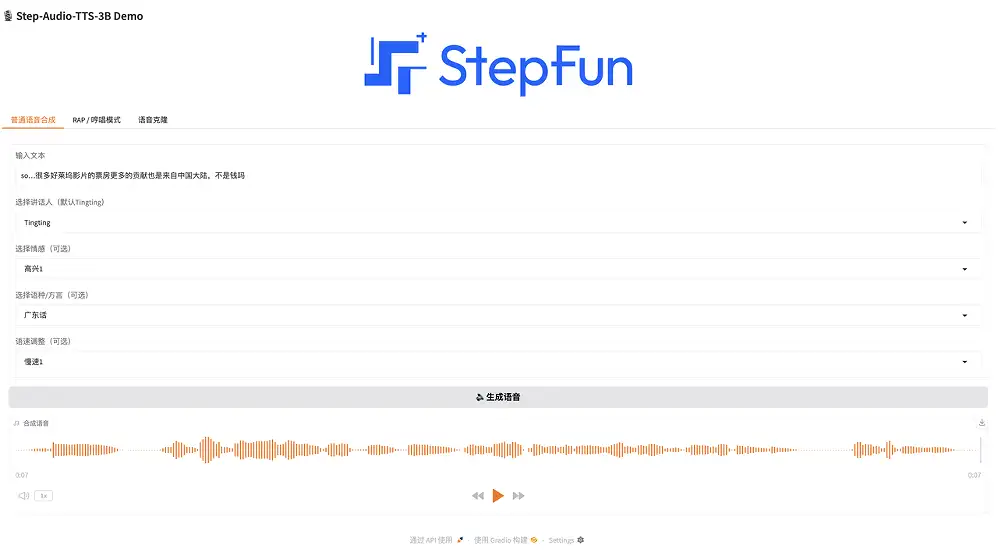
1. تركيب الكلام العام
تعمل هذه الميزة على إعداد شخصية الصوت الافتراضية الرسمية Tingting والصوت المضاف حديثًا Nezha، كما تدعم إنشاء لغات متعددة والعواطف واللهجات والإعدادات الأخرى.
وصف نغمة تركيب الكلام
* يتم إنشاء صوت Tingting بواسطة ملف المطالبة الصوتية الرسمي 4s
* يتم توليد صوت نزهة من ملف الصوت 14 ثانية "أنا نزهة الأمير الثالث، أنا غير مقيد وأحب كتابة الشعر، أمشي بيدي في جيوبي، ويمكنني جعل الطريق المنحني مستقيمًا"
في صفحة العرض التوضيحي، حدد "توليف الكلام الطبيعي"، وأدخل النص، وحدد المتحدث (الافتراضي هو Tingting)، وحدد العاطفة (سعيد، غاضب، حزين ومغازل)، وحدد اللغة/اللهجة (الصينية، الإنجليزية، اليابانية، الماندرين، السيتشوانية، الكانتونية ولهجة قوانغدونغ)، وحدد سرعة التحدث (سريعة أو بطيئة). فقط انقر فوق "إنشاء الكلام".
2. توليف الموسيقى
تعمل هذه الوظيفة على ضبط صوت Tingting الافتراضي للموقع الرسمي ونبرة Nezha المضافة حديثًا، كما تدعم RAP والهمهمة.
وصف صوت الراب
* يتم إنشاء صوت Tingting بواسطة ملف المطالبة الصوتية الرسمي 11s
* صوت نزهة يتم توليده بواسطة ملف صوتي مدته 14 ثانية بعنوان "الرعد يتدحرج وأنا خائف للغاية، يضربني في كل مكان، أنفخ في البوق لتغيير مصيري، أضحك لأتجاوز الكارثة، تيك تيك تيك تيك تيك"
وصف نغمة الطنين
* يتم إنشاء صوت Tingting بواسطة ملف مطالبة صوتي مدته 12 ثانية
* يتم إنشاء صوت نزهة بواسطة ملف الصوت 14 ثانية "لقد ولدت بلا خوف، بغض النظر عن من هو والدي أو أي شخص آخر، إذا قام السيد بإزالة الحاكم، فلن يتمكن أبدًا من أمري"
حدد "Music Synthesis" في صفحة العرض التوضيحي، وأدخل النص، وحدد مكبر الصوت (الافتراضي هو Tingting)، وحدد الوضع (RAP أو Humming). فقط انقر فوق "إنشاء RAP/Humming".

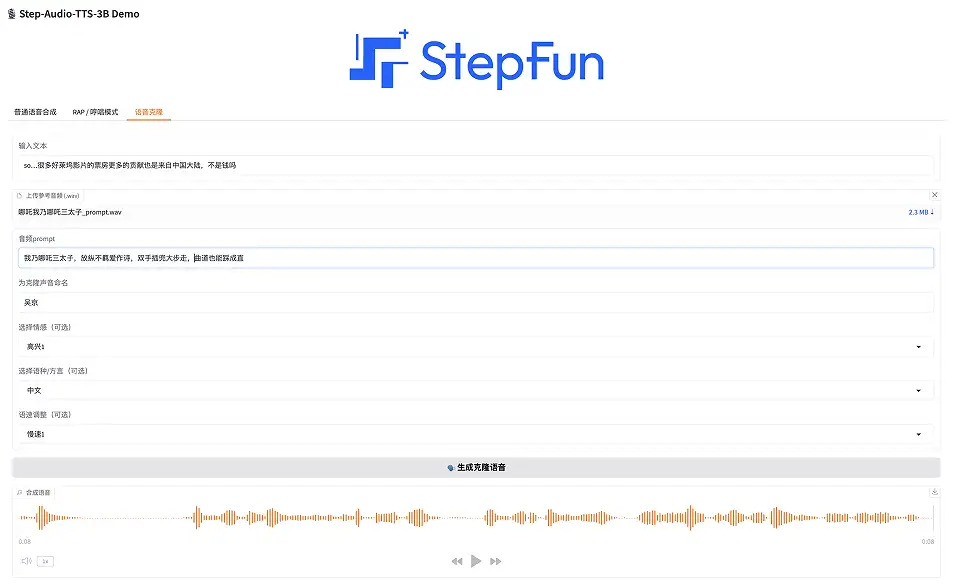
3. استنساخ الصوت
تدعم هذه الوظيفة المستخدمين لتحميل صوت مخصص وتوليد صوت شخصي.
حدد "استنساخ الصوت" في صفحة العرض التوضيحي، وأدخل النص، وقم بتحميل الصوت المرجعي (بتنسيق .wav)، وقم بتسمية الصوت المستنسخ، وحدد العاطفة (سعيد، غاضب، حزين ومغازل)، وحدد اللغة/اللهجة (اللهجة الصينية، الإنجليزية، اليابانية، الماندرين، السيتشوانية، الكانتونية ولهجة قوانغدونغ)، وحدد سرعة التحدث (سريعة أو بطيئة). فقط انقر فوق "إنشاء صوت مستنسخ".